







对大树先生titanic数据集处理的总结:
本文对大数先生所做的titanic数据集进行进一步整理:
精确到解说每一步需要做什么掌握什么。
原代码链接
原文中数据处理主要分为8大类:
1.数据总览(教你浏览数据)
2.缺失数据处理办法(根据具体缺失的数据找方法对数据进行填充)
3.分析数据关系(教画图,从图像上找出各特征与生存之间的关系)
4.变量转换(介绍了数据预处理的方法)
5.特征工程(对数据进行特征提取)
6.模型融合及测试(建模调参)
7.验证(学习曲线)
8.超参数调试(调参)
1.数据总览
拿到数据集合我们需要看一眼数据集中的内容数据集中都有什么。
所需要的库:pandas
1.用pandas打开数据集
#使用read_csv()打开数据集这里需要相对路径如果你不知道相对路径
#可以通过import os对自己当前目录进行一个测试
train_data = pd.read_csv('datalab/1386/titanic_train.csv')
2.对书籍集进行观测
目前笔者接触到3种方案:
#观测数据前5行
train_data.head()
#显示数据集中数据量可以清楚看到数据集是否缺失
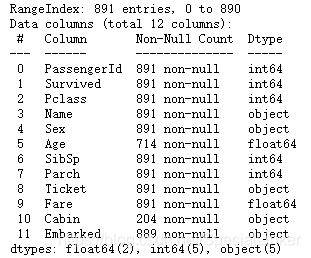
train_data.info()
#对数据信息进行描述包括每列对应的数量、方差平均值
train_data.describe()
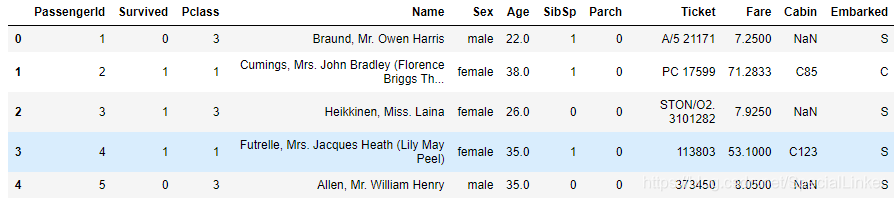
这里对titanic数据集每列的label进行解释:
PassengerId=》乘客的ID
Survived=》是否存活
Pclass=》船舱等级
Name=》乘客姓名
Sex=》乘客性别
Age=》乘客年龄
SibSp=》有无兄弟姐妹
Parch=》有无父母子女
Ticket=》登船票号
Fare=》票价
Cabin=》船舱类型
Embarked=》所到达的港口
这里是使用info的方法对数据进行浏览,可以观测出数据中存在缺失值
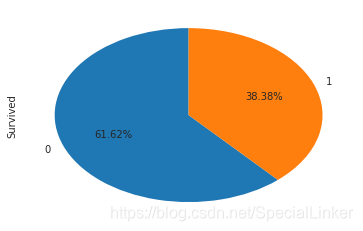
#这里画个饼图来观测存活情况顺便介绍一下饼图的画法
train_data['Survived'].value_counts().plot.pie(labeldistance = 1.1,autopct = '%1.2f%%',
shadow = False,startangle = 90,pctdistance = 0.6)
#labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
#autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
#shadow,饼是否有阴影
#startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
#pctdistance,百分比的text离圆心的距离
#patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
2.缺失数据处理办法
1.首先对缺失数据进行分析
缺失依次为Age,Cabin,Embarked接下来要对缺失数据进行分析
观察类型以及数据缺失程度
Age=》不规则的数字
Cabin=》一艘船上只有几个船舱(英文)
Embarked=》到达的港口(英文)
如果数据集很多,但有很少的缺失值,可以删掉带缺失值的行;
如果该属性相对学习来说不是很重要,可以对缺失值赋均值或者众数。
对于标称属性,可以赋一个代表缺失的值,比如‘U0’。因为缺失本身也可能代表着一些隐含信息。比如船舱号Cabin这一属性,缺失可能代表并没有船舱。
由于数据量少所以选择将数据全部进行填充
#首先是到达港口缺失较少选择使用众数来进行填充mode()
train_data.Embarked[train_data.Embarked.isnull()] = train_data.Embarked.dropna().mode().values
#其次由于Cabin属性缺失过多可能代表没有船舱其实缺失数据本身可能就是一种隐藏属性。
train_data['Cabin'] = train_data.Cabin.fillna('U0')
对于Age这种对模型影响比较大的参数可以选择多种方法进行补充:
作者选择使用随机森林回归的方法对模型进行训练用来预测Age的值
from sklearn.ensemble import RandomForestRegressor
#选择数据预测年龄
age_df = train_data[['Age','Survived','Fare', 'Parch', 'SibSp', 'Pclass']]
age_df_notnull = age_df.loc[(train_data['Age'].notnull())]
age_df_isnull = age_df.loc[(train_data['Age'].isnull())]
X = age_df_notnull.values[:,1:]
Y = age_df_notnull.values[:,0]
# 使用随机森林的方法去预测模型其中n_estimators=1000最大允许使用1000个若学习器
# n_job=-1CPU并行计算的核数(设置为-1表示对CPU核数不限制)
# 之后会对本文所用到的所有模型进行整理归纳
RFR = RandomForestRegressor(n_estimators=1000, n_jobs=-1)
RFR.fit(X,Y)
predictAges = RFR.predict(age_df_isnull.values[:,1:])
train_data.loc[train_data['Age'].isnull(), ['Age']]= predictAges
到这里为止数据已经完全补充完全
3.分析数据关系
这张主要讲的是个数据分析也就是数据可视化应该如何画图,笔者以为能画好图对数据分析非常重要
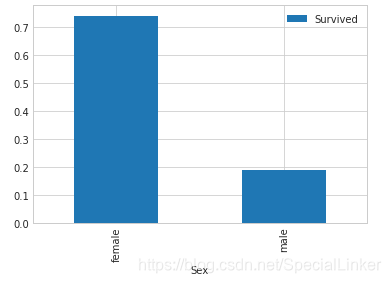
