







文章目录
第8章 其他NoSQL数据库
概述
- NoSQL并非是一个严谨的概念,包含很多能够进行数据管理和查询的系统,诸如:
- 图数据库:专门描述点线关系的数据库,例如Neo4j
- (用于缓存系统的)键值对数据库:实际仍是键值对模型,但侧重将数据转载到内存,以提升数据查询速度,例如:Redis和Memcache
- 搜索引擎:强调实现文本类数据的全文检索功能,例如:Solr
- 其他特殊的数据库:
- 环形数据库:类似于MongoDB中的定长集合,主要用于监控系统中绘制图表时提供数据支持,例如:rrdtool
- 时序数据库:专门存储时序数据,例如监控日志的数据库,例如InfluxDB等
8.1 图数据库简介
- 图是指将数据存储为顶点(或称为实体)和边(或称为关系)的数据存储模式,也可以称此类关系为网络。
- 图数据库专门描述节点与关系。对比关系型数据库,图数据库中对数据关系进行了简化,边和节点以不同的方式描述和管理。
- 图数据库与关系型数据库
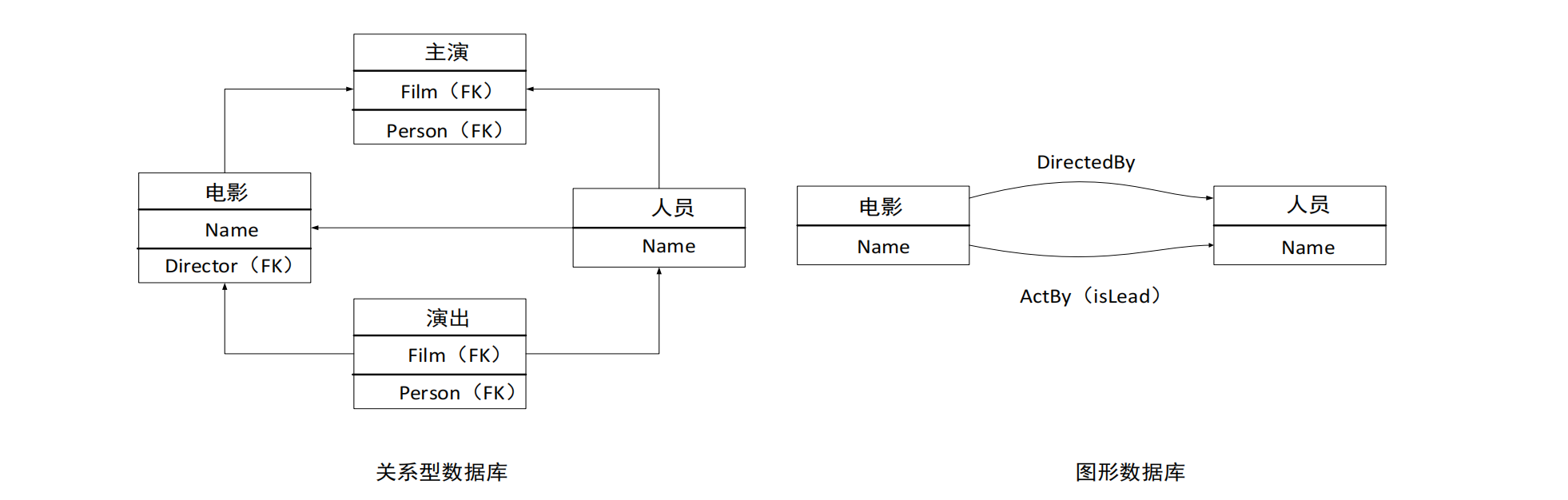
- 数据模式:节点/关系/属性/标签
- 节点
- 节点是主要的数据元素
- 节点通过 关系 连接到其他节点
- 节点可以具有一个或多个 属性
- 节点有一个或多个 标签 ,用于描
- 其在图表中的作用(示例:人员节点与Car节点)
- 关系
- 关系连接两个节点
