







Apache Parquet
关于Parquet
传统的,关系型数据的列式存储比较容易处理,但是嵌套类型的列式存储处理起来相当之困难,因为,嵌套类型的数据不仅仅只又基本数据类型,它还可以是List,Map,Set类型,虽然,依然可以快速定位到某一列的值,但如何把他们合并一行数据呢?2010年Google公司发表了一篇名为Dremel: Interactive Analysis of Web-Scale Datasets的论文,解决了这个问题。
于是Parquet的缔造者们(Twitter和Cloudera的工程师),基于Dremel的基础之上,开发出了Parquet。
1.Parquet的特点
- Apache Parquet是一种能够有效存储嵌套数据的列式存储格式。
- 由于是列式存储格式,在文件大小和查询性能上表现优秀。
列式存储的优势:
①由于每一列的数据类型相同,所以,可以针对不同数据类型的列进行不同的编码和压缩,大大降低数据存储所占空间。
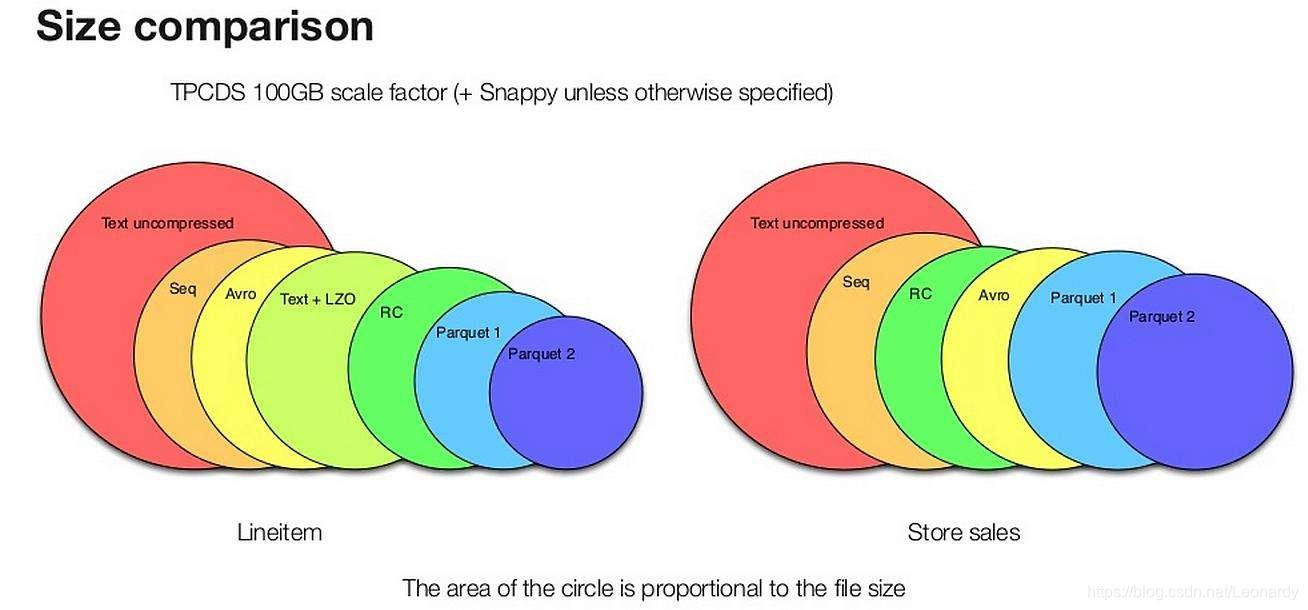
下图展示了,使用不同存储格式来存储TPC-DS数据集中的两个不同的表数据的文件大小。可以看出,Parquet较其他二进制文件存储格式能够更有效地节省存储空间,尤其是新版的Parquet 2,它使用了更高效的也存储方式。
②读取数据的时候可以把映射下推,只需要读取需要的列,这样可以大大减少每次查询的I/O数据量。
③由于每一列的数据类型相同,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。 - 灵活性:
①Parquet分为2部分,一部分是以与语言无关的方式来定义文件格式的Parquet规范(Parquet-format),另一部分是不同语言的实现规范。(MapReduce,pig,Hive,Cascading,Crunch和Spark都支持Parquet格式)
②Parquet的灵活性同样延伸至内存中的表示方法,Java的实现并没有绑定某一种表示方法,因而可以使用Avro,Thrift或者Protocol Buffers等多种内存数据表示法来将数据写入Parquet或者从Parquet文件中读取数据到内存。
2.Parquet数据类型
2-1.基本数据类型
| 类型 | 描述 |
|---|---|
| boolean | 二进制值 |
| int32 | 32位有符号整数 |
| int64 | 64位有符号整数 |
| int96 | 96位有符号整数 |
| float | 单精度(32位)IEEE 754浮点数 |
| double | 双精度(32位)IEEE 754浮点数 |
| binary | 8位无符号字节序列 |
| fixed_len_byte_array | 固定数量的8位无符号字节 |
同Avro类似,Parquet文件中的数据也通过schema描述。模式的根为message,它包含一组字段,每个字段都由以下三部分内容构成:
①一个重复的关键字(required,optional或repeated)
※注:
required:表示有且仅有一个值。
optional:表示可选,0到1个值。
repeated:表示重复,0到N个值。
②一个数据类型
③一个字段名称
message WeatherRecord {
required int32 year;
required int32 temperature;
required binary stationId (UTF8);
}
※注:Parquet并没有String类型,事实上Parquet定义了一些逻辑类型,这些逻辑类型支出如何对基本数据类型就行解读。
例如,可以通过UTF8注解的binary基本数据类型来表示String.
