







linux的文件I/O操作
1. Linux 的文件 I/O 系统,
如下图所示:
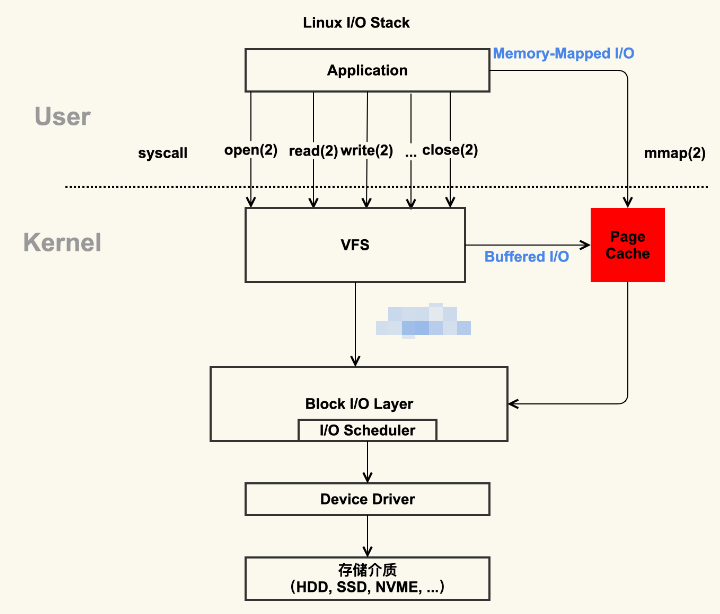
VFS中会包含具体的文件系统。
Page Cache
本质是由 Linux 内核管理的内存区域。我们通过 mmap 以及 buffered I/O 将文件读取到内存空间实际上都是读取到 Page Cache 中。
page cache的优劣势:
优:
- 加快数据访问,因为在内存中进行缓存,那么下一次访问不需要通过磁盘I/O,直接命中缓存命中即可。
- 减少 I/O 次数,提高系统磁盘 I/O 吞吐量,由于 Page Cache 的缓存以及预读能力(会读取当前页以及后续3个页的数据,即16kb(假如一个page=4kb)),而程序又往往符合局部性原理,因此通过一次 I/O 将多个 page 装入 Page Cache 能够减少磁盘 I/O 次数, 进而提高系统磁盘 I/O 吞吐量。
劣:
- 需要占用额外物理内存空间,物理内存在比较紧张的时候可能会导致频繁的 swap 操作,最终导致系统的磁盘 I/O 负载的上升。
- 另一个缺陷是对应用层并没有提供很好的管理 API,几乎是透明管理。应用层即使想优化 Page Cache 的使用策略也很难进行。
VFS和具体文件系统
虚拟文件系统(VFS)是一种抽象层,它为不同类型的具体文件系统提供了一个统一的接口。它的作用是屏蔽不同的文件系统,为上层提供一套标准的文件访问接口。这样,应用程序就可以使用相同的接口来访问不同类型的文件系统,而无需关心底层文件系统的具体实现细节。
具体文件系统则是指实现了VFS接口的各种文件系统,如ext3、ext4等。它们负责实现VFS定义的接口,以便应用程序能够通过VFS来访问底层存储设备上的数据。
文件系统层可以通过submit_bio函数将I/O请求提交给通用块层。
submit_bio函数是Linux内核中的一个函数,它用于将块I/O请求(bio)提交给通用块层进行处理。文件系统层可以通过调用submit_bio函数将I/O请求发送给通用块层,通用块层会对这些I/O请求进行合并、排序、调度等操作,然后将它们发送给设备驱动层进行处理。
submit_bio函数的原型如下:
void submit_bio(int rw, struct bio *bio);
其中,rw参数指定了I/O操作的类型(读或写),bio参数指向一个bio结构,该结构描述了要执行的I/O操作的详细信息。
bio结构是Linux内核中用于表示块I/O操作的一种数据结构。它包含了描述I/O操作的所有信息,如操作类型(读或写)、操作位置(磁盘上的扇区号)、操作大小(扇区数)以及要读写的数据缓冲区等。
bio结构的部分定义如下(摘自Linux内核源代码):
struct bio {
sector_t bi_sector; /* 起始扇区号 */
struct bio *bi_next; /* 链表指针 */
struct block_device *bi_bdev; /* 块设备指针 */
unsigned long bi_flags; /* 标志位 */
unsigned long bi_rw; /* 操作类型 */
...
