







 本文是PRML读书笔记的第四部分,主要探讨了分类的线性模型,包括判别函数、逻辑斯蒂回归、拉普拉斯逼近等概念。介绍了二分类问题的线性判别函数,强调了最小二乘法在分类问题中的局限性,提出了Fisher线性判别作为改进,并讨论了多类别的Fisher判别。此外,还讲解了概率生成模型和概率判别模型,特别是逻辑斯蒂回归的细节及其在多类别问题中的应用。
本文是PRML读书笔记的第四部分,主要探讨了分类的线性模型,包括判别函数、逻辑斯蒂回归、拉普拉斯逼近等概念。介绍了二分类问题的线性判别函数,强调了最小二乘法在分类问题中的局限性,提出了Fisher线性判别作为改进,并讨论了多类别的Fisher判别。此外,还讲解了概率生成模型和概率判别模型,特别是逻辑斯蒂回归的细节及其在多类别问题中的应用。
分类的线性模型
分类的目标是在给定输入,预测具有离散性质的目标值。输入空间被多个决策平面划分成多个决策区域,每个区域代表一个类别。决策平面是输入特征的线性函数(待会会详细介绍),因此在D维空间上的决策平面是(D-1)维的超平面,如果数据能够被这些决策平面准确划分成n个类别区域,那么数据集线性可分(linearly separable)。
当有K(>2)类时,我们采用 1-of-K 编码格式也叫one-hot encoding。 t={ 0,…,1,…,0}T,∑ktk=1 。
这章的模型可以一般表示为
其中 f(⋅) 是激活函数。如果令 f 为一个恒等函数(identity function),即
4.1 判别函数(Discriminant Functions)
在给定输入特征时,判别函数输出一个类别 Ck
4.1.1 二分类问题
最简单的判别函数为如下的线性判别函数
当 y(x)≥0 时,我们将 x 分到类别 C1 ,否则分到 C2 。因此bias项 w0 的负值有时候也被称为阈值。
因此决策平面 S 就并定义成了 y(x)=0 ,从几何上看,我们可以知道 wT 是 S 的法线,那么 w0 就可就决定了决策平面与原点的距离 −w0∥w∥ 。
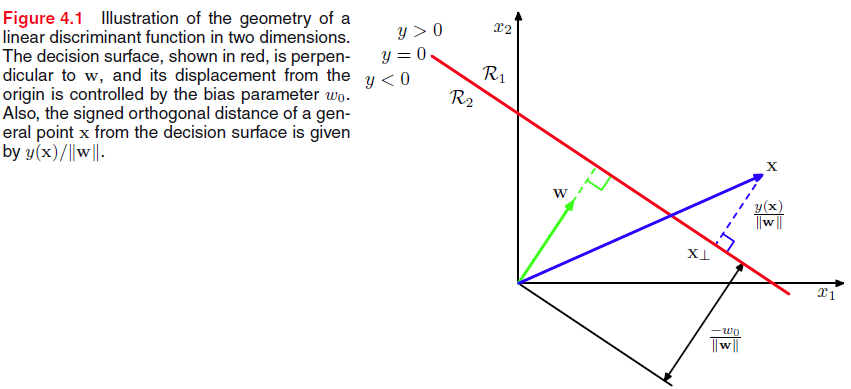
上图中 x 是空间上任意一点, x⊥ 是 x 正交投影到平面 S 上的点, r 是
如果令 x0=1,w~={ w0,w},x~={ x0,x} ,那么 y(x)=w~Tx~
4.1.2 多类别
对于多类别,可以训练K-1个分类器,每个分类器可以看做是一个二分类问题,即类别 Ck 与 非 Ck ,由于约束,我们训练K-1个分类器即可;训练 K(K−1)/2 个分类器,类别为 Ck 和 Cj 。这两种方法都会导致模糊区域的问题

为了解决模糊区域问题,可以考虑 K 类别判别(K-class discriminant),
虽然形式上有点类似前两种方法,但是只有当所有 j≠k,yk(x)>yj(x) 时,才分类到 Ck ,那么 Ck 与 Cj 的决策边界(平面) 就变成了 yk(x)=yj(x)⇒(wk−wj)Tx+(wk0−wj0)=0 ,这与二分类的决策平面一致。