- 关系是方向性的
- 节点可以有多个甚至递归的关系
- 关系可以有一个或多个属性
- 属性
- 属性是命名值,其中名称(或键)是字符串
- 属性可以被索引和约束
- 可以从多个属性创建复合索引
- 标签
- 标签用于将 节点 分组
- 一个节点可以具有多个标签
- 对标签进行索引以加速在图中查找节点
- 本机标签索引针对速度进行了优化
- 节点
- 发展趋势:
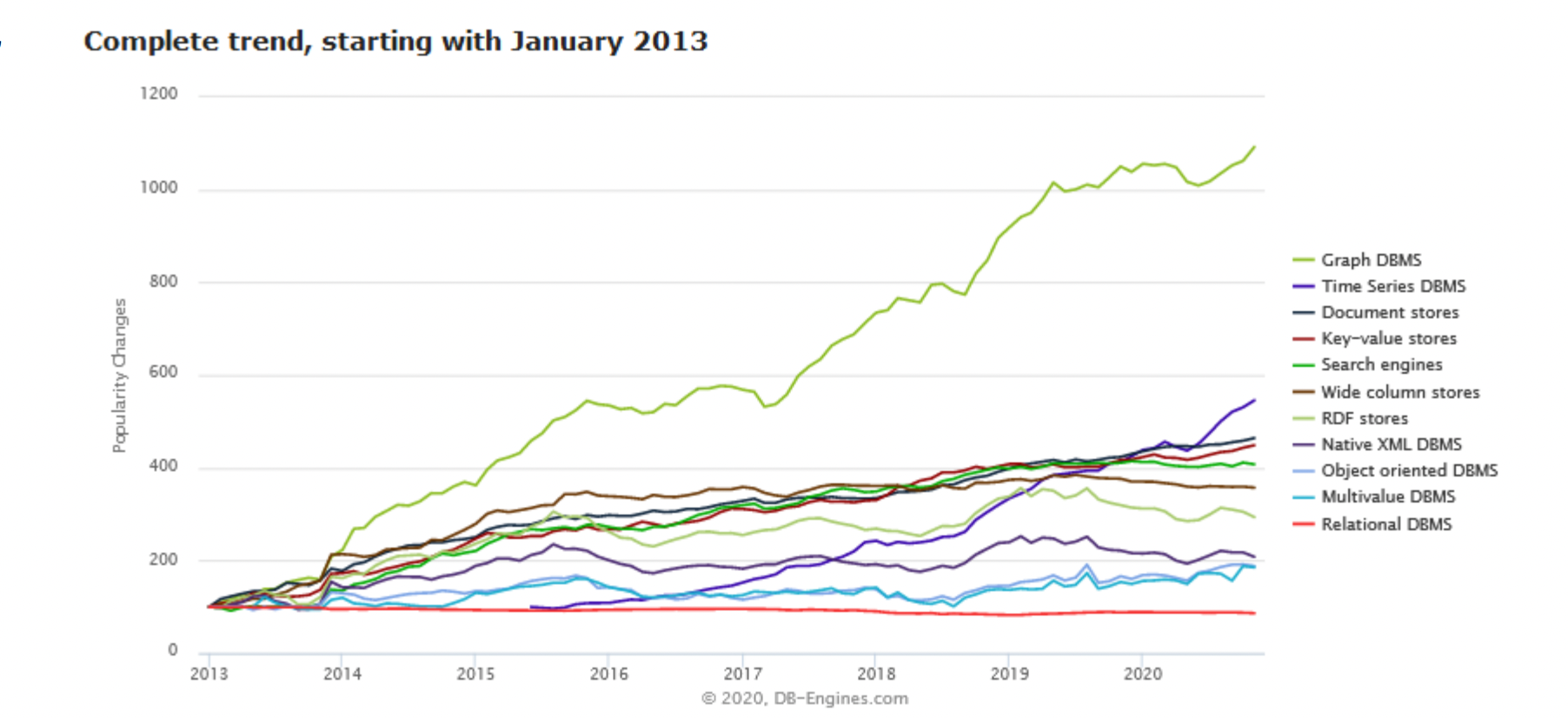
- 应用场景:

8.2 Neo4j
8.2.1 Neo4j 简介
- Neo4j是一个基于Java语言的开源图数据库系统,Neo Technology公司维护。
- 2018年11月,Neo4j 宣布3.5 版本后企业版将闭源,但社区版仍会被维护,且保持开源
- Neo4j具有强大的图处理和查询搜索能力,通过专用的Cypher语言,可以非常便利地完成各类操作。
- 目前Neo4j一般采用单机部署,但支持比较严格的事务机制,并可以提供数据的强一致性。
- 谷歌公司曾于2010年发表论文Pregel: A System for Large-Scale Graph Processing,介绍 了一种名为Pregel的分布式图计算模型。
- Apache Spark中的GraphX模块是一个Pregel模型的具体实现,运算性能较高
- 但GraphX不像Neo4j一样强调图数据的管理与查询等功能。
