






论文
1 Introduction
先前的研究都是将人体的整个步态作为网络输入进行特征提取,而本文最大的亮点在于发现人体步态的不同部分在形状以及行走时的移动模式上具有显著的区别,并且这些信息将为网络提供更多的细粒度信息,并且为此设计出了FConv模块(FPFE)和MCM模块,并且提出了基于当前为止的SOTA网络:

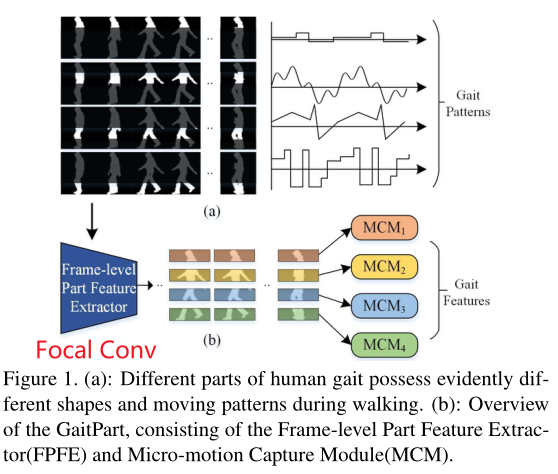
核心模块:
① FPFE(帧级特征提取器):利用Focal Convolution(焦点卷积)提供步态局部细节,获得细粒度的空间特征
② MCM(微动作捕捉模块):微动作模式是最具有判别性表示的特征,利用基于注意力及机制的MCM对局部微动作进行建模,进而全局理解整个步态序列
2 Related Work
在行人重识别(判断图像或者视频序列中是否存在特定的行人)任务中,特征图分割为条带并合成为列向量的Part-based方法应用广泛,它忽略了空间对齐。
但是不同于行人重识别领域中的part-independent(人体各个部位有可能具有相同属性,例如颜色和纹理),GaitPart应该设计为一种Part-dependent的方式,因为人体各个部分在外观和运动模式上有显著差异。

**主流方法的缺点:**3DCNN方法难以训练且效果没那么好,LSTM的方法保留了不必要的长期序列约束(没有认识到步态的周期性,造成了冗杂,丧失了步态识别的灵活性),GaitSet没有明确的对时间变化进行建模。(注意,LSTM是长距离时间建模,GaitPart是短距离时间建模,而GaitSet没有明确的时间建模)从这里也可以看出,GaitPart不能接受无序的步态序列作为输入。

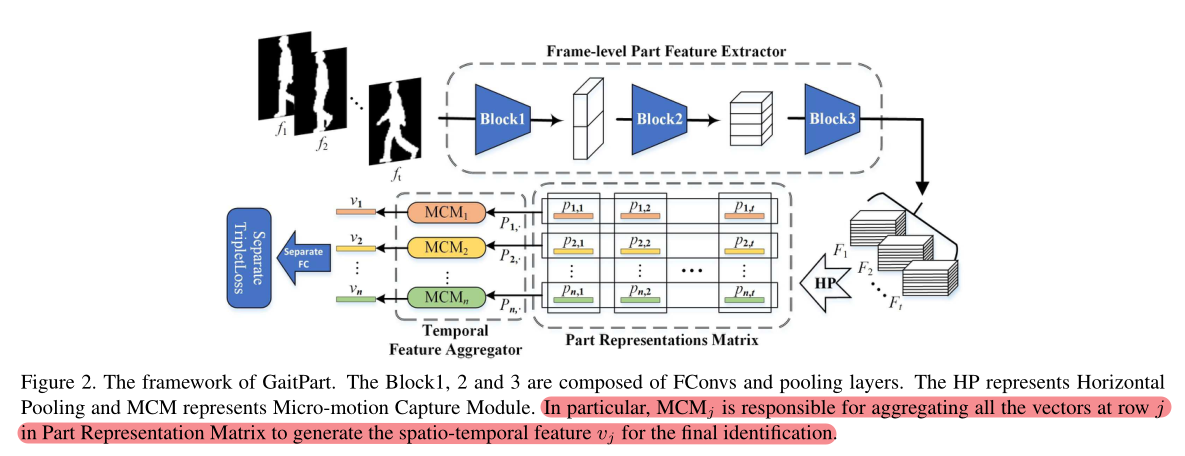
3 Proposed Method
3.1 主干网络简介
FPFE:帧级特征提取器,特别设计的卷积网络,用于提取每一帧的空间特征
HP:水平池化,将FPFE得到的特征图水平分割为n个部分,提取人体局部特征,并且通过平均+最大池化进行下采样
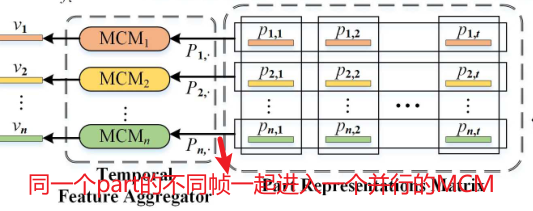
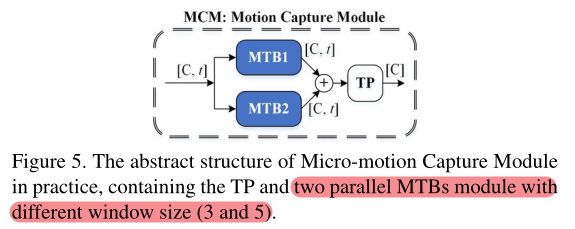
