







1 主要参考博客以及说明:
https://blog.csdn.net/weixin_42782150/article/details/89546357
-
本文更像对参考博客的个人解读,以及一些个人补充完善,有些地方与作者表达可能并非一致望自行验证。
-
函数的某些参数可能随着版本更新已经不再使用,所以本文仅供参考
2 函数参数以及参数含义
concat
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
-
objs:series,dataframe等要拼接的对象
-
axis:指明连接的轴向, 0:index行, 1:columns列,默认为0即行连接
-
join:指明连接方式 ,inner交集,outer并集,默认为outer并集
-
join_axes:自定义的索引。作为join中交集与并集的补充
-
ignore_index=True:重建索引
merge
DataFrame.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
-
left和right:要拼接的series或者DF,同concat中objs类似,只是concat中多个DF拼接需要写到列表中且可以多个DF拼接,merge只能是俩DF
-
how:连接方式,有inner、left、right、outer,默认为inner
-
on:用于连接的列索引名称,必须同时存在于左、右两个DataFrame中,默认是以两个DataFrame列名的交集作为连接键,若要实现多键连接,‘on’参数后传入多键列表即可
-
left_on:左侧DataFrame中用于连接键的列名,这个参数在左右列名不同但代表的含义相同时非常有用;
-
right_on:右侧DataFrame中用于连接键的列名
-
left_index:使用左侧DataFrame中的行索引作为连接键( 但是这种情况下最好用JOIN)
-
right_index:使用右侧DataFrame中的行索引作为连接键( 但是这种情况下最好用JOIN)
-
sort:默认为False,将合并的数据进行排序,设置为False可以提高性能
-
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’, ‘_y’)
-
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能
-
indicator:显示合并数据中数据的来源情况
join
DataFrame.join(other, on=None, how='left', lsuffix=' ', rsuffix=' ', sort=False)
- join参数与merge基本一致,常用参数见上方merge方法的参数解释即可。
append
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
-
other就是要拼接的对象
-
verify_integrity:如果为T,那么创建重复索引会报错
-
默认的链接方式同join也是左外连接。
方法实例
concat(类比关系型数据库表之间的拼接更像mysql中的union和join函数的结合体)
-
1 默认行拼接
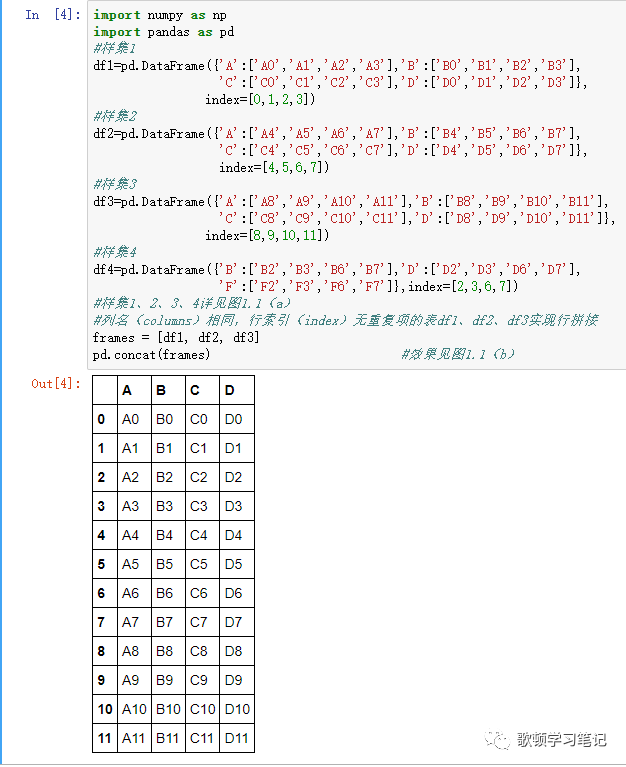
-
2 进行列拼接

