






SELECT 语句用法:
SELECT基本语法:
SELECT {*, column [alias],...} FROM table;SELECT语句中的算术表达式:
对数值型数据列、变量、常量可以使用算数操作符创建表达式(
+ - *
/
)
对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(
+ -
)
NULL值的使用:
安全等于'<=>'用于判断是否是NULL,也可以作为普通的运算符'='
定义字段的别名:
SELECT 列名 as 别名(列名 别名)
重复记录:
使用DISTINCT关键字可从查询结果中清除重复行
SELECT DISTINCT 列名 FROM 数据表名;
限制所选择的记录:
使用WHERE子句限定返回的记录
WHERE子句在FROM 子句后
SELECT {*, column [alias], ...} FROM table [WHEREcondition(s)];
WHERE中的字符串和日期要用单引号扩起来where语句中的运算符
BETWEEN运算符显示某一值域范围的记录
WHERE a BETWEEN 1 AND 5;
使用IN运算符获得匹配列表值的记录
WHERE a IN (1,2,3);
使用LIKE运算符
使用LIKE运算符执行模糊查询
查询条件可包含文字字符或数字
(%) 可表示零或多个字符
( _ ) 可表示一个字符
使用IS NULL运算符
查询包含空值的记录
逻辑运算符
使用AND运算符
AND需要所有条件都是true
使用OR运算符
OR只要两个条件满足一个就可以
使用NOT运算符
NOT是取反的意思
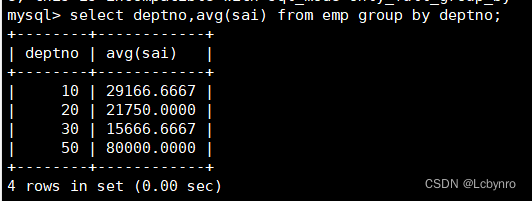
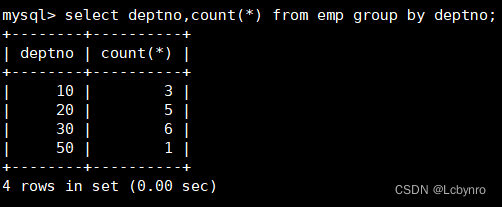
数据分组
GROUP BY
子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组。
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。
分组函数忽略空值
。
结果集隐式按升序排列
,
如果需要改变排序方式可以使用ORDER BY
子句。
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BYcolumn];
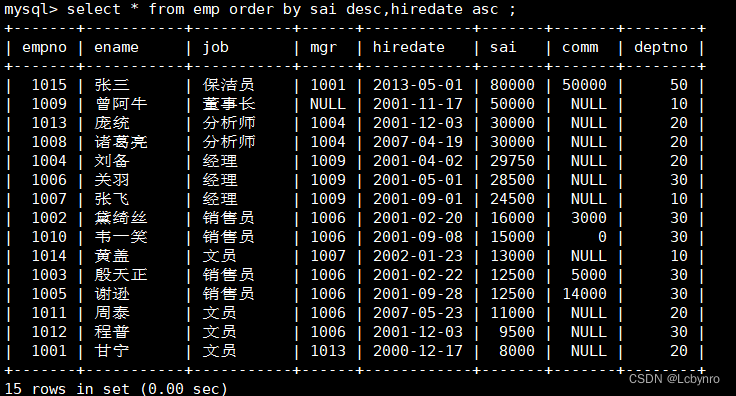
排序
order by 列名[desc],列名…
设定排序列的时候可采用列名、列序号和列别名
如果按多列排序,每列的asc,desc必须单独设定
HAVING子句用来对分组后的结果再进行条件过滤。
分组函数重要规则
如果使用了分组函数,或者使用GROUP BY 的查询:出现在SELECT列表中的字段,要么出现在组合函数
里,要么出现在GROUP BY 子句中。GROUP BY 子句的字段可以不出现在SELECT列表当中。
HAVING与WHERE的区别
WHERE是在分组前进行条件过滤, HAVING子句是在分组后进行条件过滤,WHERE子句中不能使用聚合函
数,HAVING子句可以使用聚合函数。多表关联查询
inner join:代表选择的是两个表的交差部分。
内连接就是表间的主键与外键相连,只取得键值一致的,可以获取双方表中的数据连接方式。语法如下:
SELECT 列名1,列名2... FROM 表1 INNER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
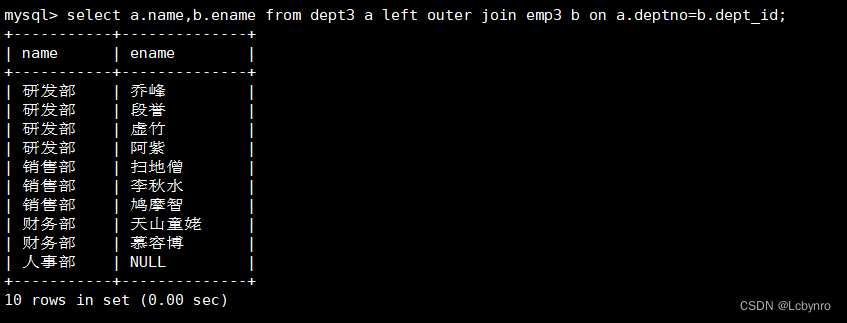
left join:代表选择的是前面一个表的全部。
左连接是以左表为标准,只查询在左边表中存在的数据,当然需要两个表中的键值一致。语法如下:
SELECT 列名1 FROM 表1 LEFT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
right join:代表选择的是后面一个表的全部
同理,右连接将会以右边作为基准,进行检索。语法如下:
SELECT 列名1 FROM 表1 RIGHT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
自连接顾名思义就是自己跟自己连接,参与连接的表都是同一张表。(通过给表取别名虚拟出)
单表查询