MCM:微动作捕捉模块,对被水平分割的特征图的每个部分进行微动作捕捉**(对整行进行聚合,即同一个part的不同帧)**,多个并行的MCM组成了TFA
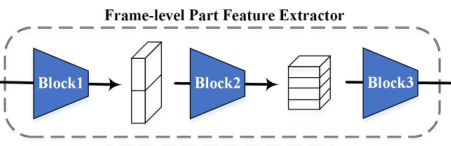
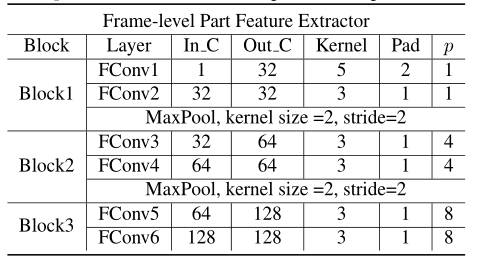
3.2 帧级特征提取器(Frame-level Part Feature Extractor)
作用:提取每帧图像的局部空间特征,加强对图像的细粒度特征的提取
组成:三个Block,每个Block包括两个FConv(焦点卷积)层 + 池化
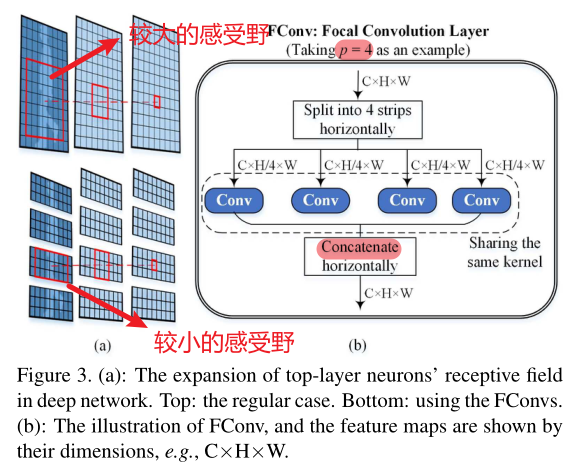
FConv的介绍:
定义:焦点卷积层即特殊卷积层,它将特征图水平划分为p个部分并对每个部分进行卷积。特别的,当p=1时,FConv=Conv
作用:随着网络深入,神经元的感受野将比正常情况下更加狭窄,有利于神经元关注跟多细节信息(感受野:卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小,即特征图上的一个点对应输入图上的区域的大小)
3.3 水平池化(HP)
该部分与GaitSet基本一致,GaitSet之所以有“金字塔”的称呼,是因为水平条(尺度)的大小分为1,2,4,8,16。而在GaitPart中,水平条(尺度)的大小均为16,因此呈不是一个类似金字塔的形状,经过HP后将得到RP-Matrix:
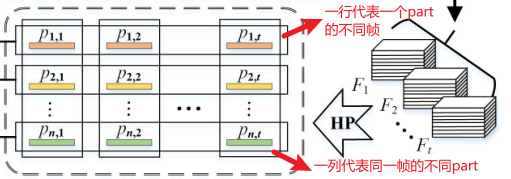
3.4 时序特征聚合器(Temporal Feature Aggregator)
多个并行的MCM组成了TFA,每个MCM代表一个part的短距离时空特征。MCM包括:
① 微动作模板构建器MTB
作用:将PR-Matrix中的帧级部件特征映射为微动作特征。任意时刻的微动作模式应该完全由其自身及其相邻帧决定。
组成:

TempFunc(时序模板):将当前帧与相邻帧通过平均池化与最大池化进行聚合。注意,是所有帧级别(frame-level)的特征都进行,并且池化是一种绝对操作(没有可以共享的参数),这意味着它不需要被划分为16个部分。

