









 BeautyGAN是一种基于深度生成对抗网络的实例级面部妆彩迁移模型,能够将给定参考人脸图像的化妆风格迁移到未化妆人脸,同时保留面部特征。该方法结合全局域级损失和局部实例级损失,引入像素级直方图损失,实现高质量的妆彩迁移。
BeautyGAN是一种基于深度生成对抗网络的实例级面部妆彩迁移模型,能够将给定参考人脸图像的化妆风格迁移到未化妆人脸,同时保留面部特征。该方法结合全局域级损失和局部实例级损失,引入像素级直方图损失,实现高质量的妆彩迁移。
虽然有其他朋友对该篇论文进行了翻译(翻译过程中也发现此篇不够准确,很多是直接贴翻译软件输出,但还是感谢作者有些名词比较专业),但我在想,假如没有这篇翻译我该怎么办。还是自己走一遍,学习没有捷径。
转载请注明出处:https://leytton.blog.csdn.net/article/details/102932180
BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network
BeautyGAN: 基于深度生成对抗网络的实例级面部妆彩迁移
ABSTRACT
摘要
Facial makeup transfer aims to translate the makeup style from a given reference makeup face image to another non-makeup one while preserving face identity. Such an instance-level transfer problem is more challenging than conventional domain-level transfer tasks, especially when paired data is unavailable. Makeup style is also different from global styles (e.g., paintings) in that it consists of several local styles/cosmetics, including eye shadow, lipstick, foundation, and so on. Extracting and transferring such local and delicate makeup information is infeasible for existing style transfer methods. We address the issue by incorporating both global domain-level loss and local instance-level loss in an dual input/output Generative Adversarial Network, called BeautyGAN. Specifically, the domain-level transfer is ensured by discriminators that distinguish generated images from domains’ real samples. The instance-level loss is calculated by pixel-level histogram loss on separate local facial regions. We further introduce perceptual loss and cycle consistency loss to generate high quality faces and preserve identity. The overall objective function enables the network to learn translation on instance-level through unsupervised adversarial learning. We also build up a new makeup dataset that consistsof 3834 high-resolution face images. Extensive experiments show that BeautyGAN could generate visually pleasant makeup faces and accurate transferring results. Data and code are available at http://liusi-group.com/projects/BeautyGAN.
面部妆彩迁移是为了将已化妆的面部图像妆彩风格转移到未化妆图像上,同时保留面部特征。这种实例级转移工作比传统的域级迁移更具挑战性,尤其是配对数据不可用的时候。妆彩风格不同于全局风格(例如:绘画),它包含多个局部风格/妆彩,包含眼影、口红、粉底等等。提取和迁移这种局部、精细的妆彩信息,对于现有的传统风格迁移方法是不可行的。我们通过结合全局域级损失和局部实例级损失到一个双输入/输出生成对抗网络中来解决这一问题,称之为BeautyGAN。具体来说,域级的迁移是由识别器来保证的,识别器将生成的图像与域的实际样本区分开来。实例级损失通过局部面部区域的像素级直方图损失计算得出。我们进一步介绍知觉损失和 周期一致性损失,以产生高质量的人脸和保持身份。整体目标函数使神经网络能够通过无监督的对抗性学习在实例级学习(风格)迁移。我们也建立了一个洗的妆彩数据集,包含3834张高分辨率人脸图像。大量的实验展示了BeautyGAN能够产生很精致漂亮的妆容和精准的迁移效果。你可以通过访问 http://liusi-group.com/projects/BeautyGAN来获取数据和代码。
CSS概念(CCS CONCEPTS)
• Computing methodologies → Computer vision tasks; Neural networks; Unsupervised learning;
• 计算方法→计算机视觉任务;神经网络;非监督学习;
关键字(KEYWORDS)
facial makeup transfer; generative adversarial network
面部妆彩迁移;生成对抗网络
ACM引入格式(ACM Reference Format):
Tingting Li, Ruihe Qian, Chao Dong, Si Liu, Qiong Yan, Wenwu Zhu, and Liang Lin. 2018. BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network . In 2018 ACM Multimedia Conference (MM ’18), October 22–26, 2018, Seoul, Republic of Korea. ACM, New York, NY, USA, 9 pages. https://doi.org/10.1145/3240508.3240618
1 INTRODUCTION
1.介绍
Makeup is a ubiquitous way to improve one’s facial appearance with special cosmetics, such as foundation for concealing facial flaws,eye liner, eye shadow and lipstick. With thousands of cosmetic products, varying from brands, colors, way-to-use, it is difficult to find a well-suited makeup style without professional suggestions.Virtual makeup application is a convenient tool, helping users try the makeup style from photos, such as MEITU XIUXIU, TAAZ and DailyMakever1. However, these tools all require user’s manual interaction and provide with only a certain number of fixed makeup styles. In daily life, celebrities always wear beautiful makeup styles,which give some examples to refer to. Makeup transfer provides an efficient way to help users select the most suitable makeup style. As shown in Figure 1, makeup transfer (results of our method) could translate the makeup style from a given reference face image to another non-makeup face without the change of face identity.
化妆是改善一个人面部形象的普遍方式,例如粉底掩盖面部缺陷,眼线、眼影和口红。化妆品数以千计,品牌、颜色、使用方法各不相同,如果没有专业的建议,很难找到一个合适的化妆风格。虚拟化妆应用是一个很方便的工具,能够帮助用户通过图片尝试不同的化妆风格,例如:美图秀秀、TAAZ和DailyMakever1。然而,这些工具都需要用户手动交互,并且只提供一定数量的固定化妆风格。在日常生活中,名人总是打扮着美丽的化妆风格,这给了一些例子可以参考。妆彩迁移提供了一种有效方式来帮助用户选择最合适的化妆风格。如图1所示,妆彩迁移(我们的方法效果)能够将给定参考人脸图像的化妆风格迁移到未化妆人脸,同时保留面部特征。

Figure 1: Example results of our BeautyGAN model for makeup transfer. Three makeup styles on reference images(top row) are translated to three before-makeup images (left column). Nine generated images are shown in the middle.
图1:使用BeautyGAN模型的妆彩迁移案例结果。上面一行是化妆风格图像,左边一列是未化妆图像,其它九张图片是生成的图像。
Existing studies on automatic makeup transfer can be classified into two categories: traditional image processing approaches[11,19, 29] like image gradient editing and physics-based manipulation, and deep learning based methods which typically build upon deep neural networks[23]. Image processing approaches generally decompose images into several layers (e.g., face structure, color,skin) and transfer each layer after warping the reference face image to the non-makeup one. Deep learning based method[23] adopt serveral independent networks to deal with each cosmetic individually. Almost all previous methods treat the makeup style as a simple combination of different components, thus the overall output image looks unnatural with apparent artifacts at combining places (see Figure 4).
现有的自动妆彩风格迁移研究可以分为两类:一类是传统的图像处理方法[11,19,29],如图像梯度编辑和基于物理的操作,另一类是基于深度学习的方法,通常基于深度神经网络[23]。图像处理方法通常将图像分解成若干层(如面部结构、颜色、皮肤),并将参考面部图像的每层迁移到未化妆图像上。基于深度学习的方法[23] 采用不同的网络分别处理每种化妆品。几乎所有之前的方法都是简单组合不同的部分来处理化妆风格,因此整体输出图像看起来不自然,组合的位置有人工合成迹象(见图4)。
Recent progress on image-to-image translation, such as style transfer[8, 9, 13], has shown that an end-to-end structure act on the entire image could generate high quality results. However, directly applying these techniques in our task is still infeasible. Facial makeup transfer has two main characteristics that are different from previous problems.
1 ) Makeup style varies from face to face,and require transferring on instance-level. On the contrary, typical image-to-image translation methods[4, 12, 35] built upon generative adversarial networks (GAN) are mostly for domain-level transfer. For instance, CycleGAN[35] realizes image-to-image translation between two collections (e.g., horses and zebras), and emphasizes inter-domain differences while omits intra-domain differences.Therefore, using CycleGAN in our problem tends to generate an average domain-level style that is invariant given different reference faces (see Figure 4).
2) Makeup style is beyond a global style and includes independent local styles. Specifically, in conventional style transfer works[8, 9, 13], style generally refers to the global painting manner like brush stroke and color distribution. In contrast, makeup style is more delicate and elaborate, which consists of several local cosmetics including eye shadows, lipsticks, foundationand so on. Each cosmetic represents a completely different style.Therefore, it is difficult to extract makeup style as a whole while preserving particular traits of various cosmetics.
最新的图像到图像转换研究进展,例如风格迁移[8, 9, 13],展示了端到端结构作用于整体图像能产生高质量结果。然而,直接将这些技术应用于我们的任务是不可行的。面部妆彩迁移有两个不同于以往问题的主要特征:
1 )化妆风格因人而异,需要实例化。相反,典型的基于生成对抗网络(GAN)的图到图转换方法[4, 12, 35],主要用于域级迁移。例如,CycleGAN[35] 实现了两个集合(如马和斑马)的图到图转换,强调域间差异,忽略域内差异。因此,使用CycleGAN倾向于产生一个平均域级风格,对于不同的参考人脸是不变的(见图4)。
2 )化妆风格不仅仅是整体风格,还包含了局部风格。具体来说,在传统的风格转移作品[8,9,13]中,风格一般是指笔触、色彩分布等全局性的绘画方式;相比之下,化妆风格更加精致,包含了多个局部化妆(风格),包括眼影、口红、粉底等等。每一种化妆都是不同的风格。因此,在保留好几种化妆位置特性的同时,很难提取出整体的化妆风格。
Another crucial issue is the lack of training data. On one hand,the released makeup dataset (see Table 1) is too small to train a sufficient large network, and the facial makeup images are mostly of low resolution/quality. On the other hand, it is difficult to obtaina pair of well-aligned face images with different makeup styles.Thus supervised learning with paired data is also implausible.
