







二值变量
伯努利分布
对于
x∈{0,1},p(x=1|μ)=μ
,
x
的概率分布有
假设一个数据集
D={x1,x2,…,xN}
,
xi
服从伯努利分布,并且独立同分布,那么
我们能够通过最大化似然函数来求解
μ
,
由于
xi∈{0,1}
,如果设
D
中
假设我们抛一枚有损的硬币 p(x=1|μ)=μ 可以不为0.5,如果 D 有3个观测值,而且全部为1,即头部向上,那么我们由最大似然函数得到的结果就是 μML=1 ,如果我们用这个值去预测以后的结果,明显准确率会十分差,这就是所谓的过拟合。
二项分布
假设我们已经知道观测值中总共有
m
个值为1的观测值,那么对
以上关于期望与方差的计算可以重新计算,或者用第一章习题1.10的结论直接得出。
贝塔分布
前面我们知道最大似然函数会容易过拟合,那么可以用贝叶斯分析来减小这个问题,但是之前我们先介绍一下贝塔分布
其中 a,b 是超参数,当 a,b 取不同值时,分布图如下所示:
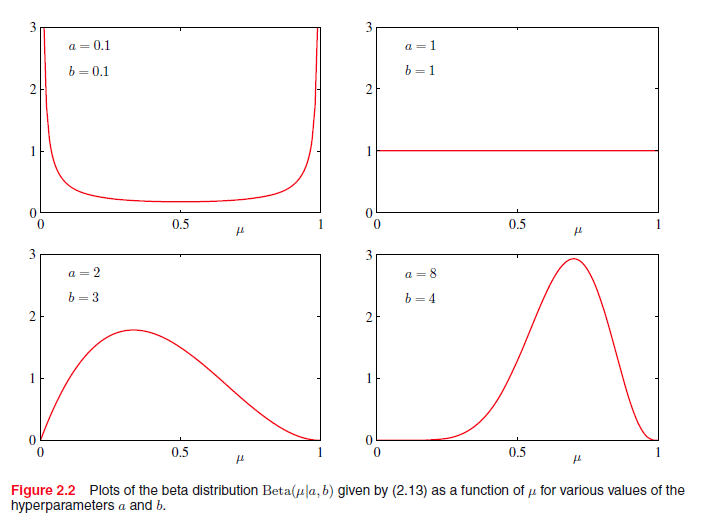
贝叶斯分析
贝叶斯公式: p(y|x)∝p(x|y)p(y)
为了使过程简化,我们希望后验概率
p(y|x)
与先验概率
p(y)
有同样的形式,这个先验被称为共轭先验(conjugate prior)。对于抛硬币问题(服从伯努利分布),由式(2)我们知道似然函数
p(m|N,μ)∝μm(1−μ)N−m
,那么我们可以取贝塔分布作为共轭先验,那么
假设我们设 a=1,b=1 , D 有三个观测值,并且都为1,那么在贝叶斯分析中去预测为 45 ,直觉上至少要比最大似然函数的预测 1 要靠谱。
当
而且最大后验能够充当下一次观测数据的先验知识,从而达到顺序学习(sequential learning),能够更好的应用于大规模数据。比如我们将
D
划分数据集大小为
N0,N1
的两个子数据集
D0,D1
,刚开始我们观测到数据集
D1
,先验知识为
p(μ|a0,b0)
,那么对于数据集
D0
的后验为
然后我们观测到数据集 D1 ,此时以 D0 的后验作为其先验,那么同理我们有
这个优点能够使我们更容易的训练大规模数据。
在贝叶斯学习中,当我们观测的数据越来越多的时候,后验分布的不确定性就会越来越小。
todo
多元变量
前面一节我们介绍的是变量只有两个状态(要么是1,要么是0),当变量有多个状态的时候,我们可以扩展成