Channel-wise Attention(通道级注意力机制):通过一个一维卷积核对特征向量进行重新加权(点乘)以获得更具有判别性的微动作表示,具体操作是在不同的通道施加一次一维卷积操作。注意,微动作需要分part进行,因此需要划分为16个部分,不共享参数。

而后将从TF和CA中获得的特征进行点乘,从而完成从Sp到Sm的转变:
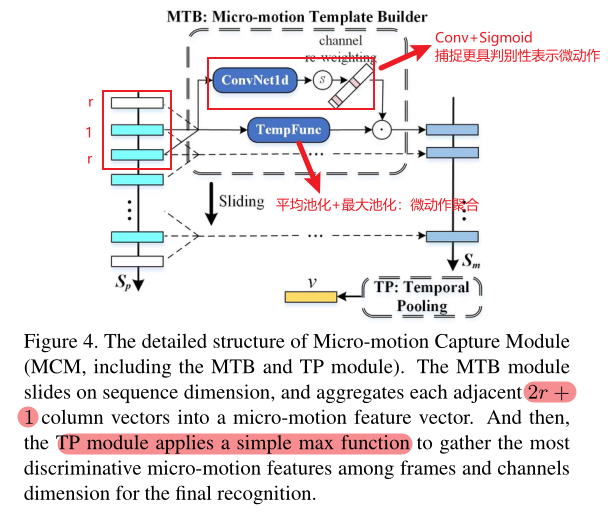
从此处可以得知:相邻帧的数量取决于卷积核与池化的大小,即2r+1。例如当卷积核大小为5时(一维卷积),r=2,即前两帧、后两帧与当前帧作为一个窗口进行卷积(channel-wise attention)与池化(TempFunc)。
② 时序池化TP
基本原则:周期性的步态在经过一个完整周期后不会有判别信息增益
在实际应用中,采用max统计函数作为TP,原因如下:
① mean统计函数:由于真实步态视频长度t(t > T,T为一个完整步态周期)不确定,均值函数不是一个好选择(只有t为T整数倍的时候,下列两式才相等)
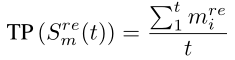
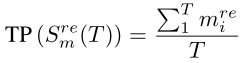
② max统计函数:由于步态的周期性,max在不同步态长度下等价(下列两式相等)
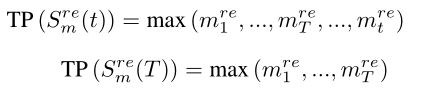
在GaitPart的实际应用中,MCM模块由两个窗口值不同(2r+1)的MTB模块以及TP模块组成:
代码
1 FPFE
'''self.FPFE = SetBlockWrapper(FPFE())'''
# 维度压缩函数 [n, s, c, h, w] => [n, s, ...]
class SetBlockWrapper(nn.Module):
def __init__(self, forward_block):
super(SetBlockWrapper, self).__init__()
self.forward_block = forward_block
def forward(self, x):
"""
In x: [n, s, c, h, w]
Out x: [n, s, ...]
