










1 简介
最近在做一项课题,涉及到建筑足迹(Building footprints)数据。所以想看看现在比较常用的都有什么产品。
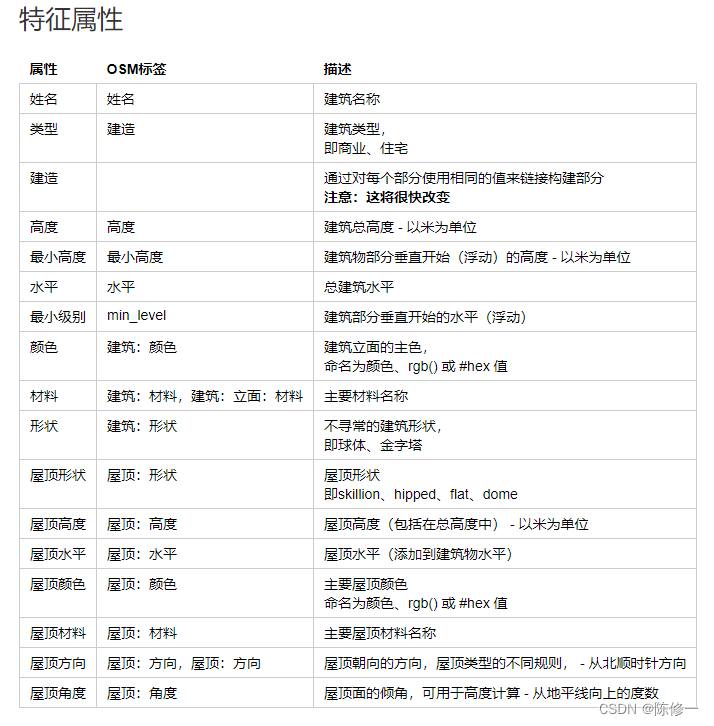
目前查到的比较权威的有微软的和谷歌的,虽然以上两个数据的覆盖率都挺全的,但是无奈几乎都只有图形信息,没有其他字段。所以我还找到了OSM建筑数据作为补充,OSM数据虽然遗漏的建筑比较多,但有比较丰富的字段信息,如下。
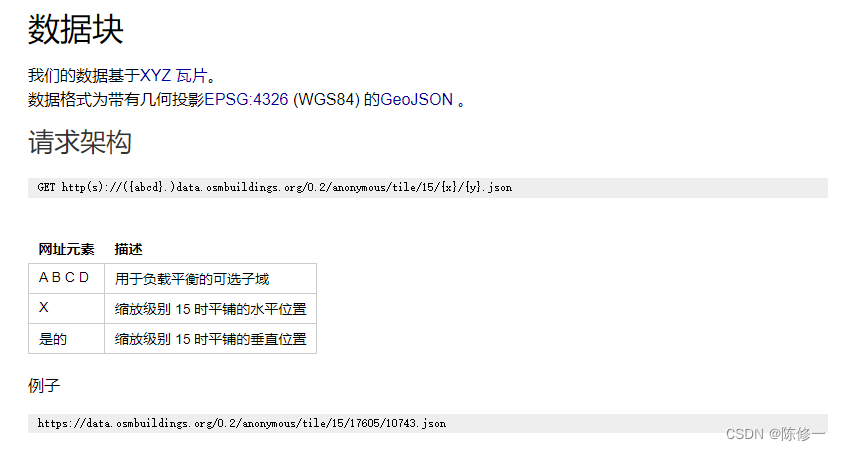
比较麻烦的是,OSM建筑数据不是一键下载的,而是geojson的瓦片数据。但还好它提供了url。
所以,这篇文章的任务就是写一个代码,下载指定位置的OSM建筑数据并转化为常用的shp格式。
2 效果展示
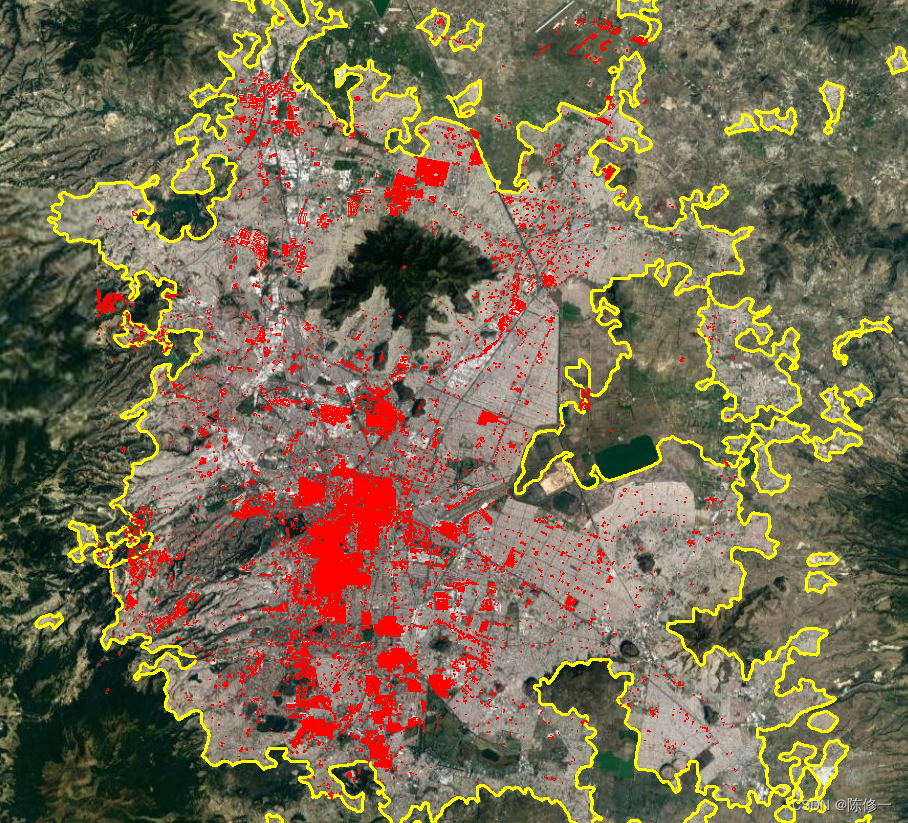
为了让大家看下去,先放出效果预览图。
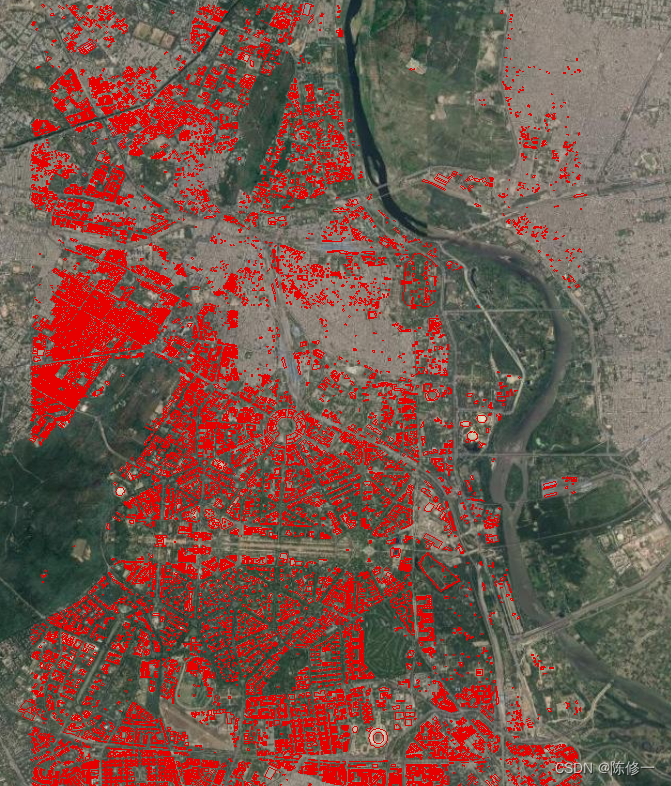
以下是我爬取并拼接的墨西哥的墨西哥城的建筑数据,共有18+万条。底图是google地图,黄色是宫鹏老师它们团队做的GUB城市边界数据,红色的才是我爬取到的建筑数据,可以看到覆盖度并不是很好(主要还是图它的字段信息)。
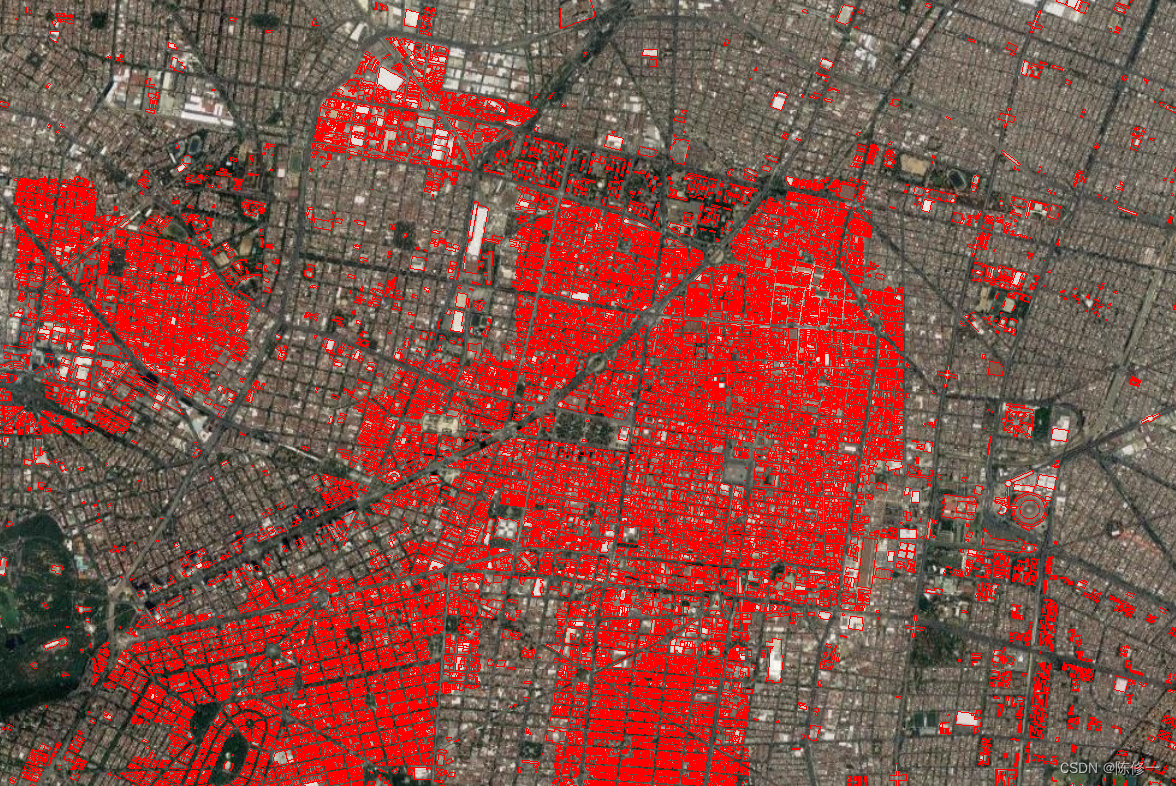
以下是大比例尺下的细节图。
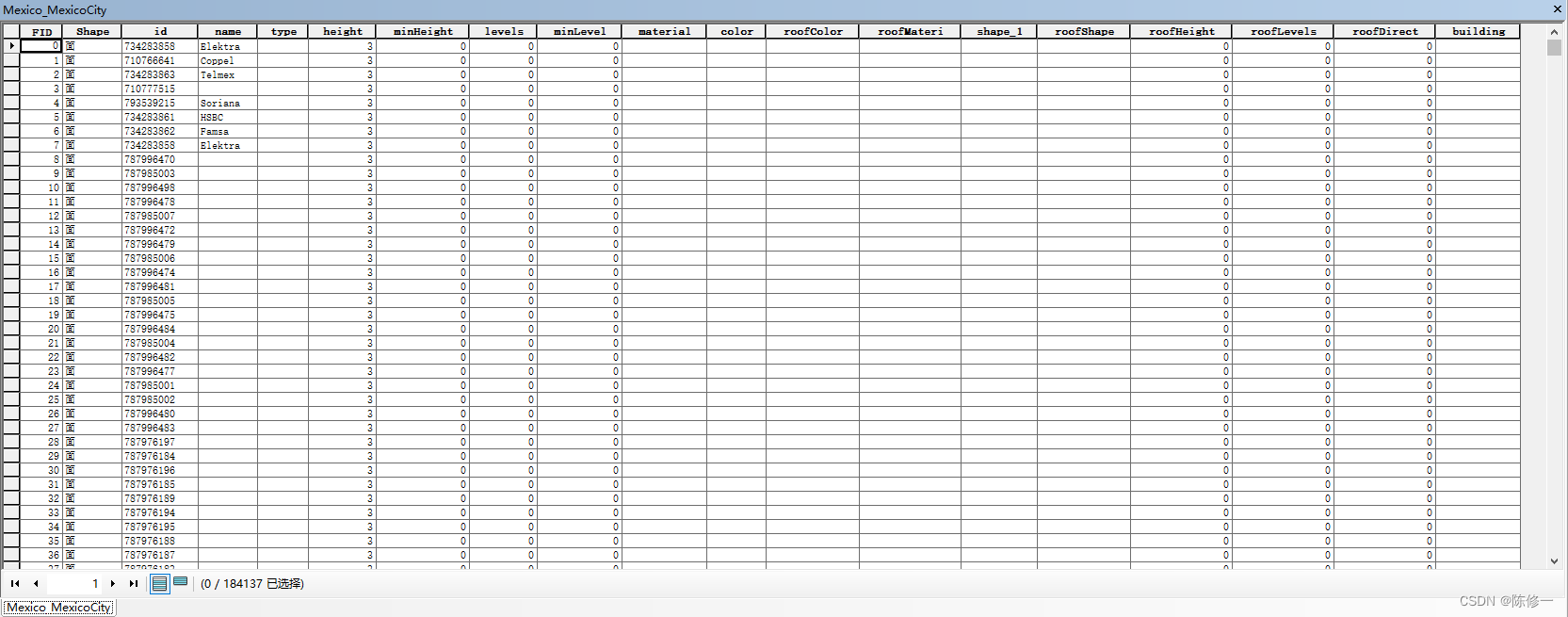