-
3 可以用key参数来显示拼接后数据所属的DF

-
4 当两个DF使用concat默认拼接方式(即行拼接时候)与append的效果是一致的
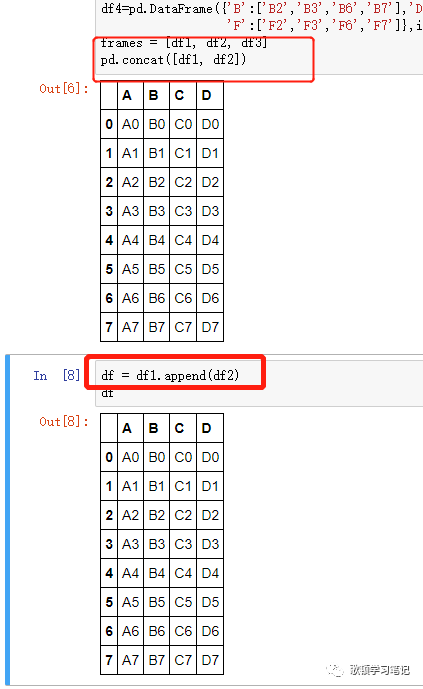
-
5 concat设置拼接方式为inner取交集的时候,如果是行拼接就会留下共有的列,同理列拼接会留下相同的行
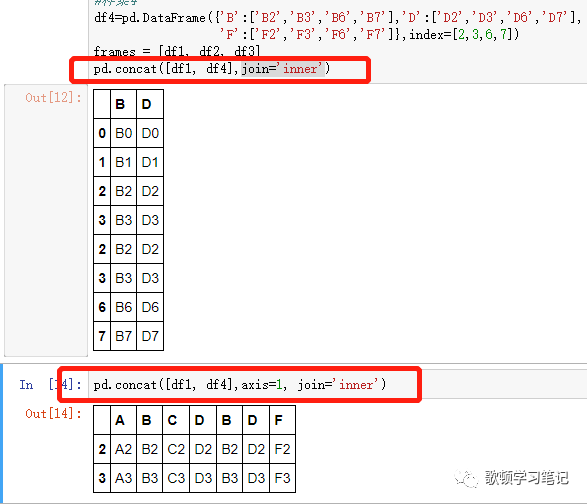
merge
- merge拼接常用于两个表有相同的列,且该列的数据相同,类似于数据库表中的两张表主键相同,默认情况下结果条件下:如图,BD列同名,行数据中重复的只有df1中的索引2和索引3,那么结果就会重新生成索引且其他不重复的列取的索引为左表对应的索引值,右表同样取得是对应索引位置上的值,也就是会默认以左边的索引位置取值。