另一个关键问题是训练数据的缺乏。一方面,发布的化妆数据集(见表1)太少了,难以训练出足够大的神经网络,并且大部分的人脸妆彩图像分辨率/质量很低;另一方面,很难获得一副不同化妆风格的脸部图像。因此,成对数据的监督学习也难以实现。
To address the above issues, we propose a novel dual input/output generative adversarial network called BeautyGAN, to realize makeup style transfer in an unified framework. It accepts the makeup and non-makeup faces as inputs and directly outputs the transferred results. No additional pre-/post-processing is required. Similar to CycleGAN[35], the network first transfers the non-makeup face to the makeup domain with a couple of discriminators that distinguish generated images from domains’ real samples. On the basis of domain-level transfer, we achieve instance-level transfer by adopting a pixel-level histogram loss calculated on different facial regions. To preserve face identity and eliminate artifacts, we also incorporate a perceptual loss and a cycle consistency loss in the overall objective function. Thanks to the dual input/output design,the cycle consistency between inputs and outputs could be achieved with only one generator, which realizes makeup and anti-makeup simultaneously in a single forward pass. Moreover, no paired data is needed during the whole training procedure. As shown in Figure1, the generated images are natural-looking and visually pleasant without observable artifacts.
为了解决上述问题,我们提出了一种新的双重输入/输出生成对抗网络,称之为BeautyGAN,能够在一个统一的框架中实现妆彩风格迁移。它接收已化妆和未化妆人脸图像作为输入,然后直接输出风格迁移后的结果图像。不需要对数据进行预/后处理。跟CycleGAN[35]类似,神经网络首先将未化妆人脸数据转移到化妆数据部分,然后用两个识别器来辨别通过真实样本产生的图像。在域级转移的基础上,我们通过调节人脸不同区域计算出来的像素直方图损失,来实现实例级转移。为了保留面部特征和消除人工痕迹,我们还在整体目标函数中加入了感知损失和 周期一致性损失。得益于双重输入/输出设计,可以只用一个生成器就可以满足输入输出之间的 周期一致性。从而在一个单一前向传输中实现同时化妆与反化妆。而且在整个训练过程中不需要配对的数据。如图1所示,生成的图像很自然美观,看不出人工合成痕迹。
To sum up, the main contributions are three-folds:(1) We achieve automatic makeup transfer with a dual input/output generative adversarial network. Experiments present the effectiveness of the transferring strategy, and generated results are of higher quality than state-of-the-art methods.(2) We achieve instance-level style transfer by successfully applying pixel-level histogram losses on local regions. Such instance-level transfer approach can be easily generalized to other image translation tasks, such as style transfer for head-shot portraits, image attribute transfer and so on.(3) we build up a new makeup dataset with a collection of 3834 images, which is available at http://liusi-group.com/projects/BeautyGAN.
总的来说,主要贡献有三点:
(1)我们使用一个双重输入/输出生成对抗网络实现了自动妆彩迁移。实验表明该方法生成的结果质量高于现有方法。
(2)我们通过计算局部区域的像素直方图损失,成功实现了实例级迁移方法。这种实例级迁移方法能够很容易地广泛用于其他图像转换任务,例如头像风格转换、图像属性转换等。
(3)我们建立了一个新的化妆数据集,包含3834张图像,可以在http://liusi-group.com/projects/BeautyGAN获取。
2 RELATED WORKS
2.相关工作
2.1 Makeup Studies
2.1化妆研究
Recently, makeup related studies have aroused much more attention.[31] proposed a facial makeup detector and remover framework based on locality-constrained dictionary learning. [20] introduced an adversarial network to generate non-makeup images for makeup invariant face verification. Makeup transfer is another attractive application, which aims to transfer makeup style from reference image when still preserving source image identity. [11] decompose dimages into three layers and transferred makeup information layer by layer. This method may smooth facial details of source images thus another image decomposition method was introduced by [19].All above makeup transfer frameworks are based on traditional methods, while [23] proposed a localized makeup transfer framework in the way of deep learning. It divided facial makeup into several parts and conducted different methods on each facial part.Warping and structure preservation were employed to synthesize after-makeup images.
近年来,与化妆相关的研究越来越受到人们的关注。[31]提出了一个基于面部位置约束字典学习的人脸卸妆检测框架。[20]介绍了一个对抗网络来生成非化妆图像,用于化妆不变的面部验证。妆彩迁移是另一个吸引人的应用,目的在于将化妆图像的妆彩迁移到未化妆图像,并仍然保持原始图像的面部特征。[11]将图片分解成三层,并逐层迁移妆彩信息。这种方法可能会丢失原始图像的面部详细特征,所以[19]提出了另一种图像分解方法。上述所有的妆彩迁移框架都是基于传统方法,但[23]提出了一个基于深度学习的局域妆彩迁移框架。它将面部妆彩分为好几部分,并对每部分使用了不同的方法。采用图像扭曲和结构保存的方法合成妆后图像。
Unlike the aforementioned works, our network could realize makeup transfer and makeup removal simultaneously. Meanwhile,the unified training process could consider relationships among cosmetics in different regions. In addition, the end-to-end network itself could learn the adaptation of cosmetics fed in source images,thus eliminates the need of post-processing.
不同于之前提到的方法,我们的网络可以同时实现化妆的迁移和卸妆。同时,统一的训练过程能够考虑不同区域妆彩间的关系。此外,端对端网络本身能够学习源图像中输入妆彩的适应性,从而免除后期处理。
2.2 Style Transfer
2.2 风格迁移
Style transfer aims to combine content and style from different images. To achieve this goal, [8] proposed a method that generated a reconstruction image by minimizing the content and the style reconstruction loss. To control more information like color, scale and spatial location, an improved approach was presented in [9], where perceptual factors were introduced. The methods mentioned above could produce high-quality results but require heavy computation.[13] proposed a feed-forward network for style transfer with less computation and approximate quality.
风格迁移的目的是结合不同图像的内容和风格。为了实现这个目标,[8]提出了一种能够通过减少内容和风格重构损失来产生重构图像的方法。为了控制如颜色、缩放和空间位置等信息,[9]提出了一种改进方法,介绍了感知因子。上述提到的方法可以产生高质量的结果但需要大量计算。[13]提出了一种前馈网络风格迁移方法,计算量小,但效果差不多。
2.3 Generative Adversarial Networks
2.3 生成对抗网络
Generative Adversarial Networks[10] (GANs) is one of the generative models, consisting a discriminator and a generator. GAN has been widely used in computer vision tasks due to its ability of generating visually realistic images. [17] presented a generative adversarial network for image super resolution. [6] employed conditional GAN[25] to solve particular eye in-painting problem. [27] trained adversarial models on synthetic images for improving the realism of them. [34] even enabled to incorporate user interactions to present real-time image editing, where GAN was leveraged to estimate the image manifold.
生成对抗网络[10](GANs) 是一种生成式模型,包括识别器和生成器。GAN因其能够生成效果逼真图片的能力,被广泛应用于计算机视觉任务。[17] 提出了一种图像超分辨率生成对抗网络。[6]采用了条件GAN[25]来解决特殊的眼部彩绘问题。[27] 用合成图像训练了对抗模型,来提高合成图像的真实感。[34]甚至能够结合用户交互来显示实时图像编辑,其中GAN被用来评估图像流。
2.4 GAN for Image-to-Image Translation
2.4 基于GAN的图像风格迁移
Most existing researches on image-to-image translation aim to learn a mapping from source domain to target domain. Recently, there are some promising works[4, 12, 35] appling GAN to this field. [12] proposed a so-called pix2pix framework, which could sythesize images from label maps and reconstruct objects from edge images. To solve the problem of lacking paired images for training, [22] proposed a model whose generators were bounded with weight sharing constraints to learn a joint distribution. [35,14] presented cycle consistency loss to regularize the key attributes between inputs and translated images. StarGAN[4] even solved problem of mapping among multiple domains within one single generator. Specially, [15] introduced an encoder working with GAN for image attribute transfer.
大多数现有的图像迁移研究都是为了学习源域到目标域的映射。近年来,GAN在这一领域取得了一些进展[4, 12, 35],[12]提出了一个pix2pix框架,它可以用标签映射合成图像,并从边缘图像重建对象。为了解决缺少配对图像训练的问题,[22]提出了一种基于权值共享约束生成器学习联合分布的模型。[35]和[14]给出了周期一致性损失,来调整输入和转换图像之间的关键属性。StarGAN[4]甚至解决了单个生成器中多个域之间的映射问题。特别地,[15]介绍了一个与GAN一起工作的用于图像属性传输的编码器。
3 OUR APPROACH: BEAUTYGAN
3 我们的方法BeautyGAN
Our goal is to realize facial makeup transfer between a reference makeup image and a non-makeup image on instance-level. Consider two data collections, A ⊂ R H × W × 3 A ⊂ R ^{H×W ×3} A⊂RH×W×3 referring to non-makeup image domain and B ⊂ R H × W × 3 B ⊂ R ^{H×W ×3} B⊂RH×W×3 referring to makeup image domain with various makeup styles on. We simultaneously learn the mapping between two domains, denoted as G : A × B → B × A G: A×B →B×A G:A×B→B×A, where ’ × × ×’ represents Cartesian product. That is to say, given two images as inputs: a source image I s r c ∈ A I_{src} ∈ A Isrc∈A and a reference image I r e f ∈ B I_{ref} ∈ B Iref∈B, the network is expected to generate an after-makeup image I s r c B ∈ B I^B_{src} ∈ B IsrcB∈B and an anti-makeup image I r e f A ∈ A I^A_{ref} ∈ A IrefA∈A, denoted as ( I s r c B , I r e f A ) = G ( I s r c , I r e f ) (I^B_{src}, I^A_{ref}) = G(I_{src},I_{ref}) (IsrcB,IrefA)=G(Isrc,Iref). I s r c B I^B_{src} IsrcB synthesizes the makeup style of I r e f I_{ref} Iref while preserving the face identity of I s r c I_{src} Isrc , and I r e f A I^A_{ref} IrefA realizes makeup removal from I r e f I_{ref} Iref . The fundamental problem is how to learn instance-level correspondence, which should ensure the makeup style consistency between result image I s r c B I^B_{src} IsrcB and reference images I r e f I_{ref} Iref . Note that there is no paired data for training.