以下是属性表。
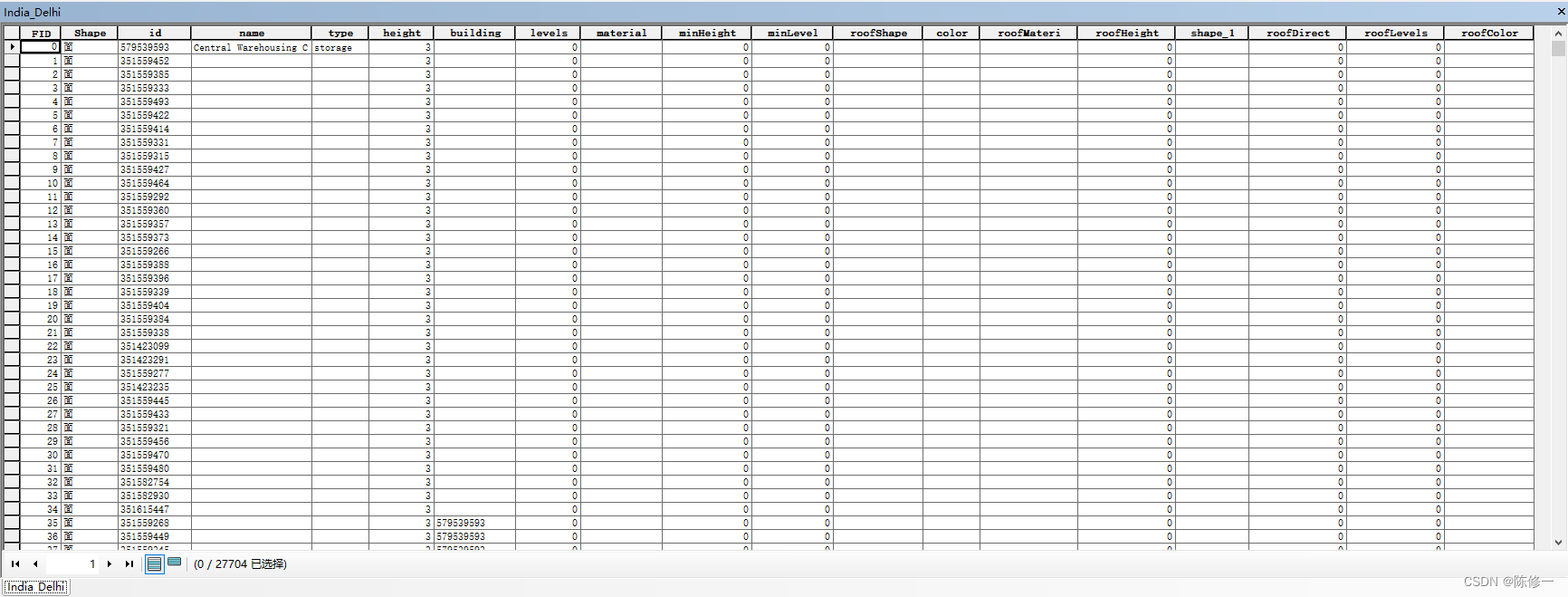
为了防止有些同学看不懂,这里再展示一个例子。以下是印度的德里地区,共2.7w条数据。

3 思路及代码
如何实现上述效果?先捋一捋思路。
- 通过经纬度爬取想要获取的瓦片
瓦片数据不难理解,就是把地图切割成一块一块的矩形,瓦片数据有三个特征信息(即xyz),x和y可以理解为在坐标轴中的位置,z可以理解为选用哪种级别的坐标轴。←我说得不是太清楚,具体还是请查阅相关资料吧。总之瓦片的xyz信息是和经纬度相对应的,就是说可以和经纬度相互转换,知道这个就行了。
OSM用的瓦片xyz是比较通用的,和谷歌地图和天地图是相通的(顺便提一嘴,百度地图比较非主流),所以可以直接套用别人的经纬度转xyz和xyz转经纬度的代码。刚好之前在github里找到一位大哥(这位大哥的工作是将瓦片数据组合为geotif,大家也可以看看,很有用)提供了相关的代码。
class Point:
def __init__(self, lon, lat):
self.lon = lon
self.lat = lat
# 下载
def download(x, y, path):
tile_path = f"{path}//{x}/{y}.geojson"
if not os.path.exists(tile_path): # 如果本地没有,那就下载
