








Mysql
Mysql架构
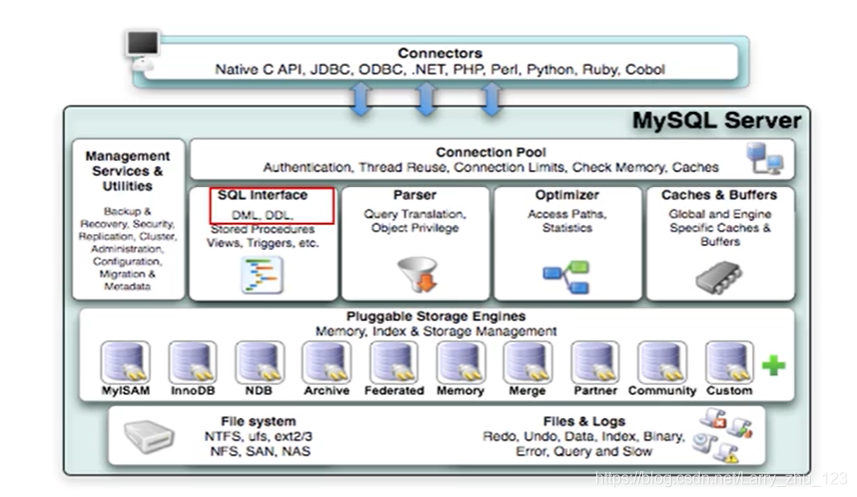
存储引擎概述

InnoDB整体架构
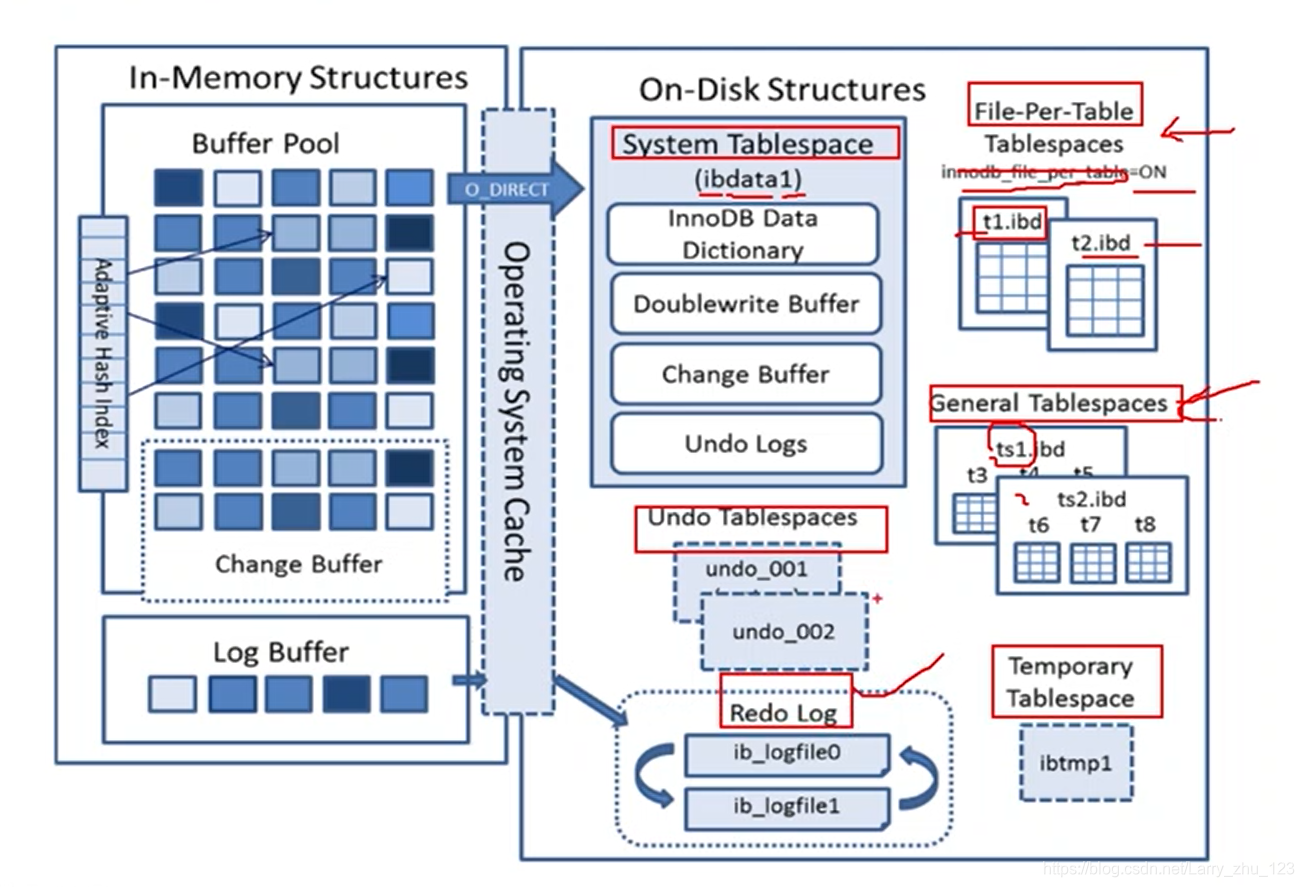
单表ibd文件内容说明

InnoDB 磁盘数据存储概念梳理

B-tree and B-plus-tree

1. 硬盘操作
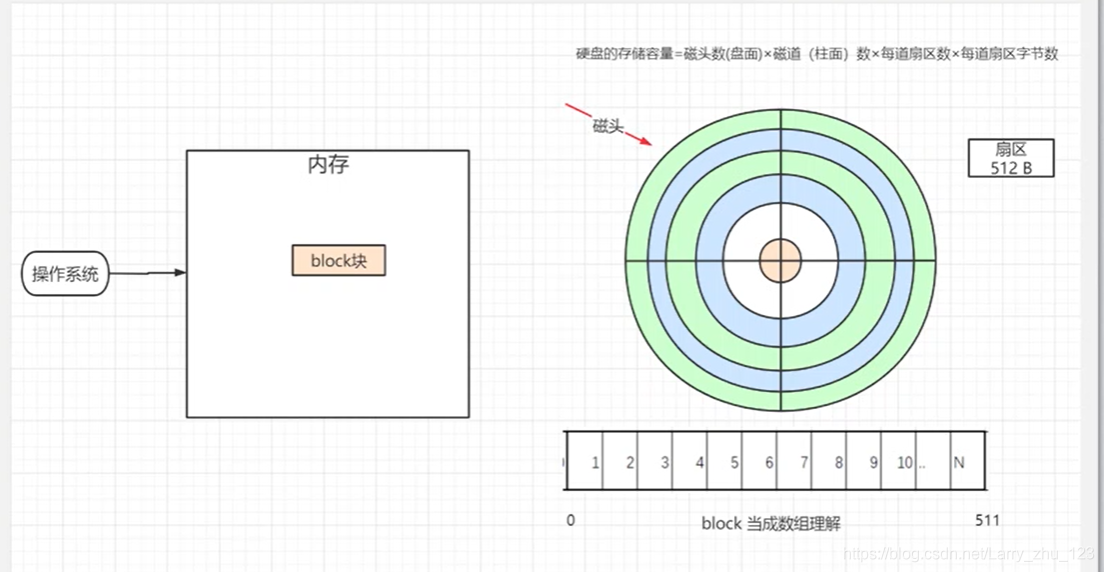
2. 数据在磁盘中的存储

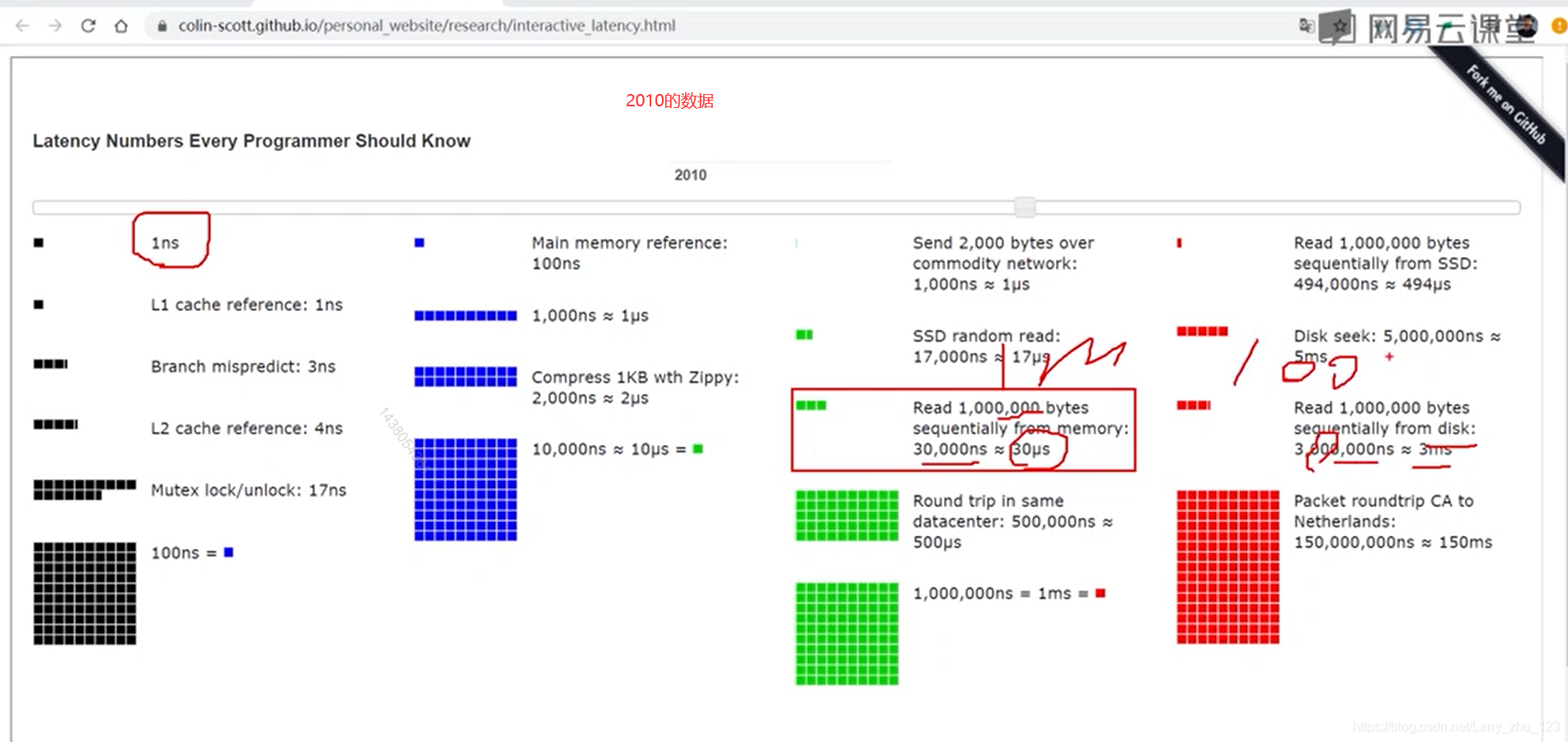
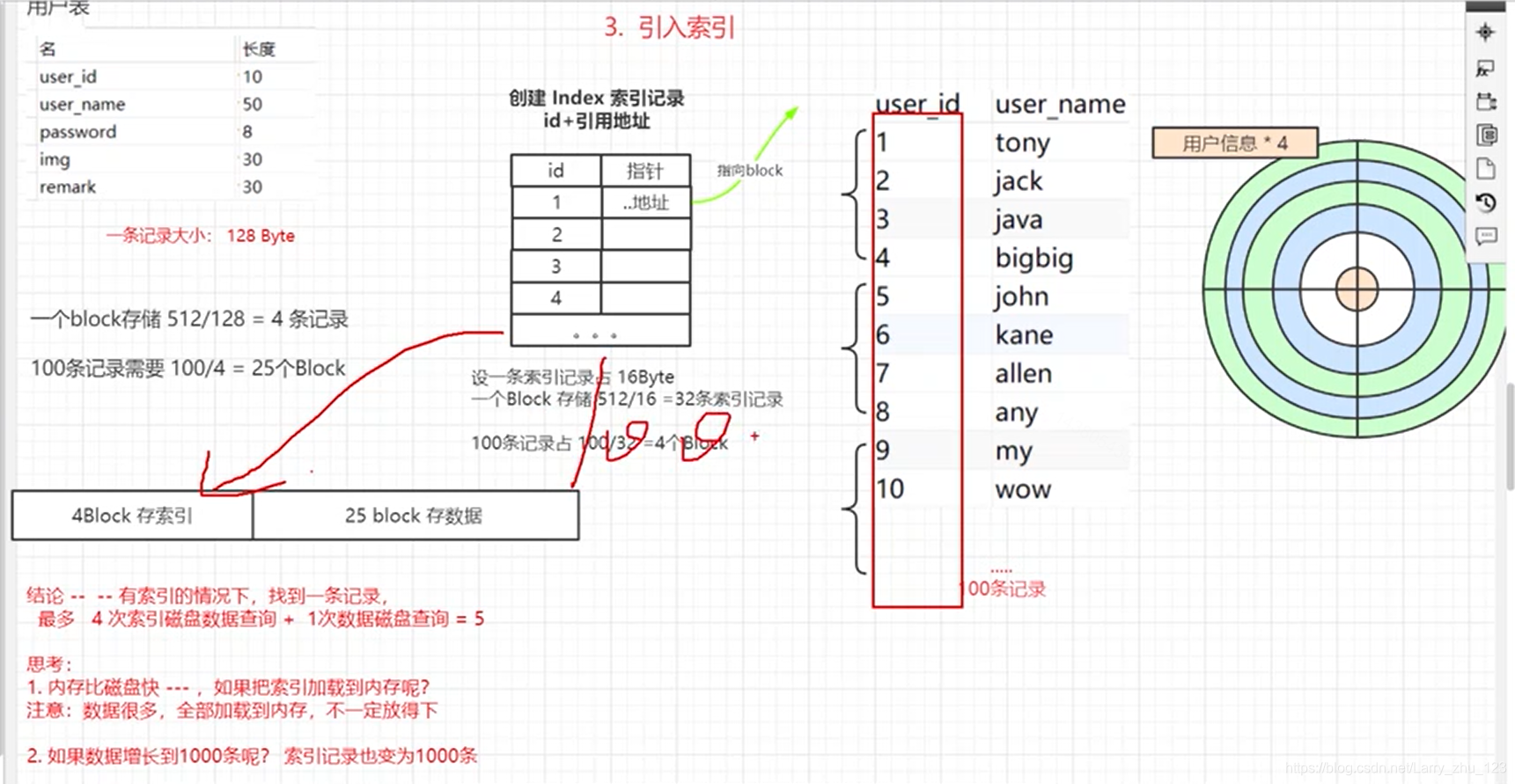
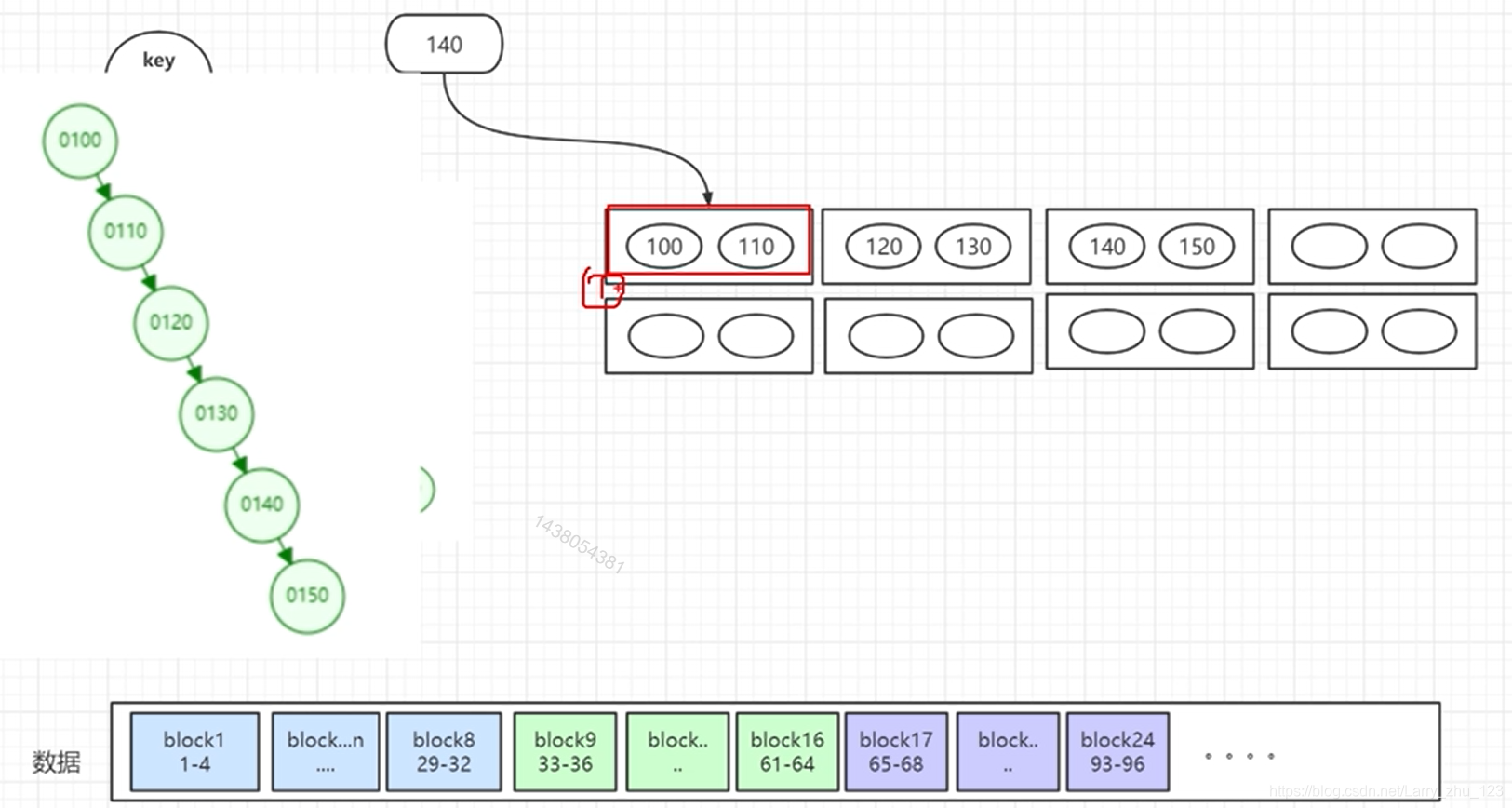