};
文件系统层可以通过调用submit_bio函数将一个bio结构提交给通用块层进行处理。通用块层会根据bio结构中的信息对I/O请求进行调度,并将其发送给设备驱动层进行处理。
通用块层
Linux通用块层(Block Layer)位于文件系统层和设备驱动层之间,它的主要作用是屏蔽底层异构设备,向上提供统一的块设备访问接口。通用块层还负责优化调度I/O请求,以提高系统的I/O性能。
通用块层包括块设备I/O队列和I/O调度器两部分。当文件系统层通过调用submit_bio函数将一个I/O请求提交给通用块层时,通用块层会根据该请求所属的设备,将其加入到相应的块设备I/O队列中。然后,I/O调度器会根据一定的策略从队列中选择一个或多个请求发送给设备驱动层进行处理。
通用块层通过对I/O请求进行合并、排序、调度等操作,可以有效地提高系统的I/O性能。例如,它可以将多个相邻的读请求合并为一个大的读请求,从而减少磁盘寻道次数,提高磁盘访问速度。
通用块层与设备驱动层之间:通用块层可以通过request_queue结构将I/O请求发送给设备驱动层。
request_queue结构是Linux内核中用于表示块设备请求队列的一种数据结构。它包含了描述请求队列的所有信息,如队列的长度、队列中的请求、I/O调度器等。
request_queue结构的部分定义如下(摘自Linux内核源代码):
struct request_queue {
struct list_head queue_head; /* 请求链表 */
struct elevator_queue *elevator; /* I/O调度器 */
...
};
通用块层会为每个块设备创建一个request_queue结构,用于管理该设备上的I/O请求。当文件系统层通过调用submit_bio函数将一个I/O请求提交给通用块层时,通用块层会根据该请求所属的设备,将其加入到相应的request_queue中。然后,I/O调度器会根据一定的策略从队列中选择一个或多个请求发送给设备驱动层进行处理。
设备驱动
驱动程序负责将来自上层的I/O请求转换为硬件设备能够理解的命令,并将硬件设备返回的数据传递回上层。
设备驱动层通常会使用request结构来表示一个I/O请求。
request结构是Linux内核中用于表示块设备I/O请求的一种数据结构。它包含了描述I/O请求的所有信息,如操作类型(读或写)、操作位置(磁盘上的扇区号)、操作大小(扇区数)以及要读写的数据缓冲区等。
request结构的定义如下(摘自Linux内核源代码):
struct request {
struct list_head queuelist; /* 链表指针 */
unsigned int cmd_flags; /* 命令标志 */
sector_t sector; /* 起始扇区号 */
...