我们的目标是实现实例级的参考化妆图像和非化妆图像之间的面部妆彩迁移。考虑到两个数据集, A ⊂ R H × W × 3 A ⊂ R ^{H×W ×3} A⊂RH×W×3 是非化妆图像, B ⊂ R H × W × 3 B ⊂ R ^{H×W ×3} B⊂RH×W×3是有不同化妆风格的图像。我们同时学习这两个集合之间的映射关系,表示为 G : A × B → B × A G: A×B →B×A G:A×B→B×A,此处‘ × × ×’表示笛卡儿积。也就是说,给定两张图像的输入:一张源图像 I s r c ∈ A I_{src} ∈ A Isrc∈A,和一张参考图像 I r e f ∈ B I_{ref} ∈ B Iref∈B,网络将生成一张化妆图像 I s r c B ∈ B I^B_{src} ∈ B IsrcB∈B,以及一张卸妆图像 I r e f A ∈ A I^A_{ref} ∈ A IrefA∈A,表示为 ( I s r c B , I r e f A ) = G ( I s r c , I r e f ) (I^B_{src}, I^A_{ref}) = G(I_{src},I_{ref}) (IsrcB,IrefA)=G(Isrc,Iref)。 I s r c B I^B_{src} IsrcB合成 I r e f I_{ref} Iref的化妆风格,同时保留 I s r c I_{src} Isrc的面部特征, I r e f A I^A_{ref} IrefA实现了 I r e f I_{ref} Iref的卸妆。根本问题是如何学习实例级的映射关系,保证输出图像 I s r c B I^B_{src} IsrcB与参考图像 I r e f I_{ref} Iref之间的化妆风格一致。注意,这里没有成对的训练数据。
To address the issue, we introduce pixel-level histogram loss acted on different cosmetics. In addition, perceptual loss has been employed to maintain face identity and structure. Then we can transfer the exact makeup to the source image without the change of face structure. The proposed method is based on Generative Adversarial Networks[10], and it is convenient to integrate all loss terms into one full objective function. Adversarial losses help generate visually pleasant images and refine the correlation among different cosmetics. The details of loss functions and network architectures are shown below.
为了解决这一问题,我们引入不同化妆品的像素直方图损失。除此之外,感知损失用来保持面部特征和结构。然后我们就可以迁移准确的妆彩到源图像,而不会改变面部结构。该方法基于生成对抗网络[10],可以方便地将所有损失项集成到一个完整的目标函数中。对抗损失有助于生成美观的图像,并细化不同化妆品之间的相关性。具体的损失函数和网络架构如下所示。
3.1 Full Objective
3.1 完整目标函数
As illustrated in Figure 2, the overall framework consists of one generator G and two discriminators: DA,DB. In the formulation (I Bsr c , IAr e f ) = G(Isr c , Ir e f ), G accepts two images, Isr c ∈ A and
Ir e f ∈ B, as inputs and generates two translated images as outputs,I Bsr c ∈ B and IA r e f ∈ A.
如图2所示,整个框架包括生成器G和两个识别器:
D
A
D_A
DA,
D
B
D_B
DB。在公式
(
I
s
r
c
B
,
I
r
e
f
A
)
=
G
(
I
s
r
c
,
I
r
e
f
)
(I^B_{src}, I^A_{ref}) = G(I_{src},I_{ref})
(IsrcB,IrefA)=G(Isrc,Iref)中,G接收两张图片,
I
s
r
c
∈
A
I_{src} ∈ A
Isrc∈A和
I
r
e
f
∈
B
I_{ref} ∈ B
Iref∈B作为输入,然后输出两张转换图像
I
s
r
c
B
∈
B
I^B_{src} ∈ B
IsrcB∈B和
I
r
e
f
A
∈
A
I^A_{ref} ∈ A
IrefA∈A。
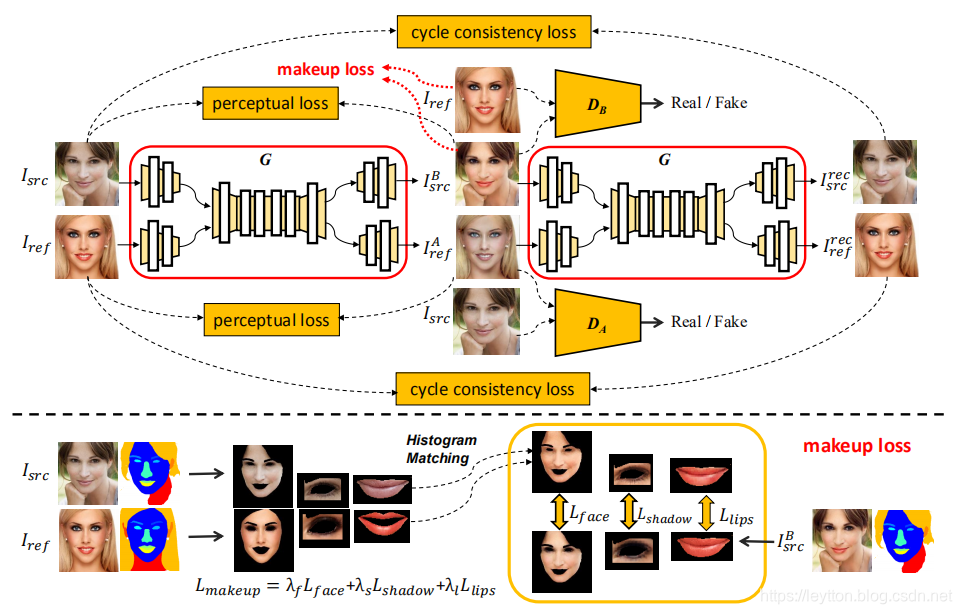
Figure 2: Framework of the proposed BeautyGAN. The upper pipeline shows the overall system. G accpets two images as inputs: non-makeup image I s r c I_{src} Isrc , reference makeup image I r e f I_{ref} Iref , and generates two outputs: transferred makeup image I s r c B I^B_{src} IsrcB , anti-makeup image I r e f A I^A_{ref} IrefA . The generated images are fed into the same G to build up reconstruction results: I s r c r e c I^{rec}_{src} Isrcrec , I r e f r e c I^{rec}_{ref} Irefrec . There are four loss terms for training G: cycle consistency loss, perceptual loss, adversarial loss (denoted as D A D_A DA and D B D_B DB) and makeup loss. The lower pipeline shows the details of makeup loss. It consists of three local histogram loss terms acted on face, eye shadow and lips, respectively. We first utilize face parsing model to separate each cosmetic region of I s r c I_{src} Isrc , I r e f I_{ref} Iref , I s r c B I^B_{src} IsrcB. Then, for each region,we employ histogram matching between I s r c I_{src} Isrc and I r e f I_{ref} Iref to obtain a histogram remapping facial region as ground truth. The local loss term calculates pixel-level differences between such ground truth and corresponding cosmetic region of I s r c B I^B_{src} IsrcB.
图2:BeautyGAN架构。上面的流程显示了整个系统。生成器G接收两张图像作为输入:未化妆图像 I s r c I_{src} Isrc,参考化妆图像 I r e f I_{ref} Iref,并输出两张图像:迁移化妆图像 I s r c B I^B_{src} IsrcB和卸妆图像 I r e f A I^A_{ref} IrefA。生成的两张图像又被输入到同样的生成器G,建立重构结果: I s r c r e c I^{rec}_{src} Isrcrec, I r e f r e c I^{rec}_{ref} Irefrec。训练生成器G时有四类损失:周期一致性损失、对抗损失(表示为 D A D_A DA和 D B D_B DB)、以及化妆损失。下面的流程显示了详细的化妆损失。它包括脸部、眼影和嘴唇三个部分的直方图损失。我们首先利用脸部解析模型来分开 I s r c I_{src} Isrc、 I r e f I_{ref} Iref和 I s r c B I^B_{src} IsrcB的每个化妆区域。然后对于每个区域,我们使用 I s r c I_{src} Isrc和 I r e f I_{ref} Iref之间的直方图匹配,来获得一个重新映射面部区域的直方图作为基准真值。局部损失就是计算基准真值与相应化妆区域 I s r c B I^B_{src} IsrcB之间的像素级差异。
We first give objective functions of D A D_A DA and D B D_B DB, which contain only adversarial losses. D A D_A DA distinguishes the generated image I r e f A I^A_{ref} IrefA from real samples in set A, given by:
£ D A = E I s r c [ l o g D A ( I s r c ) ] + E I s r c , I r e f [ l o g ( 1 − D A ( I r e f A ) ) ] (1) {\LARGE £}D_A = {\LARGE E}I_{src}[logD_A(I_{src})]+{\LARGE E}I_{src},I{ref}[log(1-D_A(I^A_{ref}))] \tag 1 £DA=EIsrc[logDA(Isrc)]+EIsrc,Iref[log(1−DA(IrefA))](1)
Similarly, D B D_B DB aims to distinguish generated image I s r c B I^B_{src} IsrcB from real samples in set B, given by:
£ D B = E I r e f [ l o g D A ( I r e f ) ] + E I s r c , I r e f [ l o g ( 1 − D A ( I s r c B ) ) ] (2) {\LARGE £}D_B={\LARGE E}I_{ref}[logD_A(I_{ref})]+{\LARGE E}I_{src},I{ref}[log(1-D_A(I^B_{src}))]\tag 2 £DB=EIref[logDA(Iref)]+EIsrc,Iref[log(1−DA(IsrcB))](2)
The full objective function of generator G contains four types of losses: adversarial loss, cycle consistency loss, perceptual loss and makeup constrain loss,
£ G = α £ a d v + β £ c y c + γ £ p e r + £ m a k e u p (3) {\LARGE £}G=α{\LARGE £}adv+β{\LARGE £}cyc+γ{\LARGE £}per+{\LARGE £}makeup\tag 3 £G=α£adv+β£cyc+γ£per+£makeup(3)
where α, β,γ are weighting factors that controls the relative importance of each term. Adversarial loss for G integrates two terms: £ D A {\LARGE £}D_A £DAand £ D B {\LARGE £}D_B £DB as
£ a d v = £ D A + £ D B (4) {\LARGE £}adv={\LARGE £}D_A+{\LARGE £}D_B\tag 4 £adv=£DA+£DB(4)
Note that the generator G G G and discriminators D A D_A DA, D B D_B DB play minmax game, where G G G tries to minimize the adversarial loss and discriminators D A D_A DA, D B D_B DB aim to maximize the same loss function. Three remaining losses will be detailed in the subsequent sections.