x=(0,…,1,…,0)T,∑Kk=1xk=1,p(xk)=μk
,那么
其中 μ=(μ1,…,μK)T,∑Kk=1μk=1 ,同之前的伯努利分布一样,对于 D={x1,…,xN} 的似然函数有
求其最大值与二值变量是基本类似的,只是多了一个约束条件 ∑Kk=1μk=1 ,我们可以用拉格朗日乘子法来进行求解
多项式分布
狄利克雷(Dirichlet)分布
多项分布的共轭先验是狄利克雷分布,如下
那么多项分布的后验
以上都是离散变量的分布,下面介绍连续型变量中最常用的分布,高斯(Gaussian)分布
高斯分布
对于单一变量: N(x|μ,σ2)=12πσ2√exp{−(x−μ)22σ2}
对于D维向量 x : N(x|μ,Σ)=1(2π)D/2|Σ|1/2exp{−12(x−μ)TΣ−1(x−μ)} ,其中 μ,Σ 分别是D维均值向量和 D×D 协方差矩阵, |Σ| 是协方差矩阵的行列式。
对于单一变量,使其熵最大化的分布是高斯分布(PRML p54),这个性质同样适用于多元(multivariate)高斯分布。中心极限定理告诉我们独立同分布的随机变量序列的和近似高斯分布。
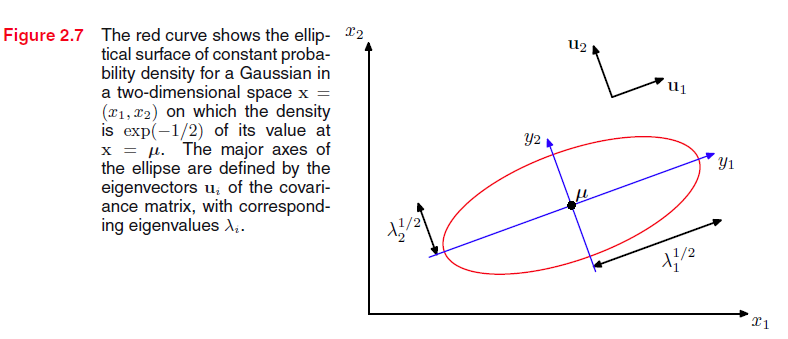
下面考虑一下高斯分布的几何形态
概率相等的点分布在一个
x
空间的曲面上。 需要注意的是
Σ
是一个对称矩阵,那么其特征向量形成一个正交向量集
其中: U 第i行为 uTi , UTU=I
对于当前的高斯分布,协方差矩阵的特征值 λi 必须严格正(全部大于0),否则不能够合适地规范化,之后我们可能会遇到有些特征值为0的高斯分布,这些分布能够限制在更低的维度空间上。
之前我们考虑的是高斯分布的几何形态,由第一章p18我们知道
p(y)=px(g(y))|g′(y)|,x=g(y)
,那么先求高斯分布
x
关于
而对称矩阵的行列式等于其特征值的连乘: |Σ|1/2=∏Dj=1λ1/2j ,那么
多元高斯分布的期望与协方差
μ,Σ 共同控制了高斯分布的形态,在D维空间中,一般情况下, μ 有D个参数,而 Σ 有 D(D+1)/2 个参数(对称矩阵),那么为了决定一个高斯分布的形态我们要有 D(D+3)/2 个参数。对于低维空间来说这个参数是可以接受的;但是对于非常大的 D ,计算量就会变得十分昂贵(协方差的逆矩阵)。
一个方法是限制协方差矩阵的形态:1.