3.引入索引
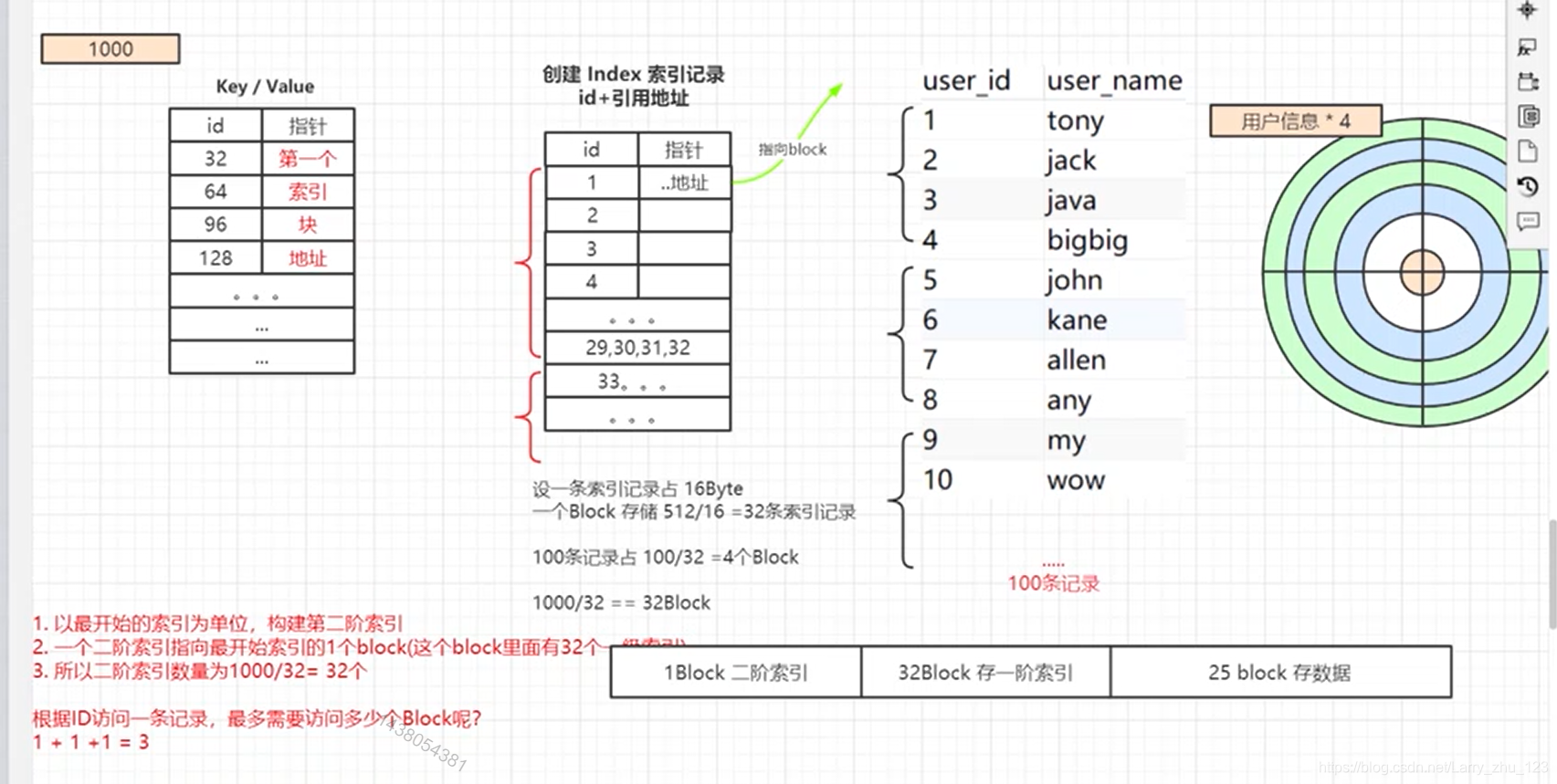
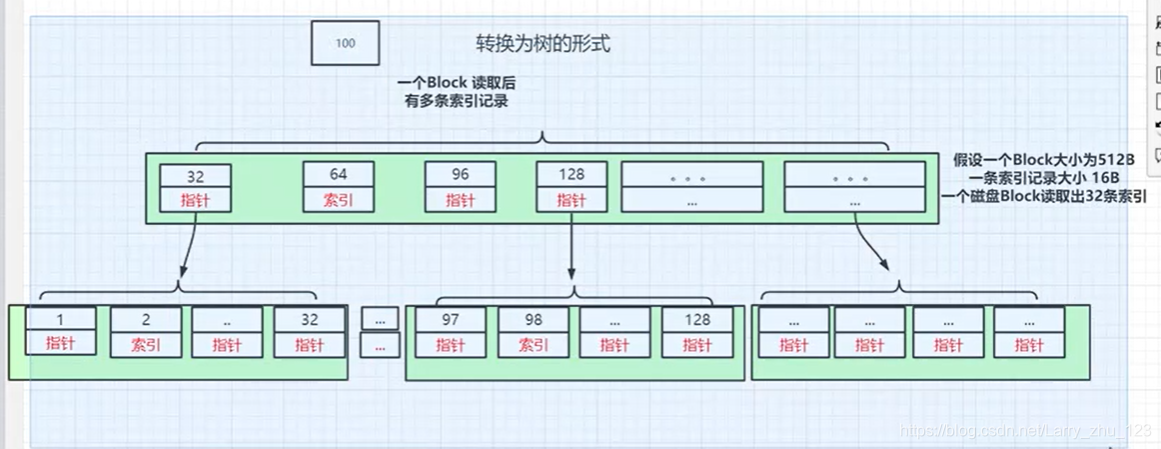
4.记录更多…引入多重索引
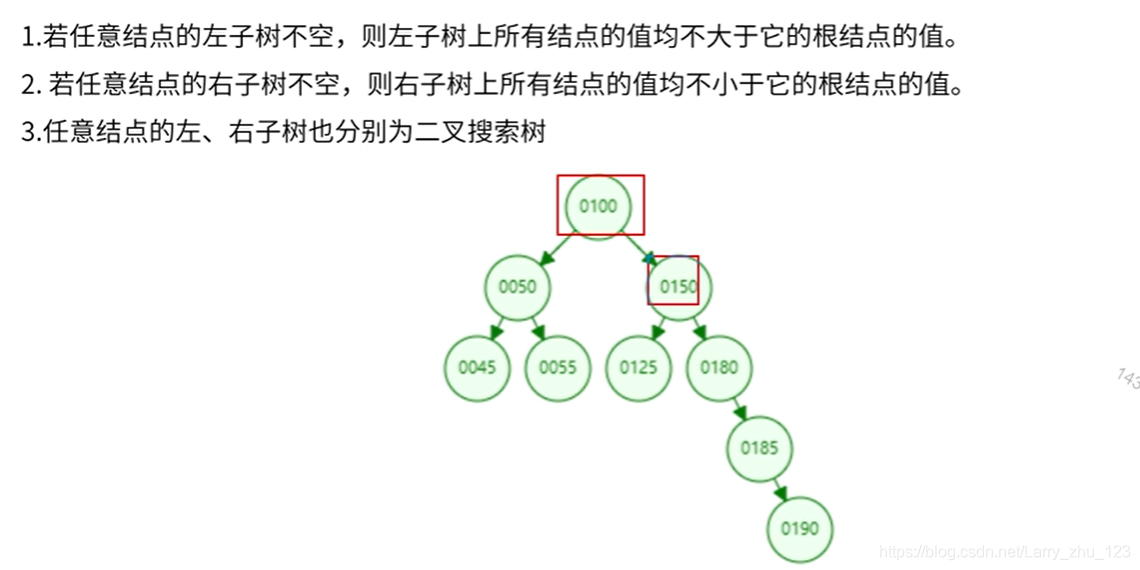
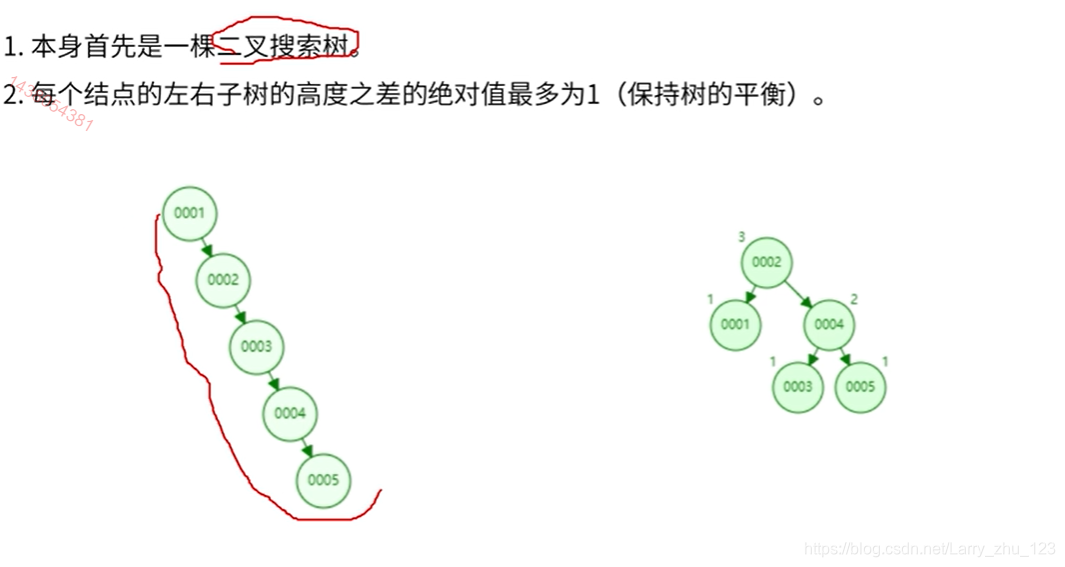
5.1 二叉查找树
Binary Search Tree 树动态构建网站
-> 不合适,不平衡

5.2 二叉平衡查找树
AVL Tree 平衡二叉树
-> 不合适 , 层级过高,(数据量越来越大的手层级过高)
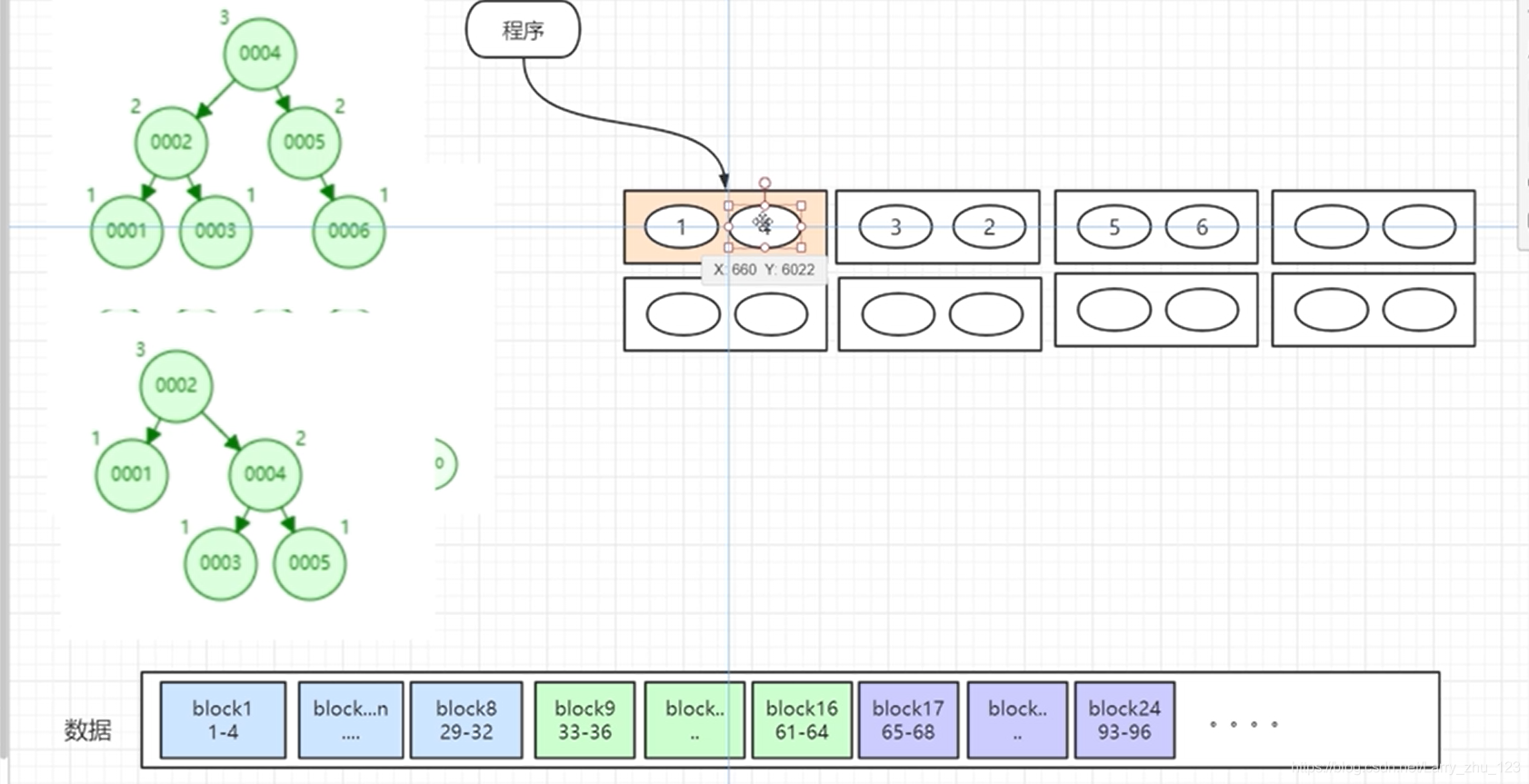
6.Btree对二叉查找树的优化