-
如果想保留两个表的所有数据,就要用到参数left_index与right_index,how参数作用即为设置左右两个表用哪个表的索引当新生成表的索引


-
参考博客中说:当axis=1时,
pd.concat([obj1, obj2], axis=1)与pd.merge(obj1, obj2, left_index=True, right_index=True, how='outer')的效果是相同的。这里测试应该是有些特殊情况下结果相同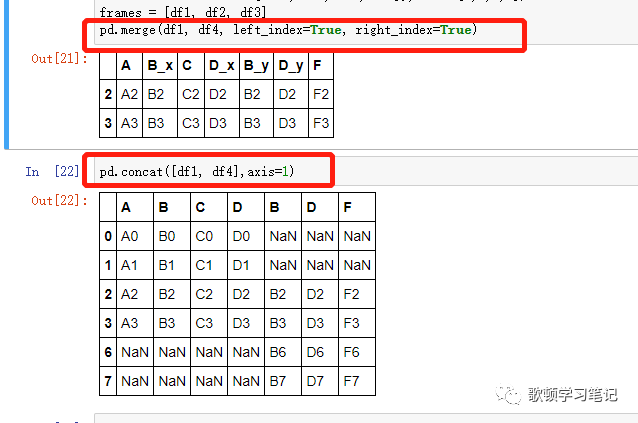
caoncat个人认为如果需要多个表同时操作使用比较方便,功能比较齐全;merge在两个表有”共键“的情况下使用更方便,从参数on也可以看出使用偏向,也更类似数据库中的表之间join,更多奇技淫巧待发掘
join
-
个人看来join与merge更加类似,参数中join的lsuffix与rsuffix和suffixes是一致的,一些情况下join更像merge的一个阉割版,可能偏向用参考文章中的一句话是:JOIN 拼接列,主要用于基于行索引上的合并,行的拼接目前本人还未遇到合适场景
-
在两个DF有重复的列名以及不重复的数据情况下,做一个对比
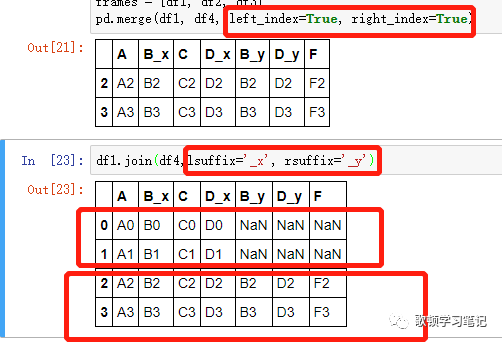
-
关于join中使用sex_index参数实现的效果直接用参考资料中的代码来展现(偷懒不自己运行了,参考文章中join的用法介绍的比较详细)
#样集1
left=pd.DataFrame({'key':['foo','bar1'],'lval':[1,2]})
>>>
key lval
0 foo 1
1 bar1 2
#样集2
right=pd.DataFrame({'key':['foo','bar'],'rval':[4,5]})
>>>
key rval
0 foo 4
1 bar 5
#列名和列内容均部分相同的表df1和df2进行基于列索引,列拼接
left.join(right.set_index('key'),on='key')
>>>
key lval rval
0 foo 1 4.0
1 bar1 2 NaN
#样集3
left=pd.DataFrame({'key':['foo','bar1'],'val':[1,2]})
>>>
key val
0 foo 1
1 bar1 2
#样集4
right=pd.DataFrame({'key':['foo','bar'],'val':[4,5]})
>>>
key val
0 foo 4
1 bar 5
#列名相同,列内容部分相同的表df1和df2基于列索引进行列合并,必须用参数lsuffix='_l',rsuffix='_r'指定重名列的下标,否则报错
left.join(right.set_index('key'),on='key',lsuffix='_l',rsuffix='_r')
>>>
key val_l val_r
0 foo 1 4.0
1 bar1 2 NaN
#特别注意,即使列名相同了,也必须用到' set_index(key)' 否则直接使用
left.join(right,on='key',lsuffix='_l',rsuffix='_r')
>>> ValueError: You are trying to merge on object and int64 columns. If you wish to proceed you should use pd.concat
#另外需明确,不指定'ON= '参数的情况下,JOIN是按行索引进行列拼接,不对列进行任何操作。
left.join(right,lsuffix='_l',rsuffix='_r')
>>>
key_l val_l key_r val_r
0 foo 1 foo 4
1 bar1 2 bar 5
从上面结果看来,在两个DF有重叠部分的时候,个人认为merge更偏向两个表的列之间的融合,而join更偏重于行之间的融合,合并分成了1 单纯的拼接类似于并集的谁也不干涉谁,2 有交集的拼接
append
-
个人认为append就是concat的阉割版(甚至比join是merge的阉割版更符合阉割的感觉),在介绍concat的时候也有append的例子,唯一需要注意的就是在对series进行拼接的时候,记得要将ignore_index=Ture,原因见下方
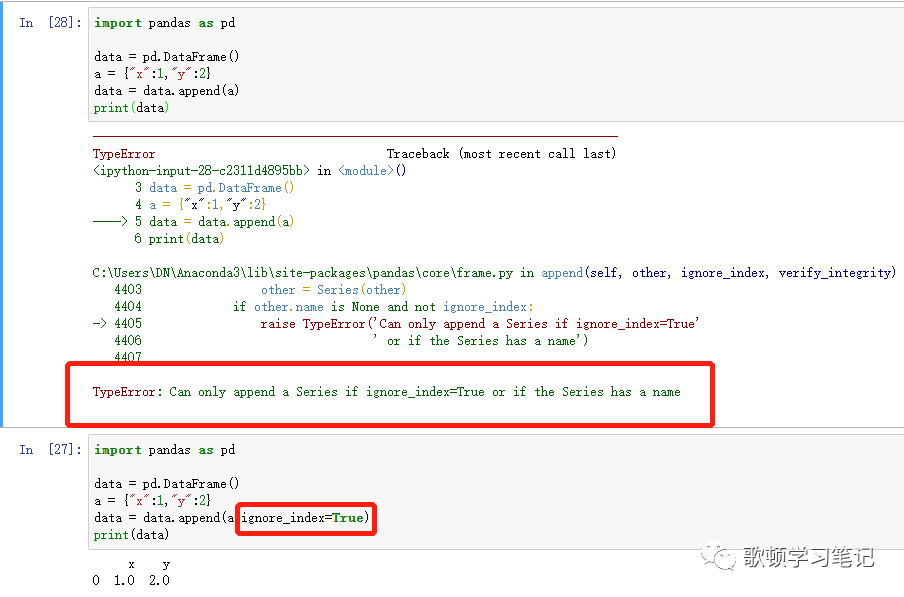
-
如何添加name呢?
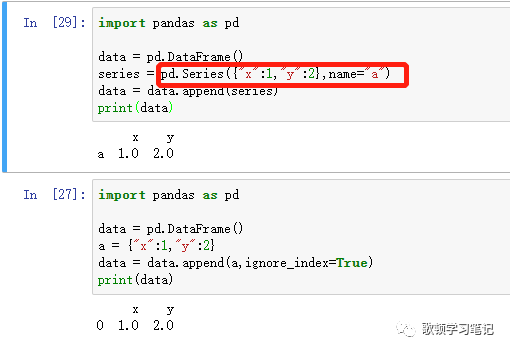
其他参考资料
append:pandas的DataFrame的append方法详细介绍_修炼之路-CSDN博客_dataframe.append()
join:Pandas中的join()合并数据方法_KJ.JK的博客-CSDN博客_pandas的join
merge:[Python3]pandas.merge用法详解_Asher117的博客-CSDN博客_pandas.merge
concat:[Python3]pandas.concat用法详解_Asher117的博客-CSDN博客_pandas.concat
如果有错误的地方欢迎指正~
















 2068
2068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











