






前言:
本篇文章以【教学赛】金融数据分析赛题1:银行客户认购产品预测_学习赛_天池大赛-阿里云天池的排行榜 (aliyun.com)![]() https://tianchi.aliyun.com/competition/entrance/531993/information为数据及来源,有需要可以自行注册账号下载。
https://tianchi.aliyun.com/competition/entrance/531993/information为数据及来源,有需要可以自行注册账号下载。
电脑系统windows11、基于python11.9的虚拟环境、Visual Studio Code编辑器、编辑文件后缀.jpynb。
一、数据预处理
1.1 读取、查看数据
对与数据查看其数据信息尤为重要,而本次数据集的数据治理水平较高,未发现数据不一致、数据重复、异常值等问题,所以就不做展示。在观察我们本次的数据集上出现数据有文本类型数据、非连续型数据、连续型数据,所以我们对于这几类类型数据进行预处理。
以下(图1)为训练集部分数据展示:
 图1
图1
1.2 编码
在图一中观察数据得知数据当中有文本类型数据,本文中将用OrdinalEncoder 预处理工具,用于将文本类型数据转换为数值型数据,否则我们在训练数据时会报错。提取为文本数据的列进行编码,然后再将处理好的数据将原本为文本的数据替换。
以下为参考代码,图2为编码后的数据:
from sklearn import preprocessing
# 数据编码
#选取特征列
x1 = df1[['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome','subscribe']].values
encoder=preprocessing.OrdinalEncoder()
encoder.fit(x1)
x1=encoder.transform(x1)
#替换原本的特征列
df1[['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome','subscribe']]=x1
 图2
图2
1.3归一化、标准化
本文中不说明归一华、标准化的适用范围只说明怎样用(如想了解可自行查阅)。做数据的归一华和标准化能够使我们的模型更快的收敛和预测,尤其在分类模型追求准确率的时候,需要根据我们的数据进行调整参数优化我们的模型。如不做归一化或标准化,模型调优时运行的时长可能会以小时为单位。
以下为归一化的参考代码,图3为数据归一化处理后的数据:
# 归一化 X 数据
def normalize_data(data):
# 计算数据的最小值和最大值
data_min = np.min(data, axis=0)
data_max = np.max(data, axis=0)
# 归一化数据到 [0, 1] 区间
normalized_data = (data - data_min) / (data_max - data_min)
return normalized_data, data_min, data_max
normalized_X, X_mean, X_std = standardize_data(df1) #调用函数将df1进行归一化处理
df11=normalized_X #将归一化后的数据赋值给df11
 图3
图3
以下为标准化的参考代码,图4为数据标准化处理后的数据:
# 标准化
def standardize_data(data):
# 计算数据的均值和标准差
data_mean = np.mean(data, axis=0)
data_std = np.std(data, axis=0)
# 标准化数据
standardized_data = (data - data_mean) / data_std # 使用均值和标准差进行标准化处理
return standardized_data, data_mean, data_std # 返回标准化后的数据, 均值和标准差
normalized_X, X_mean, X_std = standardize_data(df1) #调用函数将df1进行标准化处理
df12=normalized_X #将标准化后的数据赋值给df12
 图4
图4
二、数据划分
2.1特征选取
在选取特征的时候有些特征可能与目标值相关性并不是很强从而会影响模型的预测,所以在我们选取特征时,我们可以把相关性不太大的特征剔除。那么对于相关性可以选用皮尔逊等分析相关性的包进行分析(有需要的可以自行行查阅,这里不做过多赘述)。
天池的数据基本没什么问题,不用过多处理。直接选取特征,切割数据进行模型训练。
from sklearn.model_selection import train_test_split
X, y = df11.drop(['subscribe', 'id'], axis=1),df11['subscribe'] #选取特征x和目标y,x为除subscribe和id之外的其他特征,y为subscribe
#划分训练集和测试集,test_size=0.3表示测试集占30%,random_state=42表示随机种子。(train为训练集,test为测试集)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) 三、模型搭建
对于模型搭建有实在不懂选哪个模型的小白可以一股脑的把基分类器全部导入进行训练预测,然后再根据混淆矩阵进行选择。
3.1导包
导入相关的库是必不可少的,在环境初始是没有导包的,需要执行导包。以下为导包及几个模型参考代码:
#可根据环境自行导包,如不需要请勿运行
! pip install sklearn #在pythong环境中安装sklearn库
! conda install -c conda-forge scikit-learn #在anaconda环境中安装sklearn库# 导入相关库
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.svm import SVC #支持向量机
from sklearn.neighbors import KNeighborsClassifier# K近邻
from sklearn.tree import DecisionTreeClassifier# 决策树
from sklearn.ensemble import RandomForestClassifier#随机森林
from sklearn.naive_bayes import GaussianNB#朴素贝叶斯
from sklearn.metrics import accuracy_score #准确率3.2创建实例
在导入库后就可以搭建模型了,此处为默认参数需要调优的可以自行调整参数,以下为参考代码:
# 创建实例(未写参数表明默认参数)
lr = LogisticRegression()
svc = SVC()
knn = KNeighborsClassifier()
dt = DecisionTreeClassifier()
rf = RandomForestClassifier()
gnb = GaussianNB()3.3训练模型
模型搭建好后利用我们训练集的数据(X_train, y_train)训练模型,以下为参考代码:
# 训练模型(利用训练集,训练模型)
lr.fit(X_train, y_train)
svc.fit(X_train, y_train)
knn.fit(X_train, y_train)
dt.fit(X_train, y_train)
rf.fit(X_train, y_train)
gnb.fit(X_train, y_train)3.4测试模型
训练出来的模型分别为lr, svc, knn, dt, rf, gnb,训练好后再以测试集的数据进行预测分析其模型性能,在分类模型预测中,现在的模型预测值以目标值输出(predict),而预测值不仅仅可以以预测值输出还可以以概率值(predict_proba)输出等。以下为目标值(predict)输出参考代码:
