









1 简介
两个月前师姐替别人问我一个问题,

当时仅仅只是会使用界面化的fragstats,再加上搜遍全网也没搜到使用python进行批量景观指数计算的方法,因此没能很好地回答师姐朋友的问题,但是还是通过检索推荐了一些材料(材料1,材料2),感兴趣的同学们可以参考一下。
后来在做一个课题时(景观层面的指标计算),我自己也要使用大规模的fragstats运算,才花点时间好好静下心来研究这个题目所提到的内容。
这应该是第一个使用python调用fragstats批量进行万级及以上数据的景观指数运算的代码教程,并且在博文的末尾还提供了0代码的傻瓜解决方案(可以直接跳转到本文第4节)(但是我建议大家看完全文再寻求傻瓜方案,或者至少熟悉界面化的fragstats操作)。
开始说正题——
重点——本文针对的场景是:已经通过arcgis或其他方法制作了渔网(fishnet)并且把一个tif根据渔网格网分裂成成千上万个带编号的小方格tif集,本文的目标在于接下来计算这些带编号的小方格tif集的各种景观指数。在这里,本文假设同学们已经会使用界面化的fragstats,并且会制作批量景观计算的fbt脚本文件(也就是import batch需要导入的文件)。
本文思路在于:
1,为了解决fragstats这个软件原生性的问题,即单个过大脚本容易报错,所以要切割拆分脚本,将其分割成多个批量任务进行景观指数计算;
2,可以通过python调用cmd再调用fragstats的frg.exe文件计算景观指数(关于cmd调用fragstats可以看这篇博文),从而实现自动完成多个批量任务(注意,这里是批量完成批量脚本任务,即批量的批量)。
因此,本文包括以下两部分:
1,拆分批量运算的脚本文件(默认为fbt文件,但本文中为了方便使用csv格式的脚本);
2,根据脚本文件集批量计算景观指数。
2 拆分和合并脚本文件
在这里已经假设了各位同学知道脚本文件的构成并且知道如何制作批量运算脚本文件,所以不多赘述。如果有不清楚的可以参考这篇博文。
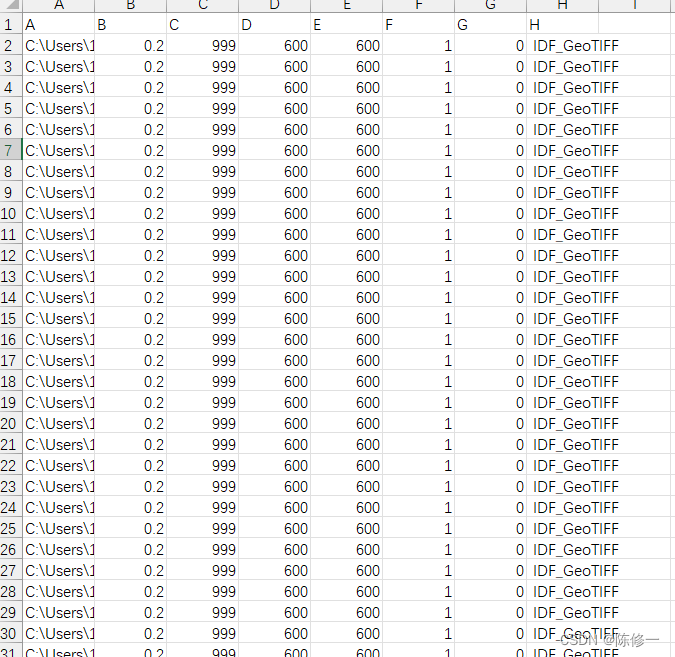
我的其中一个脚本文件长下面这个样子,我为了方便存成csv格式的,当然你要存txt或者默认的fbt都行,只需要稍微修改一下我后面要提到的代码。
然后我使用代码将它分裂成30个(只展示其中一部分)。
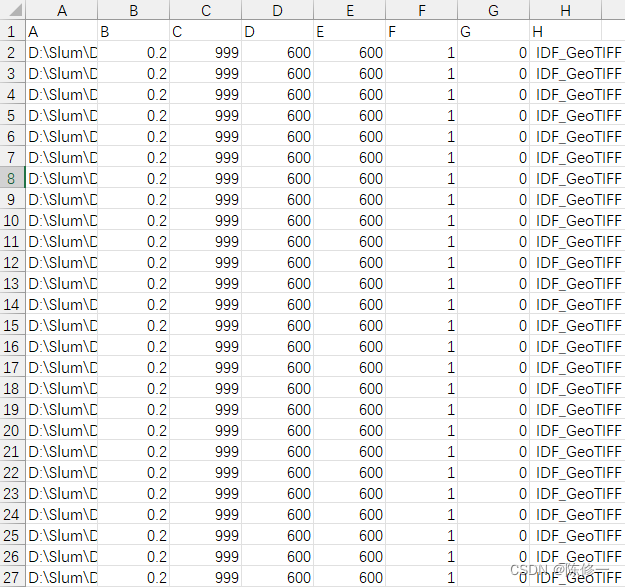
然后。。然后就没了。。
但是关键的来了,下面是代码,要用到的依赖包很少,只有两个基础包+一个pandas(pandas也很基础,没有装的自己反思一下然后光速安装)。
import pandas as pd
import os
import glob
def merge_csv(files_dir, outpath): # 将多个csv文件合并为一个,待合并csv集目录,合并后csv文件路径
csv_files = glob.glob(os.path.join(files_dir, "*.csv")) # 抓取目录下全部csv文件
features = pd.DataFrame() # 生成一个DF格式要素
for csv_file in csv_files:
feature = pd.read_csv(csv_file) # 读取单个csv文件
features = features.append(feature) # 添加进要素集
features.to_csv(outpath, index=False, encoding="utf-8") # 导出为csv文件
print("merged successfully!")