我们首先给出了目标函数
D
A
D_A
DA 和
D
B
D_B
DB,它们只包含对抗损失。
D
A
D_A
DA对生成的图像
I
r
e
f
A
I^A_{ref}
IrefA与集合A中的真实样本进行区分,得到:
£
D
A
=
E
I
s
r
c
[
l
o
g
D
A
(
I
s
r
c
)
]
+
E
I
s
r
c
,
I
r
e
f
[
l
o
g
(
1
−
D
A
(
I
r
e
f
A
)
)
]
(1)
{\LARGE £}D_A = {\LARGE E}I_{src}[logD_A(I_{src})]+{\LARGE E}I_{src},I_{ref}[log(1-D_A(I^A_{ref}))] \tag 1
£DA=EIsrc[logDA(Isrc)]+EIsrc,Iref[log(1−DA(IrefA))](1)
同样地,
D
B
D_B
DB 对生成的图像
I
s
r
c
B
I^B_{src}
IsrcB与集合B中的真实样本进行区分,得到:
£
D
B
=
E
I
r
e
f
[
l
o
g
D
A
(
I
r
e
f
)
]
+
E
I
s
r
c
,
I
r
e
f
[
l
o
g
(
1
−
D
A
(
I
s
r
c
B
)
)
]
(2)
{\LARGE £}D_B={\LARGE E}I_{ref}[logD_A(I_{ref})]+{\LARGE E}I_{src},I_{ref}[log(1-D_A(I^B_{src}))]\tag 2
£DB=EIref[logDA(Iref)]+EIsrc,Iref[log(1−DA(IsrcB))](2)
生成器G的完整目标函数包括四类损失:对抗损失、周期一致性损失、感知损失、和化妆约束损失,
£
G
=
α
£
a
d
v
+
β
£
c
y
c
+
γ
£
p
e
r
+
£
m
a
k
e
u
p
(3)
{\LARGE £}G=α{\LARGE £}adv+β{\LARGE £}cyc+γ{\LARGE £}per+{\LARGE £}makeup\tag 3
£G=α£adv+β£cyc+γ£per+£makeup(3)
α
,
β
,
γ
α,β,γ
α,β,γ 是控制每一项相对重要性的权重因子。生成器G的对抗损失为
£
D
A
{\LARGE £}D_A
£DA与
£
D
B
{\LARGE £}D_B
£DB的和:
£
a
d
v
=
£
D
A
+
£
D
B
(4)
{\LARGE £}adv={\LARGE £}D_A+{\LARGE £}D_B\tag 4
£adv=£DA+£DB(4)
注意生成器 G G G和识别器 D A D_A DA, D B D_B DB进行最大最小对抗, G G G试图减少对抗损失而判别 D A D_A DA, D B D_B DB旨在最大化相同的损失函数。其余三项损失将在后续章节详细说明。
3.2 Domain-Level Makeup Transfer
3.2 域级妆彩迁移
We exploit domain-level makeup transfer as the foundation of instance-level makeup transfer. Thanks to the dual input/output architecture, the proposed network could simultaneously learn the mapping between two domains within just one generator. The output images are required to preserve face identities and background information as input images. To satisfy these two constraints, we impose perceptual loss and cycle consistency loss, respectively.
我们使用域级妆彩迁移作为实例级妆彩迁移的基础。得益于双输入/输出结构,该网络能够在一个生成器中同时学习两个域之间的映射。输出图像需要保留输入图像的面部特征和背景信息。为了满足这两个约束条件,我们分别使用了感知损失和周期一致性损失。
Rather than directly measuring differences between pixel-level Euclidean distance, perceptual loss calculates differences between high-level features extracted by deep convolutional networks. In this paper, we utilize 16-layer VGG networks pre-trained on ImageNet Dataset. For an image x x x, F l ( x ) F_l(x) Fl(x) denotes the corresponding feature maps in lth layer on VGG, where F l ∈ R C l × H l × W l F_l ∈ R^{C_l ×H_l ×W_l} Fl∈RCl×Hl×Wl . C l C_l Cl is the number of feature maps, H l H_l Hl and W l W_l Wl are height and width of each feature map, respectively. Thus the perceptual loss between input images I s r c I_{src} Isrc , I r e f I_{ref} Iref and output images I s r c B I^B_{src} IsrcB , I r e f A I^A_{ref} IrefA are expressed as:
£ p e r = 1 C l × H l × W l ∑ i j k E l (5) {\LARGE £}per = {1\over C_l × H_l ×W_l}\sum_{ijk}E_l \tag 5 £per=Cl×Hl×Wl1ijk∑El(5) E l = [ F l ( I s r c ) − F l ( I s r c B ) ] i j k 2 + [ F l ( I r e f ) − F l ( I r e f A ) ] i j k 2 (6) E_l = [F_l(I_{src}) − F_l(I^B_{src})]^2_{ijk} + [F_l(I_{ref}) − F_l(I^A_{ref} )]^2_{ijk} \tag 6 El=[Fl(Isrc)−Fl(IsrcB)]ijk2+[Fl(Iref)−Fl(IrefA)]ijk2(6)
where F i j k l F^l_{ijk} Fijkl is the activation of the i i i th filter at position < j , k > <j,k> <j,k> in l l l th layer.
感知损失不是直接测量像素级欧氏距离(欧几里得距离)之间的差异,而是计算深度卷积网络提取的高级特征差异。在本文中,我们使用16层VGG网络对ImageNet数据集进行预处理。对于一张图像
x
x
x,F_l(x)表示VGG上第
l
l
l层对应的特征映射,其中
F
l
∈
R
C
l
×
H
l
×
W
l
F_l ∈ R^{C_l ×H_l ×W_l}
Fl∈RCl×Hl×Wl。
C
l
C_l
Cl是特征映射数量,
H
l
H_l
Hl 和
W
l
W_l
Wl是每个特征映射的高度和宽度。所以,输入图像
I
s
r
c
I_{src}
Isrc ,
I
r
e
f
I_{ref}
Iref和输出图像
I
s
r
c
B
I^B_{src}
IsrcB ,
I
r
e
f
A
I^A_{ref}
IrefA之间的感知损失表示如下:
£
p
e
r
=
1
C
l
×
H
l
×
W
l
∑
i
j
k
E
l
(5)
{\LARGE £}per = {1\over C_l × H_l ×W_l}\sum_{ijk}E_l \tag 5
£per=Cl×Hl×Wl1ijk∑El(5)
E
l
=
[
F
l
(
I
s
r
c
)
−
F
l
(
I
s
r
c
B
)
]
i
j
k
2
+
[
F
l
(
I
r
e
f
)
−
F
l
(
I
r
e
f
A
)
]
i
j
k
2
(6)
E_l = [F_l(I_{src}) − F_l(I^B_{src})]^2_{ijk} + [F_l(I_{ref}) − F_l(I^A_{ref} )]^2_{ijk} \tag 6
El=[Fl(Isrc)−Fl(IsrcB)]ijk2+[Fl(Iref)−Fl(IrefA)]ijk2(6)
其中, F i j k l F^l_{ijk} Fijkl表示第 l l l 层 < j , k > <j,k> <j,k>位置的第 i i i 个过滤器的激活值。
In order to maintain background information, we also introduce cycle consistency loss. When the output images are passed into the generator, it is supposed to generate images as close as the original input images. This procedure can be expressed as
( I s r c , I r e f ) → G ( I s r c , I r e f ) → G ( G ( I s r c , I r e f ) ) ≈ ( I s r c , I r e f ) . (7) (I_{src} , I_{ref} ) → G(I_{src} , I_{ref} ) → G(G(I_{src} , I_{ref})) ≈ (I_{src} , I_{ref}). \tag 7 (Isrc,Iref)→G(Isrc,Iref)→G(G(Isrc,Iref))≈(Isrc,Iref).(7)
The loss function is formulated as
£ c y c = E I s r c , I r e f [ d i s t ( I s r c r e c , I s r c ) + d i s t ( I r e f r e c , I r e f ) ] , (8) {\LARGE £}cyc = {\LARGE E}I_{src},I_{ref} [dist(I^{rec}_{src} , I_{src} ) + dist(I^{rec}_{ref} , I_{ref} )], \tag 8 £cyc=EIsrc,Iref[dist(Isrcrec,Isrc)+dist(Irefrec,Iref)],(8)
where ( I s r c r e c , I r e f r e c ) = G ( G ( I s r c , I r e f ) ) (I^{rec}_{src} , I^{rec}_{ref} ) = G(G(I_{src} , I_{ref})) (Isrcrec,Irefrec)=G(G(Isrc,Iref)). The distance function d i s t ( ⋅ ) dist(·) dist(⋅) could be chosen as L1 norm, L2 norm or other metrics.
为了保持背景信息,我们还引入了周期一致性损失。当输出图像传入生成器时,它应该生成与原始输入图像相近的图像。这个过程可以表示为
(
I
s
r
c
,
I
r
e
f
)
→
G
(
I
s
r
c
,
I
r
e
f
)
→
G
(
G
(
I
s
r
c
,
I
r
e
f
)
)
≈
(
I
s
r
c
,
I
r
e
f
)
.
(7)
(I_{src} , I_{ref} ) → G(I_{src} , I_{ref} ) → G(G(I_{src} , I_{ref})) ≈ (I_{src} , I_{ref}). \tag 7
(Isrc,Iref)→G(Isrc,Iref)→G(G(Isrc,Iref))≈(Isrc,Iref).(7)
损失函数公式为
£
c
y
c
=
E
I
s
r
c
,
I
r
e
f
[
d
i
s
t
(
I
s
r
c
r
e
c
,
I
s
r
c
)
+
d
i
s
t
(
I
r
e
f
r
e
c
,
I
r
e
f
)
]
,
(8)
{\LARGE £}cyc = {\LARGE E}I_{src},I_{ref} [dist(I^{rec}_{src} , I_{src} ) + dist(I^{rec}_{ref} , I_{ref} )], \tag 8
£cyc=EIsrc,Iref[dist(Isrcrec,Isrc)+dist(Irefrec,Iref)],(8)
其中
(
I
s
r
c
r
e
c
,
I
r
e
f
r
e
c
)
=
G
(
G
(
I
s
r
c
,
I
r
e
f
)
)
(I^{rec}_{src} , I^{rec}_{ref} ) = G(G(I_{src} , I_{ref}))
(Isrcrec,Irefrec)=G(G(Isrc,Iref))。距离函数
d
i
s
t
(
⋅
)
dist(·)
dist(⋅) 选择为L1范数、L2范数或其他指标。
3.3 Instance-level Makeup Transfer
3.3 实例级妆彩迁移
To further encourage the network to learn instance-level makeup transfer, it is essential to add constraints on makeup style consistency. We observe that facial makeup could be visually recognized as color distributions. No matter lipsticks, eye shadows or foundations, the makeup process could be mainly understood as color changing. There are various color transfer methods that can be found in the survey [7]. We employ Histogram Matching (HM), a straightforward method, and introduce additional histogram loss on pixel-level, which restricts the output image I s r c B I^B_{src} IsrcB and the reference image I r e f I_{ref} Iref to be identical in makeup style.