# 预测模型(利用测试集特征,预测结果)
y_pred_lr = lr.predict(X_test)
y_pred_svc = svc.predict(X_test)
y_pred_knn = knn.predict(X_test)
y_pred_dt = dt.predict(X_test)
y_pred_rf = rf.predict(X_test)
y_pred_gnb = gnb.predict(X_test)根据预测值与真实值我们可以得出准确率评估那个模型较好,以下为参考代码,图5为各模型准确率:
# 计算准确率(利用测试集真实值和预测值,计算准确率)
acc_lr = accuracy_score(y_test, y_pred_lr)
acc_svc = accuracy_score(y_test, y_pred_svc)
acc_knn = accuracy_score(y_test, y_pred_knn)
acc_dt = accuracy_score(y_test, y_pred_dt)
acc_rf = accuracy_score(y_test, y_pred_rf)
acc_gnb = accuracy_score(y_test, y_pred_gnb)
# 打印准确率
print("LogisticRegression Accuracy:", acc_lr)
print("SVC Accuracy:", acc_svc)
print("KNeighborsClassifier Accuracy:", acc_knn)
print("DecisionTreeClassifier Accuracy:", acc_dt)
print("RandomForestClassifier Accuracy:", acc_rf)
print("GaussianNB Accuracy:", acc_gnb)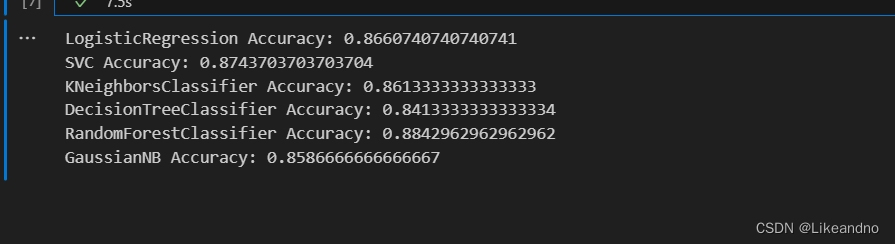
图5
四、完整代码
import pandas as pd
import numpy as np
df1 = pd.read_csv('train.csv')#读取训练集数据
print(df1.head())#查看前五行数据
print(df1.info())#查看数据集信息
from sklearn import preprocessing
# 数据编码
#选取特征列
x1 = df1[['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome','subscribe']].values
encoder=preprocessing.OrdinalEncoder()
encoder.fit(x1)
x1=encoder.transform(x1)
#替换原本的特征列
df1[['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome','subscribe']]=x1
df1.head()
# 归一化 X 数据
def normalize_data(data):
# 计算数据的最小值和最大值
data_min = np.min(data, axis=0)
data_max = np.max(data, axis=0)
# 归一化数据到 [0, 1] 区间
normalized_data = (data - data_min) / (data_max - data_min)
return normalized_data, data_min, data_max
normalized_X, X_min, X_max = normalize_data(df1)
df11=normalized_X
from sklearn.model_selection import train_test_split
X, y = df11.drop(['subscribe', 'id'], axis=1),df11['subscribe'] #选取特征x和目标y,x为除subscribe和id之外的其他特征,y为subscribe
#划分训练集和测试集,test_size=0.3表示测试集占30%,random_state=42表示随机种子。(train为训练集,test为测试集)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# %%
# 导入相关库
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.svm import SVC #支持向量机
from sklearn.neighbors import KNeighborsClassifier# K近邻
from sklearn.tree import DecisionTreeClassifier# 决策树
from sklearn.ensemble import RandomForestClassifier#随机森林
from sklearn.naive_bayes import GaussianNB#朴素贝叶斯
from sklearn.metrics import accuracy_score #准确率
# 创建实例(未写参数表明默认参数)
lr = LogisticRegression()
svc = SVC()
knn = KNeighborsClassifier()
dt = DecisionTreeClassifier()
rf = RandomForestClassifier()
gnb = GaussianNB()
# 训练模型(利用训练集,训练模型)
lr.fit(X_train, y_train)
svc.fit(X_train, y_train)
knn.fit(X_train, y_train)
dt.fit(X_train, y_train)
rf.fit(X_train, y_train)
gnb.fit(X_train, y_train)
# 预测模型(利用测试集特征,预测结果)
y_pred_lr = lr.predict(X_test)
y_pred_svc = svc.predict(X_test)
y_pred_knn = knn.predict(X_test)
y_pred_dt = dt.predict(X_test)
y_pred_rf = rf.predict(X_test)
y_pred_gnb = gnb.predict(X_test)
# 计算准确率(利用测试集真实值和预测值,计算准确率)
acc_lr = accuracy_score(y_test, y_pred_lr)
acc_svc = accuracy_score(y_test, y_pred_svc)
acc_knn = accuracy_score(y_test, y_pred_knn)
acc_dt = accuracy_score(y_test, y_pred_dt)
acc_rf = accuracy_score(y_test, y_pred_rf)
acc_gnb = accuracy_score(y_test, y_pred_gnb)
# 打印准确率
print("LogisticRegression Accuracy:", acc_lr)
print("SVC Accuracy:", acc_svc)
print("KNeighborsClassifier Accuracy:", acc_knn)
print("DecisionTreeClassifier Accuracy:", acc_dt)
print("RandomForestClassifier Accuracy:", acc_rf)
print("GaussianNB Accuracy:", acc_gnb)















 6680
6680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