};
当通用块层通过调用设备驱动层提供的接口函数将一个I/O请求发送给设备驱动层时,设备驱动层会根据该请求的信息创建一个request结构,并将其加入到设备驱动层维护的请求队列中。然后,设备驱动层会根据一定的策略从队列中选择一个或多个请求发送给硬件设备进行处理。
各层之间的联系参考:块设备的数据结构与相关操作及I/O调度器
小总结
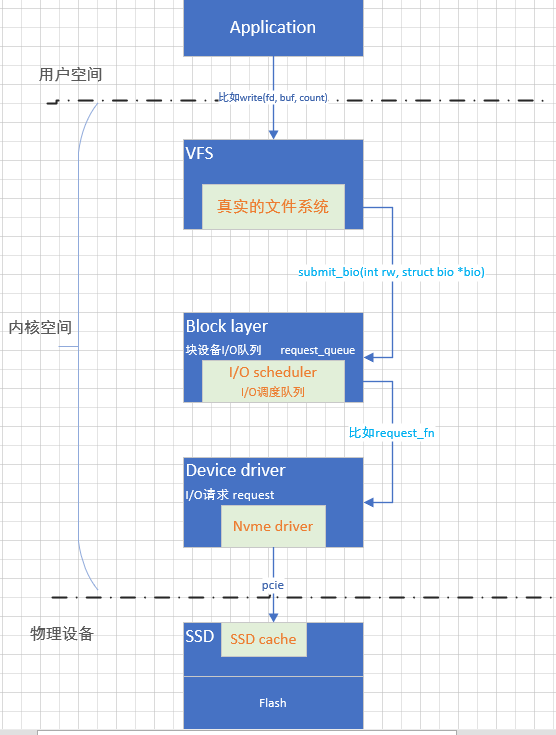
当一个应用程序在用户空间执行读写操作时,它会经过Linux I/O栈中的多个层次,最终到达底层的SSD硬件设备。下面是一个简单的例子,展示了一个读操作从用户空间到SSD之间的层层调用过程:
-
应用程序调用
read系统调用,请求从文件中读取数据。 -
系统调用会进入内核空间,并被虚拟文件系统(VFS)层处理。VFS会根据文件的路径和文件系统类型,将请求转发给相应的具体文件系统。
-
具体文件系统会根据文件的元数据(如inode),计算出要读取的数据块在磁盘上的位置。然后,它会创建一个
bio结构来描述这个读操作,并通过调用submit_bio函数将其提交给通用块层。 -
通用块层会根据
bio结构中的信息,将这个读请求加入到相应的块设备I/O队列中。然后,I/O调度器会根据一定的策略从队列中选择一个或多个请求发送给设备驱动层进行处理。 -
设备驱动层会根据请求的信息,创建一个或多个
request结构,并将它们加入到设备驱动层维护的请求队列中。然后,设备驱动层会根据一定的策略从队列中选择一个或多个请求发送给硬件设备进行处理。 -
硬件设备(SSD)会执行实际的读操作,将数据从磁盘读取到内存缓冲区中。然后,它会通过中断或轮询机制通知设备驱动层读操作已完成。
