







在这里说明一下,整理的面试经历的来源是牛客网,不是我本人的面试经历~
我做这个整理的目的,一是为了自己学习和巩固知识点,再一个是可以让找C++相关工作的朋友,快速过一下知识点。
整理的内容可能出现错误,欢迎指出!
面经来源:
https://www.nowcoder.com/discuss/688074?source_id=discuss_experience_nctrack&channel=-1
(侵删)

自我介绍和项目略。
说一说程序的内存分配
每个程序运行起来以后,它将拥有自己独立的虚拟空间。这个虚拟地址空间的大小与操作系统的位数有关系。C/C++程序在虚拟内存中的排布大概是:
text段; rodata段;data段;bss段;heap段;stack段。

Text段(代码段):存放程序执行代码的一块内存区域。
Rodata段(常量数据量):用于存放常量数据。
Data段:存放程序中已经初始化且非0的全局变量的一块内存区域,如果全局变量初始化为0,则编译有时会出于优化的考虑,将其放在bss段中。
(全局变量,在程序运行的整个生命周期都存在于内存中)
Bss段:用来存放程序中未初始化或初始化为0的全局变量的一块内存。
Heap段(堆区):用于动态分配内存,一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。
Stack段(栈区):由编译器自动分配释放,存放函数的参数值、局部变量等。
说一说堆和栈的区别
1 管理方式不同。栈由操作系统自动分配释放;堆区内存的申请和释放需要程序员控制,容易造成内存泄漏。
(补充:内存泄漏是指由于疏忽或错误造成了程序未能释放掉不再使用的内存的情况,失去了对该段内存的控制,因而造成了资源的浪费)
2 空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。
3 生长方向不同。堆的内存地址由低到高,向上生长;栈的内存地址由高到低,向下生长。
假设内存空间底部是低地址,顶部是高地址。
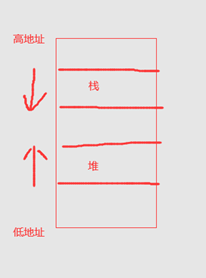
4 分配方式不同。堆是动态分配的,没有静态分配的堆。而栈既可以静态分配也可以动态分配,栈的动态分配由alloca进行分配,但是栈的动态分配与堆不同,它动态分配的内存是由OS释放的,不需要程序员手动释放。
-----------------------------以下补充内容---------------------------
Alloca:它是在栈上开辟的空间,当它作用域结束时会自动释放内存,不用像malloc那样,要用free手动释放内存。
优点:不需要手动释放,避免内存泄漏。
缺点:会导致栈溢出;可移植性差。
动态分配和静态分配:
静态分配发生在程序编译和链接的时候。在程序执行前就分配好内存了。
动态分配则发生在程序调入和执行的时候。在程序执行时分配好内存。
-----------------------------以上补充内容-----------------------------
5 分配效率不同。堆频繁的内存申请容易产生内存碎片,因此,堆的效率比栈低得多。
说一说函数调用用参数是怎么传递的
基本的参数传递机制有两种:值传递和引用传递
值传递:被调函数的形式参数作为被调函数的局部变量处理,即在堆栈中开辟了内存空间以存放由主调函数放进来的实参的值,从而成为了实参的一个副本。值传递的特点是被调函数对形式参数的任何操作都是作为局部变量进行,不会影响主调函数的实参变量的值。
引用传递:被调函数的形式参数虽然也作为局部变量在堆栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,通过堆栈中存放的地址访问主调函数中的实参变量。正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量。
-----------------------以下补充内容----------------------
一般C++用引用传递更多,因为引用传递不需要在堆栈中开辟空间,而值传递需要另外的开辟空间,对内存有一定的浪费。
直接寻址、间接寻址
直接寻址:直接给出内存单元的物理地址或虚拟地址
间接寻址:地址不是像直接寻址那样直接给出,是通过寄存器得到要寻址的地址,然后再去寻址。[段标识符:段内偏移量]
-----------------------以上补充内容----------------------
函数调用的参数是按什么顺序压栈的?为什么?

从右向左压栈(逆变量声明顺序)
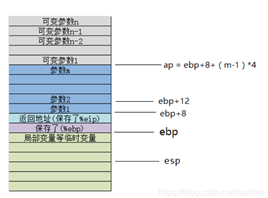
虽然不知道可变参数n的大小,但是依然可以根据固定参数的大小m,找到可变参数的开始位置,然后去访问就可以了。
所以从右向左压栈的好处是,第一个参数就在栈顶,我们很方便就定位到了第一个参数(固定参数和可变参数)的位置。
假如是字左向右(按变量声明顺序)
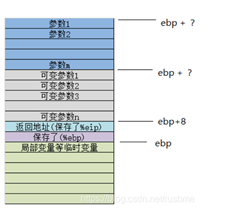
在只知道ebp的情况下,而不知道可变参数n的大小,不能确定可变参数和可变参数的分解,因为可变参数是可以传任意个参数传入的,数量可变,所以就无法确认参数1和参数m的地址,不确定它们的地址就无法访问。
有一个函数
string fun(string s1, string s2)
{
string tmp = s1+s2;
return tmp;
}
主函数里面通过: string s = fun(s1, s2); 调用,依照代码执行顺序分析一下调用了什么构造函数和顺序 以及析构函数的调用顺序。
如果我fun函数内写成 return s1 + s2 有什么区别?


