







在一些政府公开信息分享网站或专业的数据分享机构网站,都会定期公开分享一些社会发展数据,或与当前时事相关的数据。这些数据往往会采用网页分享的形式,很少会提供文件下载。
如果直接将这些数据复制下来,将需要花费大量的时间进行数据排版。但借助ABBYY FineReader PDF 15 文字识别软件的帮助,可以快速识别为表格数据,并导出为可编辑的数据表格。接下来,一起来看看怎么操作吧。
一、网页表格数据截图
首先,打开相关数据网站,对数据表格区域进行截图操作。
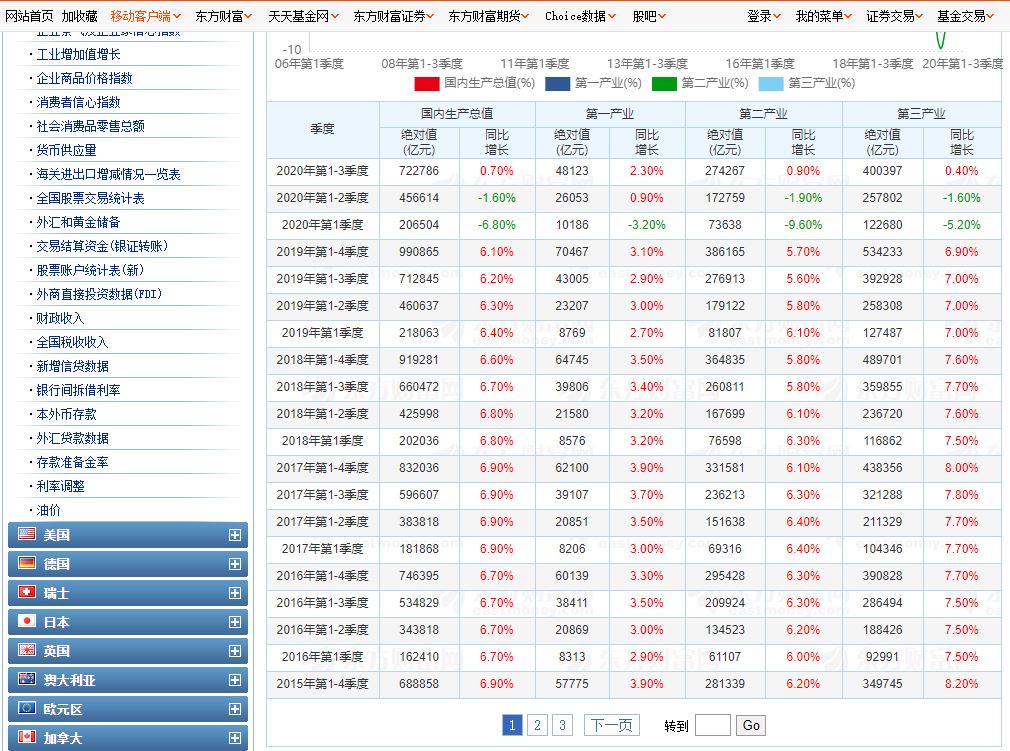
图1:打开网页截图
如图2所示,截图过程中,建议尽量保持表格边框的完整性,提高ABBYY FineReader PDF 15识别的准确度。
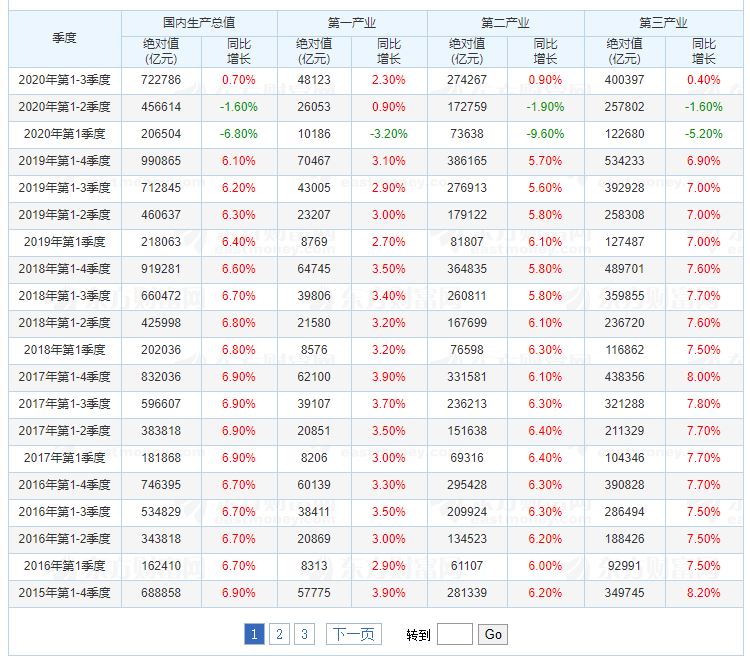
图2:完成表格数据截图
二、使用OCR编辑器识别表格
接着,打开ABBYY FineReader PDF 15文本识别软件,并使用“在OCR编辑器中打开”功能,打开刚才在网站截取的表格数据。

图3:在OCR编辑器中打开图片
接着,待软件完成图像的文本识别。在识别过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