为了进一步支持网络学习实例级妆彩迁移,有必要对化妆风格一致性添加约束。我们观察面部妆彩看起来像是颜色分布。无论是口红、眼影还是粉底,化妆的过程主要可以理解为色彩的变化。在调研[7]中发现了各种各样的色彩迁移方法。我们采用了一种简单的直方图匹配方法,在像素级引入了额外的直方图损失,使得输出图像 I s r c B I^B_{src} IsrcB和参考图像 I r e f I_{ref} Iref在化妆风格上完全相同。
Histogram loss. If we directly adopt MSE loss on pixel-level histograms of two images, the gradient will be zero, owning to the indicator function, thus makes no contribution to optimization process. Therefore, we adopt histogram matching strategy that generates a ground truth remapping image in advance. Suppose that we want to calculate histogram loss on pixels between original image x x x and reference image y y y, we should first perform histogram matching on x x x and y y y to obtain a remapping image H M ( x , y ) HM(x,y) HM(x,y), which has the same color distribution as y y y but still preserves content information as x x x. After we get H M ( x , y ) HM(x,y) HM(x,y), it is convenient to utilize the MSE loss between H M ( x , y ) HM(x,y) HM(x,y) and x x x, then back-propagate the gradients for optimization.
直方图损失。 由于指标函数的关系,如果我们直接对两幅图像的像素直方图采用MSE(均方误差)损失,梯度将会为零,这对优化过程毫无意义。因而,我们采用直方图匹配策略,提前生成一幅基准真值重映射图像。如果我们想要计算源图像 x x x和参考图像 y y y之间的像素直方图损失,我们应该首先对 x x x和 y y y执行直方图匹配,以获得一个重新映射图像 H M ( x , y ) HM(x,y) HM(x,y),它的颜色分布与 y y y相同,但仍然将内容信息保留为 x x x。我们获取到 H M ( x , y ) HM(x,y) HM(x,y)后,很容易利用 H M ( x , y ) HM(x,y) HM(x,y)与 x x x之间的均值方差损失,反向传播梯度来进行优化。
Face parsing. Instead of utilizing histogram loss over the entire image, we split the makeup style into three important components – lipsticks, eye shadow, foundation. State-of-the-art methods like [23] also take these three components as makeup representations. And then we apply localized histogram loss on each part. The reasons are two folds. First, pixels in background and hairs have no relationship with makeup. If we do not separate them apart, they will disturb the correct color distribution. Second, facial makeup is beyond a global style but a collection of several independent styles in different cosmetics regions. In that sense, we employ the face parsing model in[32] to obtain face guidance mask as M = F P ( x ) M = FP(x) M=FP(x). For each input image x x x, pre-trained face parsing model would generate an index mask M M M denoting several facial locations, including lips, eyes, face skin (corresponds to foundation), hairs, background and so on. At last, for each M M M, we track different labels to produce three corresponding binary masks, representing for cosmetics spatiality: M l i p , M e y e , M f a c e M_{lip}, M_{eye} , M_{face} Mlip,Meye,Mface . It is important to note that eye shadows are not annotated on M M M, because the before-makeup images have no eye shadows. But we expect the result image I s r c B I^B_{src} IsrcB to have similar eye shadow color and shape as reference image I r e f I_{ref} Iref . According to eyes mask M e y e M_{eye} Meye , we calculate two rectangle areas enclosing eye shadows and then exclude eyes regions, some hair and eyebrow regions in between. Thus we could create a specific binary mask representing for eye-shadows M s h a d o w M_{shadow} Mshadow .
面部解析。我们没有利用整个图像的直方图损失,而是把化妆风格分成三个重要的部分——口红、眼影、粉底。最先进的方法,如[23],也采取这三个组成部分作为化妆代表。然后我们对每个部分应用局部直方图损失。理由有两方面:首先,背景像素和头发跟化妆没有关系。如果我们不把它们分开,它们就会扰乱正确的颜色分布。其次,面部化妆不仅是全局风格,更是不同化妆区域风格的集合。所以,我们使用[32]中的人脸解析模型来获得人脸引导掩码,即 M = F P ( x ) M = FP(x) M=FP(x)。对于每个输入图像 x x x,预训练人脸解析模型将生成一个索引掩码 M M M来表示几个面部位置,包括嘴唇、研究、面部皮肤(对应粉底)、头发、背景等。最后,对于每个 M M M,我们根据不同标签,产生三个对应的二进制掩码,分别代表化妆空间性: M l i p , M e y e , M f a c e M_{lip}, M_{eye} , M_{face} Mlip,Meye,Mface。需要注意的是,眼影没有标注在 M M M上,因为化妆前的图像并没有眼影。但我们希望结果图像 I s r c B I^B_{src} IsrcB具有与参考图像 I r e f I_{ref} Iref相似的眼影颜色和形状。根据眼部掩码 M e y e M_{eye} Meye ,我们计算出两个包含眼影的矩形区域,然后排除眼睛区域,一些头发和眉毛区域。因此,我们可以为眼影 M s h a d o w M_{shadow} Mshadow创建一个特定的二进制掩码。
Makeup loss. The overall makeup loss are integrated by three local histogram losses acted on lips, eye shadows and face regions,respectively:
£ m a k e u p = λ l £ l i p s + λ s £ s h a d o w + λ f £ f a c e , (9) {\LARGE £}makeup = λ_l{\LARGE £}lips + λ_s {\LARGE £}shadow + λ_f {\LARGE £}f ace , \tag 9 £makeup=λl£lips+λs£shadow+λf£face,(9) where λ l λ_l λl , λ s λ_s λs, λ f λ_f λf are weight factors. We multiply images with their corresponding binary masks and process spatially histogram matching between result image I s r c B I^B_{src} IsrcB and reference image I r e f I_{ref} Iref . Formally, we define local histogram loss as
£ i t e m = ∥ I s r c B H M ( I s r c B ◦ M i t e m 1 , I r e f ◦ M i t e m 2 ) ∥ 2 (10) {\LARGE £}item = ∥I^B_{src} HM(I^B_{src} ◦ M^1_{item}, I_{ref} ◦ M^2_{item})∥_2 \tag {10} £item=∥IsrcBHM(IsrcB◦Mitem1,Iref◦Mitem2)∥2(10) M 1 = F P ( I s r c B ) (11) M_1 = FP(I^B_{src}) \tag {11} M1=FP(IsrcB)(11) M 2 = F P ( I r e f ) (12) M_2 = FP(I_{ref}) \tag {12} M2=FP(Iref)(12)
Here, ◦ denotes element-wise multiplication and item are in set of { l i p s , s h a d o w , f a c e } {\{lips,shadow, f ace\}} {lips,shadow,face}.
妆容损失。 整体妆容损失由嘴唇、眼影和脸部三个局部区域的直方图损失综合而成,分别为:
£
m
a
k
e
u
p
=
λ
l
£
l
i
p
s
+
λ
s
£
s
h
a
d
o
w
+
λ
f
£
f
a
c
e
,
(9)
{\LARGE £}makeup = λ_l{\LARGE £}lips + λ_s {\LARGE £}shadow + λ_f {\LARGE £}face , \tag 9
£makeup=λl£lips+λs£shadow+λf£face,(9)
其中,
λ
l
λ_l
λl ,
λ
s
λ_s
λs,
λ
f
λ_f
λf是权重因子。我们将图像与相应的二进制掩码相乘,处理结果图像
I
s
r
c
B
I^B_{src}
IsrcB与参考图像
I
r
e
f
I_{ref}
Iref之间的空间直方图匹配。我们将局部直方图损失定义为
£
i
t
e
m
=
∥
I
s
r
c
B
H
M
(
I
s
r
c
B
◦
M
i
t
e
m
1
,
I
r
e
f
◦
M
i
t
e
m
2
)
∥
2
(10)
{\LARGE £}item = ∥I^B_{src} HM(I^B_{src} ◦ M^1_{item}, I_{ref} ◦ M^2_{item})∥_2 \tag {10}
£item=∥IsrcBHM(IsrcB◦Mitem1,Iref◦Mitem2)∥2(10)
M
1
=
F
P
(
I
s
r
c
B
)
(11)
M_1 = FP(I^B_{src}) \tag {11}
M1=FP(IsrcB)(11)
M
2
=
F
P
(
I
r
e
f
)
(12)
M_2 = FP(I_{ref}) \tag {12}
M2=FP(Iref)(12)
此处,◦ 表示对应元素相乘,item是集合
{
l
i
p
s
,
s
h
a
d
o
w
,
f
a
c
e
}
{\{lips,shadow, face\}}
{lips,shadow,face}中的元素。
4 DATA COLLECTION
4 数据收集
We collect a new facial makeup dataset consisting of 3834 female images in total, with 1115 non-makeup images and 2719 makeup images. We refer to this dataset as the Makeup Transfer(MT) dataset.It includes some variations in race, pose, expression and background clutter. Plenty of makeup styles have been assembled, including smoky-eyes makeup style, flashy makeup style, Retro makeup style,Korean makeup style and Japanese makeup style, varying from subtle to heavy. Specifically, there are some nude makeup images,as for convenience, have been classified into non-makeup category.