-
设备驱动层会处理硬件设备返回的结果,并将数据从内存缓冲区复制到应用程序指定的缓冲区中。然后,它会通过调用内核中的相关函数通知上层读操作已完成。
-
最终,应用程序会收到
read系统调用的返回结果,并得到所需的数据。
这只是一个简单的例子,实际上Linux I/O栈中还有很多其他细节和优化措施,这里就不做分析了。
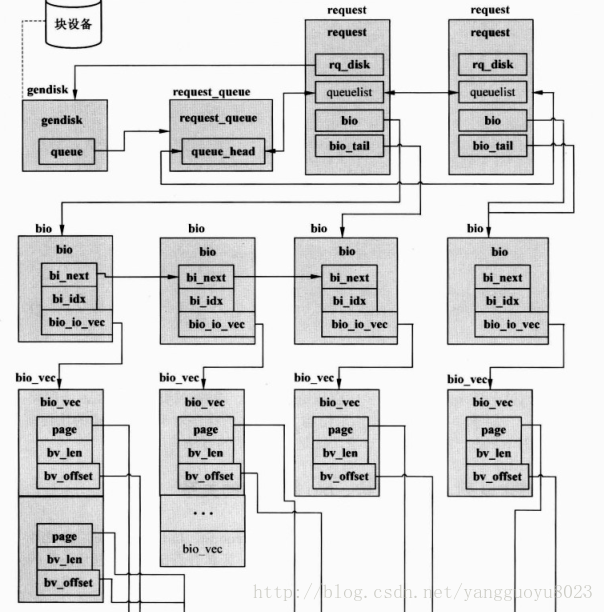
请求队列(request_queue)、请求结构(request)、bio等之间的关系:
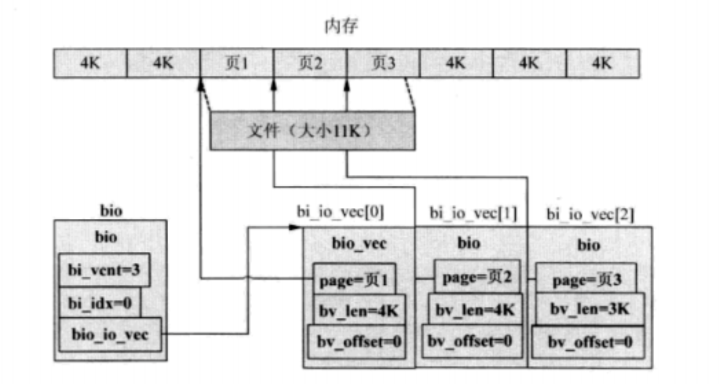
bio与bio_io_vec之间的关系:
2. Linux 存储系统的 I/O 栈
由上到下分为三个层次,分别是文件系统层、通用块层和设备层。
文件系统层:VFS和具体的文件系统
通用块层:block layer
设备层:物理存储设备和对应的设备驱动程序
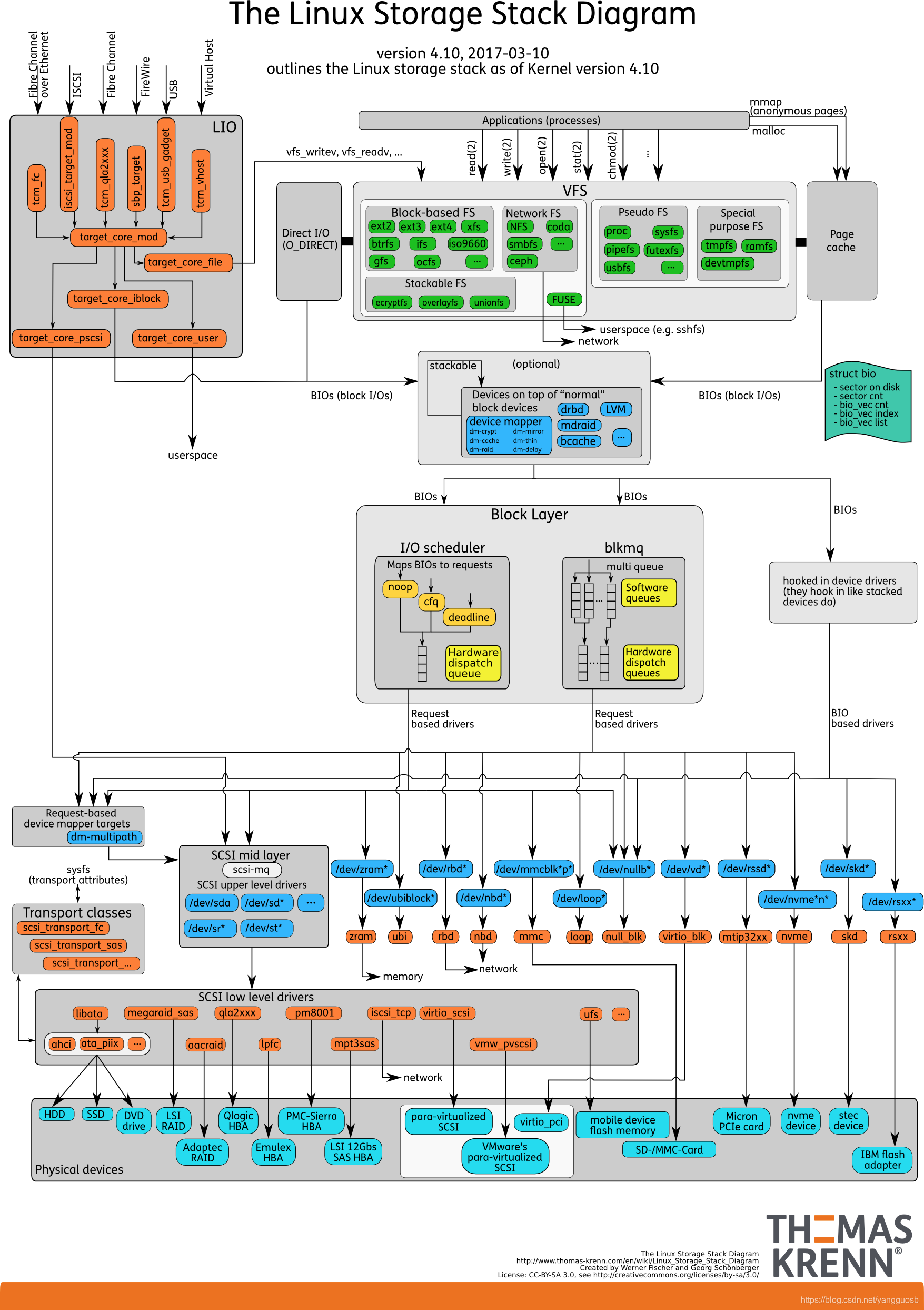
存储系统的 I/O ,通常是整个系统中最慢的一环。为了加快访问,Linux 通过多种缓存机制来优化 I/O 效率。
用户态缓存:包括用户数据缓存和标准库缓存,目的是减少系统调用次数;
内核态缓存:文件系统缓存(Page Cache、索引节点缓存、目录项缓存等),块设备缓存(Buffer Cache);
设备缓存:硬件设备内自带的缓存区。
原文链接:https://blog.csdn.net/yangguosb/article/details/103333628
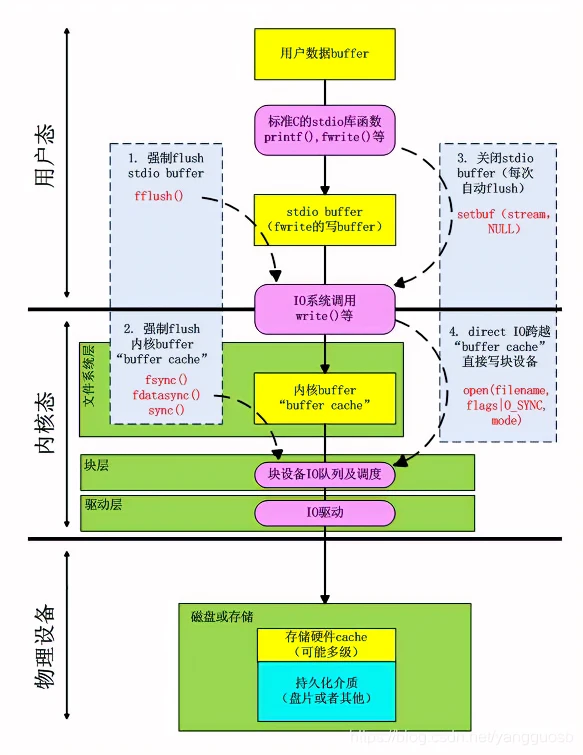
