







一、什么是爬虫呢
网络爬虫(又被称为网页支柱,网络机器人)是一种按照一定的规则,自动的抓取万维网信息的程序,可以理解为模拟客户端发送网络请求,接受请求对应的响应。
二、爬虫有哪些分类
根据使用场景,网络爬虫可分为 通用爬虫(General Purpose Web Crawler)和聚焦爬虫(Focused Web Crawler)两种。
通用爬虫是搜索引擎抓取系统的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份,通常指搜索引擎和大型 Web 服务提供商的爬虫。
聚焦爬虫 : 是针对特定网站的爬虫,定向的获取某方面数据的爬虫,可细分为以下:
累积式爬虫(Accumulative web crawler):从开始到结束,不断爬取,过程中会进行去重操作
增量式爬虫 (Incremental Web Crawler): 已 下 载 网 页 采 取 增 量式更新和只爬行新产生的或者已经发生变化网页的爬虫
深层网络爬虫(Deep Web Crawler) : 不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面
三、了解通用搜索引擎(Search Engine)工作原理
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
第一步:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
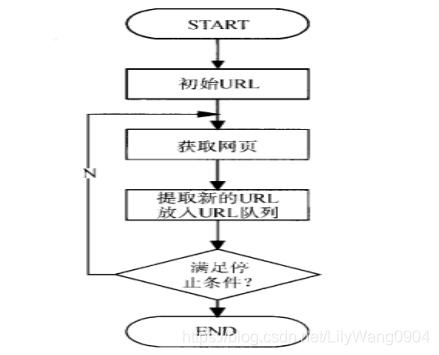
首先选取一部分的种子URL,将这些URL放入待抓取URL队列;
取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环,如图:
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
提取文字——中文分词——消除噪音(比如版权声明文字、导航条、广告等……)——索引处理——链接关系计算——特殊文件处理等。
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2386
2386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









