






【学习记录】
1.导入包,数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
data = pd.read_csv('train.csv')
data.info()

查看缺失数据个数

labels = ['存活','死亡']
f,ax = plt.subplots(1,2,figsize=(15,6))
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['font.serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题,或者转换负号为字符串
data['Survived'].value_counts().plot.pie(ax=ax[0],explode=[0,0.05],
labels=labels,
autopct='%1.1f%%',
shadow=True,
startangle=90
)
ax[0].set_title('Survived')
sns.countplot('Survived',data = data,ax = ax[1])
ax[1].set_title('Survived') 
性别与生存情况
f,ax = plt.subplots(1,2,figsize=(15,5))
data[['Survived','Sex']].groupby(['Sex']).mean().plot.bar(ax = ax[0])
ax[0].set_title('Sex VS Survived')
sns.countplot('Sex',hue = 'Survived',data = data,ax=ax[1])#hue按照列名中的值分类形成分类的条形图
ax[1].set_title('Survived VS Dead')
年龄与生存情况
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot("Pclass","Age", hue="Survived", data=data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age", hue="Survived", data=data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()
姓名

data['Initial']=0
for i in data:
data['Initial']=data.Name.str.extract('([A-Za-z]+)\.') #extract可用正则从字符数据中抽取匹配的数据+抽取多个字母
data['Initial'].value_counts() 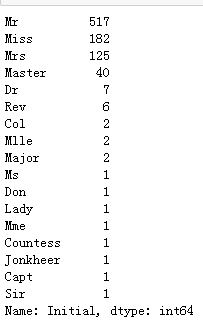
pd.crosstab(data.Initial,data.Sex).T.style.background_gradient(cmap='summer_r')#交叉表用于统计分组频率的特殊透视表 
data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],
inplace=True) 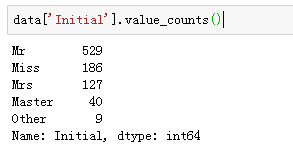
data.groupby('Initial')['Age'].mean()
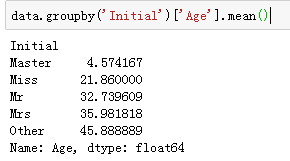
按类别填充年龄
## 使用每组的均值来进行填充
data.loc[(data.Age.isnull())&(data.Initial=='Mr'),'Age']=33
data.loc[(data.Age.isnull())&(data.Initial=='Mrs'),'Age']=36
data.loc[(data.Age.isnull())&(data.Initial=='Master'),'Age']=5
data.loc[(data.Age.isnull())&(data.Initial=='Miss'),'Age']=22
data.loc[(data.Age.isnull())&(data.Initial=='Other'),'Age']=46检查是否有空值
data.Age.isnull().any()返回的是False
f,ax=plt.subplots(1,2,figsize=(20,8))
data[data['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red')
ax[0].set_title('Survived= 0')
x1=list(range(0,85,5))
ax[0].set_xticks(x1)
data[data['Survived']==1].Age.plot.hist(ax=ax[1],color='green',bins=20,edgecolor='black')
ax[1].set_title('Survived= 1')
x2=list(range(0,85,5))
ax[1].set_xticks(x2)
plt.show()填充年龄缺失值后的年龄VS生存情况

年龄分箱
data['Age_band']=0
data.loc[data['Age']<=16,'Age_band']=0
data.loc[(data['Age']>16)&(data['Age']<=32),'Age_band']=1
data.loc[(data['Age']>32)&(data['Age']<=48),'Age_band']=2
data.loc[(data['Age']>48)&(data['Age']<=64),'Age_band']=3
data.loc[data['Age']>64,'Age_band']=4
data['Age_band'].value_counts().to_frame().style.background_gradient(cmap='summer') 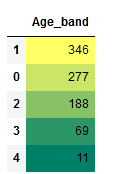
填补船舱缺失值
data['Embarked'].fillna('S',inplace=True)
data['Fare_Range']=pd.qcut(data['Fare'],4)
data.groupby(['Fare_Range'])['Survived'].mean().to_frame().style.background_gradient(cmap='summer_r') 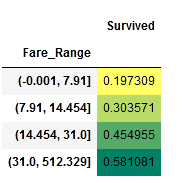
data['Fare_cat']=0