我们收集了一个新的面部化妆数据集,共包含3834张女性图像,分为1115张未化妆和2719张化妆图像。我们把这个数据集称为妆彩迁移(MT)数据集。它包含不同的种族、姿态、表情和背景,汇集了大量的化妆风格,包括烟熏妆、浮华妆、复古妆、韩妆、日妆风格,从淡妆到浓妆都有。有一些裸妆图片,为了方便起见,已经被归类为非化妆类。
The initial data are crawled from websites. We manually remove low resolution images under bad illumination condition. And then retained images are employed face alignment with 68 landmarks.According to the two eye locations, we transform them to the sames patial size 256 × 256. Among 3834 images, we randomly select 100 non-makeup images and 250 makeup images for test. The remaining images are separated into training set and validation set.
最初的数据是从网站上抓取的。我们手动除去了光照较差情况下的低分辨图片。然后用68个特征点将剩下图像的人脸对齐。根据两只眼睛的位置,我们将统一其转换为256 × 256尺寸。在3834张图像中,我们随机选取100张未化妆图像和250张化妆图像进行测试。剩下的图像分为训练集和验证集。
MT is the biggest makeup dataset comparing to other released makeup datasets. Existing makeup datasets mostly consist of no more than 1000 images. They typically assemble pairs of images for one subject: before-makeup image and after-makeup image pair. Although the same object is obtained in such pair images,they have differences on view: poses, expressions even illumination.Generally, they are applied for studying the impact of makeup in face recognition and are inapplicable for makeup transfer task.MT dataset contains diverse makeup styles and more than 3000 subjects. The detailed comparison between makeup datasets are listed in table 1. Examples of MT are illustrated in Figure 3.
相比其他发布的化妆数据集,MT是最大的。现有的化妆数据集大部分不超过1000张图片,它们一般收集了同一主题对象的多张图片:妆前图片和妆后图片组。尽管同一对象有多张图片,也有不同的方面:姿势、表情甚至光照。一般而言,它们适合用于研究化妆对面部识别的影响,但并不适合化妆风格迁移任务。MT数据集包含不同的化作风格并且超过3000个主题对象。表1列出了化妆数据集之间的详细对比。MT的例子如图3所示。

Figure 3: Samples from MT dataset. The non-makeup and makeup images are shown in upper row and lower row.
图3:MT数据集样本。上面一行是未化妆图像,下面一行是化妆图像。
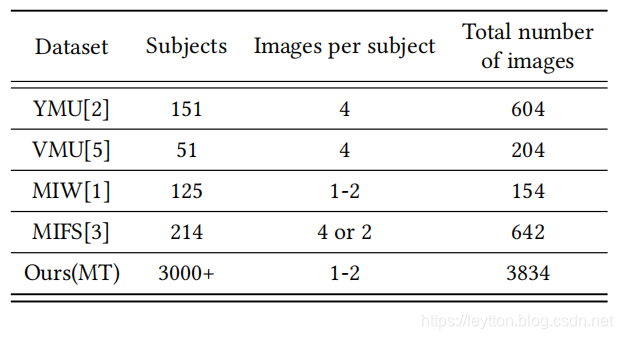
Table 1: Comparison with released makeup datasets.
表1:化妆数据集对比
5 EXPERIMENTS 实验
In this section, we depict the network architecture and training setting. All the experiments apply the same MT dataset we release. We compare performances of our method and some other baselines from both qualitative and quantitative perspectives. And we further give a thorough analysis on components of BeautyGAN.
在本节中,我们将描述网络结构和训练设置。所有的实验都会使用我们发布的MT数据集。我们从定性和定量方面,将我们的方法与其他方法做了对比。并对BeautyGAN的成分进行了深入分析。
5.1 Implementation Details
5.1 实现细节
Network architecture. We design the generator G with two inputs and two outputs. To be specific, the network contains two separate input branches with convolutions, respectively. In the middle we concatenate these two branches together and feed them into several residual blocks. After that, the output feature maps will be up sampled by two individual branches of transposed convolutions to generate two result images. Note that the branches do not share parameters within layers. We also use instance normalization [30] for G. As for discriminators DA and DB, we leverage identical 70×70 PatchGANs [18], which classifies local overlapping image patches to be real or fake.
网络结构。 我们设计了有两个输入输出的生成器G。具体来说,网络包含两个单独的卷积输入分支。在中间,我们将这两个分支连接在一起,并将它们提供给几个残差块。然后输出特征映射将会被两个独立的换位卷积分支抽样,生成两个结果图像。请注意,分支在层内不共享参数。我们还对G使用实例归一化[30]。对于识别器DA和DB,我们利用相同的70×70 PatchGANs[18],将局部重叠的图像块进行分类,以区分真假。
Training Details. To stabilize the training procedure and generate high quality images, we apply two additional training strategies. First, inspired by [35], we replace all negative log likelihood objective in adversarial loss by a least square loss [24]. For instance, equation 1 is then defined as below, so as equation 2 and 4:
£ D A = E I s r c [ ( D A ( I s r c ) − 1 ) 2 ] + E I s r c , I r e f [ D A ( I r e f A ) 2 ] (13) {\LARGE £}D_A = {\LARGE E}I_{src} [(D_A(I_{src}) − 1)^2] + {\LARGE E}I_{src},I_{ref} [D_A(I^A_{ref})^2] \tag {13} £DA=EIsrc[(DA(Isrc)−1)2]+EIsrc,Iref[DA(IrefA)2](13)
Second, we introduce spectral normalization [26] for stably training discriminators. It is computationally light and easy to incorporate, which satisfies the Lipschitz constraint σ ( W ) = 1 σ(W) = 1 σ(W)=1:
W S N ( W ) : = W σ ( W ) , (14) W_{SN} (W) := {W \over σ(W) }, \tag {14} WSN(W):=σ(W)W,(14)
where σ ( W ) σ(W) σ(W) is the spectral norm of W W W , denoted as:
σ ( w ) : = max h : h ≠ 0 ∥ W h ∥ 2 ∥ h ∥ 2 = max ∥ h ∥ 2 ≤ 1 ∥ W h ∥ 2 , (15) σ(w) := \max_{h:h\ne0} {∥W h∥_2 \over ∥h∥_2} = \max_{∥h ∥_2≤1 }∥W h∥_2, \tag {15} σ(w):=h:h=0max∥h∥2∥Wh∥2=∥h∥2≤1max∥Wh∥2,(15)
here, h h h is the input of each layer.
训练细节。 为了稳定训练过程并生成高质量的图像,我们采用了两种额外的训练策略。首先,受[35]启发,我们用最小平方损失[24]代替所有负对数似然目标。例如,公式(1)定义如下,公式(2)、(4)同样道理:
£
D
A
=
E
I
s
r
c
[
(
D
A
(
I
s
r
c
)
−
1
)
2
]
+
E
I
s
r
c
,
I
r
e
f
[
D
A
(
I
r
e
f
A
)
2
]
(13)
{\LARGE £}D_A = {\LARGE E}I_{src} [(D_A(I_{src}) − 1)^2] + {\LARGE E}I_{src},I_{ref} [D_A(I^A_{ref})^2] \tag {13}
£DA=EIsrc[(DA(Isrc)−1)2]+EIsrc,Iref[DA(IrefA)2](13)
其次,我们引入了谱归一化[26]来稳定训练识别器。它计算轻量且组合容易,满足Lipschitz约束条件
σ
(
W
)
=
1
σ(W) = 1
σ(W)=1:
W
S
N
(
W
)
:
=
W
σ
(
W
)
,
(14)
W_{SN} (W) := {W \over σ(W) }, \tag {14}
WSN(W):=σ(W)W,(14)
其中,
σ
(
W
)
σ(W)
σ(W)是
W
W
W的谱模,定义为:
σ
(
w
)
:
=
max
h
:
h
≠
0
∥
W
h
∥
2
∥
h
∥
2
=
max
∥
h
∥
2
≤
1
∥
W
h
∥
2
,
(15)
σ(w) := \max_{h:h\ne0} {∥W h∥_2 \over ∥h∥_2} = \max_{∥h ∥_2≤1 }∥W h∥_2, \tag {15}
σ(w):=h:h=0max∥h∥2∥Wh∥2=∥h∥2≤1max∥Wh∥2,(15)
此处,
h
h
h是每层的输入。
For all experiments, we obtain masks annotated labels on different facial regions through a PSPNet[33] trained for face segmentation. The relu_4_1 feature layer of VGG16[28] network is applied for identity preserving. Such VGG16 is pre-trained on ImageNet and has parameters fixed all through training process. The parameters in equations 3 and 9 are: α = 1 , β = 10 , γ = 0.005 , λ l = 1 , λ s = 1 , λ f = 0.1 α = 1, β = 10,γ = 0.005, λ_l = 1, λ_s = 1, λ_f = 0.1 α=1,β=10,γ=0.005,λl=1,λs=1,λf=0.1. We train the network from scratch using Adam[16] with learning rate of 0.0002 and batch size of 1.
对于所有实验,我们通过用于面部分割的PSPNet[33]在不同面部区域上获得标注了的掩码。VGG16[28]网络的relu_4_1特征层用于保持识别特征。这种VGG16是在ImageNet上预训练的,参数在整个训练过程中都是固定的。公式3和9中的参数为: α = 1 , β = 10 , γ = 0.005 , λ l = 1 , λ s = 1 , λ f = 0.1 α = 1, β = 10,γ = 0.005, λ_l = 1, λ_s = 1, λ_f = 0.1 α=1,β=10,γ=0.005,λl=1,λs=1,λf=0.1。我们使Adam[16]从零开始训练网络,学习率为0.0002,批量大小为1。
5.2 Baselines
5.2 参考标准
Digital Face Makeup[11] is an early makeup transfer work, applying traditional image processing method.
DTN[23] is the state-of-the-art makeup transfer work. It proposes a deep localized makeup transfer network, which independently transfers different cosmetics.
Deep Image Analogy [21] is a recent work, which realizes visual attribute transfer across two semantic-related images. It adapts image analogy to match features extracted from deep neural networks. We apply it on makeup transfer task for comparison.
CycleGAN[35] is an representative unsupervised image-to-image translation work. To adapt makeup transfer task, we modify the generator in it with two branches as input, but maintain all the other architecture and setting as the same.
Style Transfer[13] is a related work, which trains a feed-forward network for synthesizing style and content information from respective images. We employ non-makeup image as content and reference makeup image as style for experiments.
