







关系数据理论
一、 问题的提出
例子:
建立一个学校教务处的数据库: 学生的学号(sno)、所在系(sdept)、系主任名字(Mname)、课程号(Cno)、成绩(Grade).
假设用单一的模式关系来表示:
U={Sno, sdept, Mname, Cno, Grade}
属性组U的一组函数一来关系F:
F= {Sno→Sdept, sdept→Mname, (Sno,Cno)→Grade}
单一数据模式存在的问题:
- 数据沉余太大
- 更新异常: 更新系主任,所有学生都要修改
- 插入异常:刚成立没有学生的系和系主任无法插入
- 删除异常: 毕业的学生全部删除,系主任的信息也删除掉了
通常说,一个好的关系模式不会发生插入异常、删除异常和更新异常、数据沉余应尽可能少;
解决办法:通过分解关系模式来分解不合适的数据依赖
我们可以把例一的模式分为三个模式:
S{Sno, Sdept} Sno→Sdept;
SC{Sno,Cno,Grade} (sno,cno)→Grade;
dept {Sdept, Mname}Sdept→Mname;
二、 规范化
规范化正是通过改造关系模式,来解决其中不合适的数据依赖,删除、插入异常和数据沉余的问题。
1、函数依赖
简单来讲就是 一个属性可以唯一确定其他属性;
- 学号→(姓名,年龄);
- 班号→班长;
- (学号,课号)→成绩
值得注意的一个点就是,这个函数依赖也要结合语义来确定,比如说 姓名→年龄 ,存在这个函数依赖的前提是 这个班级没有重名的存在,如果有的话,那么这个函数依赖关系就是不存在的;
平凡函数依赖
X→Y,但Y是X的子集
举个例子:(Sno,Cno)→ Sno;
这个就是一个典型的平凡函数依赖 就是 Sno是 (Sno,Cno)的子集
非平凡函数依赖
X→Y 但是Y却不是X 的子集
比如说: (Sno,Cno)→Grade;
Grade不是(Sno,Cno)的子集;
完全依赖和不完全依赖
X→Y
X中的所有属性一起才能确定Y 就是完全依赖,反之就是部分依赖。
比如说:
完全依赖: (Sno,Cno)(→F) Grade
非完全依赖: (Sno,Cno)(→P) Sdept 因为学号就可以唯一确定系别
传递依赖
X→Y,Y→Z
那么就称X(→z)Z;
如果也满足Y→X 的话,Z就是直接依赖于X
比如说在关系 std(Sno,Sdept,Mname)中
Sno→Sdept,Sdept→Mname 所以说 Mname传递依赖于Sno
码
- 候选码:设K为<U,F>中的属性或者属性集合K(→F)U,则K为R的候选码;
简单的说就是 候选码就是可以确定全部属性的属性的最小集合; - 主码: 若候选码有多个,选择其中一个为主码;
- 主属性:包含在候选码中的属性;
- 非主属性:不包含在候选码中的属性;
- 全码: 整个属性组是码;
- 外码: 关系模式R中属性或者属性组并非R的码,但X是另外的属性模式中的码,那么则称X是R的外部码;
三、范式
范式是满足某一级别的关系模式的集合;
一个低级的范式可以通过模式分解转换为高级的规范,这个过程称为规范化;
第一范式(1NF)
定义: 所有属性不可再分;
第一范式也是对关系模式的一个最基本的要求,所以不满足关系数据库的关系模式,不能成为关系数据库;

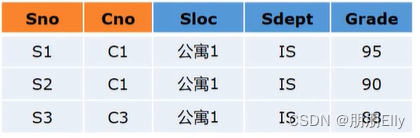
第一范式可能存在的问题:
- 插入异常:未选课的学生无法插入;
- 删除异常: 如果学生只选择了一门课,删除选课信息的时候,学生信息就也会被删除;
- 数据冗余过大: Sloc和Sdept 重复存储;
- 修改复杂:当要修改Sdept时,Sloc也要改;
第二范式(2NF)
定义: 非主属性完全依赖于任何一个候选码;
第二范式要满足完全依赖 所以可以建立两张表格 SC{Sno,Cno,Grade},dept{Sno,Sdept,Sloc};
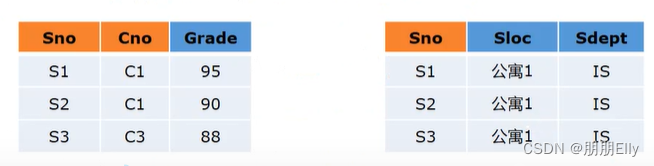
第二范式存在的问题:
- 插入异常:当新建一个公寓的时候,没有学生入住,无法插入
- 删除冗余: 当要删除学生信息时,住宿信息也被删了;
- 修改复杂: 学院换公寓,每个学生的住处都要修改;
第三范式(3NF)
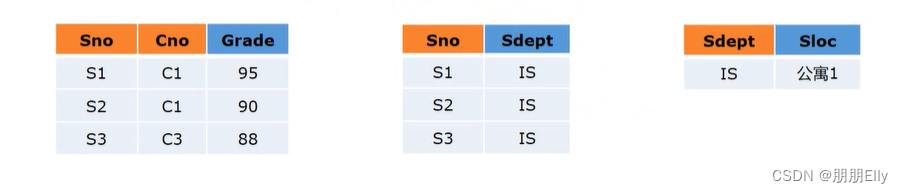
定义: 在第二范式的基础上满足,即不存在部分依赖,也不存在传递依赖;
不难发现,dept关系中是存在传递依赖的 学号确定所在系,所在系确定住处,可以通过分节这个关系,使之成为第三范式 即 dept{Sno,Sdept},Sloc{Sdept,Sloc};
















 8518
8518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