- Neo4j集群由两个不同的角色Primary Servers和Secondary Servers组成。
- 主服务器( Primary Servers )的主要责任是保护数据。核心服务器通过使用Raft协议复制所有事务来做到这一点。在确认向最终用户应用程序提交事务之前,Raft确保数据安全持久。
- 从服务器( Secondary Servers )的主要职责是扩展图数据负载能力。 只读副本的作用类似于Core Server保护的数据的缓存,但它们不是简单的键值缓存。 实际上,只读副本是功能齐全的Neo4j数据库,能够完成任意(只读)图数据查询和过程。
- 因果一致性
- 因果一致性使得可以写入Core Server(数据是安全的)并从Read Replica(其中图操作被扩展)中读取这些写入。
- 例如,因果一致性可确保当该用户随后尝试
登录时,会出现创建该用户帐户的写操作。


8.2.2 Neo4j 的安装与实践
8.3 Redis和内存数据库
8.3.1 内存数据库
- 一般是键值对数据库,但强调基于内存的数据管理,例如:Redis、Memcache
- 经常作为缓存系统使用
- 一些关系型数据库也提供了“分布式内存数据库”缓存方案,例如MySQL的NDB(MySQL Cluster)
- 通常会和“WEB开发”联系在一起,而非“大数据”,在WEB架构设计与系统开发领域很热门
8.3.2 Redis