**数字人脸化妆[11]**是比较早期的妆彩迁移工作,应用传统的图像处理方法。
DTN[23] 是最先进的的妆彩迁移工作。它提出了深度本地化的妆彩迁移网络,可以独立迁移不同妆彩。
深度图像类比 [21] 是近年来的一项工作,它实现了两个语义相关图像之间的视觉属性迁移,采用图像类比的方法来匹配深度神经网络提取的特征。
CycleGAN[35] 是一项非监督图到图迁移的经典研究工作,为了适应妆彩迁移任务,我们修改生成器为两个输入分支,但保持其他结构和设置不变。
风格迁移[13] 是一项相关工作,它训练一个前馈网络来综合各个图像的风格和内容信息。我们使用非化妆图像的内容和参考化妆图像的风格进行实验。
5.3 Comparison Against Baselines
5.3 对比参考标准
Qualitative evaluation. As demonstrated in Figure 4, we show qualitative comparison results with baselines. We observe that although Guo et al. [11] produces images with makeup on, the results all have visible artifacts. It seems like a fake mask attached on the non-makeup face. Mismatch problem occurs around facial and eyes contour. Some incorrect details are transferred, such as the black eye shadows on the second and fourth rows are transferred into blue. Liu et al. [23] transfers different cosmetics independently, as a result, it shows alignment artifacts around eye areas and lips area. The foundation and eye shadows have not been correctly transferred as well. Style transfer[13] generates images introducing grain-like artifacts, which deteriorate image quality. It typically transfers global style like painting strokes thus is infeasible for delicate makeup style transfer. Comparing to the above methods, CycleGAN[35] could produces relatively realistic images. However, the makeup styles are not consistent with references. Liao et al. [21] produces outputs with similar makeup styles as references and shows natural results. However, it transfers not only facial makeup, but also other features in reference images. For example, the third image changes background color from black to gray, the fourth image changes hair color and all images modify pupil colors to be like references. In addition, it transfers lighter makeup styles than references, especially in lipsticks and eye shadows.
定性评估. 如图4所示,我们展示了与其他基线的质量对比结果。我们可以看到,尽管Guo等人[11]在生成了化妆图像,但结果都有可见的人工痕迹。这看起来像假面具戴在未化妆的人脸上。面部和眼廓周围会出现不匹配问题。一些细节迁移不正确,例如第二行和第四行的黑眼影被迁移成了蓝色;Liu等人[23]分别传输不同的妆彩,因此,它显示在眼睛和嘴唇区域显示了人工对齐痕迹。粉底和眼影没有很好地迁移;风格迁移[13] 产生的图像存在颗粒状人工痕迹,使得图像质量变差。它典型的像画笔一样的全局风格迁移并不适精致的妆彩风格迁移;对比以上方法,CycleGAN[35]能够产生相对真实的图像。然而化妆风格和参考图像不太一致;Liao等人[21] 生成了与参考图像化作风格相似的结果,并且显示很自然。但是它不仅把化妆风格给迁移了,还把其他参考图像的特征也迁移了。例如,第三张图像将黑色背景图转化成灰色,第四张图将头发颜色以及所有图像的瞳孔颜色都转化成跟参考图像一样。此外,它转移的妆彩比参考图像更轻,尤其是口红和眼影。

Figure 4: Qualitative comparisons between BeautyGAN and baselines. The first two columns are non-makeup images and reference images, respectively. Each row in the remaining columns shows the makeup transfer results of different methods.
图4:BeautyGAN和其他参考标准的定性比较。前两列分别是是未化妆图像和参考图像。剩余列的每行展示了不同方法的妆彩迁移效果。
Compared with baselines, our method generates high quality images with the most accurate makeup styles on, no matter compared in eye shadows, lipsticks or foundations. For instance, in the second row, only our result transfers the dark eye shadows of reference image. The results also show that BeautyGAN keep other makeup-irrelevant components intact as the original non-makeup images, like hairs, clothes and background. In Figure 5, we zoom in the performances of eye makeup and lipsticks transfer for better demonstrating the comparison. More results are shown in the supplementary file.
对比参考标准,我们的方法能够产生最精准的化妆风格高质量图像,无论是眼影、口红还是粉底。举个例子,在第二行,只有我们的结果迁移了参考图像的黑色眼影。研究结果还表明,BeautyGAN保留了原图其他与化妆无关的成分,如头发、衣服和背景。在图5中,我们放大了眼部彩妆和口红迁移的效果,以便更好地展示对比。更多结果请看补充文件。
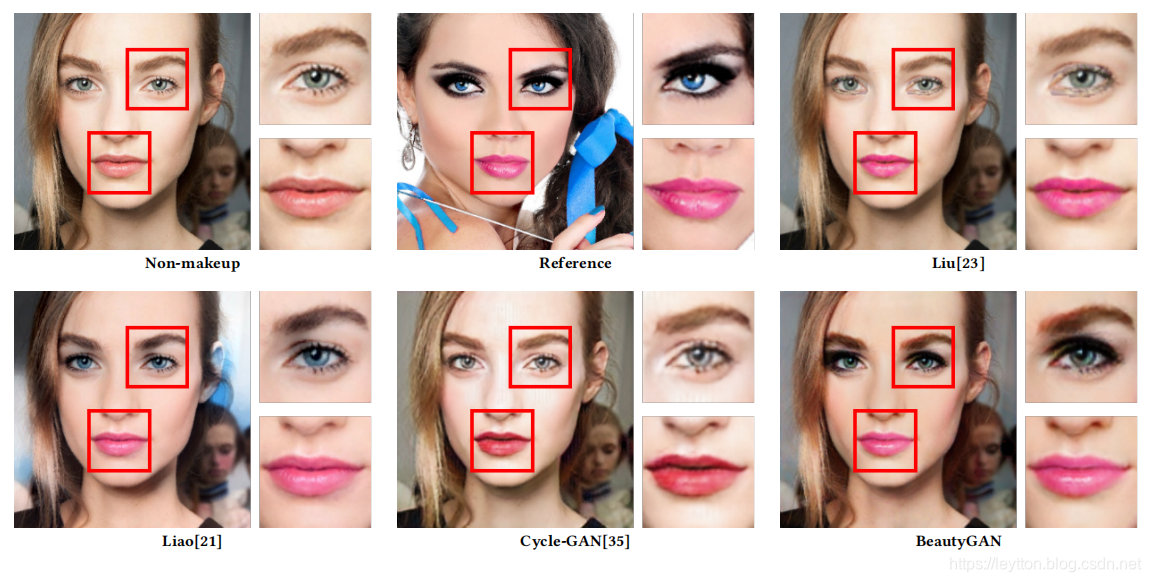
Figure 5: Zoom in the performance of eye makeup and lipsticks transfer.
图5:放大眼部彩妆和口红的转移效果。
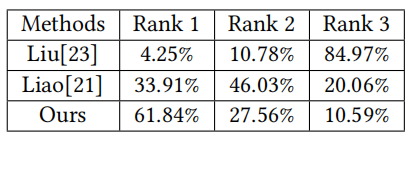
Quantitative comparison. For quantitative evaluation on BeautyGAN, we conduct a user study from 84 volunteers. We randomly choose 10 non-makeup test images and 20 makeup test images, which would obtain 10×20 after-makeup results for each makeup transfer method. Two representative baselines are in comparison: Liao et al. [21] and Liu et al. [23]. Each time, we present five images, including a non-makeup image, a makeup image as reference, and three randomly shuffled makeup transfer images generated from different methods. Participants are instructed to give a rank order of three generated images, based on quality, realism and makeup style similarity. Rank 1 represents the best makeup transfer performance while rank 3 represent the worst makeup transfer performance.
定量比较. 对于BeautyGAN的定性评估,我们对84位志愿者进行了调研。我们随机选择10位未化妆测试图像和20张化妆测试图像,每种妆彩迁移方法得到10×20张化妆后效果。比较了两种具有代表性的方法:Liao等人的[21]和Liu等人的[23]。每次,我们展示5张图片,包括一张未化妆图片,一张化妆参考图片,和三张使用不同方法产生的随机打乱的妆彩迁移图片。参与者被要求根据质量、真实感和化妆风格的相似性,对生成的三张图片进行排序。排名1表示最好的妆彩迁移效果,排名3表示最差的妆彩迁移效果。
Table 3 shows the results. For each method, we normalize the votes and obtain the percentages of three rank orders. There are 61.84% results of BeautyGAN rank number one, comparing to 33.91% of Liao et al. and 4.25% of Liu et al… Also, BeautyGAN has the least percentage on Rank 3 column. We observe that BeautyGAN is mostly voted as Rank 1, Liao et al. distributes mainly on Rank 2 and Liu et al. has most votes on Rank 3. User study demonstrates that our method performs better than other baselines.
表3是用户调研结果。对于每种方法,我们对投票进行规范化,并获得三个排名的百分比。排名第一的BeautyGAN结果为61.84%,Liao等为33.91%,Liu等为4.25%。同时,BeautyGAN在第三列的比例最低。我们观察到,BeautyGAN的得票以1居多,Liao等人的得票以2居多,Liu等人的得票以3居多。用户调研显示了我们的方法比其他方法效果更好。
Table 3: Result of user study.
表3:用户调研结果
5.4 Component Analysis of BeautyGAN BeautyGAN成分分析
To investigate the importance of each component in overall objective function (Eqn. 3), we perform ablation studies. We mainly analyse the effect of perceptual loss term (Eqn. 5) and makeup loss term (Eqn. 9). Thus the experiments are conducted with adversarial and cycle consistency loss all the time. Table 2 shows the settings and Figure 6 demonstrates the results.
为了研究每个成分在整体目标函数中的重要性(等式3),我们进行了排除法研究。我们主要分析感知损失项(等式5)和妆彩损失项(等式9)。因此,实验始终采用对抗和循环一致性损失。表2展示了设置,图6展示了结果。

Figure 6: Results of ablation study. The first two columns are non-makeup images and reference images, respectively. Each row in the remaining columns shows the makeup transfer results of five experiments: A, B, C, D, E. Different experiment settings are illustrated in Table 2.