# 下载
url = f"https://data.osmbuildings.org/0.2/anonymous/tile/15/{x}/{y}.json"
# print(f"正在下载... {url}")
response = requests.get(url)
path_dir = f"{path}//{x}"
if not os.path.exists(path_dir): # 如果没有上级目录就创建
os.makedirs(path_dir)
if response.status_code == 200:
with open(tile_path, "w", encoding='utf-8') as f:
f.write(response.text) # 写入
# print("成功")
else:
# pass
print(f"network error! {url}")
# xyz转经纬度
def xyz2lonlat(x, y, z):
n = math.pow(2, z)
lon = x / n * 360.0 - 180.0
lat = math.atan(math.sinh(math.pi * (1 - 2 * y / n)))
lat = lat * 180.0 / math.pi
return lon, lat
# 经纬度转xyz
def lonlat2xyz(lon, lat, zoom):
n = math.pow(2, zoom)
x = ((lon + 180) / 360) * n
y = (1 - (math.log(math.tan(math.radians(lat)) + (1 / math.cos(math.radians(lat)))) / math.pi)) / 2 * n
return int(x), int(y)
def cal_tiff_box(x1, y1, x2, y2, z):
LT = xyz2lonlat(x1, y1, z)
RB = xyz2lonlat(x2 + 1, y2 + 1, z)
return Point(LT[0], LT[1]), Point(RB[0], RB[1])
-
合并多个瓦片
照OSM网页中的说明,爬取到的数据是geojson数据,也就是一个字典的列表。那问题就很简单了,直接把列表合并就行了。 -
将geojson转为shp
直接套用geopandas里现成的代码。
2和3的代码我合在一起写了。
# geojson转shp
def geojson_to_shp(geojson_path, shp_path):
data = gpd.read_file(geojson_path)
data.to_file(shp_path, driver='ESRI Shapefile', encoding='utf-8')
# 合并多个geojson并转shp
def merge_json_to_shp(west_lon, south_lat, east_lon, north_lat, shp_path):
# 投影到瓦片
z = 15
point_lt = Point(float(west_lon), float(north_lat))
point_rb = Point(float(east_lon), float(south_lat))
x1, y1 = lonlat2xyz(point_lt.lon, point_lt.lat, z)
x2, y2 = lonlat2xyz(point_rb.lon, point_rb.lat, z)
# 遍历并存储为geojson
features = []
for i in range(x1, x2+1):
for j in range(y1, y2+1):
geojson_path = f"D://GeoData//OSM_Buildings//data//{i}//{j}.geojson" # 瓦片存储的目录,如果有现成的瓦片就省得二次下载了————改成你自己的目录
# print(geojson_path)
if os.path.exists(geojson_path):
try:
f = open(geojson_path, "r", encoding='utf-8') # 读取
geojson_content = f.read()
geojson_content = json.loads(geojson_content)
features.extend(geojson_content["features"])
f.close()
except:
print(f"{geojson_path} 文件出错!!!")