测试结果:
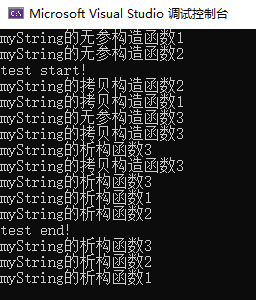
1 从test start的地方开始看,fun(s1,s2)是以值传递的方式传入被调用函数的,而函数调用的参数是按从右向左的顺序压栈的,所以先调用s2的拷贝构造函数,再调用s1的拷贝构造函数。
2 调用myString的+运算符重载,这里的s2用的是引用传递的方式传入函数的,所以不用进行拷贝构造。myString temp(a.i+this->i); 调用了无参构造函数;而+运算符重载函数的返回类型是非引用类型,也就是用值传递的方式返回一个temp,因此要调用拷贝构造函数,用来初始化调用方的结果。函数结束,temp离开作用域,析构掉。
3 在//5的地方,还是用值传递的方式返回myString类型的对象temp,因此要调用拷贝构造函数,用来初始化调用方的结果。函数结束,s2、s1、temp离开作用域,析构掉,析构的顺序是temp、s1、s2。
----------------------------以下是不理解的地方---------------------
疑问:myString temp=fun(s1,s2);这条指令创建了一个myString类型的未初始化的对象temp,然后用fun(s1,s2)的返回值初始化temp,我在debug的时候发现使用这个等号初始化对象temp的时候并没有调用拷贝构造函数。为什么?在底层发生了什么?
----------------------------以上是不理解的地方---------------------
如果fun函数内写成return s1+s2有什么区别?

运行结果:
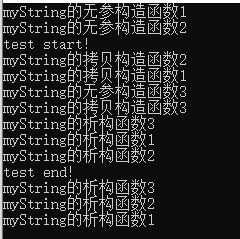
答:区别是省去了一次拷贝构造函数和析构
-----------------------以下是不理解的地方--------------------------
疑问:为什么会省去一次构造函数?两次返回值都是非引用类型,为什么只用了一次拷贝构造函数?
-----------------------以上是不理解的地方--------------------------
一个结构体里面定义了一个char和double,它的空间内存布局是怎么样的?
---------------------以下补充内容-------------------------------
结构体的存储:
1 结构体整体空间是占用空间最大的成员(的类型)所占字节的整数倍。
2 结构体的每个成员相对结构体首地址的偏移量(offset)都是最大基本类型成员字节大小的整数倍,如果不是编译器会自动补齐。
结构体大小等于最后一个成员的偏移量加上它的大小,第一个成员的偏移量为0。
只有结构体变量才分配地址,而结构体的定义是不分配空间的。
--------------------以上补充内容-------------------------------
定义了一个char类型的对象,1个字节,随后定义了一个double类型的对象,因为double类型是8个字节的,假如不自动补齐的话,那double的首地址相对于结构体首地址的偏移量就是1,不是8的整数倍。所以char后面需要补7个字节的内存,然后才是double的8个字节的内存空间。


手撕代码:leetcode772.基本计算器III

class Solution {
public:
int calculate(string s) {
int n = s.size(), curRes = 0, res = 0;
long num=0;
char op = '+';
for (int i = 0; i < n; ++i) {
char c = s[i];
if (c >= '0' && c <= '9') {
num = num * 10 + c - '0';
} else if (c == '(') {
int j = i, cnt = 0;
for (; i < n; ++i) {
if (s[i] == '(') ++cnt;
if (s[i] == ')') --cnt;
if (cnt == 0) break;
}
num = calculate(s.substr(j + 1, i - j - 1));
}
//遇到加减乘除号,先要处理前面的
if (c == '+' || c == '-' || c == '*' || c == '/' || i == n - 1) {
//先根据op的值对num进行分别的加减乘除的处理,结果保存到curRes中
switch (op) {
case '+': curRes += num; break;
case '-': curRes -= num; break;
case '*': curRes *= num; break;
case '/': curRes /= num; break;
}
//假如当前字符是加或减或最后一个数了,把符号前面的结果加到res中
if (c == '+' || c == '-' || i == n - 1) {
res += curRes;
curRes = 0;
}
//更新op、num,也就是下一次的运算符号
op = c;
num = 0;
}
}
return res;
}
};














 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