data.loc[data['Fare']<=7.91,'Fare_cat']=0
data.loc[(data['Fare']>7.91)&(data['Fare']<=14.454),'Fare_cat']=1
data.loc[(data['Fare']>14.454)&(data['Fare']<=31),'Fare_cat']=2
data.loc[(data['Fare']>31)&(data['Fare']<=513),'Fare_cat']=3 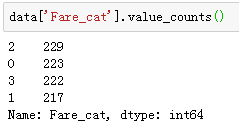
编码转换
data['Sex'].replace(['male','female'],[0,1],inplace=True)
data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True)
删除列
data.drop(['Name','Age','Ticket','Fare','Cabin','Fare_Range','PassengerId'],axis=1,inplace=True) 
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2,annot_kws={'size':8})
fig=plt.gcf()
fig.set_size_inches(6,6)
plt.xticks(fontsize=8)
plt.yticks(fontsize=8)
plt.show()
文件另存为newdata.csv
data.to_csv('newdata.csv')
newdata = pd.read_csv('newdata.csv',index_col=0)
newdata.info()
导入相应包
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score划分训练集测试集
X = newdata.loc[:,newdata.columns!='Survived']
Y = newdata['Survived']
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size=0.2, random_state=40)决策树
model=DecisionTreeClassifier()
model.fit(Xtrain,Ytrain)
score = model.score(Xtest,Ytest)
print('The accuracy of the DecisionTreeClassifier is',score)The accuracy of the DecisionTreeClassifier is 0.8097014925373134
可以调到0.8320
随机森林
model=RandomForestClassifier()
model.fit(Xtrain,Ytrain)
score = model.score(Xtest,Ytest)
print('The accuracy of the RandomForestClassifier is',score)The accuracy of the RandomForestClassifier is 0.8470149253731343SVM
model=svm.SVC()
model.fit(Xtrain,Ytrain)
score=model.score(Xtest,Ytest)
print('Accuracy for linear SVM is',score)Accuracy for linear SVM is 0.8171641791044776LogisticRegression
model = LogisticRegression()
model.fit(Xtrain,Ytrain)
score = model.score(Xtest,Ytest)
print('The accuracy of the Logistic Regression is',score)The accuracy of the Logistic Regression is 0.8022388059701493KNN
model=KNeighborsClassifier(n_neighbors=6)
model.fit(Xtrain,Ytrain)
score = model.score(Xtest,Ytest)
print('The accuracy of the KNN is',score)The accuracy of the KNN is 0.8246268656716418
贝叶斯
model=GaussianNB()
model.fit(Xtrain,Ytrain)
score = model.score(Xtest,Ytest)
print('The accuracy of the GaussianNB is',score)The accuracy of the GaussianNB is 0.7910447761194029
决策树调参
1.max_depth
c_score = []
s = []
C = range(1,10)
for i in C:
clf = DecisionTreeClassifier(max_depth=i
,random_state=90
,splitter="random"
)
clf = clf.fit(Xtrain, Ytrain)
c_score.append(cross_val_score(clf,Xtrain,Ytrain).mean())
s.append(clf.score(Xtest, Ytest))
print('max_cross_score:',max(c_score))
print('max_score:',max(s),'max_depth',s.index(max(s))+1)
plt.plot(C,s,color="red",label="max_depth")
plt.legend()
plt.show()
2.min_samples_leaf
score_l= []
C = range(1,15)
for i in C:
clf = DecisionTreeClassifier(max_depth=5,random_state=90,splitter="random"
,min_samples_leaf = i)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score_l.append(score)
print('max_score:',max(test),"min_samples_leaf:",test.index(max(test))+1)
plt.plot(C,score_l,color="blue",label="min_samples_leaf")