def split_csv(csv_file, outdir, count): # 将一个csv文件拆分为多个,待拆分csv文件,拆分保存目录,拆分个数
feature = pd.read_csv(csv_file) # 读取csv
feature = pd.DataFrame(feature)
num = int(len(feature)/count) # 单个文件个数
for i in range(count):
start = i * num
end = (i+1) * num
if i == 0:
start = 0
if i == count-1:
end = len(feature)
feature_single = feature.iloc[start:end, :]
file_name = os.path.splitext(os.path.split(csv_file)[1])[0]
comlete_name = f"{file_name}_{str(i+1)}_{end-start}count"
outpath = os.path.join(outdir, comlete_name + ".csv")
feature_single.to_csv(outpath, index=False, encoding="utf-8") # 导出为csv文件
print(f"{comlete_name} split successfully")
model = input("请输入模式(1:合并 2:拆分):")
if model == "1":
print("\n==================== 进入合并模式 ====================\n")
files_dir = input("请输入待合并的csv文件集目录:")
outpath = input("请输入合并后文件的输出路径:")
merge_csv(files_dir, outpath)
print("\n=====================================================")
if model == "2":
print("\n==================== 进入拆分模式 ====================\n")
csv_file = input("请输入待拆分的csv文件路径:")
outdir = input("请输入拆分后文件集的输出路径:")
counts = input("请输入该csv文件的拆分个数:")
counts = int(counts)
split_csv(csv_file, outdir, counts)
print("\n=====================================================")
代码是傻瓜式代码,因为使用了input语句,所以一上去运行就行了(但是理解起来也不难)。
运行完分为两种模式,模式1是合并,是为了将一些稀碎的脚本或最终计算完成的结果合并为一个csv准备的;模式2是拆分,就是本小节的主要任务。因为直接使用了input,所以代码也可以直接使用命令行调用。
拆分的操作如下(其实只要按指引填上相关的路径和信息即可):
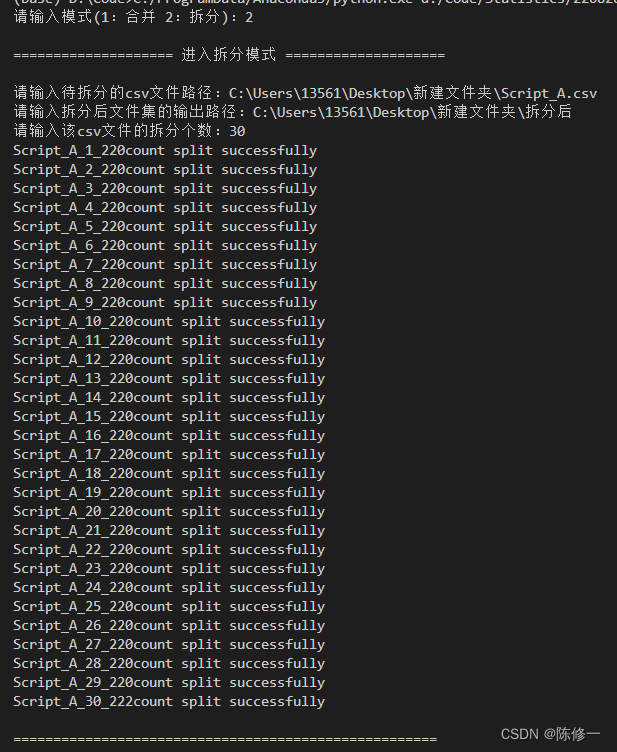