2-2.Parquet的逻辑类型
| 类型 | 描述 | schema实例 |
|---|---|---|
| UTF8 | UTF8字节的字符串,可用于注解binary |
message m {
required binary fieldName (UTF8); } |
| ENUM | 枚举(一组命名值的集合)可用于注解binary |
message m {
required binary fieldName (ENUM); } |
| DECIMAL (precision,scale) |
任意精度的有符号小数,可以用于注解int32,int64,binary或fixed_len_byte_array | message m { requried int32 fieldName (DECIMAL(5,2)); } |
| DATE | 不带时间的日期值,可以注解int32 用Unix元年(1970年1月1日)以来的天数表示 |
message m {
required int32 fieldName (DATE); } |
| LIST | 一组有序的值,可以用于注解group | message m {
required group groupName (LIST) { repeated group listName { required int32 element } } } |
| MAP | 一组无序的键值对,可以用于注解group | message m {
required group groupName (MAP) { repeated group key_value { required binary key (UTF8); optional int32 value; } } } |
Parquet利用group类型来构造复杂类型,它可以增加一层嵌套。
2-3.嵌套编码
使用面向列式的存储格式时,同一列数据连续存储。
不同于Hive的RPCFile(通过将嵌套结构扁平化来回避对嵌套结构进行编码),Parquet使用的是Dremel编码方式,
即schema中的每个基本数据类型的字段都会被单独存储为一列,且每个值都需要通过使用两个整数来对其结构进行编码:
①列定义深度(definition level):
It specifies how many fields in path p that could be undefined(repeated & optional) are actually present.
表示在该值的路径上,有多少个字段是可以不被定义的(repeated和optional)但是却已经被定义。
(该值只对空值有意义)而对于非空值它是没有意义的,因为非空值即意味着该值的每一层节点都已经定义,所以,对于已定义的值而言,definition level为到该节点为止的路径中(包括该节点)所包含的repeated和optional的节点数。
由于网上的说明和例子千篇一律但是却都解释的不够明晰,这里自己稍作改动。
// message定义
message DefinitionLevelExample {
optional group defLevel0 {
optional group defLevel1 {
optional binary defLevel2_col_a (UTF8);
}
}
}
// 四种情况
1.defLevel0:null
2.defLevel0:{
defLevel1:null}
3.defLevel0:{
defLevel1:{
defLevel2_col_a:null}}
4.defLevel0:{
defLevel1:{
defLevel2_col:"parquet test"}}
// 为了方便观看把上面四种情况转换成下面的形式
DefinitionLevelExample
{
defLevel0:null
defLevel0:
defLevel1:null
defLevel0:
defLevel1:
defLevel2_col:null
defLevel0:
defLevel1:
defLevel2_col:"test"
}
| case | value | path | definition level |
|---|---|---|---|
| ① | defLevel0:null | /DefinitionLevelExample/defLevel0 | 0 |
| ② | defLevel0:{
defLevel1:null } |
/DefinitionLevelExample/defLevel0/defLevel1 |
1 |
| ③ | defLevel0:{
defLevel1:{ defLevel2_col:null } } |
/DefinitionLevelExample/defLevel0/defLevel1/defLevel2_col |
2 |
| ④ | defLevel0:{
defLevel1:{ defLevel2_col:“parquet test” } } |
/DefinitionLevelExample/defLevel0/defLevel1/defLevel2_col |
3 |
※上面的表格中,以红色标注的即为,到该值的路径中可以不被定义,但是却已经被定义的字段。case④中,所有节点都已经被定义,所以repetition level的值为3。
②列元素重复次数(repetition level):
It tells us at what repeated field in the field’s path the value has repeated
repetition level的主要目的是为了记录repeated标记的节点,它表示当前节点的路径中,在哪个(第几个)被repeated定义的字段被重复使用(这里的重复使用指的是下面定义的message中那些被定义为repeated的节点不止一次出现)。
(sorry,语文水平比较差,话不多说,还是上demo吧。)
// 定义message
message RepetitionLevelDemo {
optional group year {
repeated group month {
repeated binary day (UTF8);
optional binary week (UTF8);
}
}
repeated group music {
repeated group folkmusic {
required binary guitar (UTF8);
repeated binary bass (UTF8);
}
}
}
// struct结构展示
year
month
day:"10"
day: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4775
4775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