- Redis :
- Redis 是一个开源(BSD许可)的,内存数据结构存储系统,它可以用作数据库、缓存和消息中间件。
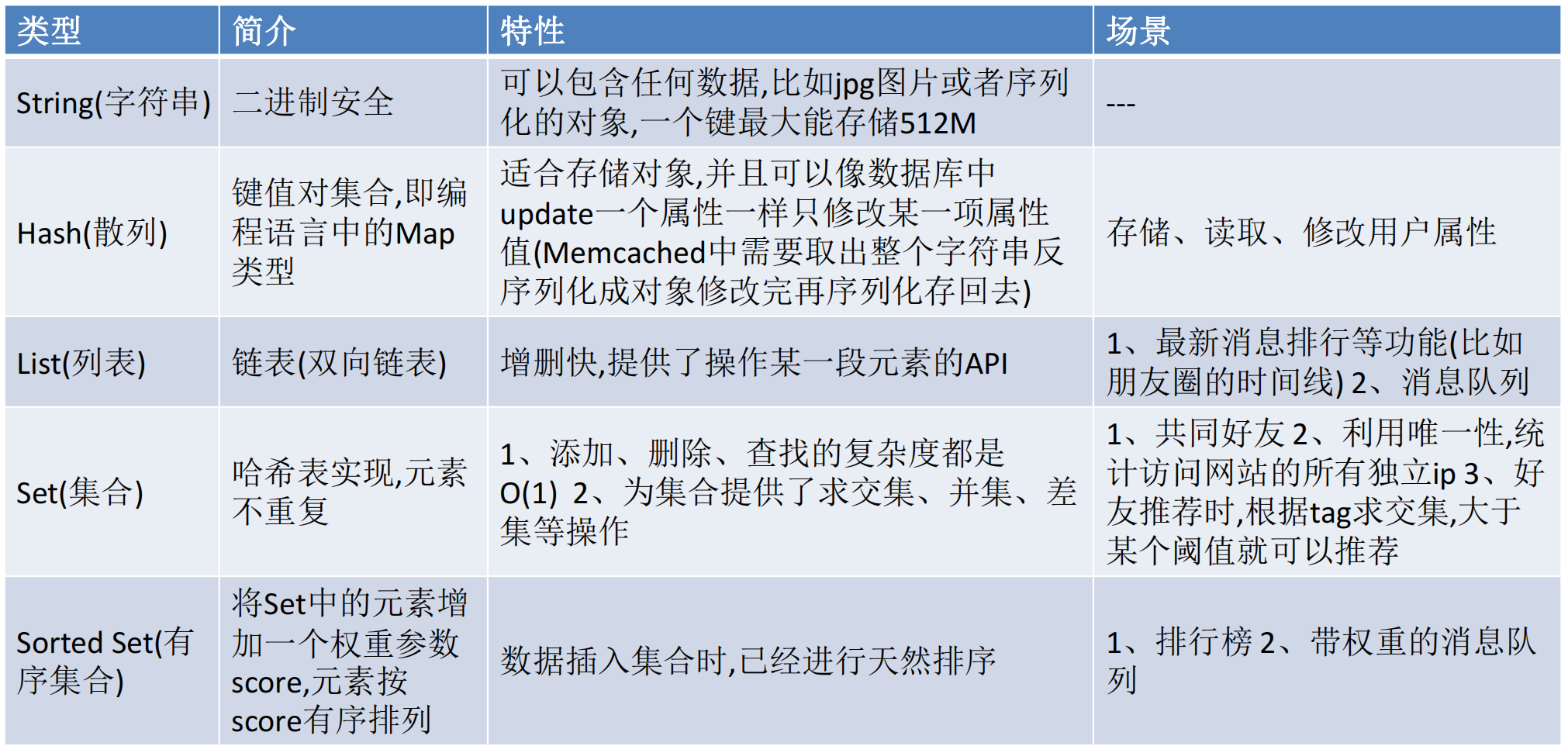
- 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets),有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
- Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)。
- https://redis.io/
- Redis特性:
- 存储结构:Redis 支持的数据类型有字符串、散列、列表、集合、有序集合。
- 内存存储与持久化:Redis数据库的所有数据都存储在内存中。Redis也提供了持久化的支持,即将内存中的数据异步写入硬盘中,同时不影响继续提供服务。
- 功能丰富:可以用作缓存、队列系统。例如,Redis可作为缓存系统,并且可以为每个键设置生存时间,生存时间到期后键会自动删除;Redis还支持“发布/订阅”的消息模式,等等。
- 简单稳定:在Redis中使用命令来读写数据,提供了几十种不同编程语言的客户端库。 Redis是开源的,良好的开发氛围和严谨的版本发布机制使得Redis的稳定版本更加可靠