3.1Sex 与Survived 之间的关系(直方图画法)
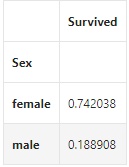
#这里用到了groupby函数:以sex进行分组对其他参量进行求平均
train_data[['Sex','Survived']].groupby(['Sex']).mean()
#这里非常方面可以直接接在数据后面用plot.bar进行图标绘制
#以sex为横坐标Survived为纵坐标
train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
可直观看出女士优先体现出性别的重要性
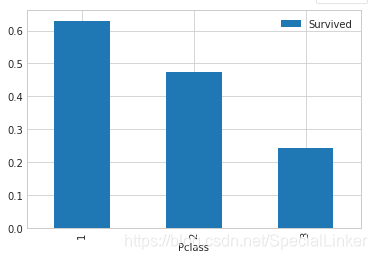
3.2 Pclass vs Survived(依旧是直方图这里重复的东西不做过多解释)
train_data[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar()
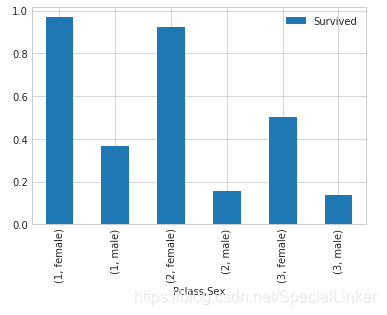
#这里也解释一下这里groupby的意思是以Pclass分类后再对Pclass中的sex进行分类
train_data[['Sex','Pclass','Survived']].groupby(['Pclass','Sex']).mean().plot.bar()
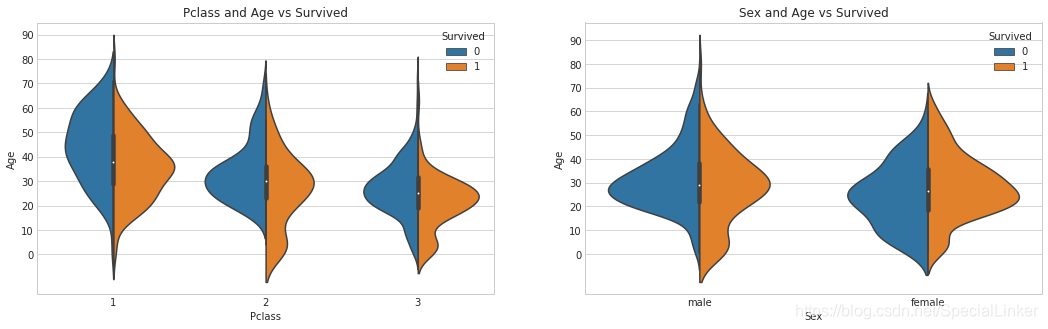
3.3 Age 与 Survived之间的关系
因为Age是离散化较高的一个数据所以图形画法比较多结合数据集整合
3.3.1 小提琴图
分别分析不同等级船舱和不同性别下的年龄分布和生存的关系:
X[Pclass] Y[Age] hue[Survived]
#对画布进行布局
fig,ax = plt.subplots(1,2, figsize = (18,5))
#对y轴进行范围设置
ax[0].set_yticks(range(0,110,10))
#对sns.violinplot进行传参x为Pclass y为Age 需要对比的是Survived
#这里我们分析一下什么样的数据类型可以画小提琴图
#也就是说X类别比较少的一类参数Y为类别比较大 hue为2分类情况
sns.violinplot("Pclass","Age",hue="Survived",data=train_data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age",hue="Survived",data=train_data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
plt.show()
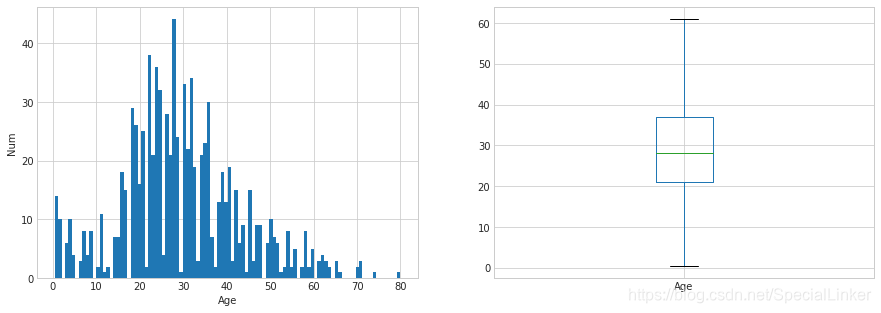
3.3.2 hist 分布直方图和盒图(单列数据作图)
#另一种布置方式
plt.figure(figsize=(15,5))
plt.subplot(121)