else:
print(f"x={i}, y={j} 不存在")
print(f"共有 {len(features)} 个要素")
print("正在存储为.geojson...")
with open(shp_path+".geojson", "w") as f:
geojson_content["features"] = features
f.write(json.dumps(geojson_content)) # 写入
# 转为shp并存储
print("正在存储为.shp...")
geojson_to_shp(shp_path+".geojson", shp_path)
最后加一个主函数。
def start(west_lon, south_lat, east_lon, north_lat, shp_path, z=15):
print(west_lon, south_lat, east_lon, north_lat) # 四角经纬度
path = r"D:\GeoData\OSM_Buildings\data" # 改成你自己的目录
# 投影到瓦片
point_lt = Point(float(west_lon), float(north_lat))
point_rb = Point(float(east_lon), float(south_lat))
x1, y1 = lonlat2xyz(point_lt.lon, point_lt.lat, z)
x2, y2 = lonlat2xyz(point_rb.lon, point_rb.lat, z)
# 计算任务数量/爬取景数
count = 0
all = (x2-x1+1) * (y2-y1+1)
print(all) # 输出总任务数量
# 逐景爬取
for i in range(x1, x2+1):
for j in range(y1, y2+1):
flag = 0
reconnect = 0
# 报错重连
while flag == 0:
try:
download(i, j, path)
flag = 1
except:
print(f"{count+1}/{all} 出现异常,正在尝试恢复...") # 计数
reconnect += 1
if reconnect >= 5:
time.sleep(120*reconnect)
time.sleep(10)
pass
count += 1
# 每50景输出当前进程
if count%50 == 0:
print(f"{count}/{all}") # 计数
# 输出实际爬取的经纬度空间范围
lt, rb = cal_tiff_box(x1, y1, x2, y2, z)
print([lt.lon, lt.lat, rb.lon, rb.lat], "瓦片获取完成\n\n")
# 存储为.shp
if not os.path.exists(shp_path):
merge_json_to_shp(west_lon, south_lat, east_lon, north_lat, shp_path)
print(shp_path)
print("全部完成!!!\n\n\n")
3 完整代码
import math
import os
import requests
import geopandas as gpd
import numpy as np
import json
import time
class Point:
def __init__(self, lon, lat):
self.lon = lon
self.lat = lat
# 下载
def download(x, y, path):
tile_path = f"{path}//{x}/{y}.geojson"
if not os.path.exists(tile_path): # 如果本地没有,那就下载
# 下载
url = f"https://data.osmbuildings.org/0.2/anonymous/tile/15/{x}/{y}.json"
# print(f"正在下载... {url}")
response = requests.get(url)
path_dir = f"{path}//{x}"
if not os.path.exists(path_dir): # 如果没有上级目录就创建
os.makedirs(path_dir)
if response.status_code == 200:
with open(tile_path, "w", encoding='utf-8') as f:
f.write(response.text) # 写入
# print("成功")
else:
# pass
print(f"network error! {url}")
# xyz转经纬度
def xyz2lonlat(x, y, z):
n = math.pow(2, z)
lon = x / n * 360.0 - 180.0
lat = math.atan(math.sinh(math.pi * (1 - 2 * y / n)))
lat = lat * 180.0 / math.pi
return lon, lat
# 经纬度转xyz
def lonlat2xyz(lon, lat, zoom):
n = math.pow(2, zoom)
x = ((lon + 180) / 360) * n
y = (1 - (math.log(math.tan(math.radians(lat)) + (1 / math.cos(math.radians(lat)))) / math.pi)) / 2 * n
return int(x), int(y)
def cal_tiff_box(x1, y1, x2, y2, z):
LT = xyz2lonlat(x1, y1, z)
RB = xyz2lonlat(x2 + 1, y2 + 1, z)
return Point(LT[0], LT[1]), Point(RB[0], RB[1])
# geojson转shp
def geojson_to_shp(geojson_path, shp_path):
data = gpd.read_file(geojson_path)
data.to_file(shp_path, driver='ESRI Shapefile', encoding='utf-8')
# 合并多个geojson并转shp
def merge_json_to_shp(west_lon, south_lat, east_lon, north_lat, shp_path):
# 投影到瓦片
z = 15
point_lt = Point(float(west_lon), float(north_lat))
point_rb = Point(float(east_lon), float(south_lat))
x1, y1 = lonlat2xyz(point_lt.lon, point_lt.lat, z)
x2, y2 = lonlat2xyz(point_rb.lon, point_rb.lat, z)
# 遍历并存储为geojson
features = []
for i in range(x1, x2+1):
for j in range(y1, y2+1):
geojson_path = f"D://GeoData//OSM_Buildings//data//{i}//{j}.geojson" # 瓦片存储的目录,如果有现成的瓦片就省得二次下载了————改成你自己的目录
# print(geojson_path)
if os.path.exists(geojson_path):
try:
f = open(geojson_path, "r", encoding='utf-8') # 读取
geojson_content = f.read()
geojson_content = json.loads(geojson_content)
features.extend(geojson_content["features"])
f.close()
except:
print(f"{geojson_path} 文件出错!!!")