plt.legend()
plt.show()
K折交叉验证
from sklearn.model_selection import KFold #for K-fold cross validation
from sklearn.model_selection import cross_val_score #score evaluation
from sklearn.model_selection import cross_val_predict #prediction
kfold = KFold(n_splits=10, random_state=22) # k=10, split the data into 10 equal parts
xyz=[]
accuracy=[]
std=[]
classifiers=['Linear Svm','Radial Svm','Logistic Regression','KNN','Decision Tree','Naive Bayes','Random Forest']
models=[svm.SVC(kernel='linear'),svm.SVC(kernel='rbf'),LogisticRegression(),
KNeighborsClassifier(n_neighbors=5),
DecisionTreeClassifier(max_depth=5,random_state=90,splitter="random",min_samples_leaf = 3),GaussianNB(),
RandomForestClassifier()]
for i in models:
model = i
cv_result = cross_val_score(model,Xtrain,Ytrain, cv = kfold,scoring = "accuracy")
cv_result=cv_result
xyz.append(cv_result.mean())
std.append(cv_result.std())
accuracy.append(cv_result)
new_models_dataframe2=pd.DataFrame({'CV Mean':xyz,'Std':std},index=classifiers)
new_models_dataframe2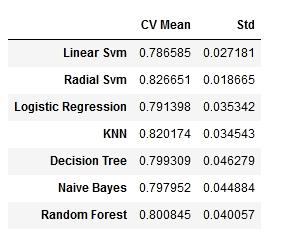
plt.subplots(figsize=(12,6))
box=pd.DataFrame(accuracy,index=[classifiers])
box.T.boxplot()
混淆矩阵
f,ax=plt.subplots(2,3,figsize=(12,10))
y_pred = cross_val_predict(svm.SVC(kernel='rbf'),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,0],annot=True,fmt='2.0f')
ax[0,0].set_title('Matrix for rbf-SVM')
y_pred = cross_val_predict(svm.SVC(kernel='linear'),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,1],annot=True,fmt='2.0f')
ax[0,1].set_title('Matrix for KNN')
y_pred = cross_val_predict(RandomForestClassifier(n_estimators=100),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,2],annot=True,fmt='2.0f')
ax[0,2].set_title('Matrix for Random-Forests')
y_pred = cross_val_predict(LogisticRegression(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,0],annot=True,fmt='2.0f')
ax[1,0].set_title('Matrix for Logistic Regression')
y_pred = cross_val_predict(DecisionTreeClassifier(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,1],annot=True,fmt='2.0f')
ax[1,1].set_title('Matrix for Decision Tree')
y_pred = cross_val_predict(GaussianNB(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,2],annot=True,fmt='2.0f')
ax[1,2].set_title('Matrix for Naive Bayes')
plt.subplots_adjust(hspace=0.2,wspace=0.2)
plt.show()
解释混淆矩阵:来看第一个图
1)预测的正确率为491(死亡)+ 247(存活),平均CV准确率为(491+247)/ 891=82.8%。
2)58和95都是弄错了的。
投票分类器 这是将许多不同的简单机器学习模型的预测结合起来的最简单方法。它给出了一个平均预测结果基于各子模型的预测。
from sklearn.ensemble import VotingClassifier
ensemble_lin_rbf=VotingClassifier(estimators=[('KNN',KNeighborsClassifier(n_neighbors=10)),
('RBF',svm.SVC(probability=True,kernel='rbf',C=0.5,gamma=0.1)),
('RFor',RandomForestClassifier(n_estimators=500,random_state=0)),
('LR',LR(C=0.05)),
('DT',DecisionTreeClassifier(random_state=0)),
('NB',GaussianNB()),
('svm',svm.SVC(kernel='linear',probability=True))
],
voting='soft').fit(Xtrain,Ytrain)
print('The accuracy for ensembled model is:',ensemble_lin_rbf.score(Xtest,Ytest))