"""
n, s, c, h, w = x.size()
x = self.forward_block(x.view(-1, c, h, w))
input_size = x.size()
output_size = [n, s] + [*input_size[1:]]
return x.view(*output_size)
# FPFE主模块
class FPFE(nn.Module):
def __init__(self):
super(FPFE, self).__init__()
self.feature = self.whole_layers() # 获取所有Layers
def forward(self, seqs):
out = self.feature(seqs) # 前向传播
return out
# 获取整个FPFE模块
def whole_layers(self):
# Block1 特别注意,由于p=1,FConv相当于Conv
Layers = self.make_layers('BC', 1, 32, 5, 1, 2, 0) # 5×5 Conv
Layers += self.make_layers('BC', 32, 32, 3, 1, 1, 0) # 3×3 Conv
Layers += self.make_layers('M', 0, 0, 0, 0, 0, 0) # MaxPooling
# Block2
Layers += self.make_layers('FC', 32, 64, 3, 1, 1, 2) # 3×3 FConv p = 2^2 = 4
Layers += self.make_layers('FC', 64, 64, 3, 1, 1, 2) # 3×3 FConv p = 2^2 = 4
Layers += self.make_layers('M', 0, 0, 0, 0, 0, 0) # MaxPooling
# Block3
Layers += self.make_layers('FC', 64, 128, 3, 1, 1, 3) # 3×3 FConv p = 2^3 = 8
Layers += self.make_layers('FC', 128, 128, 3, 1, 1, 3) # 3×3 FConv p = 2^3 = 8
return nn.Sequential(*Layers) # 连接网路层
# 制造卷积层函数
def make_layers(self, typ, in_c, out_c, kernel_size, stride, padding, halving):
def get_layer(typ, in_c, out_c, kernel_size, stride, padding, halving):
# 基本卷积 或者 焦点卷积
if typ == 'BC':
return BasicConv2d(in_c, out_c, kernel_size=kernel_size, stride=stride, padding=padding)
return FocalConv2d(in_c, out_c, kernel_size=kernel_size, stride=stride, padding=padding, halving=halving)
if typ == 'M':
# 获取最大池化层
Layers = [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
# 获取卷积层 + 激活函数
conv2d = get_layer(typ, in_c, out_c, kernel_size, stride, padding, halving)
Layers = [conv2d, nn.LeakyReLU(inplace=True)]
return Layers
# 普通卷积
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size,
stride=stride, padding=padding, bias=False, **kwargs)
def forward(self, x):
x = self.conv(x)
return x
# 焦点卷积
class FocalConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, halving, **kwargs):
super(FocalConv2d, self).__init__()
self.halving = halving
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size, bias=False, **kwargs)
def forward(self, x):
if self.halving == 0:
z = self.conv(x)
else:
h = x.size(2)
split_size = int(h // 2**self.halving) # p:水平划分
z = x.split(split_size, 2) # 划分特征
z = torch.cat([self.conv(_) for _ in z], 2) # 焦点卷积
return z
2 HP
'''self.HPP = SetBlockWrapper(HorizontalPoolingPyramid(bin_num=[16]))'''
# 水平池化层
class HorizontalPoolingPyramid():
def __init__(self, bin_num):
self.bin_num = bin_num # [16], 16个尺度
# 为什么是16尺度呢?因为此时特征图的大小是11宽*16高,为了在横向划分part,将尺度变为16,从而保证了:
# 下边的x == z,相当于没有划分,而是在宽这个维度上做池化
def __call__(self, x):
"""
x : [n, c, h, w]
ret: [n, c, p]
"""
n, c = x.size()[:2]
features = []