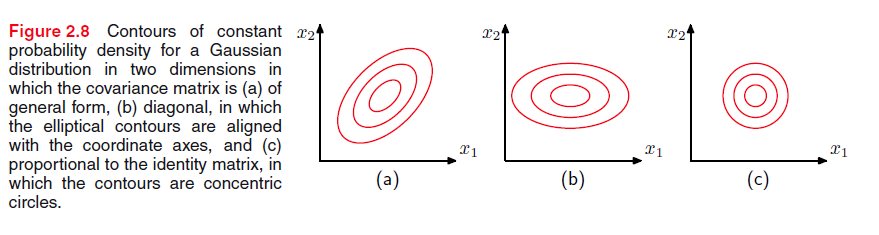
由上图知道,虽然限制协方差矩阵的形态能够使计算协方差矩阵的逆更加快速,但是这也限制了高斯函数的分布从而影响高斯分布拟合数据的能力。
条件高斯分布与边缘高斯分布
条件高斯分布与边缘高斯分布的推导可以参考PRML p86。
p(x)=p(xa,xb) ,当我们固定 xb 就得到 xa 关于 xb 的条件概率
由上面的推导我们知道,当 xb 固定时,上式是关于 xa 的二项式,因此 p(xa|xb) 是干死分布。下面介绍知道一个高斯分布的指数的二项式之后,求它的期望与协方差矩阵。
上式的const是指与 x 无关的项。根据上式我们就得到 p(xa|xb) 的均值与协方差矩阵
条件高斯分布 p(xa|xb) 的均值是 xb 的线性函数
至于边缘函数则可以由积分求得: p(xa)=∫p(xa,xb)dxb ,与条件高斯分布的推导基本类似都是,详细请看书P88,下面只给出结果
高斯条件分布 p(y|x) 的均值是 x 的线性函数那么,
需要注意的是,书中的推导是先求出 p(x,y) ,然后再根据高斯条件分布与高斯边缘分布的结论直接得出 p(y),p(x|y)
高斯分布的最大似然
X={x1,…,xN},{xn} 独立同分布。
由于 μML 不依赖于 ΣML ,可以先求 μML 再求 ΣML 。
顺序估计(sequential estimation)
首先对于高斯分布的均值(mean)估计: μML=1N∑Nn=1xn
在我们估计了
N−1
个观测值的
μN−1ML
后又来了一个新的观测数据,我们能够很轻松的利用先前的
μN−1ML
来估计
μNML
,大大减小了计算量。对于拥有
μML∝∑Nn=1xn
,我们可以利用上式来进行sequential estimation。如果更一般的话,我们可以利用Robbins-Monro算法推导更一般的形式
如单一变量的高斯分布, ∂∂μMLlnp(x|μML,σ2)=1σ2(x−μML) ,此时令 aN=σ2/N