由上图知道 xa,xb 是决策区域 Rk 的任意两个点,那么在直线 xaxb 上的任一点 x^ ,我们可以表示为
明显对于任意 j≠k ,我们有 yk(x^)≥yj(x^) ,即对于线性可分的数据, Rk 是单连通凸区域(singly connected and convex)。
4.1.3 分类的最小二乘法
采用最小二乘法能够使预测值逼近 E[t|x] ,详细参考第三章中的最小二乘法的解释。 对于K类别,我们有
最小二乘法对离群点不鲁棒,如下图
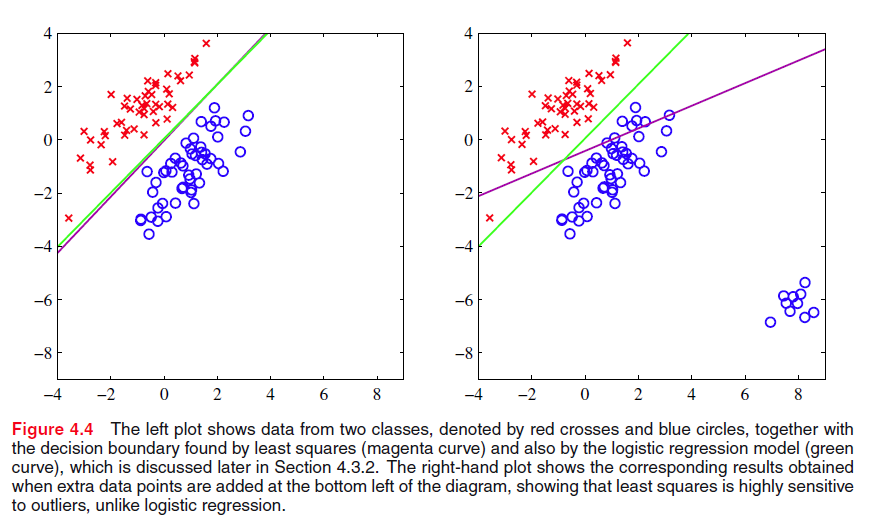
左图的决策边界已经能够很好地划分两个区域了,但是来了一些新的数据的时候,如右图,尽管原先的决策边界也能够很好地划分数据,但是由于采用了最小二乘法,为了使损失达到最小,即划分边界距离两个类的条件期望 E[t|x] 最近,从而驱使原先的决策边界偏离,即右图紫色边界线。
(书上原话: The sum-of-squares error functin penalizes predictions that are ‘too correct’ in that they lie a long way on the correct side of descision boundary.)

我认为导致左图的原因除了二乘法原因外,还有 K-class discriminant方法中,所有的决策区域必定相交于一个平面,所以左图的数据对于 K-class discriminant是不可分的(?)
导致上述问题的一个根本原因是,最小二乘法是高斯分布假设下的最大似然估计解决方案,而对于分类问题的目标值是离散的,而不是连续的,从而与高斯分布假设不相符。
4.1.4 Fisher线性判别(Fisher’s linear discriminant)
线性判别函数一般表示为 y=wTx , 从几何上看,我们将 D 为输入 x 经过一个变换之后,输出了一个一维的空间 y ,并且在这个一维空间上不同类的数据是可分的。考虑2分类问题,只有推广。如果将每个类看成一个簇,那么它中点看做
为了使不同类的数据分开,我们使 m1,m2 投影到一维空间上的距离最远,即
假设 xa∈C1 ,当 xa 在 m1 附近或者 m1xa−→−− 的方向与 m1m2−→−−− 背离(夹角大于90度),那么 xa 能够与 C2 中的点很好地分离,同理 C2 。
但是对于 xa 不在 m1 附近并且 m1xa−→−− 的方向与 m1m2−→−−− 同向(不是夹角等于0,而是夹角小于90度) ,那么这些点就有可能不能很好地分离开,如下图左图所示

Fisher linear discriminant wiki。Fisher线性判别对这个问题进行了研究,他的思想要使类内(within-class)数据的方差最小,并且使类间(between-class)数据的方差最大,从而得出了Fisher criterion
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