for b in self.bin_num:
z = x.view(n, c, b, -1) # 类似于GaitSet的操作,最后两个维度压缩
z = z.mean(-1) + z.max(-1)[0] # 最后两个维度的平均池化与最大池化
features.append(z)
return torch.cat(features, -1)
3 TFA

'''self.TFA = TemporalFeatureAggregator(in_channels=128, parts_num=16)'''
# 克隆传入的module,复制N份
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
# Channel-wise Attention中的简单卷积层
class BasicConv1d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, **kwargs):
super(BasicConv1d, self).__init__()
self.conv = nn.Conv1d(in_channels, out_channels,
kernel_size, bias=False, **kwargs)
def forward(self, x):
ret = self.conv(x)
return ret
# 时序特征聚合器
class TemporalFeatureAggregator(nn.Module):
def __init__(self, in_channels, squeeze=4, parts_num=16):
super(TemporalFeatureAggregator, self).__init__()
hidden_dim = int(in_channels // squeeze) # 128 // 4 = 32 squeeze:紧缩率
self.parts_num = parts_num # 16个部分
# MTB1:窗口值3
# 16个Channel-wise Attention,对16个部分单独进行微动作提取,即不共享参数
conv3x1 = nn.Sequential(
BasicConv1d(in_channels, hidden_dim, 3, padding=1),
nn.LeakyReLU(inplace=True),
BasicConv1d(hidden_dim, in_channels, 1)) # 两个Conv,前一个卷积核大小为3,后一个为1,感受野为3,即窗口值为3
self.conv1d3x1 = clones(conv3x1, parts_num) # 克隆16个ConvNet1d
# TempFunc是池化操作(没有可共享参数),是对frame-level的微动作提取,不需要复制16份
self.avg_pool3x1 = nn.AvgPool1d(3, stride=1, padding=1) # 大小为3,对应窗口值
self.max_pool3x1 = nn.MaxPool1d(3, stride=1, padding=1) # 当步长为1且外边距为1时,维持维度不变
# MTB2:窗口值5
conv3x3 = nn.Sequential(
BasicConv1d(in_channels, hidden_dim, 3, padding=1),
nn.LeakyReLU(inplace=True),
BasicConv1d(hidden_dim, in_channels, 3, padding=1)) # 两个Conv,前一个卷积核大小为3,后一个为3,感受野为5,即窗口值为5
self.conv1d3x3 = clones(conv3x3, parts_num)
self.avg_pool3x3 = nn.AvgPool1d(5, stride=1, padding=2) # 大小为5,对应窗口值
self.max_pool3x3 = nn.MaxPool1d(5, stride=1, padding=2) # 当步长为1且外边距为2时,维持维度不变
# Temporal Pooling, TP
self.TP = torch.max
# 前向传播过程
def forward(self, x):
"""
Input: x, [n, s, c, p]
Output: ret, [n, p, c]
"""
n, s, c, p = x.size()
x = x.permute(3, 0, 2, 1).contiguous() # [16, bs, 128, 30]
feature = x.split(1, 0) # [[1, bs, 128, 30], [1, bs, 128, 30], ..., [1, bs, 128, 30]] len(feature) = 16
x = x.view(-1, c, s) # [bs * 16, 128, 30]
# MTB1: ConvNet1d & Sigmoid(Channel-wise Attention) 2r+1 = 3
logits3x1 = torch.cat([conv(_.squeeze(0)).unsqueeze(0)
for conv, _ in zip(self.conv1d3x1, feature)], 0)
# 16部分经过16层简单卷积,并对特征进行连接,整个层的维度变换如下(可以看出,每一个部分的全部30帧同时进行处理):
# [1, bs, 128, 30] _.squeeze(0) =>
# [bs, 128, 30] BasicConv1d(128, 32, 3) + Lrelu =>
# [bs, 32, 30] BasicConv1d(32, 128, 1) =>
# [bs, 128, 30] .unsqueeze(0) =>
# [1, bs, 128, 30] torch.cat =>
# [16, bs, 128, 30]
scores3x1 = torch.sigmoid(logits3x1) # 通过Sigmoid函数 [16, bs, 128, 30]