- Redis应用场景:存在大规模数据访问,对数据查询效率要求高,且数据结构简单,不涉及太多关联查询。
- (电商网站)秒杀抢购
- (视频直播)消息弹幕
- (游戏应用)游戏排行榜
- (社交APP)返回最新评论/回复
- Redis数据类型:
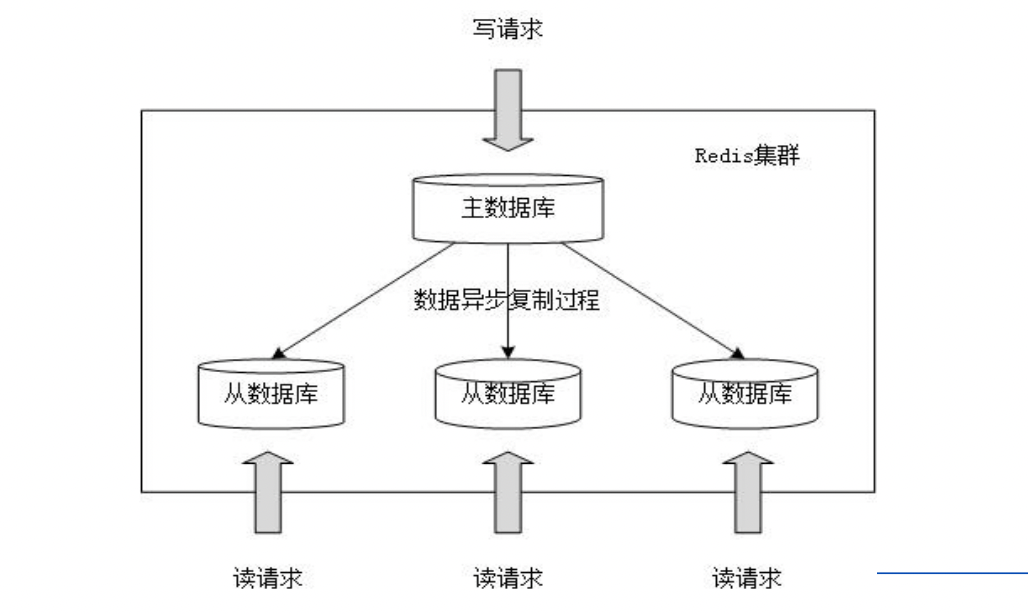
- 主从复制:如果主服务器宕机,从服务器可以替代主服务器来为客户端服务,相当于备份。并且可以把持久化的配置在从服务器端来减轻主服务器的压力,主服务器不做持久化,由从服务器负责。
- 哨兵机制:哨兵(sentinal)是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 master 并将所有的 slave 连接到新的 master。
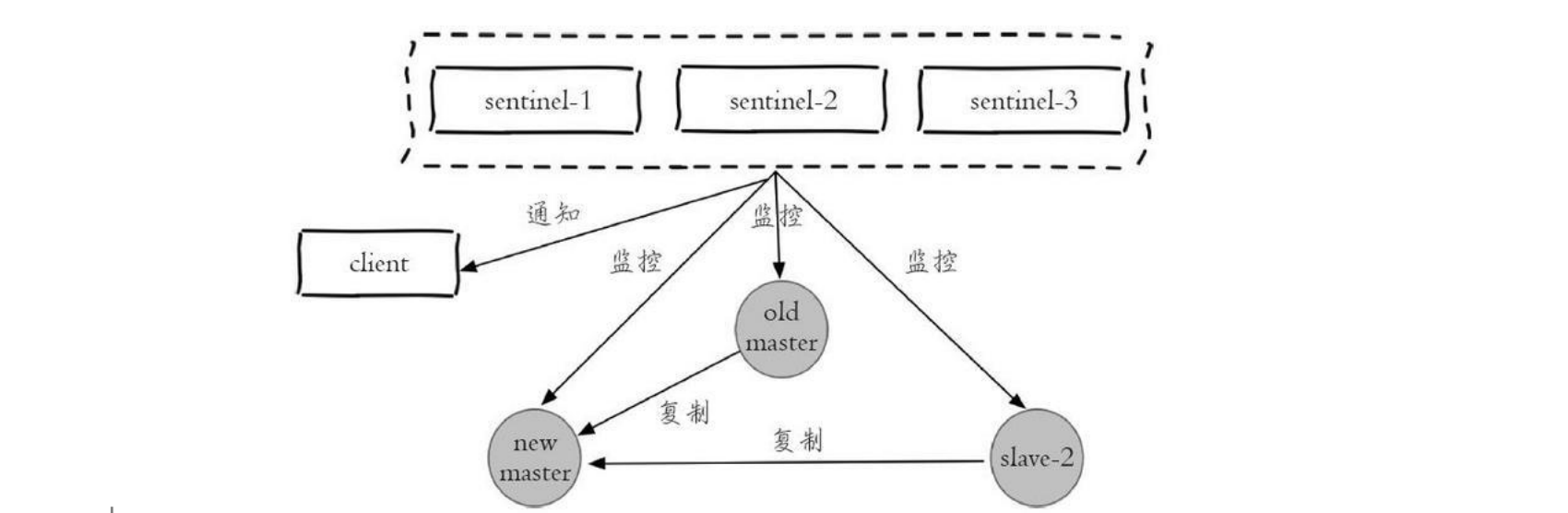
- Redis集群:
- Redis没有使用一致性哈希机制,而是引入了哈希槽的概念。Redis 集群有16384个哈希槽,集群中所有设备平分这些哈希槽,数据则根据其行键的散列计算结果,映射到不同的哈希槽中。在集群中添加、去除或改变节点信息,都会涉及对哈希槽的重新分配。
- 支持数据多副本、主从复制机制
- 支持主节点选举机制
- 在内存管理方面,Redis支持最近最少使用算法(Least Recently Used,LRU)
8.3.3 Redis安装与实践
8.4 搜索引擎系统