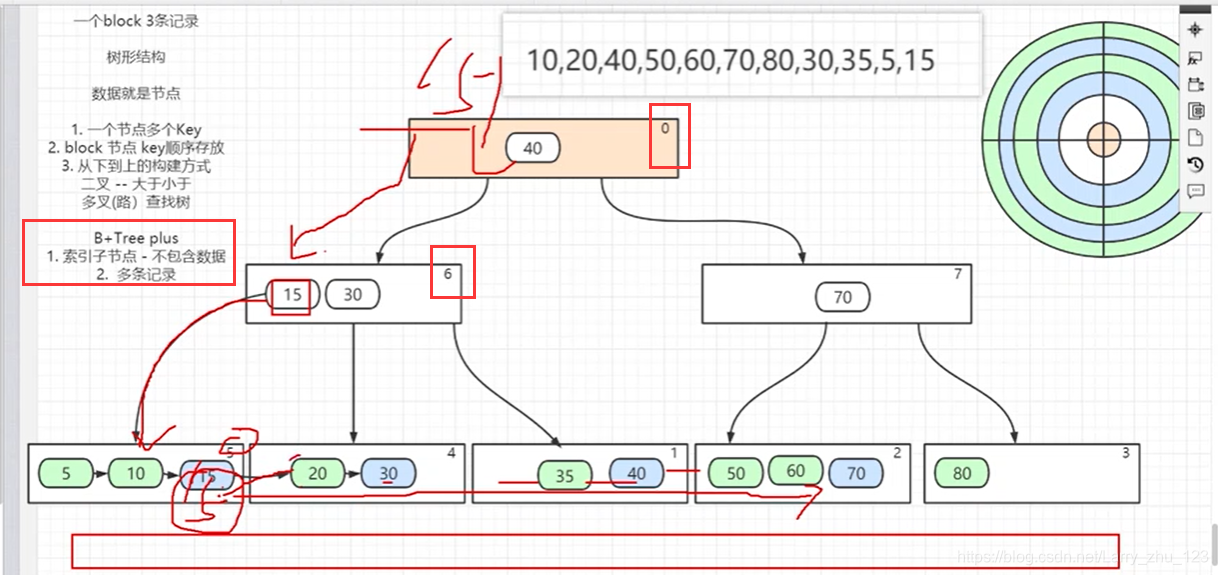
7. B±tree

ACID与InnoDB
InnoDB整体架构
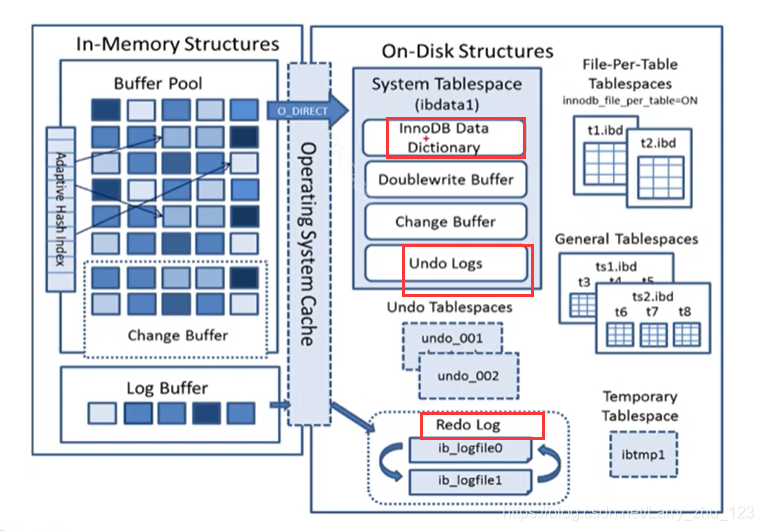
ACID描述

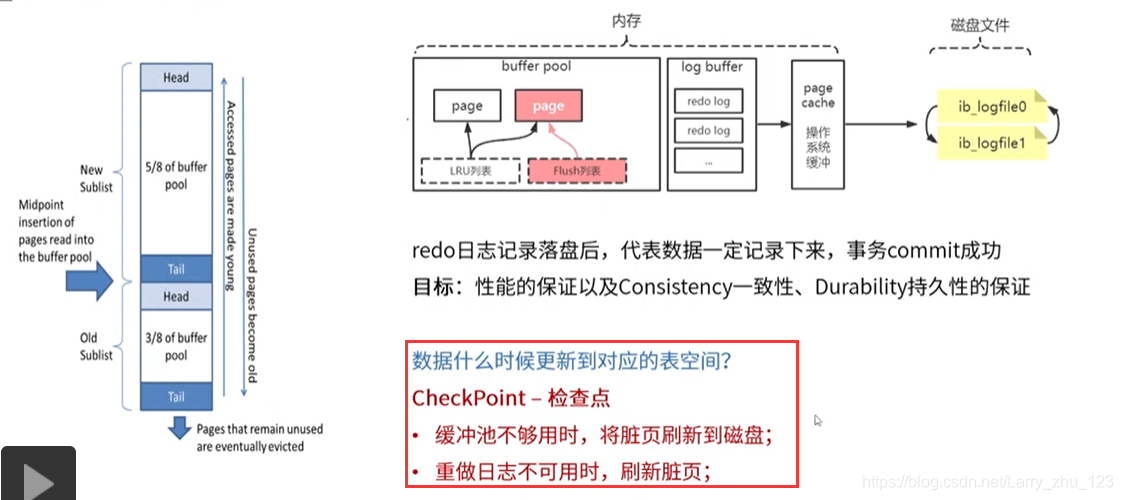
Redo Log
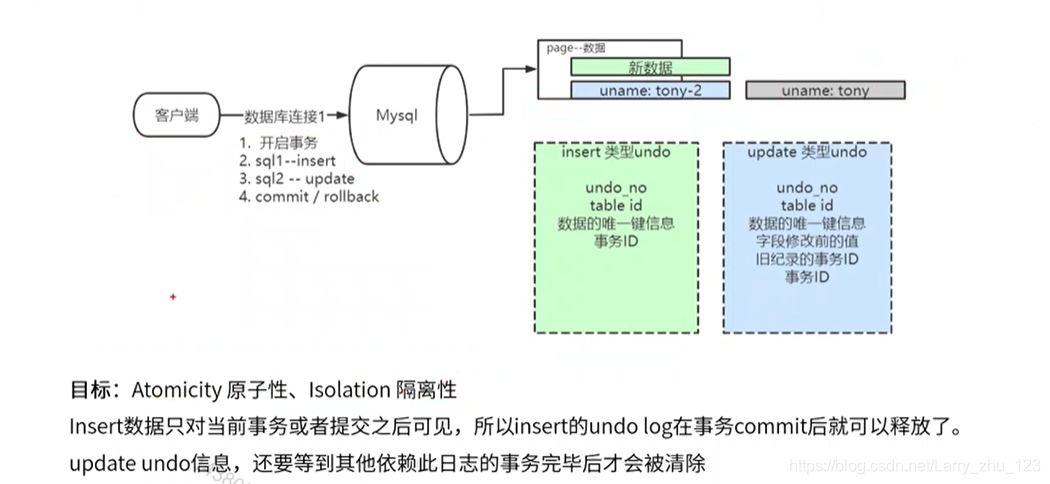
Undo Log
Mysql Workbench介绍
-> workbench 能够通过ssh的方式连接 可视化的查看日志信息 ,并且提供很多的可视化功能

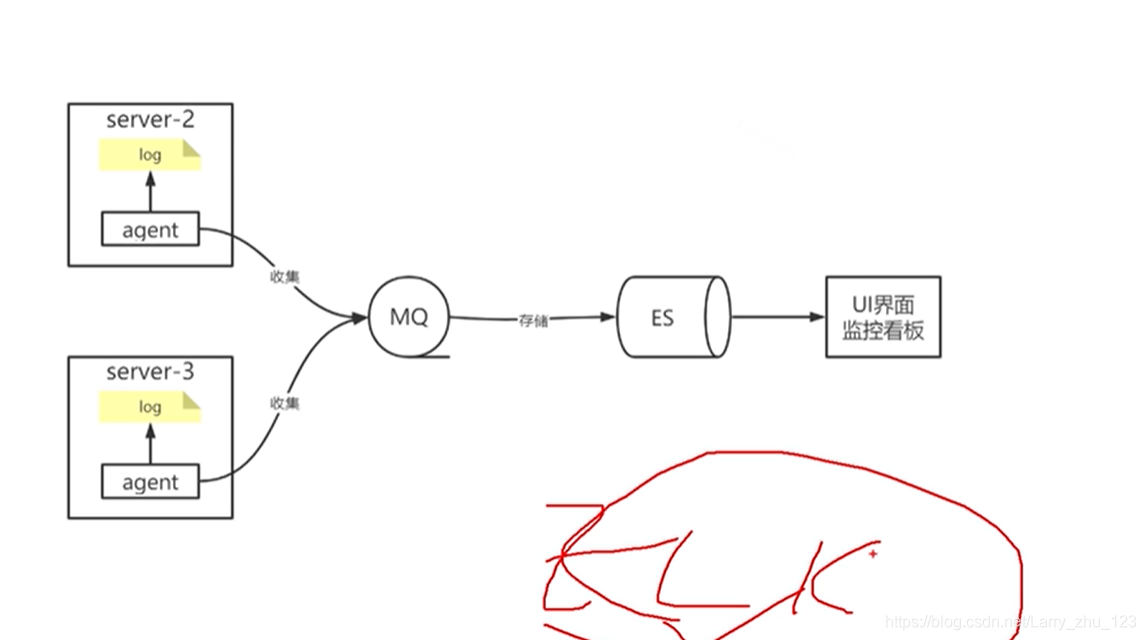
Mysql 慢查询日志
概述
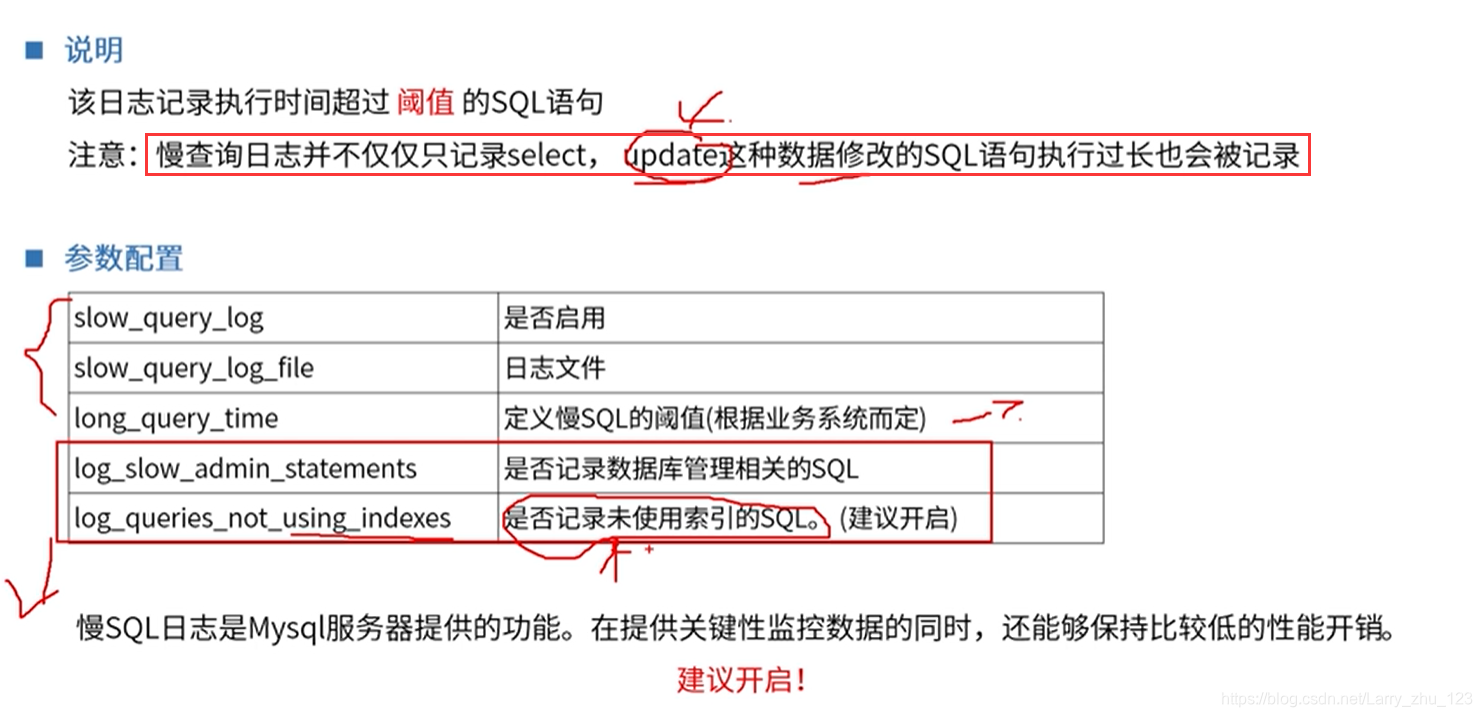
日志内容分析