# MTB1: Template Function
feature3x1 = self.avg_pool3x1(x) + self.max_pool3x1(x) # 平均池化[bs * 16, 128, 30] + 最大池化[bs * 16, 128, 30]
feature3x1 = feature3x1.view(p, n, c, s) # [bs * 16, 128, 30] => [16, bs, 128, 30]
feature3x1 = feature3x1 * scores3x1 # 点乘,进行re-wight [16, bs, 128, 30]
# MTB2: ConvNet1d & Sigmoid 2r+1 = 5
logits3x3 = torch.cat([conv(_.squeeze(0)).unsqueeze(0)
for conv, _ in zip(self.conv1d3x3, feature)], 0)
scores3x3 = torch.sigmoid(logits3x3)
# MTB2: Template Function
feature3x3 = self.avg_pool3x3(x) + self.max_pool3x3(x)
feature3x3 = feature3x3.view(p, n, c, s)
feature3x3 = feature3x3 * scores3x3
# Temporal Pooling
ret = self.TP(feature3x1 + feature3x3, dim=-1)[0] # [p, n, c, s] => [p, n, c] 时序池化模块,frame维度进行
ret = ret.permute(1, 0, 2).contiguous() # [n, p, c]
return ret
4 FC
'''self.FC = SeparateFCs(in_channels=128, out_channels=256)'''
# 全连接层:128 => 256
class SeparateFCs(nn.Module):
def __init__(self, parts_num=16, in_channels=256, out_channels=256, norm=False):
super(SeparateFCs, self).__init__()
self.p = parts_num
self.fc_bin = nn.Parameter(
nn.init.xavier_uniform_(
torch.zeros(parts_num, in_channels, out_channels)))
self.norm = norm
def forward(self, x):
"""
x: [p, n, c]
"""
if self.norm:
out = x.matmul(F.normalize(self.fc_bin, dim=1))
else:
out = x.matmul(self.fc_bin)
return out
5 BackBone
class GaitPart(nn.Module):
def __init__(self, *args, **kargs):
super(GaitPart, self).__init__(*args, **kargs)
self.FPFE = SetBlockWrapper(FPFE())
self.HPP = SetBlockWrapper(HorizontalPoolingPyramid(bin_num=[16]))
self.TFA = TemporalFeatureAggregator(in_channels=128, parts_num=16)
self.FC = SeparateFCs(in_channels=128, out_channels=256)
# 参数初始化
for m in self.modules():
if isinstance(m, (nn.Conv3d, nn.Conv2d, nn.Conv1d)):
nn.init.xavier_uniform_(m.weight.data)
if m.bias is not None:
nn.init.constant_(m.bias.data, 0.0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight.data)
if m.bias is not None:
nn.init.constant_(m.bias.data, 0.0)
elif isinstance(m, (nn.BatchNorm3d, nn.BatchNorm2d, nn.BatchNorm1d)):
if m.affine:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0.0)
def forward(self, sils):
'''bs: batch_size'''
if len(sils.size()) == 4:
sils = sils.unsqueeze(2) # 维度扩张 [bs, 30, 64, 44] => [bs, 30, 1, 64, 44]
out = self.FPFE(sils) # [n, s, c, h, w] [bs, 30, 128, 16, 11]
out = self.HPP(out) # [n, s, c, p] [bs, 30, 128, 16]
out = self.TFA(out) # [n, p, c] [bs, 16, 128]
feature = self.FC(out.permute(1, 0, 2).contiguous()) # [p, n, c] [16, bs, 256]
feature = feature.permute(1, 0, 2).contiguous() # [n, p, c] [bs, 16, 256]
return feature
总结:CV的本质就是一堆卷积和一堆池化,不要害怕一堆花里胡哨的名词(狗头)














 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