创建表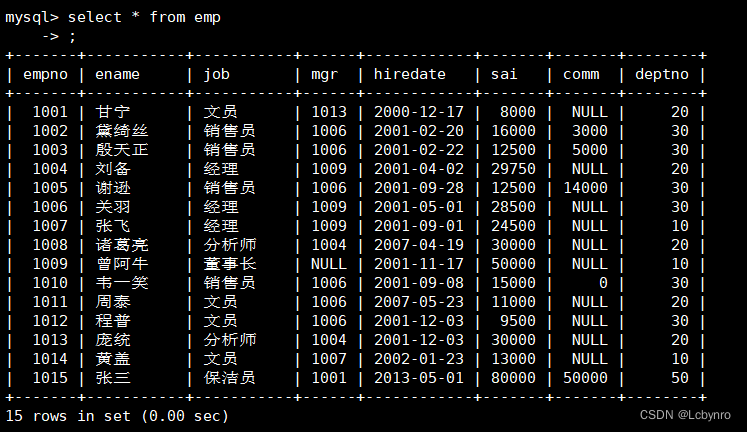
(1)
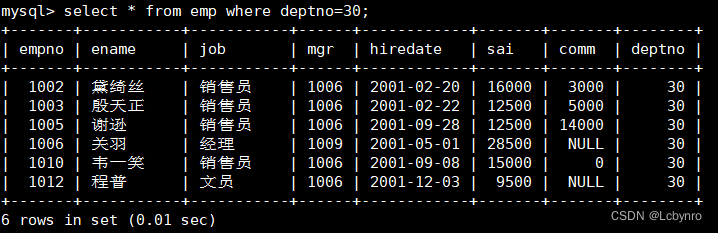
(2)
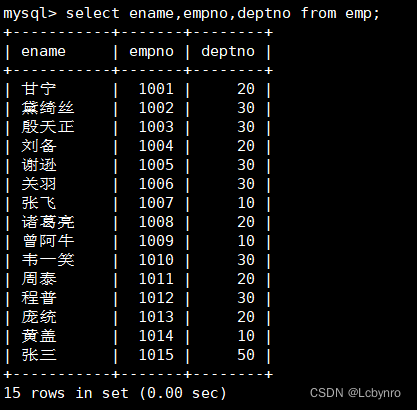
(3)
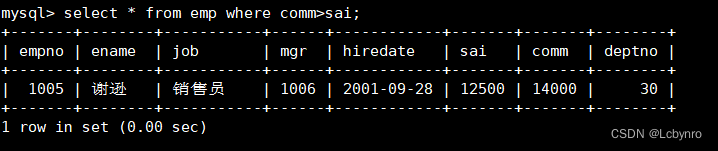
(4)

