






背景
最近在写一个常见的小demo——社区功能中的评论与回复功能。在实现过程中,定义了一个评论类实体CommunityReplyEntity,然后在这个实体中加多一个回复评论集合List<CommunityReplyEntity>的children子集。这样写下去的逻辑就是当children不为空就有回复,那么就会碰到一个问题,就是每个评论都有回复,并且回复子集仍然有回复。这样就会导致树的结构很深达到不止三层,这样很不方便前端去渲染评论-回复信息。因此,我用一级评论+一级评论所有回复这样的两级数据去作为我的返回数据。这样就可以避免树的结构深度问题。
注意:以下是一个简单的实现方法,只提供初学者或则自己练手项目参考使用。欢迎大家一起讨论发表评论、回复功能中更好的表数据结构、以及返回数据结构格式。
评论回复表
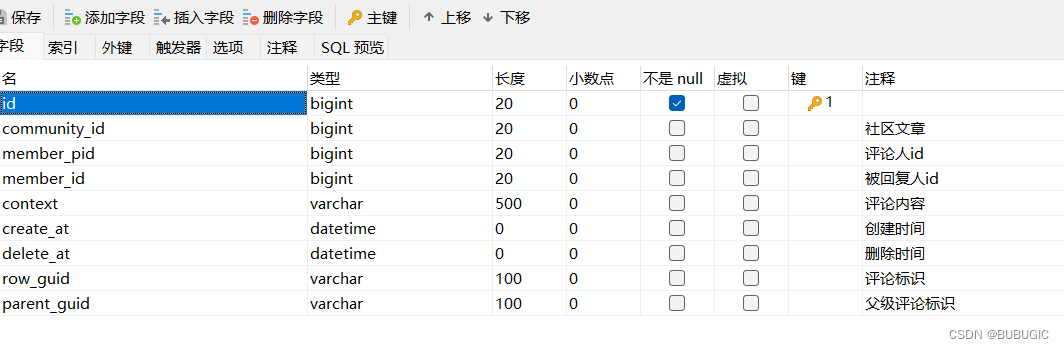
评论实体类
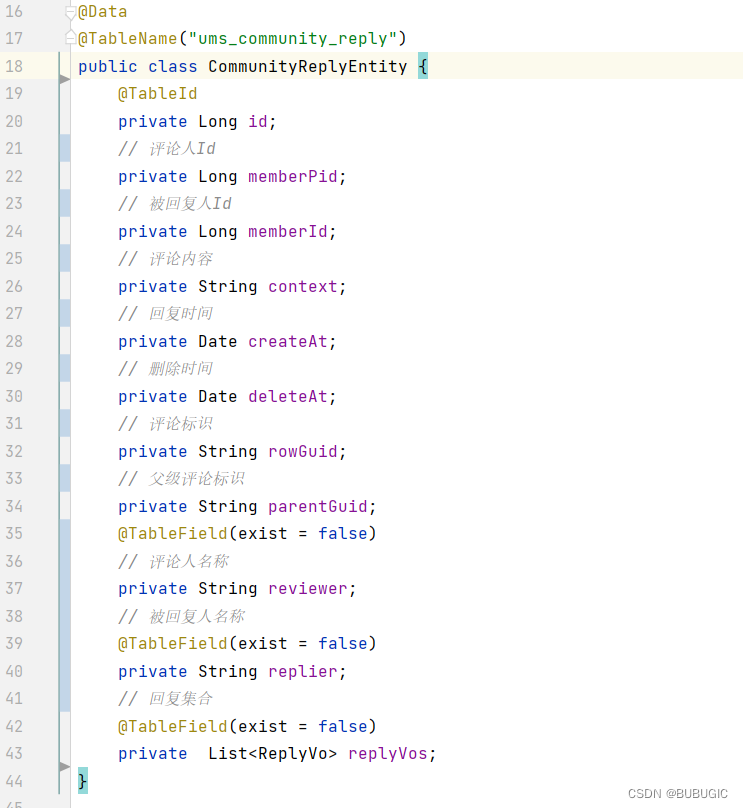
回复结果Vo