高斯分布的贝叶斯推理
前面我们大致介绍了在贝叶斯推理中,最重要的是选择共轭先验。在高斯分布中,共轭先验的选择相对于多项分布更复杂,主要分为以下三种情况,先考虑单一变量的高斯分布
1
σ2
已知,
μ
未知:取高斯分布作为先验
N(μ|μ0,σ2)
2
σ2
未知,
μ
已知:取伽马分布作为先验
3 当 σ2,μ 都未知,取Normal-Gamma分布做为先验
共轭先验的选取主要是考察似然函数的形式,这个推导就不详细叙述。对于D维变量的高斯分布的共轭先验,大致与单一变量的高斯分布一样
1
Λ
已知,
μ
未知:取高斯分布作为先验
N(μ|μ0,Λ)
2 Λ 未知, μ 已知:取Wishart分布作为先验
3 当 Λ,μ 都未知,取Normal-Wishart分布做为先验
Student’s t-distribution
t-分布是由无穷个具有相同 μ 不同 λ 的高斯分布累加而成的,t-分布比高斯分布具有更长的尾巴,从而使其对离群点更加鲁棒。
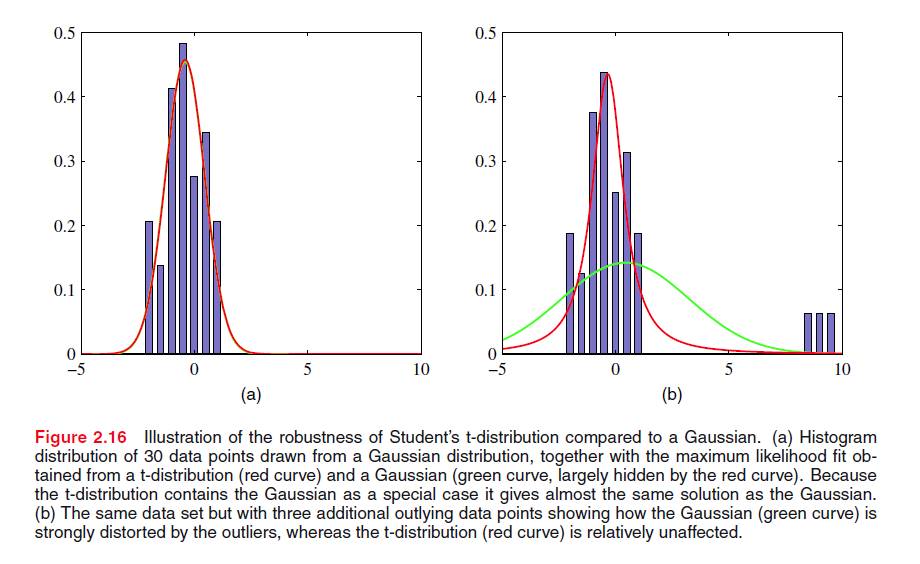
当 ν→∞ 时,t-分布就变成了 N(x|μ,λ−1)
周期变量
从笛卡尔坐标系转到极坐标系。von Mises分布
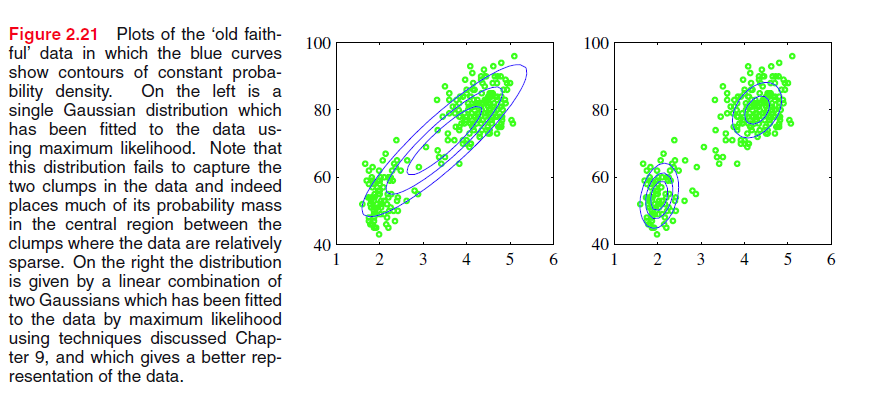
混合高斯(Mixtures of Gaussians)
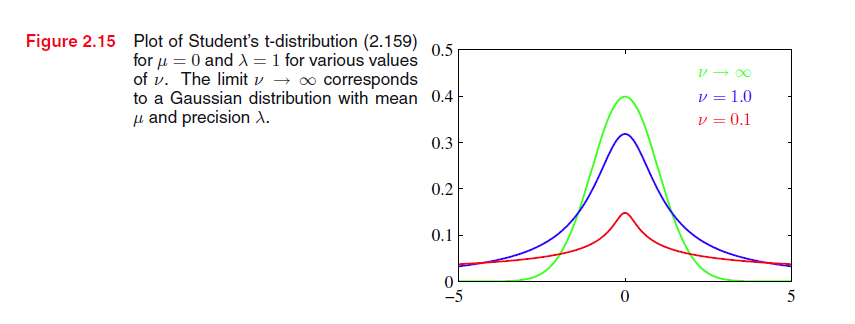
我们知道高斯分布是一个单峰分布,对于实际应用如果用单一高斯分布会存在很大的限制
上图中的左子图明显不能捕捉到数据的真实分布,我们希望能得到右子图的模型。因此提出混合高斯模型
下图是3个高斯分布的混合模型
假如我们将混合系数 πk 泛化
对混合高斯模型的最大化似然函数采用EM模型
指数族分布
加入一个分布满足以下条件,则称其属于指数族分布
下面从指数族分布来考虑先前我们介绍过的一些分布
伯努利分布
对照指数族分布的形式,我们有