需要注意的是,拆分后的文件除了增加文件的索引(就是1到30)还增加了文件内条目的个数,这对于我们控制fragstats的运算是有帮助的,因为如果一个脚本里太多条目了容易崩掉(懂得都懂)。。。并且这个崩不崩掉和电脑的性能关系不是太大,在这里的批量运算中建议拆分后单个脚本的条目个数<300(亲测最稳定快速)。
至于合并就不展示了,就是倒过来操作,运行一下选模式1根据指引输入参数就可。
再补充一点,这个代码目前只能识别csv文件,会无视掉同一个目录下的其他格式文件,有其他需求的可以自己改改,改完可以识别.class文件。
3 根据脚本集批量计算景观指数
在开始通过python调用fragstats计算景观指数前,为了确保代码能够使用,需要把fragstats安装目录添加到环境变量中,如下图。
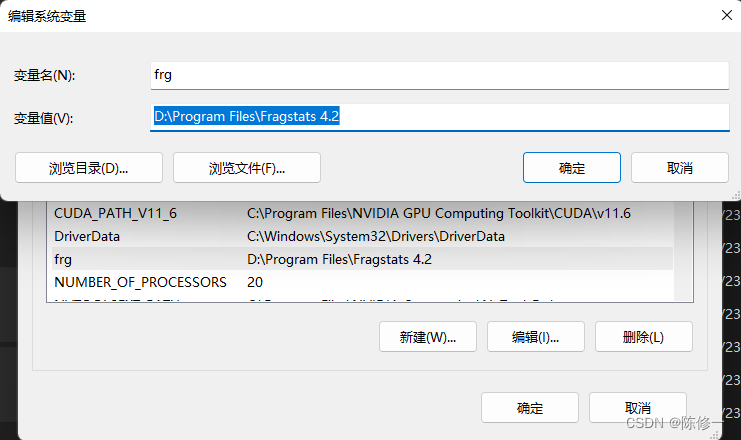
变量值填你自己的路径奥,别照搬我的。不懂得配置环境变量的同学可以另行百度。
你如果跟我皮,不添加也行,可以直接使用frg.exe的绝对路径运行fragstats,具体在这里不细说,有需要的同学可以参考这篇博文的方法修改代码。
下面是代码(添加环境变量后才能良好运行的代码,没添加的自己改改),一样,使用了input,直接运行然后输入参数即可。
import os
from glob import glob
import pandas as pd
def frg_cmd(model, scripts_dir, output_dir): # 模型路径,脚本所在目录,输出目录
csv_scripts = glob(os.path.join(scripts_dir, "*.csv")) # 抓取目录下全部csv文件
for csv_script in csv_scripts:
output_file = os.path.join(output_dir, os.path.split(csv_script)[1])
output_file = os.path.splitext(output_file)[0]
print("=====================================================")
print(f"model: {model}")
print(f"script: {csv_script}")
print(f"output: {output_file}")
print("\n")
frg_flag = 0
while frg_flag == 0:
os.system(f"frg -m {model} -b {csv_script} -o {output_file}") # 命令行执行
read_csv_script = pd.read_csv(csv_script) # 读取脚本文件
read_output_file = pd.read_csv(output_file+".class") # 读取输出文件
read_csv_script = pd.DataFrame(read_csv_script)
read_output_file = pd.DataFrame(read_output_file)
if len(read_csv_script) == len(read_output_file): # 如果条目数匹配
frg_flag = 1
print("data match!")
else:
print("data do not match! Restart!")
print("\n")
print(f"{output_file} is completed!")