生产环境如何发现慢SQL
索引概述
管理索引的语法

索引的分类

索引的相关概念

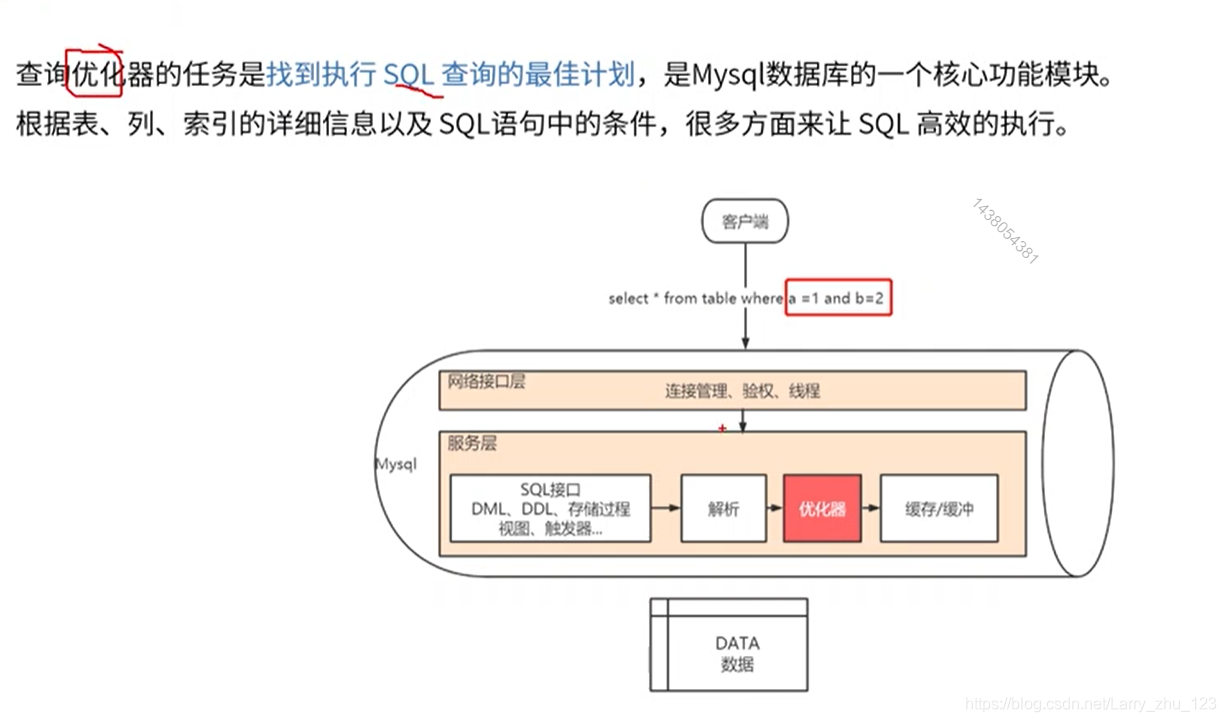
查询优化器与执行计划
查询优化器
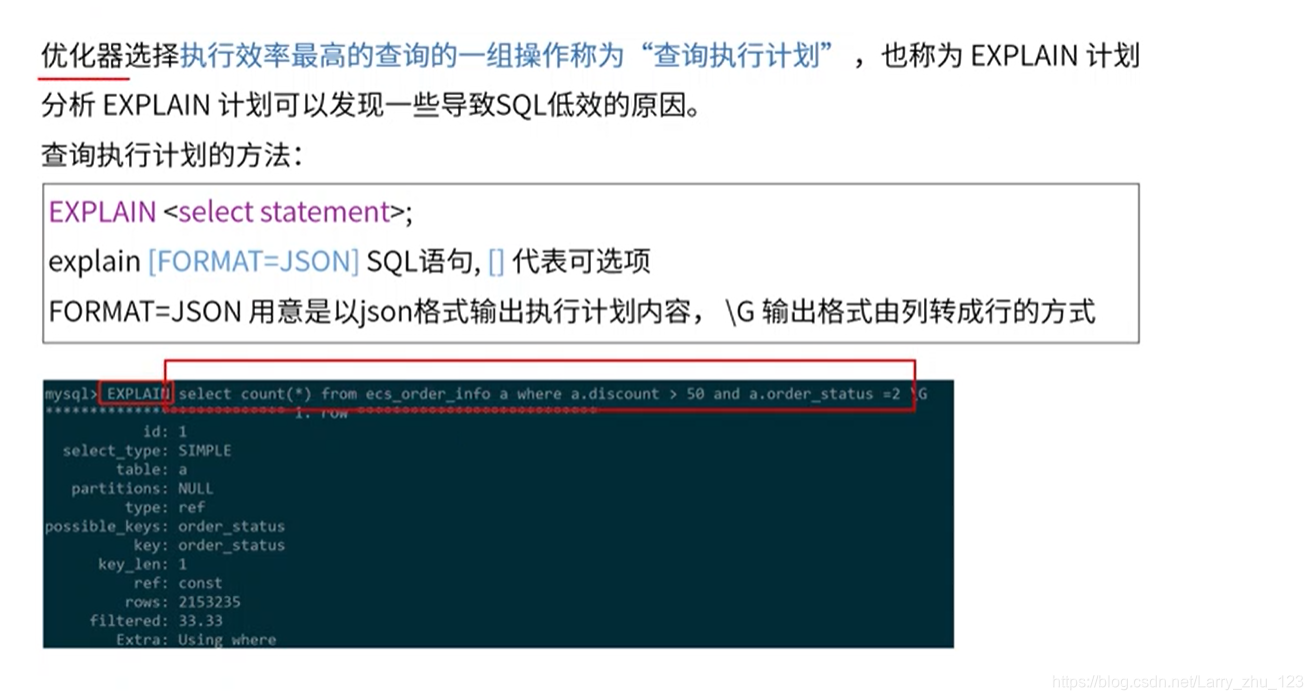
执行计划
mysql开启执行计划debug模式相关的配置后 可以查看所有的执行过程,具体的可以参考官方文档
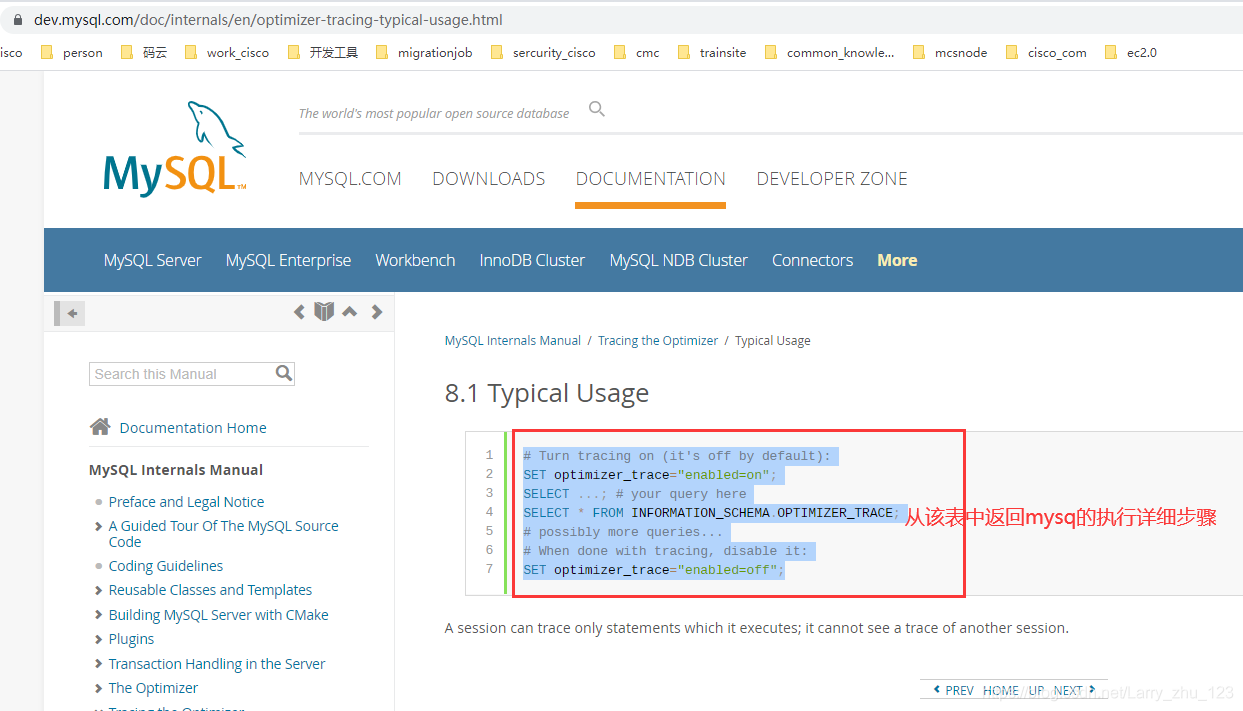
-> 复制出内容如下是一个json的字符串,详细的标注了每一个步骤
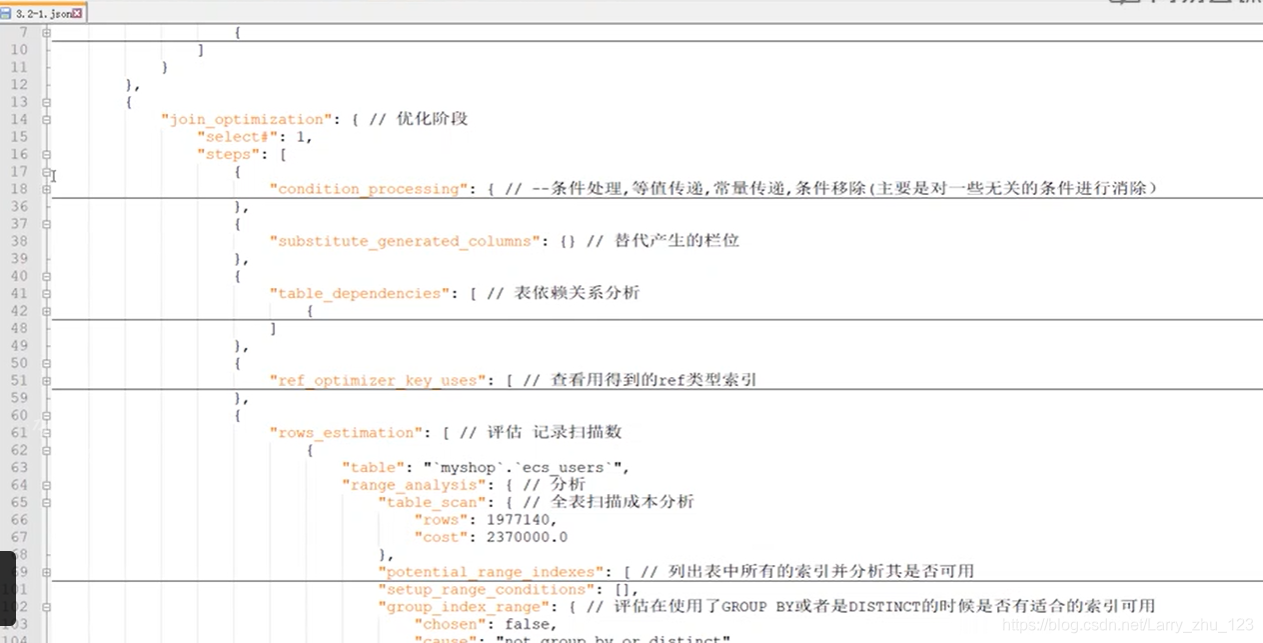
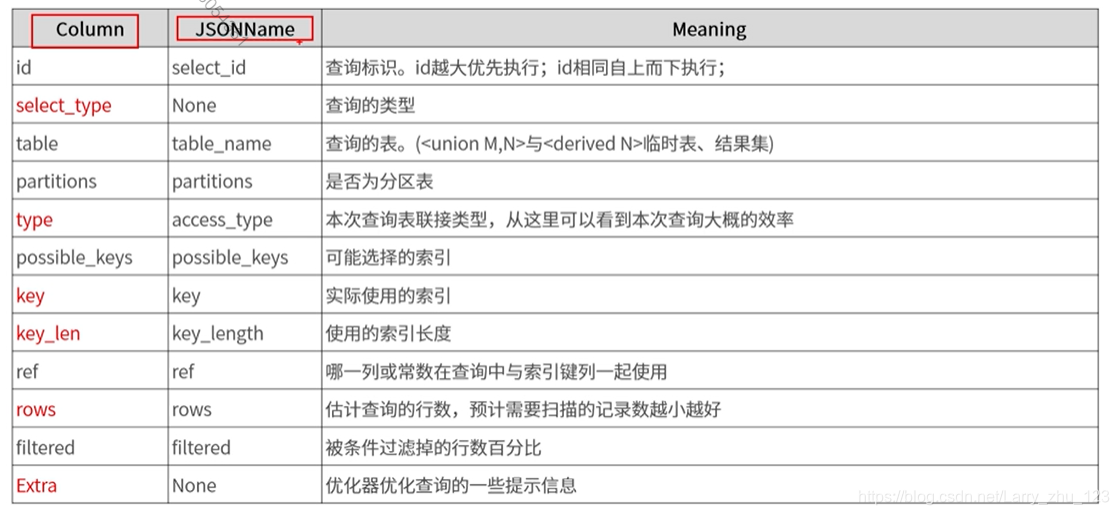
执行计划输出列说明
关键字段 select_type
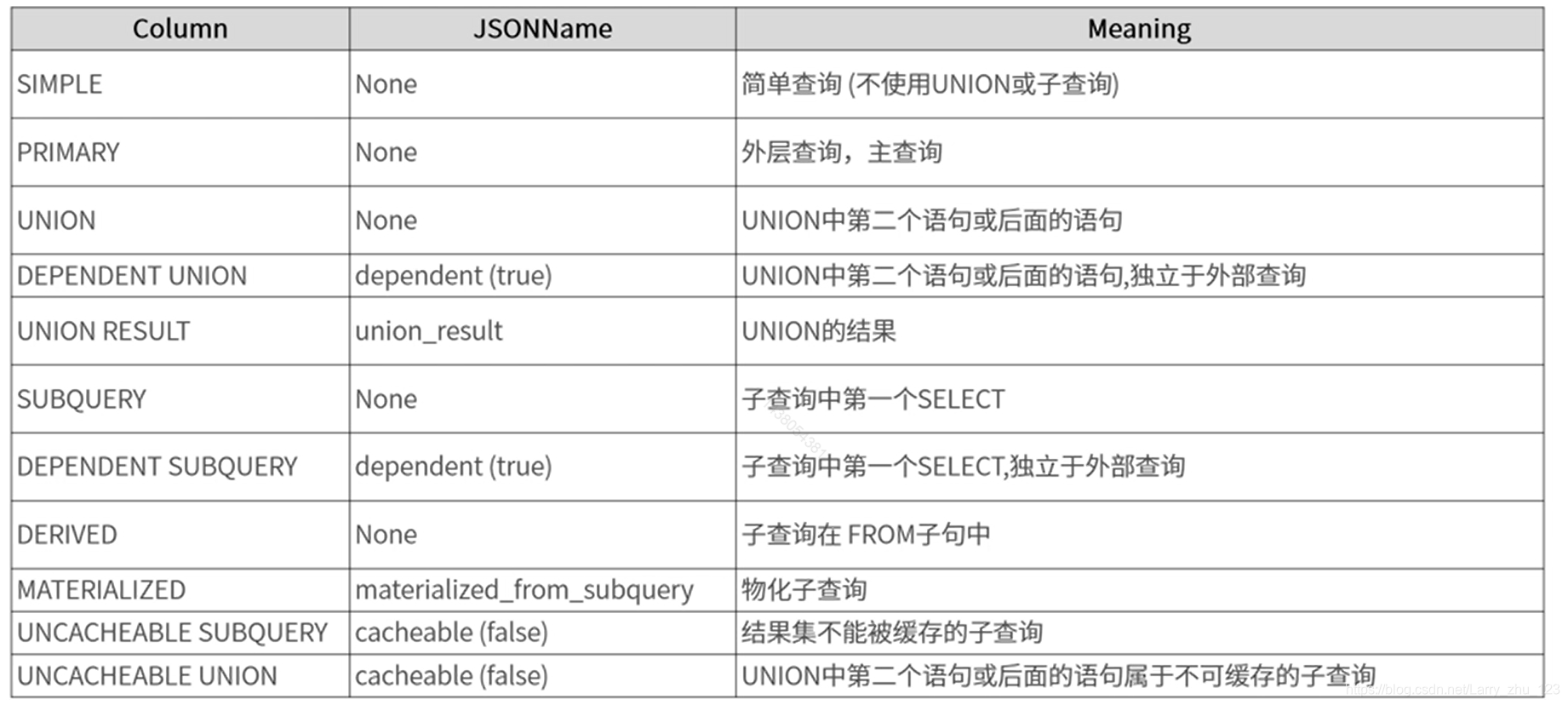
-- select type的多种类型
-- id相同的可以认为是一组,从上往下顺序执行;
-- id不同id值越大,优先级越高,越先被执行。
-- SIMPLE 最简单的查询方式
EXPLAIN select * from myshop.ecs_users where user_id =1;
-- PRIMARY 最外层开始查询
-- UNION,UNION 第一个SELECT 为PRIMARY,第二个及之后的所有SELECT 为 UNION SELECT TYPE;
-- UNION RESULT,每个结果集的取出来后,会做合并操作,这个操作就是 UNION RESULT
EXPLAIN select * from myshop.ecs_users where user_id =1 union select * from myshop.ecs_users where user_id =2;
-- DEPENDENT UNION,子查询中的UNION操作,从UNION 第二个及之后的所有SELECT语句的SELECT TYPE为 DEPENDENT UNION
-- DEPENDENT SUBQUERY,子查询中内层的第一个SELECT,依赖于外部查询的结果集
EXPLAIN select * from myshop.ecs_users where user_id in (
select user_id from myshop.ecs_users where user_id =1 union select user_id from myshop.ecs_users where user_id =2);
-- SUBQUERY,子查询内层查询的第一个SELECT,结果不依赖于外部查询结果集
EXPLAIN select * from myshop.ecs_users where user_id = (
select max(user_id) from myshop.ecs_users where email is null );
-- DERIVED 派生表,子查询在 FROM子句中
EXPLAIN select * from myshop.ecs_users a,
(select max(user_id) as user_id, CURRENT_DATE() from myshop.ecs_users where email is null ) b
where a.user_id = b.user_id;
-- mysql不会为每个子查询都创建派生表,派生表的目的就是用于保存子查询的中间结果
-- 此语句优化后无子查询(子查询展开) EXPLAIN select * from (select user_id from myshop.ecs_users where user_id =1) as a;
-- 默认开启,优化器工作 可以关闭 set optimizer_switch='derived_merge=off';
-- MATERIALIZED 物化子查询
EXPLAIN select * from myshop.ecs_users
where user_id in (
SELECT USER_ID FROM myshop.ecs_order_info where order_id < 10 );
-- 从 MySQL 5.7.20开始,查询缓存就被弃用了,并在 MySQL 8.0中被删除。
-- UNCACHEABLE SUBQUERY 结果集不能被缓存的子查询,不可物化每次都需要计算(动态计算,耗时操作)
EXPLAIN select * from myshop.ecs_users where user_id = (
select max(LAST_INSERT_ID()) as user_id from myshop.ecs_users);
-- UNCACHEABLE UNION UNION中第二个语句或后面的语句属于不可缓存的子查询
EXPLAIN select * from myshop.ecs_users where user_id = (
select max(LAST_INSERT_ID()) as user_id from myshop.ecs_users
union select max(LAST_INSERT_ID()) as user_id from myshop.ecs_users);
关键字段 type
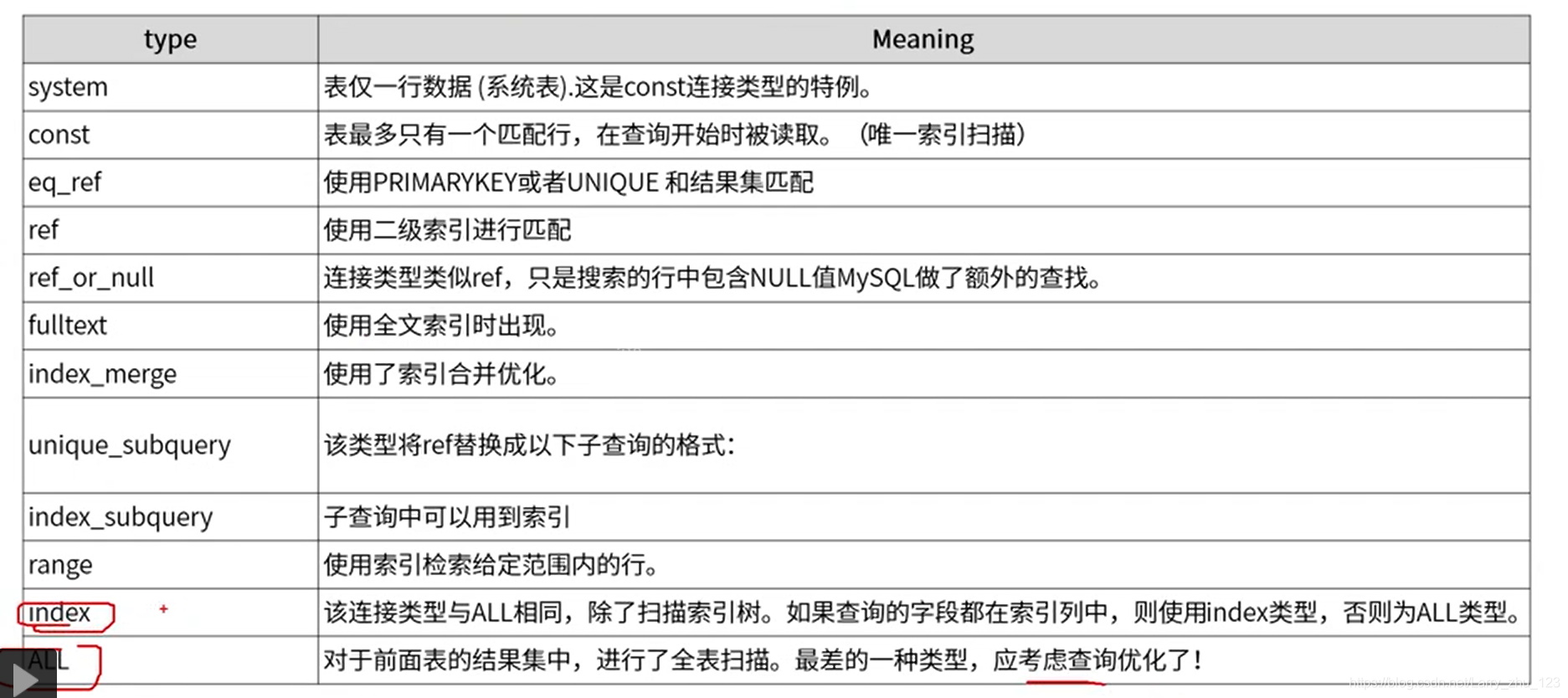
-- access_type 表查询联接类型,由上到下,性能逐步变低
-- 1. NULL 不访问任何一个表
EXPLAIN select 1 from dual;
-- 2. system 根据主键查询系统表且这个表只有一条记录【特殊的const场景】
-- 3. const 常量查询非常快。主键或者唯一索引的常量查询,表格最多只有1行记录符合查询。
EXPLAIN select * from myshop.ecs_users where user_id =1;
-- 4. eq_ref 使用PRIMARYKEY或者UNIQUE 和前面的结果集匹配。
EXPLAIN select * from myshop.ecs_order_info b, myshop.ecs_users a where b.user_id = a.user_id;
-- 5. ref 非聚集索引的常量查询。
EXPLAIN select * from myshop.ecs_users where email = 'onlyoneemail.com';
-- 6. fulltext 查询的过程中,使用到了 fulltext 索引(fulltext index在innodb引擎中,只有5.6版本之后的支持)
EXPLAIN SELECT * FROM `demo-fulltext` WHERE MATCH(`remark`) AGAINST('Tony');
-- 7. ref_or_null 跟ref查询类似,在ref的查询基础上,加多一个null值的条件查询
EXPLAIN select * from myshop.ecs_users where email = 'onlyoneemail.com' OR email is null;
-- 8. index_merge 索引合并(分别两个查询条件的结果,再合并)
EXPLAIN select * from myshop.ecs_users where email = 'onlyoneemail.com' OR user_id = 1;
-- 9. unique_subquery IN子查询的结果由聚族索引或唯一索引覆盖。
SET optimizer_switch='materialization=off';
EXPLAIN select * from myshop.ecs_users where user_id not in (
select user_id from myshop.ecs_users where email like '%.com%' );
SET optimizer_switch='materialization=on';
-- 10. index_subquery 与unique_subquery类似,但是用的是二级索引
SET optimizer_switch='materialization=off';
EXPLAIN select * from myshop.ecs_users where email not in (
select email from myshop.ecs_users where email like '%.com%' );
SET optimizer_switch='materialization=on';
-- 11. range =、<>、>、>=、<、<=、IS NULL、BETWEEN、IN、<=> (这是个表达式:左边可以推出右边,右边也可推出左边)
EXPLAIN select order_id from myshop.ecs_order_info where order_id < 10;