这就是为什么我在二分类的逻辑回归问题中我们用logistics sigmoid function的原因。
多项式分布
我们知道 ηk 不是独立的,因为 ∑Kk=1μk=1 ,加入我们只保留 K−1 个参数,那么就会得到类似伯努利分布的指数形态。
μk=exp(ηk)1+∑K−1j=1exp(ηj) 即softmax函数。
高斯分布
指数族分布的最大似然
在介绍指数族分布的最大似然之前,我们先求一下指数族分布的真实 η
上式两边对 η 求导,得
当 X={x1,…,xN},p(xn|η)=h(xn)g(η)exp(ηTu(x)} ,那么它的似然函数为
从而当 N→∞ 时, ηML 等于真实的 η 。
共轭先验
由似然函数的形式我们得到指数族的共轭先验
其中 f(χ,ν) 是归一化系数
无信息(noninformative)先验
由于 p(y|x)∝p(x|y)p(y) ,如果先验在某些点上概率为0,就算我们之后观测到这些点,但是后验的概率也为0。而通常情况下,我们并不知道数据的概率分布函数,因此为解决上述问题,引入了noninformative prior。(也没太理解PRML这节的组织形式,先放着之后再看)
非参数(nonparametric)法
之前的概率分布都是一些具有特定形式的函数,并且能有少数的参数来控制这个函数的形态,但是采用这种方法会很大的局限性,因为我们选取的概率分布函数有可能不能捕捉数据的潜在概率分布。比如说高斯分布中,数据的潜在概率分布可能具有多个峰值,但是高斯分布是个单峰函数,因此在预测新的数据的时候,预测性能会很差,这种问题可以用混合高斯分布等扩展方法来解决。我们下面介绍另一个方法:非参数法。
假设观测值是从一个未知的概率分布 p(x) 中选取的, x 是D维空间的点,那么对于一个很小的区域 R ,这个区域的概率质量为
现在假设我们从 p(x) 中选取N个观测值,那么落在区域 R 的观测值个数 K 服从二项分布
当N很大的时候,由 var[K/N]=P(1−P)/N 知道分布会集中分布中均值上,此时的均值 K≃NP
