







通过使用ABBYY FineReader PDF 15的智能OCR文本识别功能,我们可以实现快速的图像文本识别功能,将图像中的文本识别为可编辑的文本。
不仅如此,ABBYY FineReader PDF 15希望为用户提供更加便捷的图像识别服务。通过使用ABBYY Screenshot Reader功能,我们可以进一步实现截图、识别的一体化操作。
一、打开Screenshot Reader功能
Screenshot Reader是ABBYY FineReader PDF 15内置的一项工具,集截图与识别于一体,可同时完成截图与文本识别的功能。
如图1所示,Screenshot Reader既可以在OCR编辑器中的工具菜单中找到。
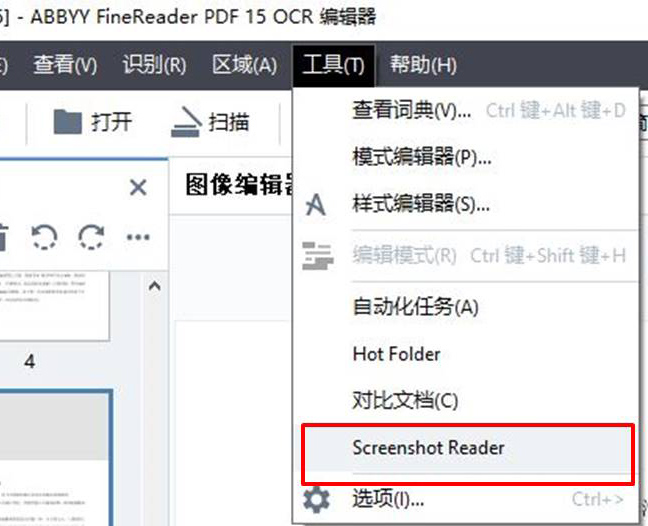
图1:OCR编辑器
也可以在如图2所示的PDF文档查看编辑器的工具菜单中找到。
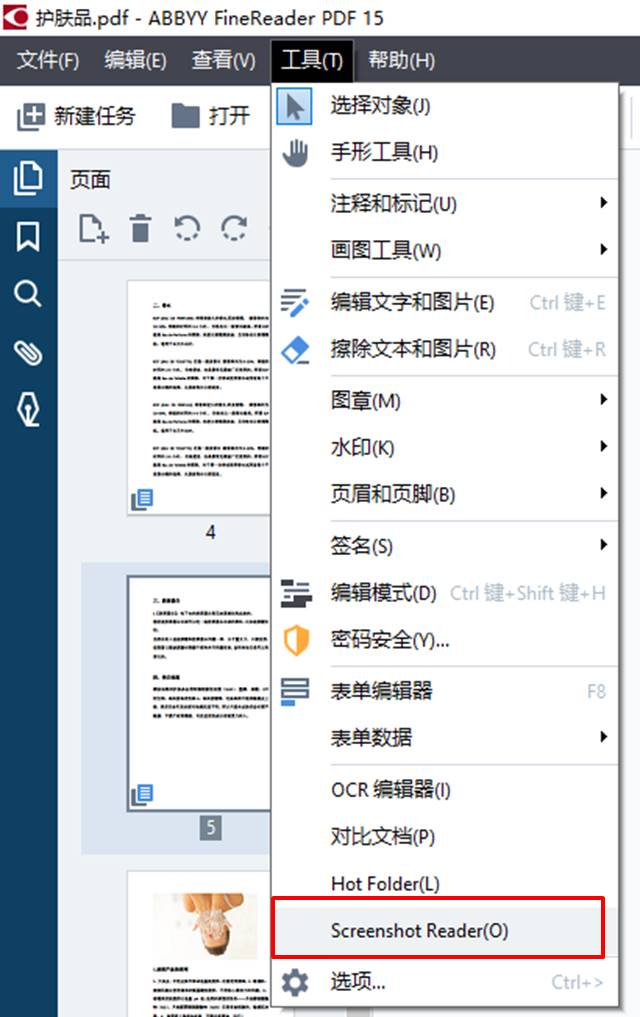
图2:PDF文档查看与编辑功能
二、Screenshot Reader选项设置
打开Screenshot Reader后,如图3所示,可以看到,该工具包含了捕获区域、识别语言与发送至三个选项。
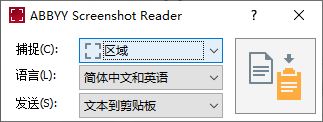
图3:操作面板
捕获
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