-- 12. index 执行full index scan直接从索引中取的想要的结果数据,也就是可以避免回表
EXPLAIN select order_id from myshop.ecs_order_info;
-- 13. ALL 执行full table scan,这事最差的一种方式
EXPLAIN select pay_fee from myshop.ecs_order_info;
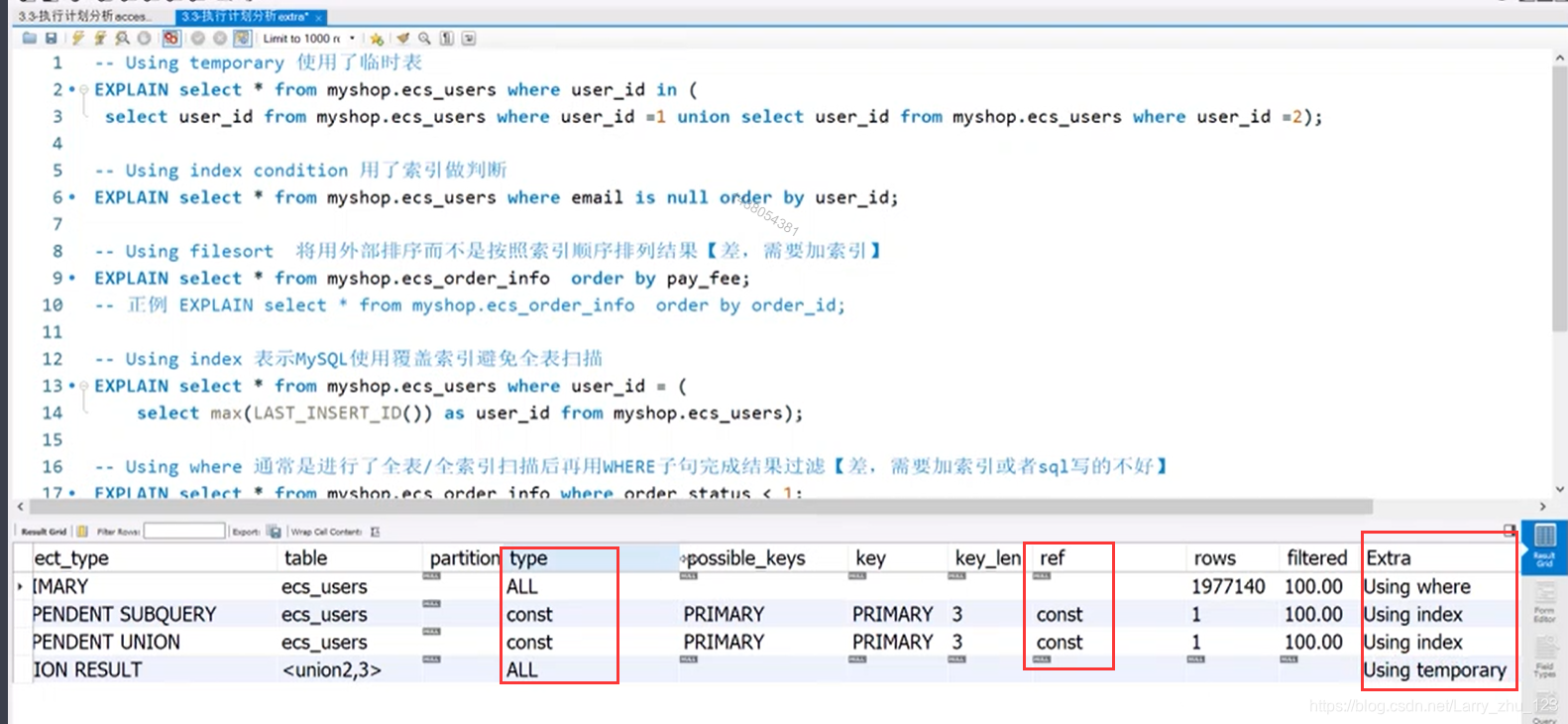
关键字段 extra
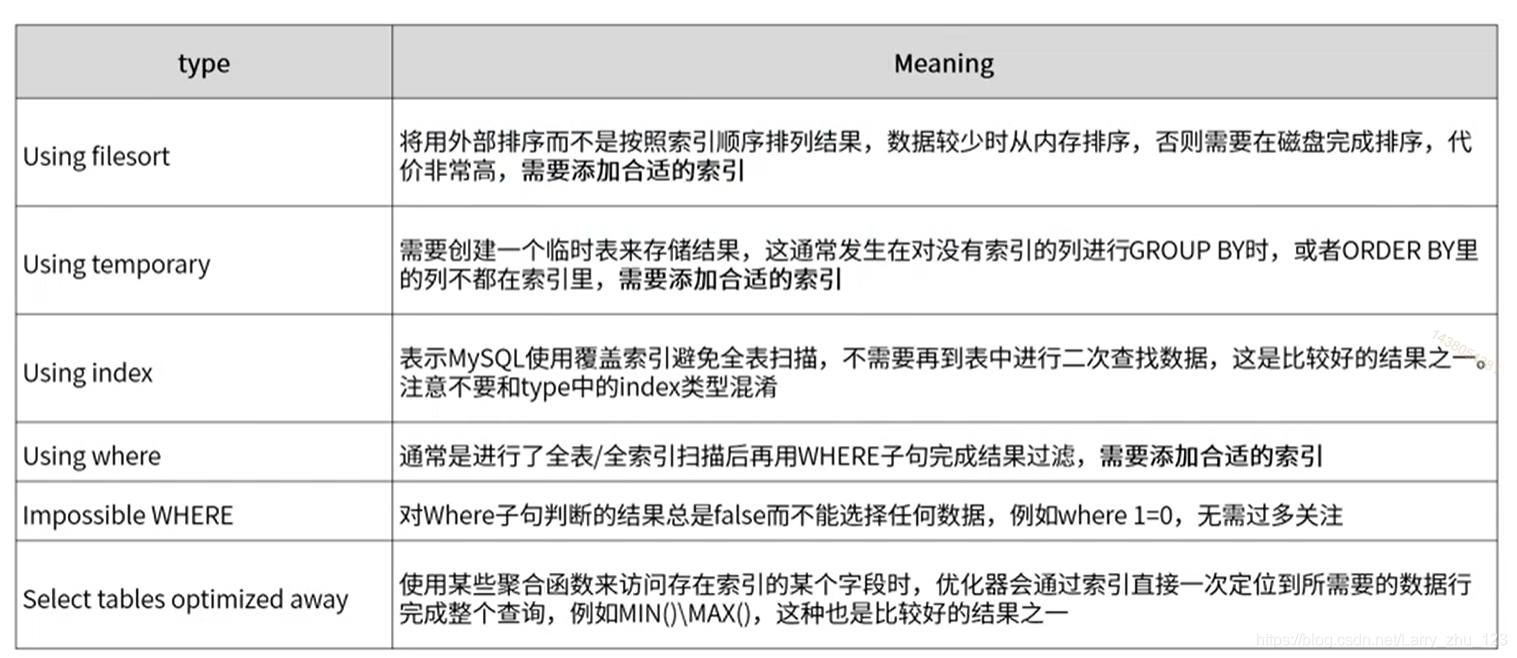
-- Using temporary 使用了临时表
EXPLAIN select * from myshop.ecs_users where user_id in (
select user_id from myshop.ecs_users where user_id =1 union select user_id from myshop.ecs_users where user_id =2);
-- Using index condition 用了索引做判断
EXPLAIN select * from myshop.ecs_users where email is null;
-- Using filesort 将用外部排序而不是按照索引顺序排列结果【差,需要加索引】
EXPLAIN select * from myshop.ecs_order_info order by pay_fee;
-- 正例 EXPLAIN select * from myshop.ecs_order_info order by order_id;
-- Using index 表示MySQL使用覆盖索引避免全表扫描
EXPLAIN select * from myshop.ecs_users where user_id = (
select max(LAST_INSERT_ID()) as user_id from myshop.ecs_users);
-- Using where 通常是进行了全表/全索引扫描后再用WHERE子句完成结果过滤【差,需要加索引或者sql写的不好】
EXPLAIN select * from myshop.ecs_order_info where order_status < 1;
-- Impossible WHERE 不成立的where判断。比如order_status字段不能为空
EXPLAIN select * from myshop.ecs_order_info where order_status is null;
-- Select tables optimized away 通过聚合函数来访问某个索引字段时,优化器一次定位到所需要的数据行完成整个查询【比较好】
EXPLAIN select * from myshop.ecs_users where user_id = (
select max(user_id) from myshop.ecs_users where email is null );
SQL查询技巧分析
Like会不会走索引
-- 案例1: Like会不会走索引?
explain select * from myshop.ecs_users where email like 'onlyoneemail.com'; --范围查询 前后固定是=
explain select * from myshop.ecs_users where email like 'onlyoneemail.com%'; --走索引
explain select * from myshop.ecs_users where email like '%onlyoneemail.com'; --不走
explain select * from myshop.ecs_users where email like '%onlyoneemail.com%';--不走
索引列能不能为空
-- 案例2: 索引列能不能空? IS NULL 与 IS NOT NULL
select * from myshop.ecs_users where email is null;
select * from myshop.ecs_users where email ='aamain.com';
select * from myshop.ecs_users where email is not null; --不走索引 ,优化器认为这个字段有索引则绝大多数数据不为空,则进行全表扫描
函数计算会不会走索引
-- 案例3 - 索引函数计算会不会走索引? 函数走不走索引不一定得具体的分析如下 FROM_UNIXTIME联合count会走
SELECT count(*) FROM myshop.ecs_order_info where FROM_UNIXTIME(add_time, '%Y-%m-%d') = '2020-05-05';
SELECT * FROM myshop.ecs_order_info where FROM_UNIXTIME(add_time, '%Y-%m-%d') = '2020-05-05';--不走索引
类型不一致会不会不走索引
–不一定 有的简单的会走但也得看特定版本的优化器具体的实现 所以要尽量的自己避免这种问题 ,可以打开优化器的debug模式查看具体的优化过程
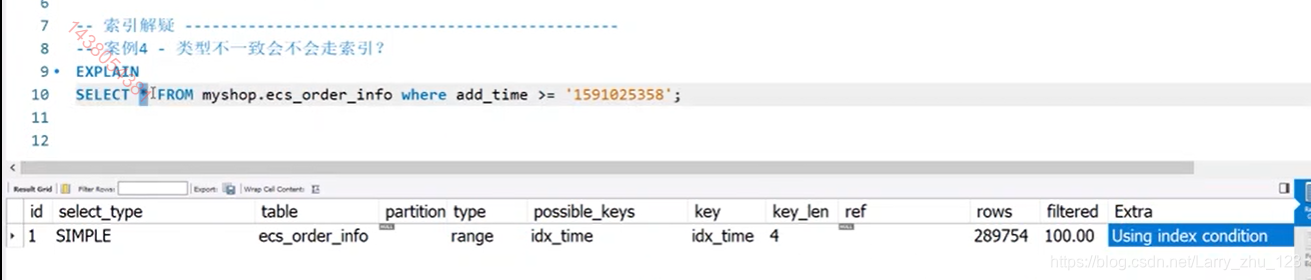
-- 案例4 - 类型不一致会不会走索引?
SELECT * FROM myshop.ecs_order_info where add_time >= '1591025358';
where条件顺序
-> 多列索引与顺序无关 但前提是最昨天的列得有
-- 案例5 - 多列索引,顺序反了会不会走索引? 索引 idx_ship_pay(pay_id,shipping_id, pay_time)
-- 记住最左前缀的概念
SELECT * FROM myshop.ecs_order_info where shipping_id = 4 and pay_id = 2 and pay_time >= '1591025358'; --会
SELECT * FROM myshop.ecs_order_info where shipping_id = 2 and pay_time >= '1591025358';--
SELECT * FROM myshop.ecs_order_info where shipping_id = 2;
SELECT * FROM myshop.ecs_order_info where pay_id = 2 and pay_time >= '1591025358';
-- 不用组合索引,查询多个单列索引 会不会只有一个索引生效? - 索引合并(指的是会根据索引查询两个然后合并在一起)
select * from myshop.ecs_users where email = 'onlyoneemail.com' or user_name = 'edu_159100060138810';
要不要用UNION代替OR
-> 会发现or的会解析成union ,并且union的cost会低于OR, 但是uinon脚本太长用or就会方便很多,看具体的业务量选择合适的脚本。
-- 案例7 - UNION 替代 OR语句? 查看下面两条sql的cost时发现union低于or
---- 以后都用union代替or吗 不是得看你的业务需求 union sql写出来不好看 若是数据量不大的时候用or也可以接收
select * from myshop.ecs_users where email = 'onlyoneemail.com'
union
select * from myshop.ecs_users where user_name = 'edu_159100060138810';
select * from myshop.ecs_users where email = 'onlyoneemail.com' or user_name = 'edu_159100060138810';
EXISTS VS IN
->常见情况下,子查询结果少,用in ,子查询结果多,用exists .但是这个多和少是没有办法定义的,只能在测试环境模拟数据查看解析计划,另外对于常量型的值用in比较快
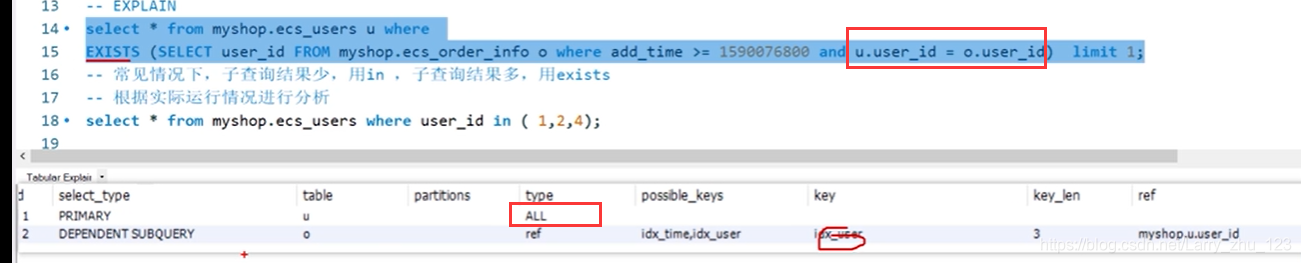
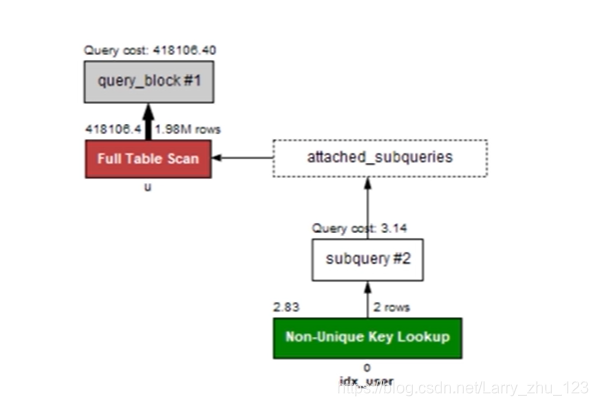
-- 案例8 - EXISTS VS IN - 是否需要用EXISTS替代IN、用NOT EXISTS替代NOT IN?
select * from myshop.ecs_users where user_id
in ( SELECT user_id FROM myshop.ecs_order_info where add_time >= 1590076800 ) limit 1;
select * from myshop.ecs_users u where