当 R 足够小,那么在这个区域上 p(x) 近似为一个常数,那么 P≃p(x)V 。从而有 p(x)=KNV (两个假设,在实际应用中会不会导致结果相差太大?)。这个估计公式主要由 K,V 两个值决定
核密度估计(kernel density estimation)
固定
V
,从数据中决定
我们取 k((x−xn)/h) ,那么 K=∑Nn=1k(x−xnh) ,那么对于 p(x) ,我们就得到
Parzen window核函数会导致求出的 p′(x) 人为的不连续性,而不是因为 p(x) 本身引起的。因此采用另一个核函数——高斯核函数
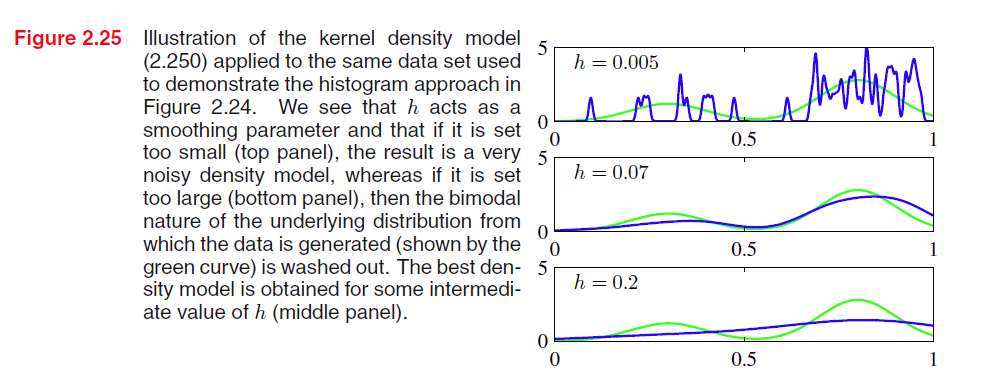
我们可以看到从现在的超参数就变成了 h 。
最邻近法(Nearest-neighbour methods)
核方法的一个局限性是,它对于大部分空间上具有相同的密度,但是有些数据集可能在某些区域密度较为集中,而另一些区域密度相对较小,那么核方法中的
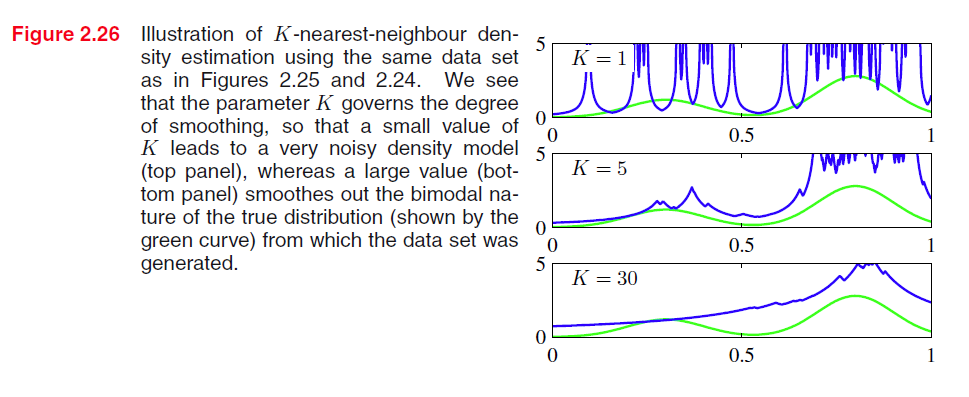
假设一个数据集一共有N个实例,其中有
Nk
个属于类
Ck
,
∑kNk=N
。如果我们想分类一个新的实例
x
,我们以
x
为中心选取
K
个实例。那么在这里面有
K-近邻算法的概率解释,通俗解释就是选取与测试实例最近的 K 个实例,如果这
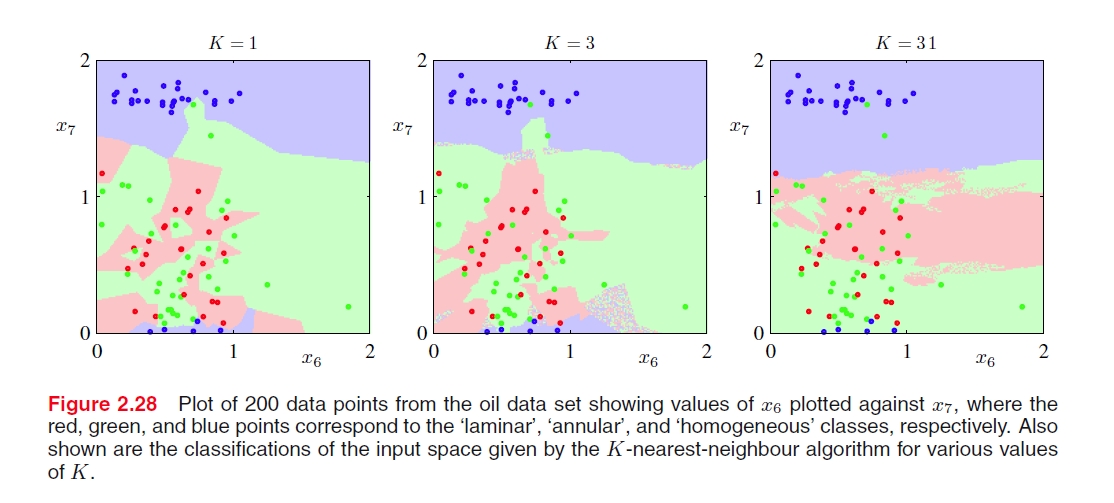
从上图的例子我们知道, K <script type="math/tex" id="MathJax-Element-422">K</script> 值选取会决定分类算法的性能。K-近邻算法需要保存整个数据集,当数据量很大时,计算十分昂贵,所以为了解决这个问题,可以构造树形搜索结构来加速计算。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