#单列作图图主要用于看Age在数据集中的分布bins代表柱的个数
train_data['Age'].hist(bins=100)
plt.xlabel('Age')
plt.ylabel('Num')
plt.subplot(122)
#盒图很坐标为Age纵坐标为年龄尺度后面还会有对盒子图的介绍(详细用法)
train_data.boxplot(column='Age',showfliers=False)
plt.show()
3.3.3 使用FacetGrid进行作图作kdeplot曲线图通过拟合的一种曲线
不同年龄下的生存和非生存的分布情况:
#前期对facet进行设定1.数据集2.hue指定参数进行区分
facet = sns.FacetGrid(train_data,hue="Survived",aspect=4)
#用map进行作图1.图的类型sns.kdeplot 2.作图的数据3.Shade是否需要填充
facet.map(sns.kdeplot,'Age',shade=True)
#对x轴的范围进行设置
facet.set(xlim=(0,train_data['Age'].max()))
#添加hue的标签
facet.add_legend()
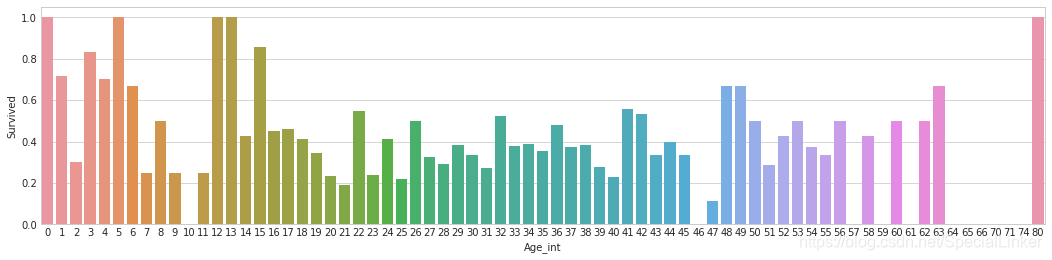
3.3.4不同年龄下的平均生存率:(使用sns进行绘制直方图主要是好看)
fig,axis1 = plt.subplots(1,1,figsize=(18,4))
#绘制直方图对Age需要进行转格式
train_data['Age_int'] = train_data['Age'].astype(int)
#这里是不是很熟悉对也可以用上述绘制直方图的方式进行作图
average_age = train_data[["Age_int", "Survived"]].groupby(['Age_int'],as_index=False).mean()
1.X 2.Y 3.Data
sns.barplot(x='Age_int',y='Survived',data=average_age)
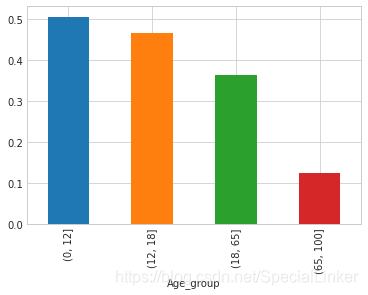
3.3.5 对年龄进行分类看看不同年龄区间对生存的影响
bins = [0, 12, 18, 65, 100]
#采用pd.cut对年龄进行划分将具体的Age归类到具体的区间
train_data['Age_group'] = pd.cut(train_data['Age'],bins)
by_age = train_data.groupby('Age_group')['Survived'].mean()
print(by_age)
by_age.plot(kind = 'bar')
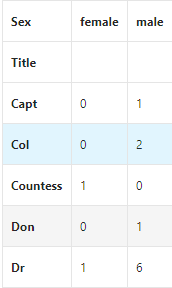
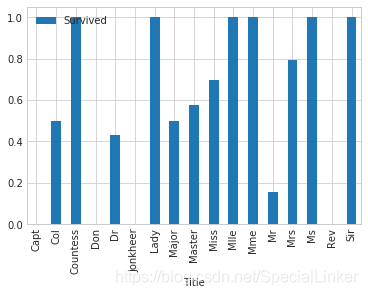
3.4称呼与存活之间的关系