EXISTS (SELECT user_id FROM myshop.ecs_order_info o where add_time >= 1590076800 and u.user_id = o.user_id) limit 1;
-- 常见情况下,子查询结果少,用in ,子查询结果多,用exists
-- 根据实际运行情况进行分析
select * from myshop.ecs_users where user_id in ( 1,2,4);
select * from myshop.ecs_users u where EXISTS
( select * from (
select 1 user_id union select 2 union select 4
) u1 where u.user_id = u1.user_id );
– 用in
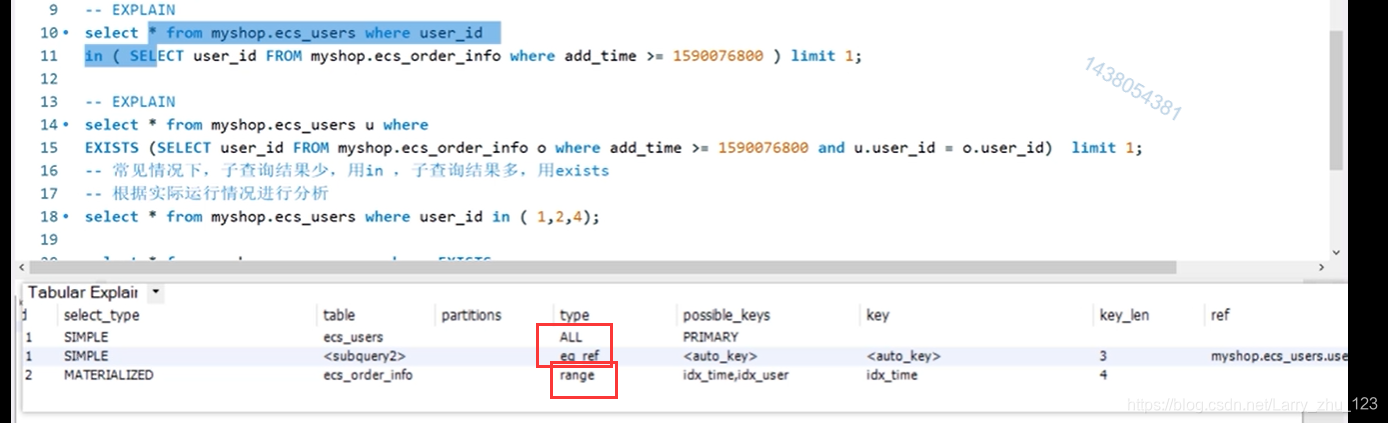
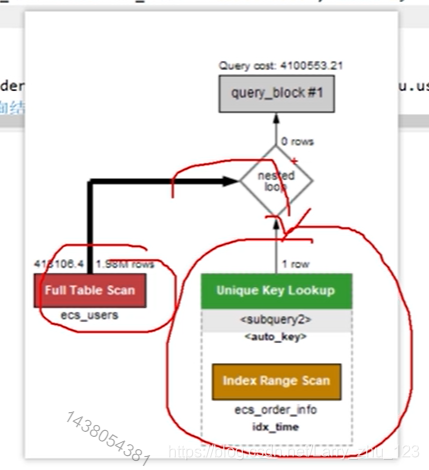
– 用 exists.
非等于会不会走索引
-> 不确定 ,需要具体分析,一般主键会走索引,非主键列一般不走索引 但与一些函数配合使用的时候也会走索引。
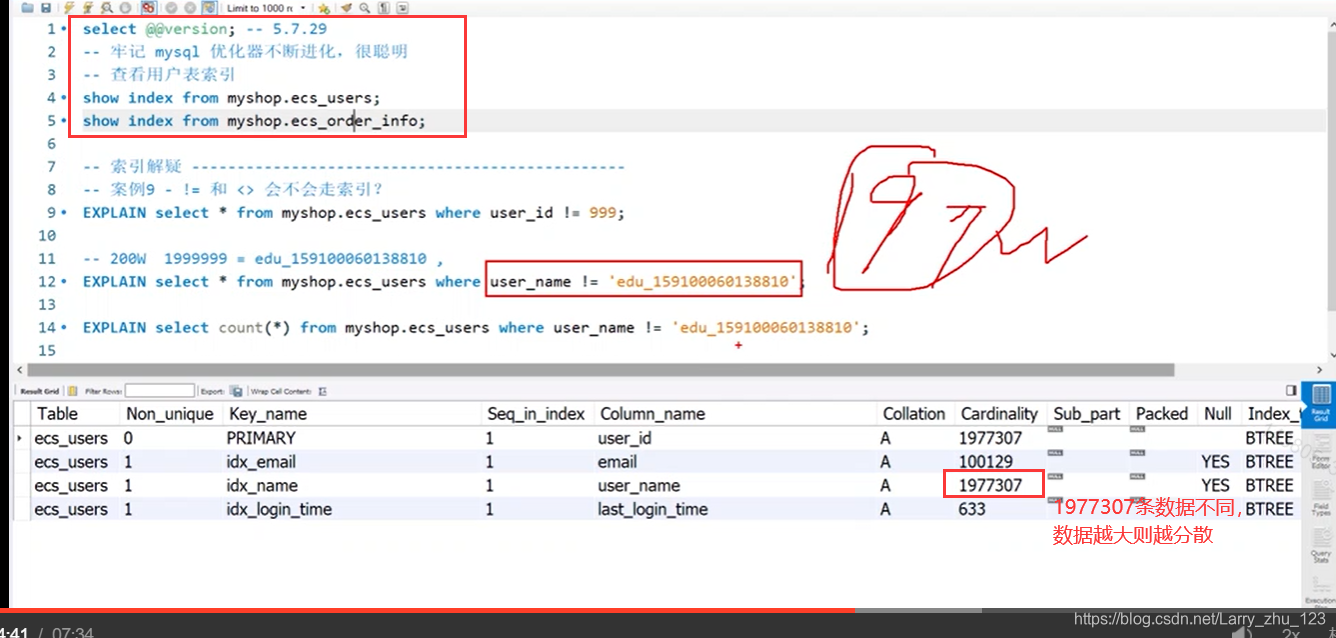
-- 案例9 - != 和 <> 会不会走索引?
select * from myshop.ecs_users where user_id != 999;--主键会走索引 ,主键比较特殊
select * from myshop.ecs_users where user_name != 'edu_159100060138810';--不走索引,user_name数据比较分散 加入100w的数据 查询一个不等于**的有可能需要查找99.8w次 等同于全表扫描
select count(*) from myshop.ecs_users where user_name != 'edu_159100060138810';--走索引因为count基本上都走索引
索引覆盖
-- 案例10 - 合理利用索引覆盖
SELECT * FROM myshop.ecs_users WHERE last_login_time >= 1591025358 limit 10000, 1000; --耗时0.15,用到索引但是需要回表查询信息。
SELECT user_id FROM myshop.ecs_users WHERE last_login_time >= 1591025358 limit 10000, 1000; --耗时0.016
用子查询还是表关联
-> 建议使用表关联 ,
-- 多表关联、子查询------------------------------------------
-- 需求:假设今天6.1日,查询最近20天 总消费金额 高于 3W 的 且近7天登录过用户信息
-- 注意: 第一次查询会非常慢,你的buffer_pool调大一点
SELECT count(*) FROM myshop.ecs_order_info where add_time >= 1590076800; -- 100W
SELECT count(*) FROM myshop.ecs_users where last_login_time >= 1590076800; -- 33W
-- 案例1 - 用子查询还是表关联?
SELECT
u.user_id, SUM(o.money_paid) pay
FROM
myshop.ecs_order_info o, myshop.ecs_users u
WHERE u.last_login_time >= 1590076800
AND o.add_time >= 1590076800
AND o.user_id = u.user_id
GROUP BY o.user_id
HAVING pay > 30000;
SELECT u.user_id, o.pay FROM
myshop.ecs_users u,
(
select user_id,SUM(money_paid) pay from myshop.ecs_order_info where add_time >= 1590076800
GROUP BY user_id HAVING pay > 30000
) o
where o.user_id = u.user_id
and u.last_login_time >= 1590076800;
表关联之大表小表
-> 大表小表先后顺序没有影响,是一样的执行顺序,mysql优化器是很智能的。
-- 案例2 - 大表关联小表,还是小表关联大表? -- 统计某个地区的订单
select r.region_name,count(o.order_id) from myshop.ecs_region r , myshop.ecs_order_info o
where r.region_id = o.province and o.add_time >= 1591025358 group by r.region_name;
select r.region_name,count(o.order_id) from myshop.ecs_order_info o , myshop.ecs_region r
where r.region_id = o.province and o.add_time >= 1591025358 group by r.region_name;
select r.region_name,count(o.order_id) from myshop.ecs_region r left join myshop.ecs_order_info o
on r.region_id = o.province where o.add_time >= 1591025358 group by r.region_name;
select r.region_name,count(o.order_id) from myshop.ecs_order_info o left join myshop.ecs_region r
on r.region_id = o.province where o.add_time >= 1591025358 group by r.region_name;
分页的玩法
-- 1. count(*) 解疑
select count(email) from myshop.ecs_users; -- 不统计null
select count(1) from myshop.ecs_users; -- 不解析内容 统计所有行
select count(*) from myshop.ecs_users; -- 标准SQL 有主键就查主键 统计所有行
-- 2. 分页(查你需要的字段,不要*)
select * from myshop.ecs_order_info order by order_id limit 1,100;
select * from myshop.ecs_order_info order by order_id limit 4000000,100;--很慢
-- 递增ID,连续不中断
select * from myshop.ecs_order_info o where o.order_id between 4000000 and 4000100;--很快
-- 递增ID, 不连续
select * from myshop.ecs_order_info o where o.order_id
>=
(select order_id from myshop.ecs_order_info order by order_id limit 4000000,1) limit 100;--很快
-- 无序读取
SELECT * FROM myshop.ecs_users u where u.last_login_time >= 1590076800 order by u.last_login_time,u.user_id limit 1, 10;
SELECT * FROM myshop.ecs_users u where u.last_login_time >= 1590076800 order by u.last_login_time,u.user_id limit 200000, 10;--很慢 虽然time有index 但是需要回表
-- 利用索引覆盖来优化上面的查询脚本
SELECT * FROM myshop.ecs_users u ,
(
SELECT user_id FROM myshop.ecs_users u where u.last_login_time >= 1590076800 order by u.last_login_time,u.user_id limit 200000, 10
) u1 where u1.user_id = u.user_id order by u.user_id;
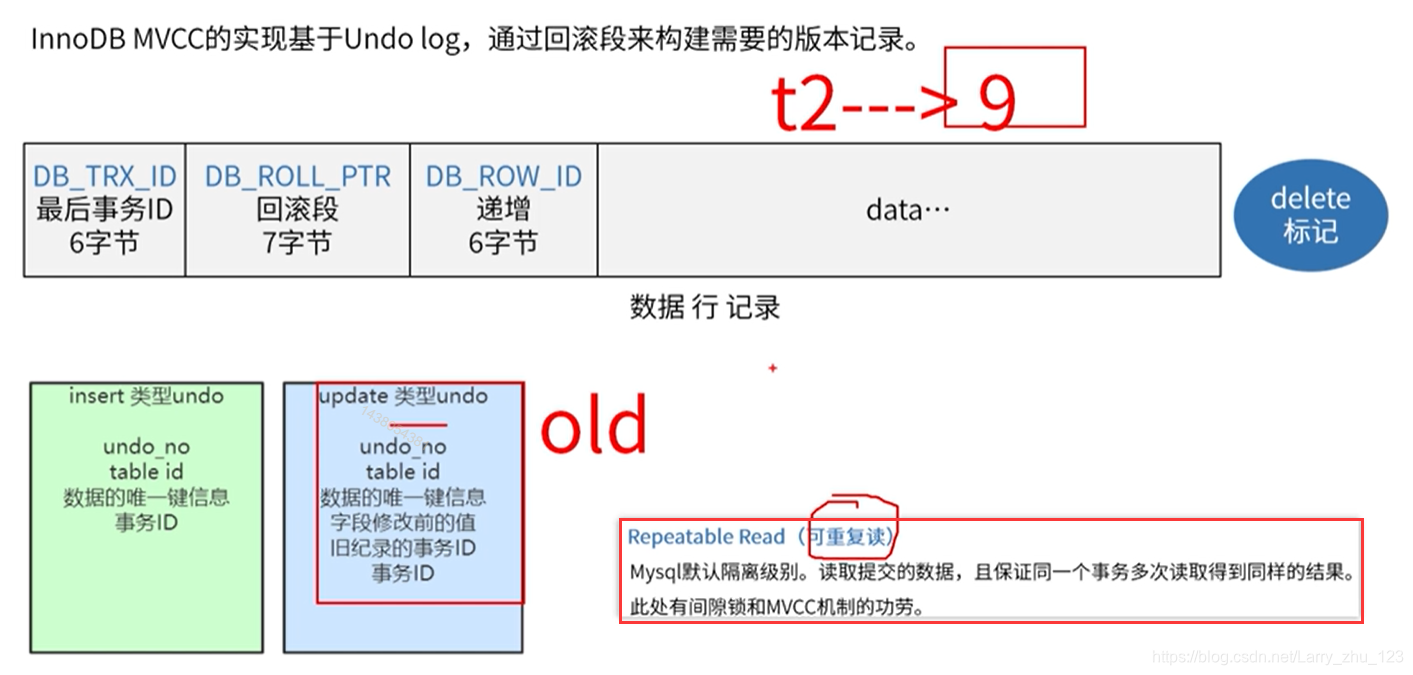
MVCC-多版本并发控制