图6:排除法研究结果。前两列分别是非化妆图像和参考图像。其余的每行展示了A、B、C、D、E五个实验的妆彩迁移结果。表2展示了不同的实验设置。
Table 2: Ablation Study Setups
表 2: 排除法研究步骤
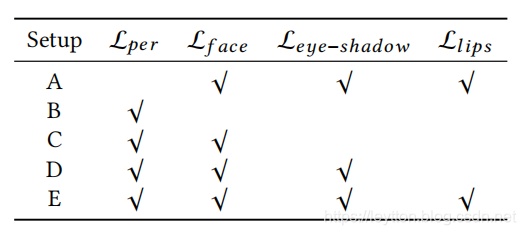
In experiment A, we remove the perceptual loss term from Eqn. 3. In such situation, the results are all fake images like two inputs warped and merged on pixels. On the contrary, other experiments, where perceptual loss term is included, show that the identities of non-makeup faces are maintained. Therefore, it indicates perceptual loss helps to preserve image identity.
在实验A中,我们移除了公式3中的感知损失项。这种情况下,结果都是假图像,就像两张输入图像的像素扭曲和合并一样。相反,其他包含感知损失的实验显示,未化妆的面部身份特征被保留下来。因此,这表明感知损失有助于保留图像身份特征。
Experiments B, C, D, E are designed for investigating makeup loss term, which consists of three local histogram loss acted on different cosmetic regions: £ f a c e , £ s h a d o w , £ l i p s {\LARGE £}face,{\LARGE £}shadow, {\LARGE £}lips £face,£shadow,£lips. In experiment B, we directly remove makeup loss from Eqn. 3. We find the generated images are slightly modified on skin tone and lipsticks, but do not transfer makeup style from reference images. We then sequentially add £ f a c e {\LARGE £}face £face , £ s h a d o w {\LARGE £}shadow £shadow and £ l i p s {\LARGE £}lips £lips on experiment C, D, E. Column C shows results that foundation could be successfully transferred from reference images. Based on foundation transfer, experiment D add eye shadow constraints £ s h a d o w {\LARGE £}shadow £shadow within. We observe that local eye makeup are transferred as well. Column E is the results trained with overall makeup loss. It shows that lipsticks are additionally transferred comparing to column D. To sum up, makeup loss is necessary for instance-level makeup transfer. Three terms of makeup loss play role on foundation, eye shadow and lipsticks transfer, respectively.
实验B、C、D被设计用于研究化妆损失项,包含三个化妆区域的局部直方图损失: £ f a c e , £ s h a d o w 和 £ l i p s {\LARGE £}face,{\LARGE £}shadow和{\LARGE £}lips £face,£shadow和£lips。在实验B中,我们直接移除公式3的化妆损失,发现生成图像在肤色和口红有轻微的修改,但并没有将参考图像的妆彩风格迁移。我们随后在实验C、D、E上依次添加了 £ f a c e {\LARGE £}face £face , £ s h a d o w {\LARGE £}shadow £shadow 和 £ l i p s {\LARGE £}lips £lips。C列表明参考图像的粉底可以被成功迁移出来。基于粉底迁移,实验D中添加眼影约束 £ s h a d o w {\LARGE £}shadow £shadow,我们观察到眼部妆彩也迁移得比较好。E列是经过完整化妆损失训练的结果,实验表明,与D列相比,口红也迁移了。粉底、眼影和口红三项化妆损失有着各自的作用。
6 CONCLUSION AND FUTURE WORK
6.总结和未来工作
In this paper, we propose a dual input/output BeautyGAN for instance-level facial makeup transfer. With one generator, BeautyGAN could realize makeup and anti-makeup simultaneously in a single forward pass. We introduce pixel-level histogram loss to constrain the similarity of makeup style. Perceptual loss and cycle consistency loss have been employed to preserve identity. Experimental results demonstrate that our approach can achieve significant performance gain over existing approaches.
在这篇论文中,我们提出了一种双重输入/输出的方法BeautyGAN,来进行实例级的面部妆彩转移。使用一个生成器,BeautyGAN能在单个前向传播中同时实现化妆和卸妆。我们引入了像素直方图损失来约束化妆风格的相似性。感知损失和 周期一致性损失用于保持面部特征。实验结果表明,与现有方法相比,我们的方法可以获得显著的效果提升。
REFERENCES 参考文献
[1] Cunjian Chen, Antitza Dantcheva, and Arun Ross. 2013. Automatic facial makeup detection with application in face recognition. In Biometrics (ICB), 2013 International Conference on. IEEE, 1–8.
[2] Cunjian Chen, Antitza Dantcheva, and Arun Ross. 2016. An ensemble of patchbased subspaces for makeup-robust face recognition. Information fusion 32 (2016),80–92.
[3] Cunjian Chen, Antitza Dantcheva, Thomas Swearingen, and Arun Ross. 2017.Spoofing faces using makeup: An investigative study. In Identity, Security and Behavior Analysis (ISBA), 2017 IEEE International Conference on. IEEE, 1–8.
[4] Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. 2017. StarGAN: Unified Generative Adversarial Networks for MultiDomain Image-to-Image Translation. arXiv preprint arXiv:1711.09020 (2017).
[5] Antitza Dantcheva, Cunjian Chen, and Arun Ross. 2012. Can facial cosmetics affect the matching accuracy of face recognition systems?. In Biometrics: Theory,Applications and Systems (BTAS), 2012 IEEE Fifth International Conference on. IEEE,391–398.
[6] Brian Dolhansky and Cristian Canton Ferrer. 2017. Eye In-Painting with Exemplar Generative Adversarial Networks. arXiv preprint arXiv:1712.03999 (2017).
[7] Hasan Sheikh Faridul, Tania Pouli, Christel Chamaret, Jürgen Stauder, Alain Trémeau, Erik Reinhard, et al. 2014. A Survey of Color Mapping and its Applications. Eurographics (State of the Art Reports) 3 (2014).
[8] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. 2015. A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576 (2015).
[9] Leon A Gatys, Alexander S Ecker, Matthias Bethge, Aaron Hertzmann, and Eli Shechtman. 2017. Controlling perceptual factors in neural style transfer. In IEEE Conference on Computer Vision and Pattern Recognition.
[10] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley,Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Advances in neural information processing systems. 2672–2680.
[11] Dong Guo and Terence Sim. 2009. Digital face makeup by example. In Computer Vision and Pattern Recognition, 2009. IEEE Conference on. IEEE, 73–79.
[12] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2016. Image-to-image translation with conditional adversarial networks. arXiv preprint arXiv:1611.07004 (2016).
[13] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision. Springer, 694–711.
[14] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jungkwon Lee, and Jiwon Kim. 2017. Learning to discover cross-domain relations with generative adversarial networks.arXiv preprint arXiv:1703.05192 (2017).
[15] Taeksoo Kim, Byoungjip Kim, Moonsu Cha, and Jiwon Kim. 2017. Unsupervised visual attribute transfer with reconfigurable generative adversarial networks.arXiv preprint arXiv:1707.09798 (2017).
[16] Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
[17] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. 2016. Photo-realistic single image super-resolution using a generative
adversarial network. arXiv preprint arXiv:1609.04802 (2016).
[18] Chuan Li and Michael Wand. 2016. Precomputed real-time texture synthesis with markovian generative adversarial networks. In European Conference on Computer Vision. Springer, 702–716.
[19] Chen Li, Kun Zhou, and Stephen Lin. 2015. Simulating makeup through physics-based manipulation of intrinsic image layers. In IEEE Conference on Computer Vision and Pattern Recognition. 4621–4629.
[20] Yi Li, Lingxiao Song, Xiang Wu, Ran He, and Tieniu Tan. 2017. Anti-Makeup:
Learning A Bi-Level Adversarial Network for Makeup-Invariant Face Verification.arXiv preprint arXiv:1709.03654 (2017).
[21] Jing Liao, Yuan Yao, Lu Yuan, Gang Hua, and Sing Bing Kang. 2017. Visual attribute transfer through deep image analogy. ACM Transactions on Graphics(TOG) 36, 4 (2017), 120.
[22] Ming-Yu Liu and Oncel Tuzel. 2016. Coupled generative adversarial networks. In Advances in neural information processing systems. 469–477.
[23] Si Liu, Xinyu Ou, Ruihe Qian, Wei Wang, and Xiaochun Cao. 2016. Makeup like a superstar: deep localized makeup transfer network. In the Association for the Advance of Artificial Intelligence. AAAI Press, 2568–2575.
[24] Xudong Mao, Qing Li, Haoran Xie, Raymond Y. K. Lau, and Zhen Wang. 2016. Multi-class Generative Adversarial Networks with the L2 Loss Function. CoRR abs/1611.04076 (2016). arXiv:1611.04076 http://arxiv.org/abs/1611.04076
[25] Mehdi Mirza and Simon Osindero. 2014. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014).
[26] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. 2018. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957 (2018).
[27] Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, and Russ Webb. 2016. Learning from simulated and unsupervised images through adversarial training. arXiv preprint arXiv:1612.07828 (2016).
[28] K. Simonyan and A. Zisserman. 2014. Very Deep Convolutional Networks for Large-Scale Image Recognition. CoRR abs/1409.1556 (2014).
[29] Wai-Shun Tong, Chi-Keung Tang, Michael S Brown, and Ying-Qing Xu. 2007. Example-based cosmetic transfer. In Computer Graphics and Applications, 2007.PG’07. 15th Pacific Conference on. IEEE, 211–218.
[30] Dmitry Ulyanov, Andrea Vedaldi, and Victor S. Lempitsky. 2016. Instance Normalization: The Missing Ingredient for Fast Stylization. CoRR abs/1607.08022(2016). arXiv:1607.08022 http://arxiv.org/abs/1607.08022
[31] Shuyang Wang and Yun Fu. 2016. Face Behind Makeup. In the Association for the Advance of Artificial Intelligence. 58–64.
[32] Zhen Wei, Yao Sun, Jinqiao Wang, Hanjiang Lai, and Si Liu. 2017. Learning Adaptive Receptive Fields for Deep Image Parsing Network. In IEEE Conference on Computer Vision and Pattern Recognition. 2434–2442.
[33] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. 2017. Pyramid scene parsing network. In IEEE Conference on Computer Vision and Pattern Recognition. 2881–2890.
[34] Jun-Yan Zhu, Philipp Krähenbühl, Eli Shechtman, and Alexei A Efros. 2016. Generative visual manipulation on the natural image manifold. In European Conference on Computer Vision. Springer, 597–613.
[35] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint arXiv:1703.10593 (2017).


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