else:
print(f"x={i}, y={j} 不存在")
print(f"共有 {len(features)} 个要素")
print("正在存储为.geojson...")
with open(shp_path+".geojson", "w") as f:
geojson_content["features"] = features
f.write(json.dumps(geojson_content)) # 写入
# 转为shp并存储
print("正在存储为.shp...")
geojson_to_shp(shp_path+".geojson", shp_path)
def start(west_lon, south_lat, east_lon, north_lat, shp_path, z=15):
print(west_lon, south_lat, east_lon, north_lat) # 四角经纬度
path = r"D:\GeoData\OSM_Buildings\data" # 改成你自己的目录
# 投影到瓦片
point_lt = Point(float(west_lon), float(north_lat))
point_rb = Point(float(east_lon), float(south_lat))
x1, y1 = lonlat2xyz(point_lt.lon, point_lt.lat, z)
x2, y2 = lonlat2xyz(point_rb.lon, point_rb.lat, z)
# 计算任务数量/爬取景数
count = 0
all = (x2-x1+1) * (y2-y1+1)
print(all) # 输出总任务数量
# 逐景爬取
for i in range(x1, x2+1):
for j in range(y1, y2+1):
flag = 0
reconnect = 0
# 报错重连
while flag == 0:
try:
download(i, j, path)
flag = 1
except:
print(f"{count+1}/{all} 出现异常,正在尝试恢复...") # 计数
reconnect += 1
if reconnect >= 5:
time.sleep(120*reconnect)
time.sleep(10)
pass
count += 1
# 每50景输出当前进程
if count%50 == 0:
print(f"{count}/{all}") # 计数
# 输出实际爬取的经纬度空间范围
lt, rb = cal_tiff_box(x1, y1, x2, y2, z)
print([lt.lon, lt.lat, rb.lon, rb.lat], "瓦片获取完成\n\n")
# 存储为.shp
if not os.path.exists(shp_path):
merge_json_to_shp(west_lon, south_lat, east_lon, north_lat, shp_path)
print(shp_path)
print("全部完成!!!\n\n\n")
上面都是函数,那么如何运行呢?这里需要用主函数start( ),里面有五个参数需要填,前两个参数是左下角的经纬度,三四个参数是右上角的经纬度,第五个参数是你的geojson和shp文件的输出路径。
以墨西哥城和德里为例:
start(-99.316, 19.248, -98.900, 19.756, r'D:\GeoData\OSM_Buildings\data\123\Mexico_MexicoCity')
start(77.189, 28.580, 77.256, 28.691, r'D:\GeoData\OSM_Buildings\data\123\India_Delhi')
4 一些说明
代码里涉及本地目的的地方需要更改,是瓦片存储的地方,瓦片仍以瓦片的形式存储在本地目录里。
启动下载后会优先查看本地目录里是否存在瓦片,如果存在那就不重新下载了,这样做的好处是节省了下载时间。
如果有精力,可以一口气跑完全球的数据,以后直接启动调用就可以生成任何地方的shp了。
-----------------------分割线(以下是乞讨内容)-----------------------


















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