InnoDB MVCC design
-> 每条记录都有3个隐形的字段,还未commit的数据都在undo log中,并用DB_ROLL_PTR和DB_TRX_ID做标记

二级索引的多版本设计

数据库锁机制
-- 创建测试数据库
create database if not exists demo_database default character set = 'utf8mb4';
use demo_database;
create table t01 (a int, b int, primary key(a));
create table t02 (a int, b int, primary key (a), key(b), foreign key(b) references t01(a));
create table t03 (a int, b int, primary key(a));
insert into t01 values (1,2), (2,3), (7,8);
insert into t02 values (1,2), (2,2), (3,7);
insert into t03 values (10,11),(12,13),(14,15);
术语简介

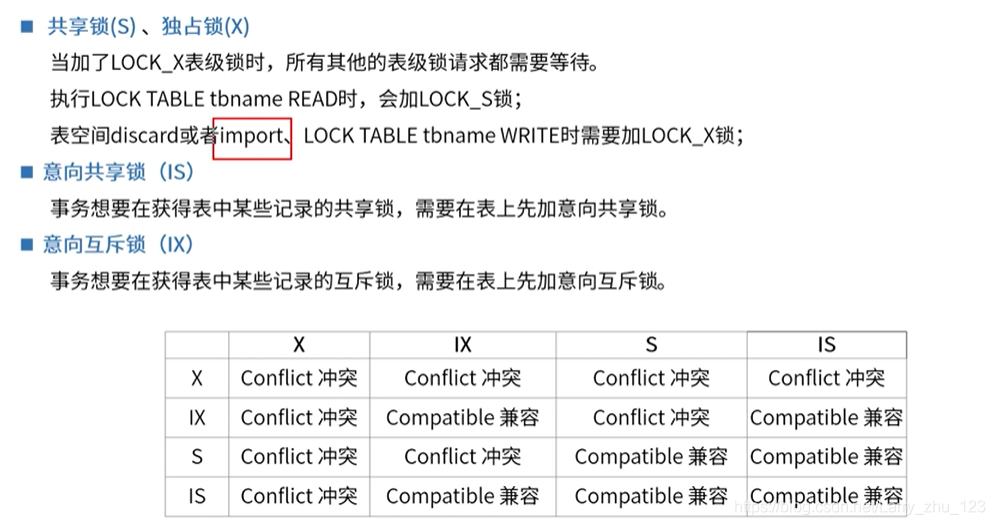
行锁之独占和共享
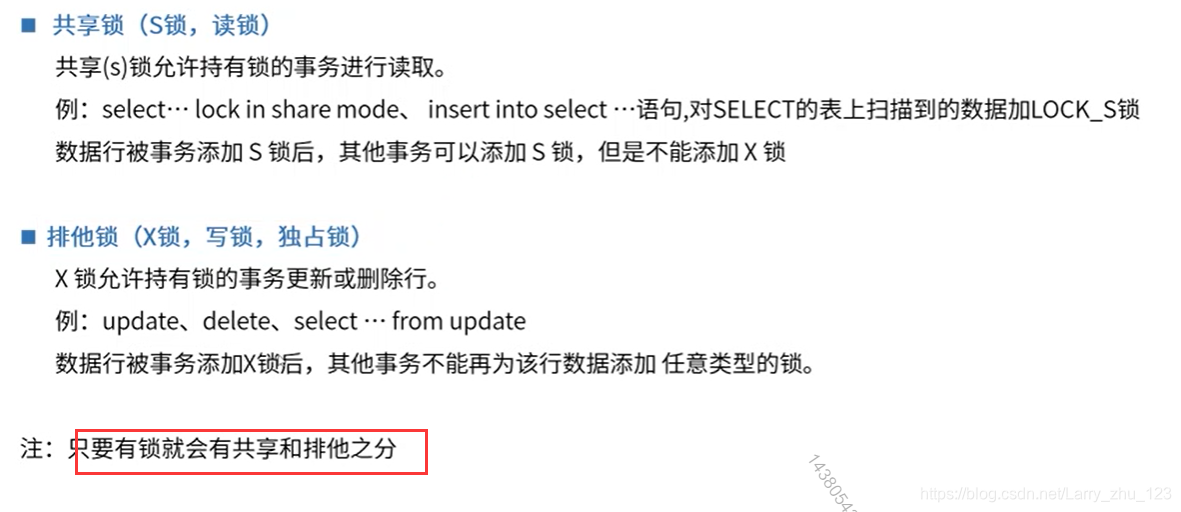
-- 1. 行共享锁、 排他锁(X锁,写锁,独占锁) ---------------------------------------------------------------------
-- 数据行被事务添加 S 锁后,其他事务可以添加 S 锁,但是不能添加 X 锁
-- select… lock in share mode;insert into select …语句,对SELECT的表上扫描到的数据加LOCK_S锁
-- X 锁允许持有锁的事务更新或删除行。例:update、delete、select … from update
-- 数据行被事务添加X锁后,其他事务不能再为该行数据添加 任意类型的锁。
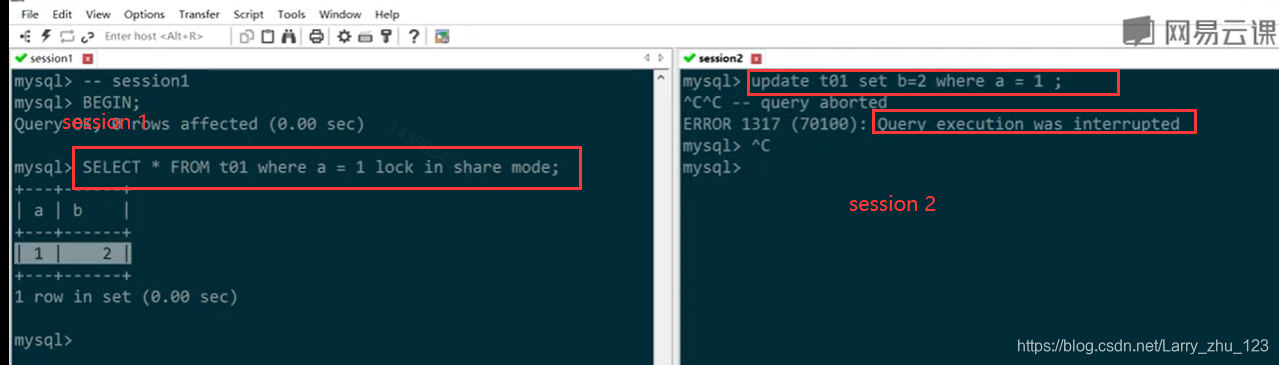
-- 示例1
-- session1
BEGIN;
SELECT * FROM t01 where a = 1 lock in share mode;
-- session2 阻塞直到session1事务完成
update t01 set b=2 where a = 1 ;
-- session1
ROLLBACK;
-- 示例2
-- session1
BEGIN;
insert into t01 select * from t03;--隐式的加了读锁
-- session2 阻塞直到session1事务完成
update t03 set b=13 where a = 10 ;
-- session1
ROLLBACK;
-- 示例3
-- session1
BEGIN;
SELECT * FROM t03 where a = 10 for update;
-- session2 阻塞直到session1事务完成
insert into t01 select * from t03;
-- session1
ROLLBACK;
间隙锁 NEXT-KEY 及插入意向锁

-- 2. 间隙锁 ---------------------------------------------------------------------
-- 单纯的间隙锁,【锁不存在的数据】
-- 【Innodb中的实现】NEXT-KEY锁,特殊的间隙锁实现,单记录锁和间隙锁的组合
-- 简单理解:锁定遍历过的范围,锁定遍历过的已存在记录
-- 特例:使用唯一特性的字段查询一行数据不使用间隙锁
-- 为啥叫NEXT-KEY?要查询出需要的N条数据,需要遍历N+1次;(一直找一直找,找到一条不满足条件的为止)
-- 【注意】把事务的隔离级别降级为读提交(Read Committed, RC),间隙锁则会自动失效
-- 示例1 - 间隙锁
-- session1 表面锁一条记录,实际遍历过的都锁了
BEGIN;
insert into t01 select * from t03;
-- session2 阻塞直到session1事务完成
BEGIN;
insert into t03 values (5,6);
-- session1
ROLLBACK;
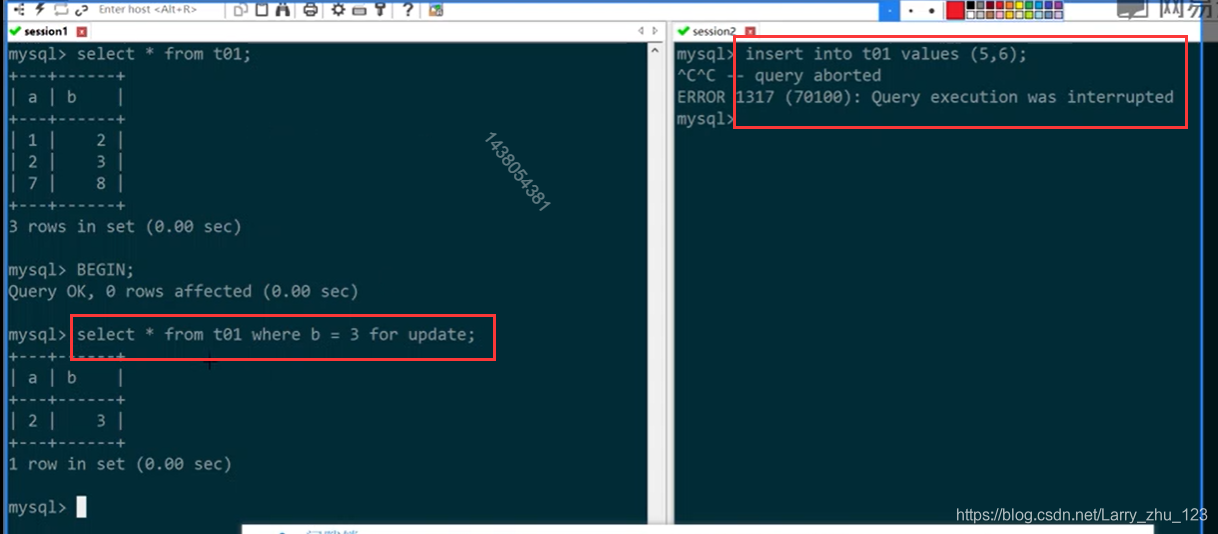
-- 示例2 - NEXT-KEY锁
-- session1 表面锁一条记录,实际遍历过的都锁了
BEGIN;
select * from t01 where b = 3 for update;
-- session2 阻塞直到session1事务完成
insert into t01 values (5,6);
-- session1
ROLLBACK;
-- 示例3 - NEXT-KEY锁 - update 主键 未锁定
-- session1
BEGIN;
update t01 set b = b where a = 7;
-- session2
BEGIN;
update t01 set b = b where a = 2;
-- session1
ROLLBACK;
-- session2
ROLLBACK;
-- 示例4 - NEXT-KEY锁 - update 看起来互不影响,实际锁了一大波
-- session1
BEGIN;
update t01 set b = b where b = 3;
-- session2 阻塞直到session1事务完成
BEGIN;
update t01 set b = b where b = 2;
-- session1
ROLLBACK;
-- session2
ROLLBACK;
###意向锁
-- 插入意向锁,间隙锁的一种,INSERT 操作在插入行之前设置的一种间隙锁
-- 多个事务,在同一个索引,同一个范围区间进行插入记录的时候,如果 插入的位置不冲突,不会阻塞彼此
-- 示例1 - 插入意向锁
-- session1
BEGIN;
update t01 set b = b where b = 3;
-- session2 阻塞直到session1事务完成
BEGIN;
insert into t01 values (5,4);
-- session1
ROLLBACK;
-- 示例2 - 插入意向锁
-- session1
BEGIN;
insert into t01 values (5,4);
-- session2 阻塞直到session1事务完成
BEGIN;
update t01 set b = b where b = 3;
-- session1
ROLLBACK;
-- 示例3 - 插入意向锁 - 冲突
-- session1
BEGIN;
insert into t01 values (5,4);
-- session2 阻塞直到session1事务完成
insert into t01 values (5,4);
-- session1
ROLLBACK;
-- 示例3 - 插入意向锁 - 非冲突
-- session1
BEGIN;
insert into t01 values (5,4);
-- session2
BEGIN;
insert into t01 values (6,4);
-- session1
ROLLBACK;
-- session2
ROLLBACK;
Predicate locks