cross=cross_val_score(ensemble_lin_rbf,Xtrain,Ytrain, cv = 10,scoring = "accuracy")
print('The cross validated score is',cross.mean())
0.8379目前最高
网格搜索调参
from sklearn.model_selection import GridSearchCV
C=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
gamma=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]
kernel=['rbf','linear']
hyper={'kernel':kernel,'C':C,'gamma':gamma}
gd=GridSearchCV(estimator=svm.SVC(),param_grid=hyper,verbose=True)
gd.fit(Xtrain,Ytrain)
print(gd.best_score_)
print(gd.best_estimator_)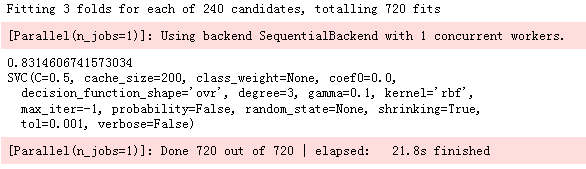
model=RandomForestClassifier(max_depth=7,random_state=90)
model.fit(Xtrain,Ytrain)
pd.Series(model.feature_importances_,Xtrain.columns).sort_values(ascending=True).plot.barh(width=0.8)
plt.title('Feature Importance in Random Forests')
plt.show()
AdaBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier(n_estimators=200,random_state=0,learning_rate=0.1)
result = cross_val_score(ada,Xtrain,Ytrain,cv=10,scoring='accuracy')
print('The cross validated score for AdaBoost is:',result.mean())
score = ada.fit(Xtrain,Ytrain).score(Xtest,Ytest)
print('The accuracy score for AdaBoost is:',score)The cross validated score for AdaBoost is: 0.8228968253968253
The accuracy score for AdaBoost is: 0.8268156424581006AdaBoostClassifier 网格搜索
from sklearn.model_selection import GridSearchCV
n_estimators=list(range(50,300,10))
learn_rate=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
hyper={'n_estimators':n_estimators,'learning_rate':learn_rate}
gd=GridSearchCV(estimator=AdaBoostClassifier(random_state=0),param_grid=hyper,verbose=True)
gd.fit(Xtrain,Ytrain)
print(gd.best_score_)
print(gd.best_estimator_)0.824438202247191
AdaBoostClassifier(algorithm='SAMME.R', base_estimator=None,
learning_rate=0.3, n_estimators=100, random_state=0)from sklearn.ensemble import GradientBoostingClassifier
grad=GradientBoostingClassifier(n_estimators=500,random_state=0,learning_rate=0.1)
result=cross_val_score(grad,Xtrain,Ytrain,cv=10,scoring='accuracy')
print('The cross validated score for Gradient Boosting is:',result.mean())
score = grad.fit(Xtrain,Ytrain).score(Xtest,Ytest)
print('The accuracy score for Gradient Boosting is:',score)The cross validated score for Gradient Boosting is: 0.7694841269841269
The accuracy score for Gradient Boosting is: 0.8044692737430168
Xgboost
from xgboost import XGBClassifier as XGBC
from sklearn.model_selection import cross_val_predict
reg = XGBC(n_estimatores=200,max_depth=3,learning_rate = 0.2)
result = cross_val_score(reg,Xtrain,Ytrain,cv=10,scoring='accuracy')
print('The cross validated score for Xgboost is:',result.mean())
score = reg.fit(Xtrain,Ytrain).score(Xtest,Ytest)
print('The accuracy score for Xgboost is:',score)
pred_result=cross_val_predict(reg,X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,pred_result),cmap='winter',annot=True,fmt='2.0f')
plt.show()















 2930
2930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









