









这里不对hdfs上传文件的过程进行源码分析,下面只粘出代码。
下面讲hdfs文件上传的过程中内部的工作原理和对应的面试题
一、客户端对hdfs各种操作的代码
建议将代码贴到自己的 eclipse 中查看
package com.Lin_wj1995.bigdata.hdfs;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsClient {
FileSystem fs = null;
/**
* 初始化FileSystem
*/
@Before
public void init() throws Exception {
// 构造一个配置参数对象,设置一个参数:我们要访问的hdfs的URI
// 从而FileSystem.get()方法就知道应该是去构造一个访问hdfs文件系统的客户端,以及hdfs的访问地址
// new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml
// 然后再加载classpath下的hdfs-site.xml
Configuration conf = new Configuration();
//conf.set("fs.defaultFS", "hdfs://hdp-node01:9000");
/**
* 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置
*/
//conf.set("dfs.replication", "3");
// 获取一个hdfs的访问客户端,根据参数,这个实例应该是DistributedFileSystem的实例
// fs = FileSystem.get(conf);
// 如果这样去获取,那conf里面就可以不要配"fs.defaultFS"参数,而且,这个客户端的身份标识已经是hadoop用户
fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop");
}
/**
* 往hdfs上传文件
*/
@Test
public void testAddFileToHdfs() throws Exception {
// 要上传的文件所在的本地路径
Path src = new Path("c:/liuliang.jar");
// 要上传到hdfs的目标路径
Path dst = new Path("/");
fs.copyFromLocalFile(src, dst);
fs.close();
}
/**
* 从hdfs中复制文件到本地文件系统
*/
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException, IOException {
fs.copyToLocalFile(new Path("/jdk-7u65-linux-i586.tar.gz"), new Path("d:/"));
fs.close();
}
/**
* 在hfds中创建目录、删除目录、重命名
*/
@Test
public void testMkdirAndDeleteAndRename() throws IllegalArgumentException, IOException {
// 创建目录
fs.mkdirs(new Path("/a1/b1/c1"));
// 删除文件夹 ,如果是非空文件夹,参数2必须给值true
fs.delete(new Path("/aaa"), true);
// 重命名文件或文件夹
fs.rename(new Path("/a1"), new Path("/a2"));
}
/**
* 查看目录信息,只显示文件
*/
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
// 思考:为什么返回迭代器,而不是List之类的容器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-length:" + bl.getLength() + "--" + "block-offset:" + bl.getOffset());
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("--------------分割线--------------");
}
}
/**
* 查看文件及文件夹信息
*/
@Test
public void testListAll() throws FileNotFoundException, IllegalArgumentException, IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "d-- ";
for (FileStatus fstatus : listStatus) {
if (fstatus.isFile())
flag = "f-- ";
System.out.println(flag + fstatus.getPath().getName());
}
}
}
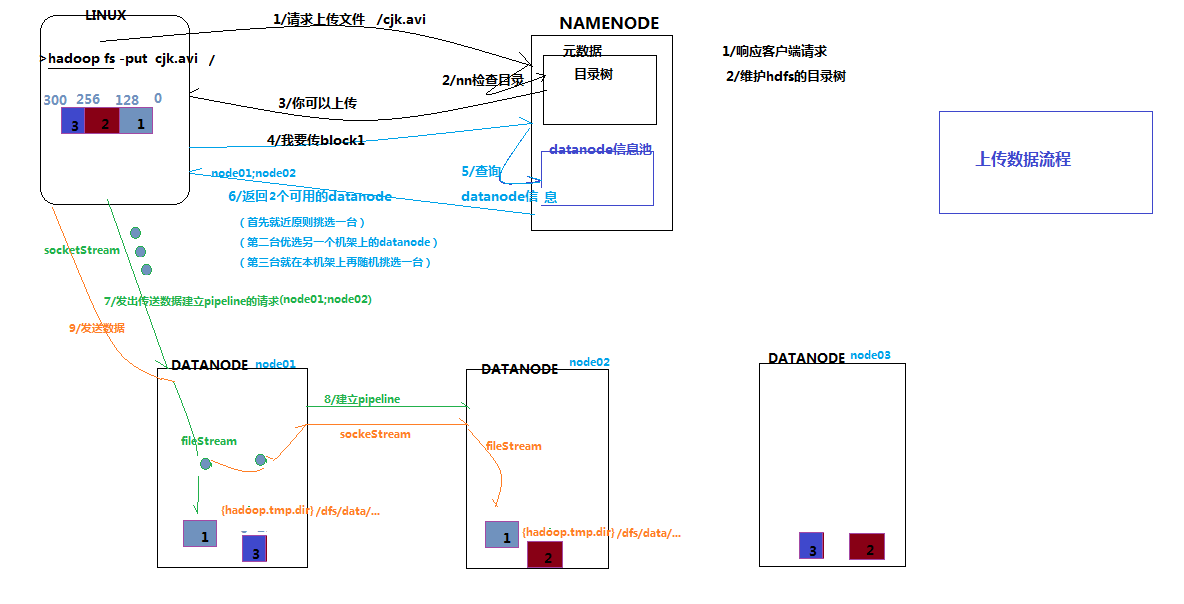
二、文件上传流程的文字解释
- 客户端拿到一个文件,跟namenode说,我要上传这个文件,上传到哪个目录下。我们假设这个文件名为 cjk.avi,目录为 /hadoop/hdfs/
- namenode拿到这个文件后,获取文件名,然后去元数据中查找/hadoop/hdfs/中是否已经存在相同文件名的文件,如果没有,那么告诉客户端说你可以上传这个文件
- 客户端接到可以上传文件的命令后,会将文件进行切分(hadoop2.X是128M),切分成N(N>=1)块
- 客户端拿到第一个块block01后,跟namenode说,我要上传block01,然后namenode去自身的datanode信息池中查找应该上传到哪几个datanode(备份数)中,然后将查询到的datanode的信息告诉客户端
- 客户端拿到datanode的信息后,开辟一个socket流将block01上传到namenode返回的datanode中最近的一个datanode节点,然后这个datanode节点会对block01进行水平备份,也就是将数据从datanode本地复制到其他指定的机器上。
- datanode将数据水平备份完成之后,会通知客户端,说block01上传成功
- 然后客户端会通知namenode说block01上传成功,此时namenode会将元数据(可以简单地理解为记录了block块存放到哪个datanode中)同步到内存中
- 其他的block块循环上面的过程
- 至此一个大文件就上传到hdfs中了
三、图解
四、hdfs上传文件过程常见的面试题
下面是我面试到的关于hdfs上传文件过程的面试题目
描述一下hdfs上传文件的过程
答:将上面的文字解释部分大致讲给面试官听即可如何选择文件上传到哪几个datanode
答:下面我按照默认的备份数(3份)进行讲解
(1)首先就近原则挑选一台
(2)第二台优选另一机架上的datanode
(3)第三台就在本机机架上再随机挑选一台block块是如何备份的
答:我们先将block块上传一个datanode节点,然后由该节点进行水平备份(最主要是水平备份这个词)hadoop默认的块是多大
答:hadoop2.X是128M,hadoop1.X是64Mhdfs中block的备份数是多少
答:默认是3份,可在配置文件中进行配置















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