8.4.1 搜索引擎系统
- 搜索引擎(Search Engine)系统,也称全文检索系统,一般被用作Web搜索引擎,或者用于限定行业、领域的垂直模糊搜索领域
- 常见的Web搜索引擎服务可以看作是搜索引擎系统和网络爬虫系统(负责抓取并分析网页和链接)的结合
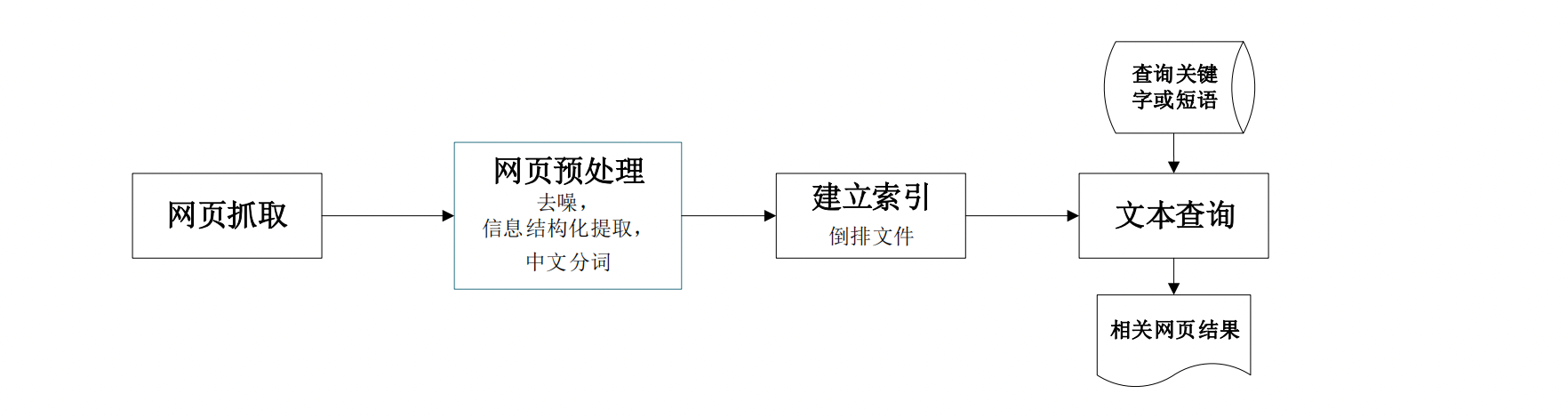
- 不同于NoSQL数据库,搜索引擎通过建立独特的索引机制和查询方法,实现高效的全文模糊查询,甚至处理查询结果排名等细节问题,但对原始数据(可能是结构化、半结构化或非结构化信息)的存储、管理等方面并不涉及。
- 搜索引擎系统常和其他NoSQL数据库或分布式文件系统配合使用,如HBase、HDFS等,由后者实现原始数据的分布式存储和管理。
8.4.2 常见搜索引擎
1. Nutch
- Nutch是一个基于Java的分布式开源搜索引擎,由Apache软件基金会维护。Nutch包括全文检索和网络爬虫(crawler)两个部分,当爬虫抓取网页之后,一般会将其保存在HDFS之上,并通过MapReduce实现对网页的分析,以获取标题、正文、链接等元素,并建立“倒排索引”。
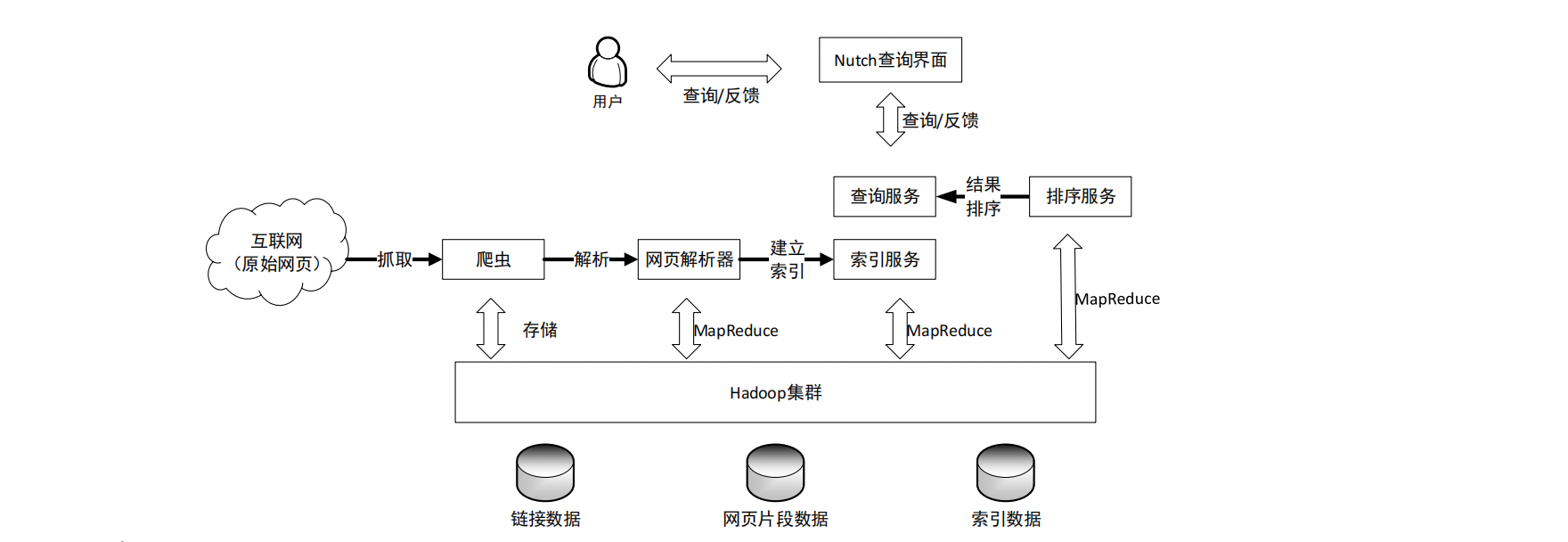
2. Lucene
- Nutch通过Lucene引擎实现网页以及全文索引的建立。Lucene创立于2000年,目前也是Apache软件基金会的顶级开源项目