实现逻辑
1.找出该笔记下面所有的一级评论 
2.找出评论下的所有回复

3.调用到的封装用户名称方法

4.递归方法实现逻辑
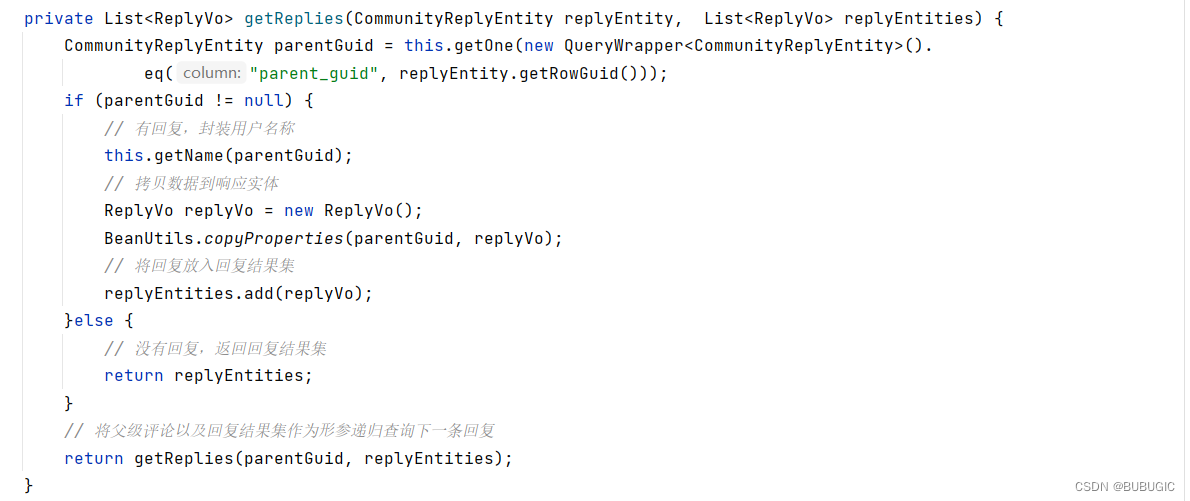
5.实现效果(响应数据)
{
"msg": "success",
"code": 0,
"data": [{
"id": 1,
"memberPid": 2,
"reviewer": "PHW",
"replier": null,
"memberId": null,
"context": "wow,nice pic!",
"createAt": null,
"deleteAt": null,
"rowGuid": "1",
"parentGuid": null,
"children": []
},
{
"id": 2,
"memberPid": 6,
"reviewer": "壹壹wo",
"replier": null,
"memberId": null,
"context": "wow,what a nice pic!",
"createAt": null,
"deleteAt": null,
"rowGuid": "2",
"parentGuid": null,
"children": [{
"id": 3,
"memberPid": 2,
"reviewer": "PHW",
"replier": "壹壹wo",
"memberId": 6,
"context": "yes,I want to get one!",
"createAt": null,
"deleteAt": null,
"rowGuid": "3",
"parentGuid": "2",
"children": null
},
{
"id": 4,
"memberPid": 6,
"reviewer": "壹壹wo",
"replier": "PHW",
"memberId": 2,
"context": "OK,I will buy one for you!",
"createAt": null,
"deleteAt": null,
"rowGuid": "4",
"parentGuid": "3",
"children": null
},
{
"id": 5,
"memberPid": 2,
"reviewer": "PHW",
"replier": "壹壹wo",
"memberId": 6,
"context": "really,Thank you very muck!",
"createAt": null,
"deleteAt": null,
"rowGuid": "5",
"parentGuid": "4",
"children": null
}
]
}
]
}
下面是实现代码
@Override
public List<CommunityReplyEntity> getAllReplies(Long communityId) {
// 找出该笔记下面所有的一级评论
List<CommunityReplyEntity> head = this.list(new QueryWrapper<CommunityReplyEntity>().
eq("community_id", communityId).
isNull("parent_guid"));
// 找出评论下的所有回复
List<CommunityReplyEntity> collect = head.stream().map(item -> {
List<ReplyVo> replyEntities = new ArrayList<>();
// 封装用户名称
this.getName(item);
// 将父级评论以及回复结果集作为形参递归查询下一条回复
replyEntities = getReplies(item, replyEntities);
// 封装评论的回复结果集
item.setReplyVos(replyEntities);
return item;
}).collect(Collectors.toList());
return collect;
}
// 获得名字
private void getName(CommunityReplyEntity item) {
MemberEntity memberPEntity = memberService.getById(item.getMemberPid());
if (memberPEntity != null) {
// 评论人
item.setReviewer(memberPEntity.getNickname());
}
MemberEntity memberEntity = memberService.getById(item.getMemberId());
if (memberEntity != null ) {
// 被回复人
item.setReplier(memberEntity.getNickname());
}
}
private List<ReplyVo> getReplies(CommunityReplyEntity replyEntity, List<ReplyVo> replyEntities) {
CommunityReplyEntity parentGuid = this.getOne(new QueryWrapper<CommunityReplyEntity>().
eq("parent_guid", replyEntity.getRowGuid()));
if (parentGuid != null) {
// 有回复,封装用户名称
this.getName(parentGuid);
// 拷贝数据到响应实体
ReplyVo replyVo = new ReplyVo();
BeanUtils.copyProperties(parentGuid, replyVo);
// 将回复放入回复结果集
replyEntities.add(replyVo);
}else {
// 没有回复,返回回复结果集
return replyEntities;
}
// 将父级评论以及回复结果集作为形参递归查询下一条回复
return getReplies(parentGuid, replyEntities);
}记录一下基于以上实现方法可以进行优化的方式
- SQL 优化:在
getComments和getReplies方法中,都有进行 SQL 查询的操作,可以考虑优化 SQL 语句,例如使用连表查询等方式,减少数据库查询次数。 - 缓存优化:在
getComments和getReplies方法中,可以添加缓存机制,将查询结果缓存到缓存系统中,下次查询时可以直接从缓存中获取,减少数据库查询次数。 - 分页查询:如果评论和回复数据量较大,可以考虑使用分页查询,每次只查询一页数据,减少数据量,提高查询效率。
- 数据库索引优化:在数据库中为评论和回复的关键字段建立索引,可以加快查询速度。
- 代码逻辑优化:在
getReplies方法中,可以使用迭代方式替代递归方式,减少方法调用次数,提高性能。 需要根据具体情况来选择合适的优化方案,以达到最优的查询和维护效果。















 6561
6561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