print("=====================================================")
model = input("请输入模型路径:")
scripts_dir = input("请输入脚本目录:")
output_dir = input("请输入输出目录:")
frg_cmd(model, scripts_dir, output_dir)
模型路径,就是你在界面化中勾选的一些要计算的景观指数然后保存的.fca文件。
脚本目录,就是上面制作的csv脚本的目录,在这个代码默认只能识别csv格式的脚本。
输出目录,就是你要保存结果的目录。
我输入的信息如下,可以参考(根据实际情况设置,不要无脑照抄):

然后就是和在界面化fragstats终端中输出的信息类似的,首先是加载,
然后是分析计算,
需要注意的是,我的代码中加入了输出结果的脚本中数量的比对,如果数量不一致就会自动重新计算,这样可以避免出错漏算一些条目(解决脚本中条目太多会中断漏算的问题),所以还是建议大家把每个脚本的条目数弄少一点(建议<300)。
最后等终端显示计算完成出现相关提示后就可以在你的输出文件夹里看到.class的结果文件了。
我一般是把后缀直接改成.csv打开就行了。
上图中我先跑出了三个(为了写博客没必要都跑出来结果),我的电脑跑一个200+条目(格子)的脚本的结果大概花不到1分钟,简单来说就是不慢。
我自己的一个研究二十多万个条目(tif或格子)分成1000+个csv也才用不到一天时间,如果想要很快可以放在多台电脑上,这东西不需要什么算力。
说回正题,把导出的结果.class文件改成.csv后缀直接打开如下。
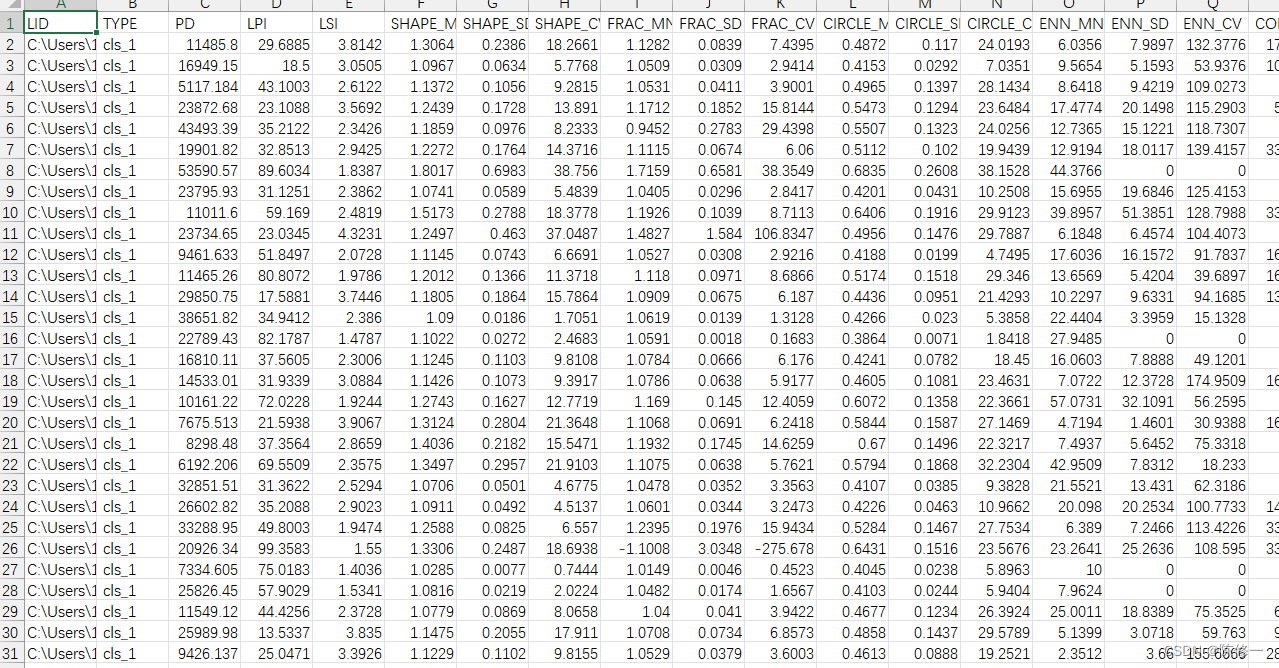
好了,这就得到我们最终需要的结果了。
如果需要合并结果,用第2节的代码切到合并格式然后输入相关信息合并即可。
4 懒得学python或者没有python环境的解决方案
我简单把上面两个代码封装了一下,方便不会python或没有python环境的同学。
这两个exe在一般windows电脑都可以运行,打开即可(但是仍然用要把fragstats添加到环境变量中)。
现在只要V我50吃顿肯德基,即可获取下面两个封装后的傻瓜版exe。
重新说一边奥,为了帮助到没有python环境和不会python同学(会python的同学直接运行第2、3节的代码,不用再问我啦),我把上面的代码封装成两个小程序,直接打开即可实现类似上面的操作。但是下面两个小程序是有偿获取的(知识付费,随便打赏50元以上即可),需要的同学可以联系我邮箱(chinshuuichi@qq.com)并且贴上打赏付款证明(码在下面),我看到后就会在附件中贴上这两个小程序给你。(记得在邮件里说明要哪篇博客的材料啊!之前一些博客也有提供类似有偿服务,总是有同学不说明要啥,很耽误时间。)

如果对你有帮助,还望支持一下~点击此处施舍或扫下图的码。
-----------------------分割线(以下是乞讨内容)-----------------------
















 6764
6764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}