- Lucene所建立的索引称为倒排索引(Inverted Index),这种索引是从字符串(如单词)映射到全文
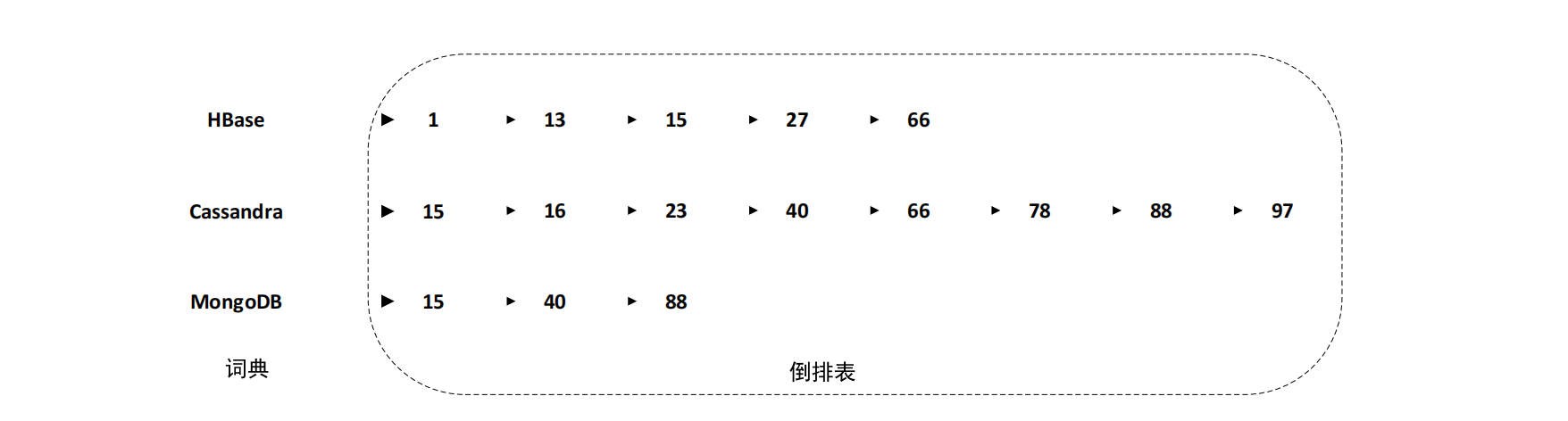
- Lucene需要借助Hadoop实现分布式的网页处理和索引维护
- 在全文检索(建立索引和进行搜索)时,对于汉语,由于其词汇之间没有空格,因此需要借助中文分词组件(如IKAnalyzer)进行单词切分
- 对于相关性,一般考虑两个权重:TF和IDF。
- 如果查询词在某篇文本中出现的次数多,则该文本的相关度较高,该权重称为TF(Term Frequency),即词频。
- 如果查询词在多篇文档中的出现频率都很高,则该词汇重要性较小,如一些连词、量词等,该权重称为IDF(Inverse Document Frequency),即逆文档词频。将这两个权重相乘,就得到了一个词的TF-IDF值,该值越大,即说明该文本的相关度越高。
- 还需要考虑对搜索结果的排名
- 典型权重算法:PageRank算法
3. Solr 和 Elasticsearch
- 使用Solr和Elasticsearch等开源软件,可以降低使用和管理难度。
- Solr是由Java开发的基于Lucene的完整的开源企业级全文检索引擎系统,目前也由Apache软件基金会维护。