(5)

(6)

(7)
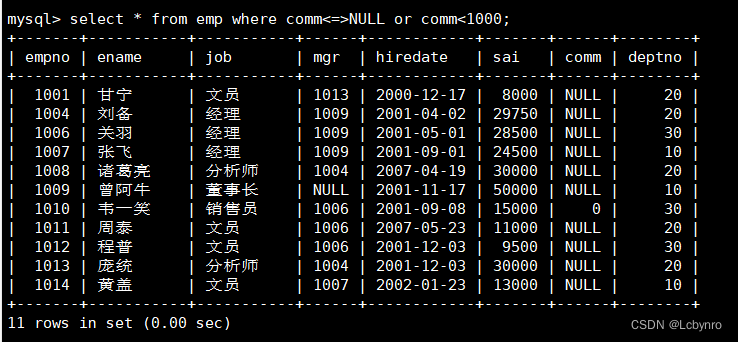
(8)
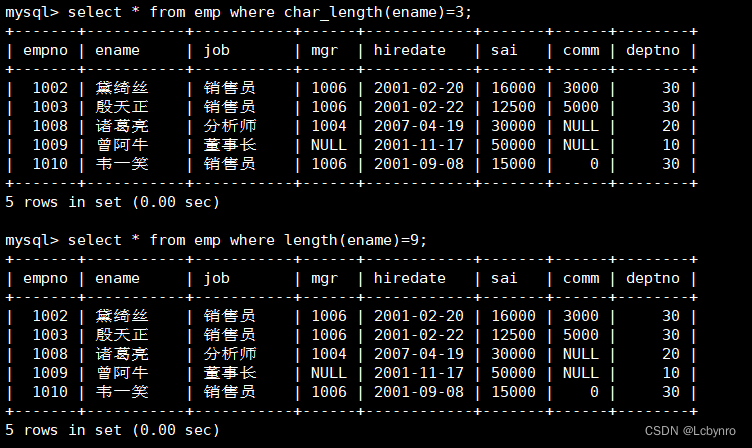
(9)
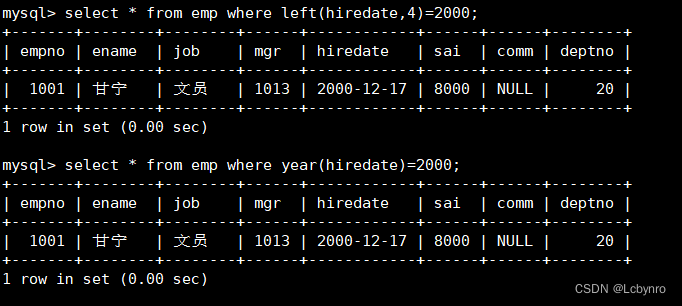
(10)
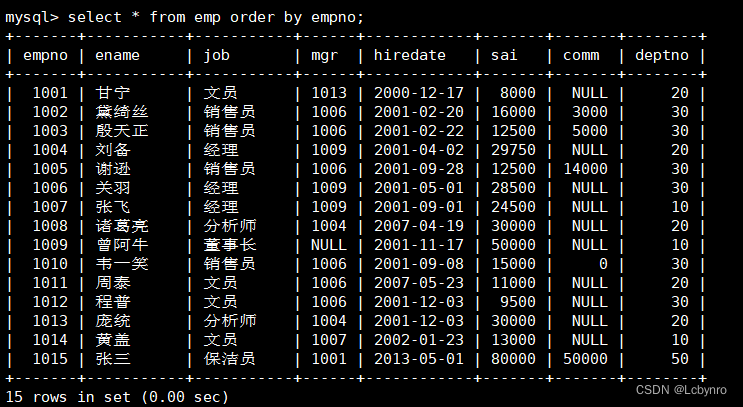
(11)
(12)
(13)
(14)

多表查询

(1)
(2)
(3)

(4)

(5)
















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