通过观察名字数据,我们可以看出其中包括对乘客的称呼,如:Mr、Miss、Mrs等,称呼信息包含了乘客的年龄、性别,同时也包含了入社会地位等的称呼,如:Dr,Lady,Major(少校),Master(硕士,主人,师傅)等的称呼。
#姓名中提取.之前的称呼
train_data['Title'] = train_data['Name'].str.extract(' ([A-Za-z]+)\.',expand=False)
#交叉透视表看称呼与性别之间的关系
pd.crosstab(train_data['Title'],train_data['Sex'])
train_data[['Title','Survived']].groupby(['Title']).mean().plot.bar()
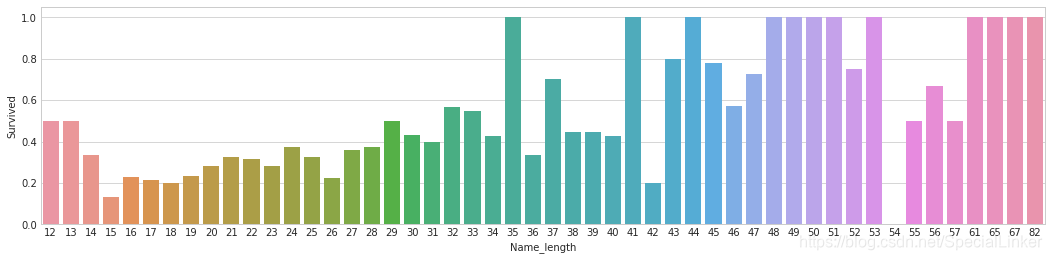
这里作者提到了一个比较玄学的概念名字长度与生存之间的关系
fig, axis1 = plt.subplots(1,1,figsize=(18,4))
train_data['Name_length'] = train_data['Name'].apply(len)
name_length = train_data[['Name_length','Survived']].groupby(['Name_length'], as_index=False).mean()
sns.barplot(x='Name_length', y='Survived',data=name_length)
3.5 有无兄弟姐妹和存活与否的关系 SibSp(饼图)
value_counts().plot.pie()
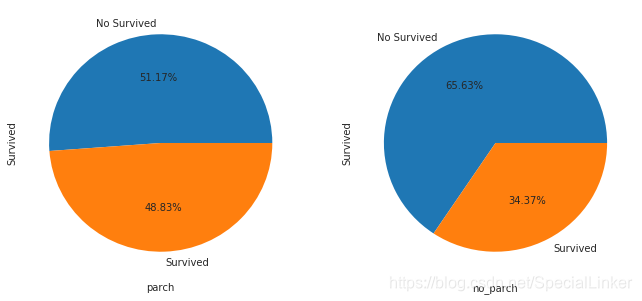
3.6 有无父母子女和存活与否的关系 Parch(饼图)
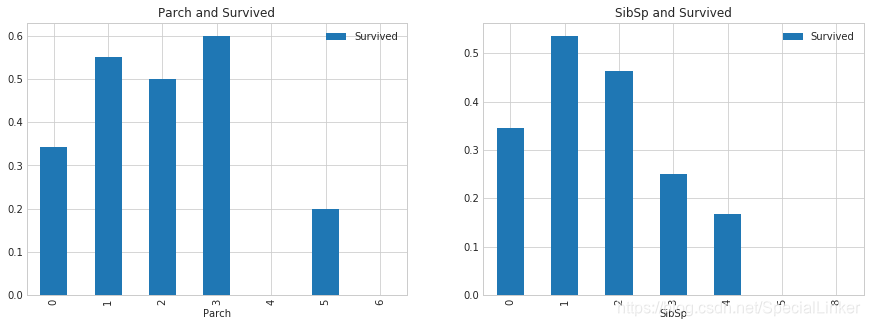
3.7亲友的人数和存活与否的关系 SibSp & Parch(直方图)
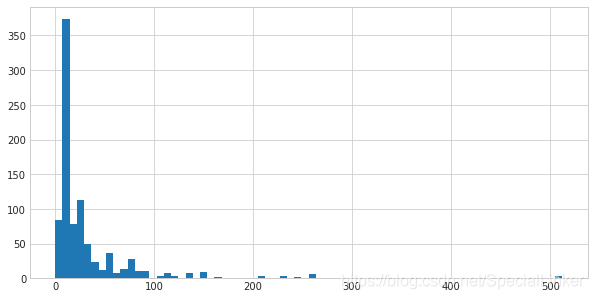
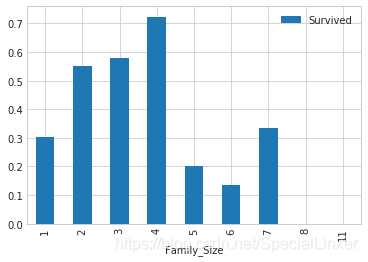 3.8 票价分布和存活与否的关系 Fare
3.8 票价分布和存活与否的关系 Fare
hist
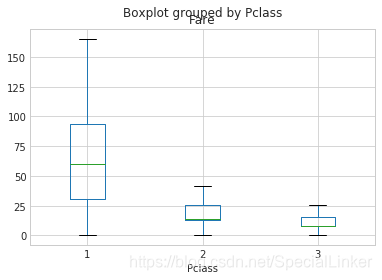
这里绘制票价与Pclass的关系盒图
#以Pclass进行分类每列都代表票价
train_data.boxplot(column='Fare', by='Pclass', showfliers=False)
绘制生存与否与票价均值和方差的关系:
fare_not_survived = train_data['Fare'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2496
2496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