- Solr也对Lucene进行了封装、完善和扩展,提供了比Lucene更丰富的查询语言,实现了可配置、可扩展,并对查询性能进行了优化,提供了一个完善的功能管理界面。
- Elasticsearch也是一个基于Lucene的企业级搜索引擎系统,目前已经有独立的公司来进行维护,但其基本产品仍保持开源免费状态。
- 一般认为Elasticsearch的实时搜索能力较强,对于大数据的分布式处理能力更强
- 可以和Spark等大数据处理工具相结合使用
- 目前看来,两个软件和lucene、Nutch相比,热度更高
8.5 小结 & 思考题
小结:
- 图数据库是一种简单易用的、处理点线关系的数据库
- 在Windows上安装也很方便
- 一般单机使用,而非集群化部署
- 通过Cypher语言操作数据
- “内存数据库”
- 可以看作键值对数据库的分支
- 通常作为WEB架构中的缓存系统
- 其分布式部署策略和Cassandra、MongoDB等均有相通之处
- 全文检索和搜索引擎
- 可能和Hadoop、HBase建立联系
- 学习的重点在于算法和优化
- 可以直接使用Solr、Elasticsearch等集成化软件
思考题:
- 描述Redis的数据类型(5种)。
- Redis数据库的拓扑架构和多副本策略。















 4749
4749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