3. 一些系统调用:
系统调用描述:参考博客
- fsync(fd):将 fd 代表的文件的脏数据和脏元数据全部刷新至磁盘中。
- fdatasync(fd):将 fd 代表的文件的脏数据刷新至磁盘,同时对必要的元数据刷新至磁盘中,这里所说的必要的概念是指:对接下来访问文件有关键作用的信息,如文件大小,而文件修改时间等不属于必要信息。
- sync():则是对系统中所有的脏的文件数据元数据刷新至磁盘中。
- mmap: 在持久化中经常被提及的mmap的数据其实也只是在Application Cache和内核Page Cache中建立了映射关系。这样所有在应用层对数据的操作实际是映射到内核的Page Cache中的。因此使用mmap我们不用调用flush,也不用担心数据会因为应用崩溃而丢失。mmap除了能够直接在应用层操作内核中的数据,同时也因此减少了不必要的上下文切换。比如普通写入中,我们调用flush是需要相应的上下文切换呢,这里会有一定的开销。
关于各系统调用在linux的文件I/O系统下的关系:
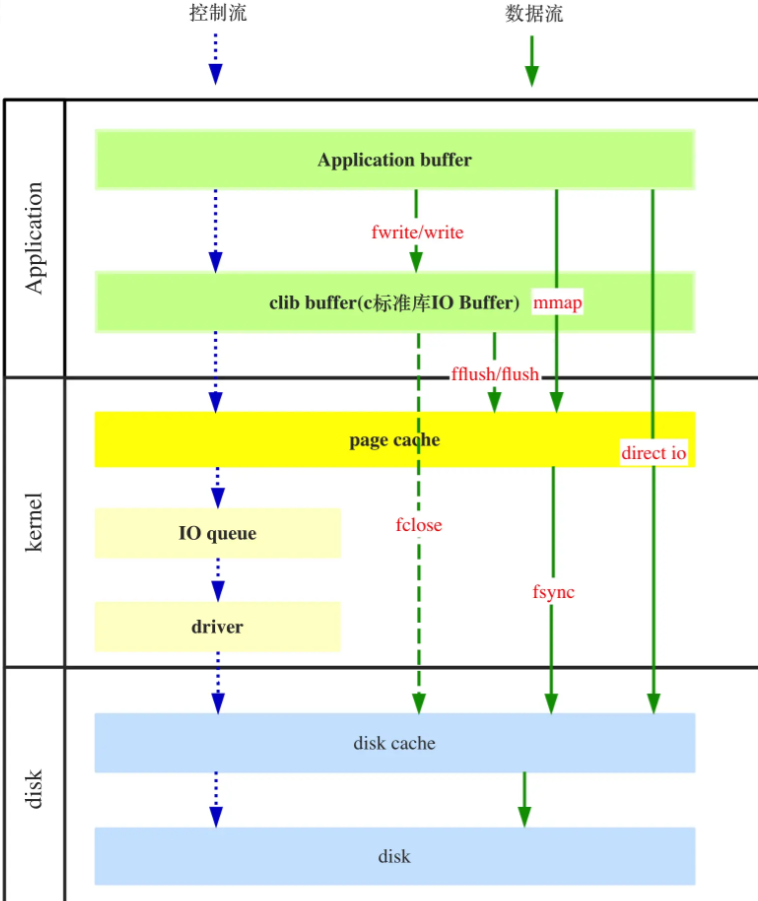
4. direct I/O
Direct I/O 即直接 I/O。其名字中的”直接”二字用于区分使用 page cache 机制的缓存 I/O。模式如下图:
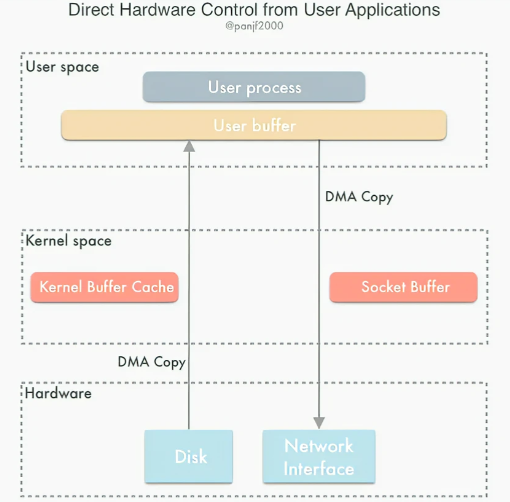
直接IO就是在应用层Buffer和磁盘之间直接建立通道。这样在读写数据的时候就能够减少上下文切换次数,同时也能够减少数据拷贝次数,从而提高效率。
直接IO的使用很简单,只需要在open文件的时候添加O_DIRECT标识即可。
但使用时需要特别注意数据块对齐。数据的读写需要是设备的块大小和linux系统的页大小的整数倍。所以通常我们都以4K大小的块读写数据。open的参数与数据块对齐
- Write 操作:由于其不使用 page cache,所以其进行写文件,如果返回成功,数据就真的落盘了(不考虑磁盘自带的缓存);
- Read 操作:由于其不使用 page cache,每次读操作是真的从磁盘中读取,不会从文件系统的缓存中读取。
关于直接I/O的一些其他补充:https://juejin.cn/post/7002034457007882277
直接I/O的缺点:
a、系统基本不缓存数据,因此应用需要合理的读写数据,否则会导致性能很差。
b、所有缓存都由应用层直接控制,增加了应用层的实现复杂度,对开发者能力要求很高。
直接I/O的使用注意:
只有在确定了设置缓冲 I/O(即普通I/O) 的开销非常巨大的情况下,才考虑使用直接 I/O。比如要传输的数据量很大时,若使用page cache,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销。
直接 I/O 应用场景常见的两种:
- 应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启直接 I/O,默认是不开启;
- 传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用直接 I/O。















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









