






 本文介绍了如何使用Python爬虫获取蝉妈妈平台上的热门视频榜单数据。通过分析请求参数,发现需要登录后的cookie来获取数据。文章提供了一段测试代码,并强调在headers中加入cookie后才能成功获取数据。最后,完整代码将数据保存在本地CSV文件video.csv中,提醒读者使用自己的cookie进行替换。
本文介绍了如何使用Python爬虫获取蝉妈妈平台上的热门视频榜单数据。通过分析请求参数,发现需要登录后的cookie来获取数据。文章提供了一段测试代码,并强调在headers中加入cookie后才能成功获取数据。最后,完整代码将数据保存在本地CSV文件video.csv中,提醒读者使用自己的cookie进行替换。
前言
本文是该专栏的第38篇,后面会持续分享python爬虫干货知识,记得关注。
通过蝉妈妈查看视频榜单数据的前提,首先需要账号登录才能正常看到榜单数据。榜单如下:
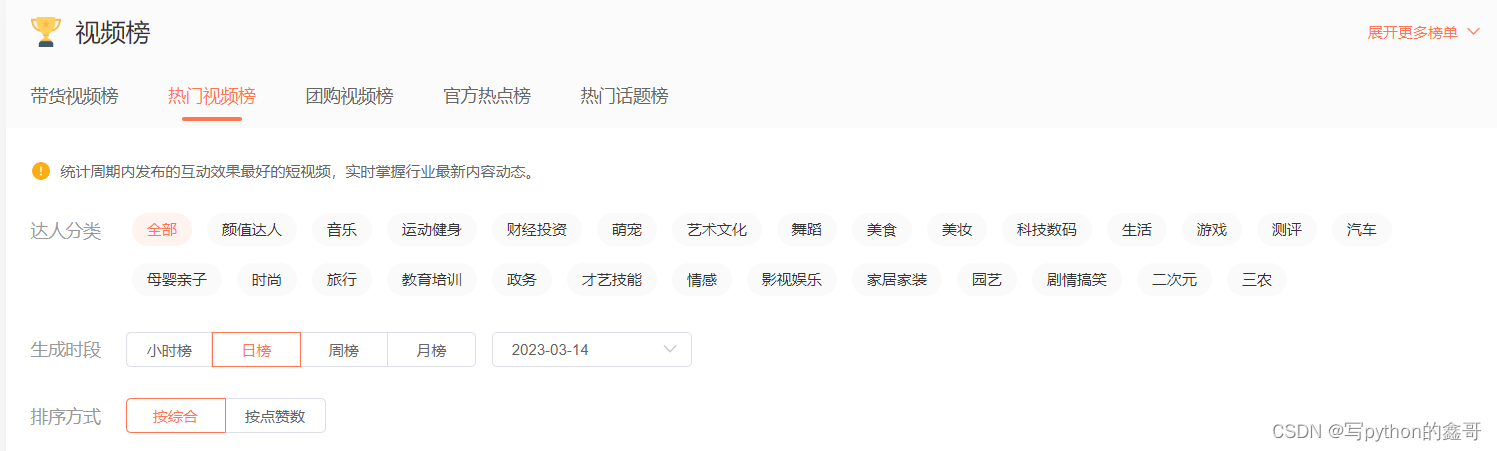
下面以热门视频榜为例,跟着笔者直接往下看。
正文
1. 参数分析
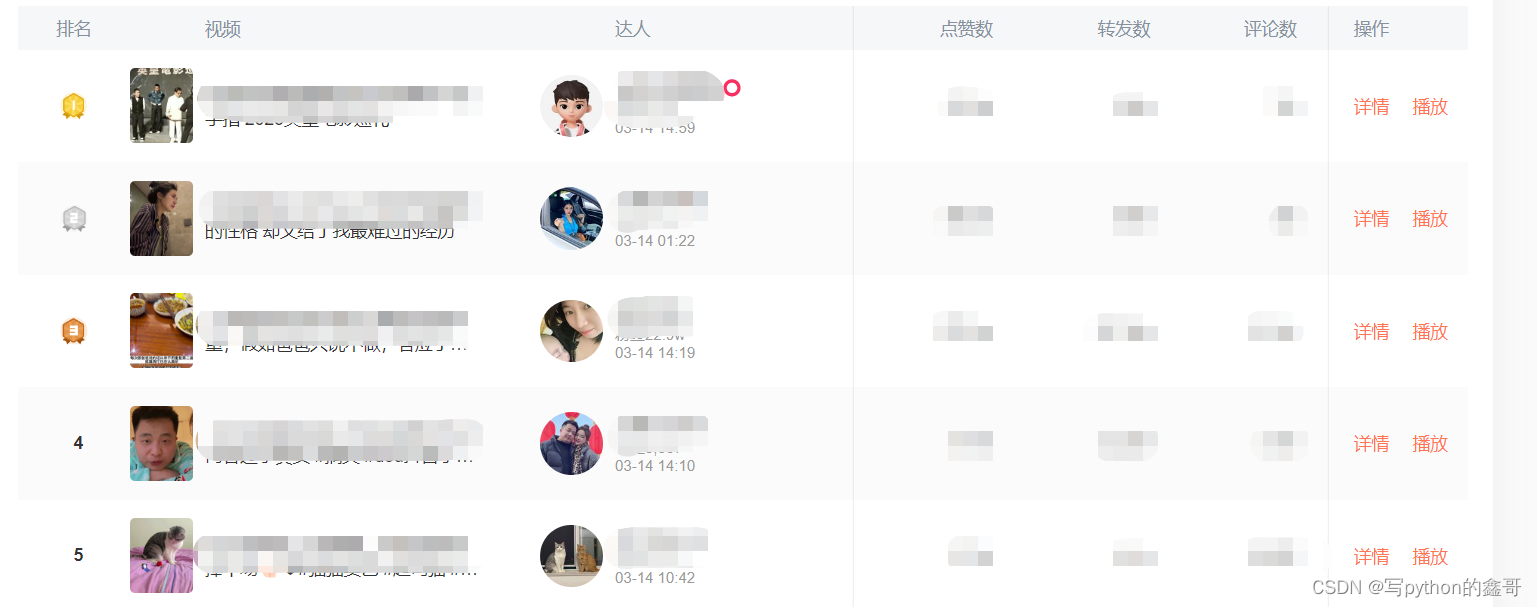
进入榜单页面之后,直接Ctrl+Shift+I快捷键启动开发者工具。将鼠标滑动最底部,并点击加载更多按钮,会看到右侧一栏出现如下信息,如下:

前言
本文是该专栏的第38篇,后面会持续分享python爬虫干货知识,记得关注。
通过蝉妈妈查看视频榜单数据的前提,首先需要账号登录才能正常看到榜单数据。榜单如下:
下面以热门视频榜为例,跟着笔者直接往下看。
正文
进入榜单页面之后,直接Ctrl+Shift+I快捷键启动开发者工具。将鼠标滑动最底部,并点击加载更多按钮,会看到右侧一栏出现如下信息,如下:
 1230
517
951
1230
517
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