表级锁
-- 创建测试数据库
create database if not exists demo_database default character set = 'utf8mb4';
use demo_database;
create table t04 (a int, b int, primary key(a));
create table t05 (a int, b int, primary key (a), key(b), foreign key(b) references t01(a));
create table t06 (a int NOT NULL AUTO_INCREMENT, b int, primary key(a)) ENGINE=InnoDB AUTO_INCREMENT=15;
insert into t04 values (1,2), (2,3), (7,8);
insert into t05 values (1,2), (2,2), (3,7);
Server层的MDL锁
表锁之独占和共享
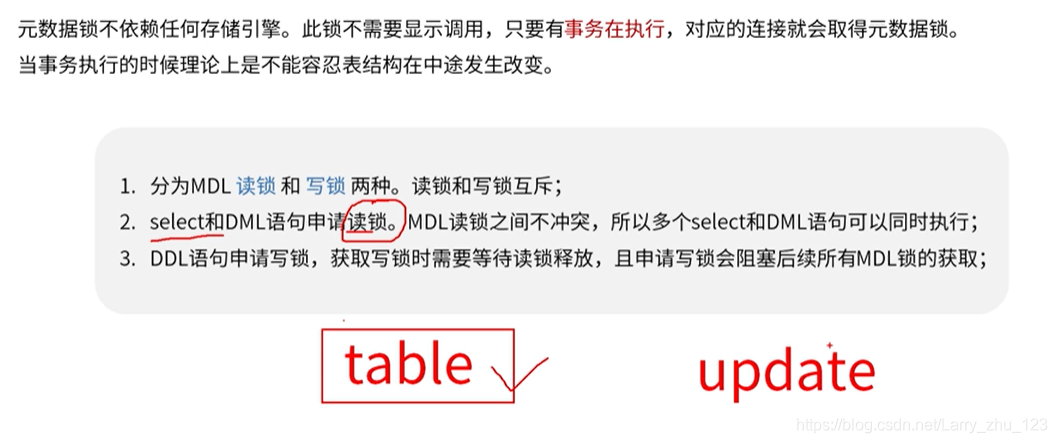
-- MDL 元数据锁,防止DDL和DML的并发冲突问题-----------------------------------------------------------------------
-- 分为MDL 读锁 和 写锁 两种。读锁和写锁互斥;
-- select和DML语句申请读锁。MDL读锁之间不冲突,所以多个select和DML语句可以同时执行;
-- DDL语句申请写锁,获取写锁时需要等待读锁释放,且申请写锁会阻塞后续所有MDL锁的获取;
-- 示例1
-- session1
BEGIN;
SELECT * FROM t04;
-- session2 阻塞直到session1事务完成
DROP TABLE t04;
-- session1
ROLLBACK;
-- session2
ROLLBACK;
-- 没有MDL锁可能出现 Table 'demo_database.t04' doesn't exist
-- 示例2
-- session1
BEGIN;
SELECT * FROM t06;
-- session2 阻塞直到session1事务完成
ALTER TABLE t06 ADD INDEX `idx_b` (`b` ASC);
-- session1
-- 表锁之独占和共享 ---------------------------------------------------------------------
-- 意向锁 意向锁的出现是为了Innodb更好的支持多粒度锁(避免加表锁时,逐个检查表中的行记录)。
-- 示例1 - S锁
-- session1
BEGIN;
LOCK TABLE t04 READ;
-- session2
BEGIN;
LOCK TABLE t04 WRITE;
-- session1
UNLOCK TABLES;
-- session2
UNLOCK TABLES;
-- 示例2 - 意向互斥锁锁
-- session1
BEGIN;
LOCK TABLE t04 WRITE;
-- session2
BEGIN;
insert into t04 values (9,10);
-- session1
UNLOCK TABLES;
-- session2
UNLOCK TABLES;
-- 【注意】事务结束不会自动释放锁, session结束会释放表锁
自增锁

-- 自增主键锁 ---------------------------------------------------------------------
-- 查看模式 ,要修改模式改配置文件重启..
select @@innodb_autoinc_lock_mode;
-- 示例1 【默认】模式1
-- session1
BEGIN;
insert into t06 values (null,2), (null,2);
select * from t06;
-- session2 阻塞直到session1事务完成
BEGIN;
insert into t06 values (null,2), (null,2);
select * from t06;
-- session1
ROLLBACK;
-- session2
ROLLBACK;
-- 【注意】 这个锁并非以事务单位,而是以SQL执行,意味着回滚后,生成的ID也就浪费了。
事务模型
Mysql中事务的隔离级别

READ UNCOMMITTED 读未提交
-- READ UNCOMMITTED 读未提交
-- 脏读、幻读、不可重复读
set session transaction isolation level READ UNCOMMITTED;
select @@session.tx_isolation; --查看事务的隔离级别
-- 示例1 - 脏读 - 读取到的数据是无效的
-- session1
BEGIN;
insert into t07 values (4,1000);
-- session2
BEGIN;
select * from t07;
-- session1
ROLLBACK;
-- session2
ROLLBACK;
READ COMMITTED 读已提交
-- READ COMMITTED 读已提交
-- 幻读、不可重复读
set session transaction isolation level READ COMMITTED;
select @@session.tx_isolation;
-- 示例1 - 幻读 - 读取到的数据是无效的
-- session1
BEGIN;
insert into t07 values (4,1000);
-- session2
BEGIN;
select * from t07;
-- session1
commit;
-- session2
select * from t07;

REPEATABLE READ 可重复读
set session transaction isolation level REPEATABLE READ;
select @@session.tx_isolation;
-- 示例1 -- 快照readview解决 select读
-- session1
BEGIN;
insert into t07 values (5,1000);
-- session2
BEGIN;
select * from t07;
-- session1
commit;
-- session2
select * from t07;
-- 示例2 - 间隙锁解决 DML语句的 幻读问题【异常示例】
-- session1
BEGIN;
insert into t07 values (10,1000);
-- session2
BEGIN;
select * from t07;
update t07 set balance=balance+1000;
-- session1
commit;
-- session2
select * from t07;
-- 示例2 - 间隙锁解决 DML语句的 幻读问题【正常示例】
-- session1
BEGIN;
select * from t07 for update;
-- session2
BEGIN;
insert into t07 values (10,1000);
-- session1
commit;
-- session2
update t07 set balance=balance+1000;
select * from t07;
SERIALIZABLE 序列化
串行不是事务一个一个的执行,而是更为严格的帮你加上锁 如查询的时候帮你加上share锁
-- 类似 REPEATABLE READ
set session transaction isolation level SERIALIZABLE;
select @@session.tx_isolation;
-- 示例1 - 告诉你..这玩意不是说事务一个个执行
-- session1
BEGIN;
update t07 set balance = balance where uid = 1;
-- session2
BEGIN;
update t07 set balance = balance where uid = 2;
-- session1
ROLLBACK;
-- session2
ROLLBACK;
-- 示例2 - 更严格的是,给一个普通的select也加了锁
-- session1 -- 普通查询转为 SELECT ... LOCK IN SHARE MODE
BEGIN;
select * from t07 where uid = 2;
-- session2
BEGIN;
update t07 set balance = balance where uid = 2;
-- session1
ROLLBACK;
-- session2
ROLLBACK;
数据变更注意事项
可能发生的问题
碰到表锁了
碰到行级锁了
事务执行太长了
数据量太大了
生产环境表结构
推荐工具: pt-online-schema-change

insert 导致的死锁
CREATE TABLE t20 (uid INT NOT NULL AUTO_INCREMENT,login_name VARCHAR(45) NOT NULL,age VARCHAR(45) NULL,
PRIMARY KEY (uid), UNIQUE INDEX `login_name_UNIQUE` (login_name ASC));
-- 示例2 - insert导致死锁
-- session1
BEGIN;
insert into t20 values (null,'tony',18);
-- session2 阻塞直到session1事务完成
BEGIN;
insert into t20 values (null,'tony',18);
-- session3 阻塞直到session1事务完成
BEGIN;
insert into t20 values (null,'tony',18);
-- session1
ROLLBACK;
update 导致的死锁
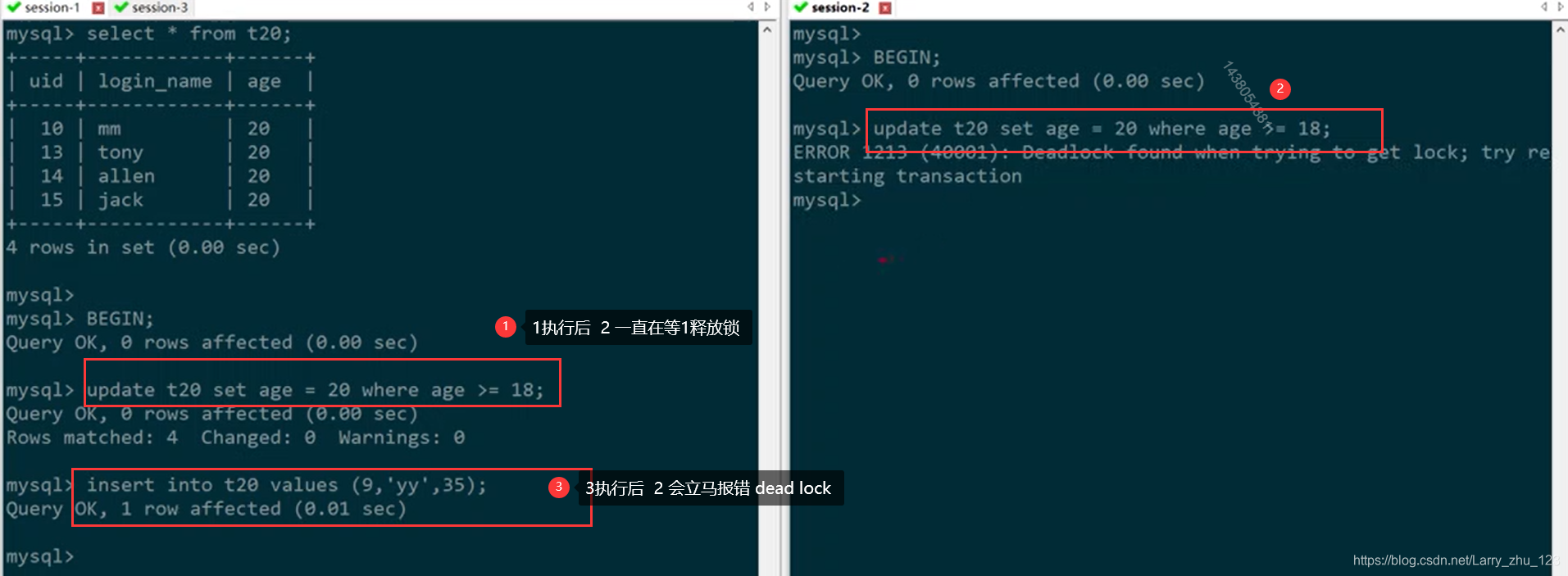
-- 示例3 - update导致死锁
-- session1
BEGIN;
update t20 set age = 20 where age >= 18;
-- session2 阻塞直到session1事务完成
BEGIN;
update t20 set age = 20 where age >= 18;
-- session1
insert into t20 values (9,'yy',35);
分区
分区表的概念
将表数据存储在不同的文件中,因为在操作系统中文件系统也是有大小限制的
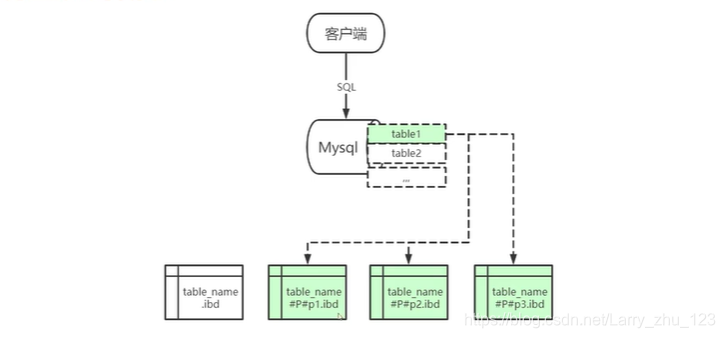
分区方式



分区表的好处

注意事项

手写DB-SimpleDB
http://www.cs.bc.edu/~sciore/
http://www.cs.bc.edu/~sciore/simpledb/
SimpleDB是由波士顿学院开发的,它与Amazon SimpleDB完全无关。
该系统仅用于教学用途。
SimpleDB是用Java编写的多用户事务数据库服务器,它通过JDBC与Java客户端程序进行交互。
对应的教材
https://www.amazon.com/Database-Design-Implementation-Edward-Sciore/dp/0471757160
-
先运行 数据库服务器
-
再运行CreateStudentDB 创建测试表和数据
-
再运行 SelectMajors.java 测试
注意: simpleclient 依赖 simpledb 项目,开发工具中记得配置依赖关系
总结
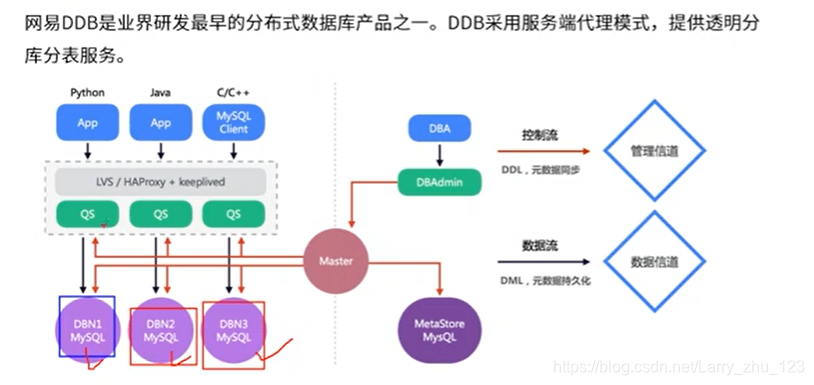
网易数据库结构
应用通过QS访问数据 ,不知道具体的数据到底在哪个库里面。市场上开源的有mycat ,sharding jdbc, apacher shardingSphere


















 5055
5055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









