






前馈神经网络 之 NLP姓氏分类——从MLP到CNN
一. 感知机部分
1.1 perceptron (感知机)
感知机是现存最简单的神经网络,用于二分类任务的线性分类模型,只有简单的输入层和输出层,通过线性组合与激活函数输出分类结果。感知器的一个历史性的缺点是它不能学习数据中存在的一些非常重要的模式。例如,图1-1中绘制的数据点。在异或(XOR)情况下,决策边界不能是一条直线(也称为线性可分)。下图中,感知器不能完成分类任务。

1.2 The Multilayer Perceptron(多层感知器)
多层感知器(MLP)是对感知器的扩展。感知器将数据向量作为输入,计算出一个输出值。在MLP中,许多感知器被分组,以便单个层的输出是一个新的向量,而不是单个输出值,从而将多个层与每个层之间的非线性结合在一起。。在PyTorch中,只需设置线性层中的输出特性的数量即可实现。MLP的另一个方面是,它将多个层与每个层之间的非线性结合在一起。
最简单的MLP(三层感知机),如图1-2所示,由三个表示层和两个线性层组成。第一层(输入层)是输入向量。如在餐馆评论的情绪进行分类任务中,输入向量可以是Yelp评论的一个one-hot表示。给定输入向量,第一个线性层计算出了隐藏向量(第二层)。使用这个隐藏向量,第二个线性层计算一个输出向量(第三层 or 输出层)。在像Yelp评论分类这样的二分类任务中,输出向量仍然可以是0 or 1。在多类设置中,即本blog后面的“示例:带有多层感知器的姓氏分类”一节中看到,输出向量同类数量大小相同。虽然在这个例子中,我们只展示了一个隐藏的向量,但是实际中MLP也可能会有多个中间层(隐藏层),每个阶段产生自己的隐藏向量。最终的隐藏向量总是通过线性层和非线性的组合映射到输出向量。

多层感知机(MLP)的进步在于添加了第二个线性层,并允许模型学习一个线性分割的中间表示。这种表示的特性在于能够通过一条直线(or 一个超平面)来区分数据点位于直线(or 超平面)的哪一侧。学习到特定属性的中间表示使得分类任务变得线性可分,是其建模能力的精髓所在。
如图1-3所示。在XOR示例中,错误分类的数据点用黑色填充,而正确分类的数据点没有填充。在左边的面板中,从填充的形状可以看出,感知器在学习一个可以将星星和圆分开的决策边界方面有困难。然而,MLP(右面板)学习了一个更精确的决策边界。

尽管图中显示MLP具有两个决策边界,但实际上它只有一个决策边界!由于中间表示法改变了空间,使得一个超平面同时出现在这两个位置上,才会出现这样的效果。在图1-4中,我们可以看到MLP计算的中间值。这些点的形状表示类别(星形或圆形)。从图中可以看出,神经网络(在本例中为MLP)已经学会了“扭曲”数据所处的空间,使得数据通过最后一层时,可以用一条直线将其分割开来。
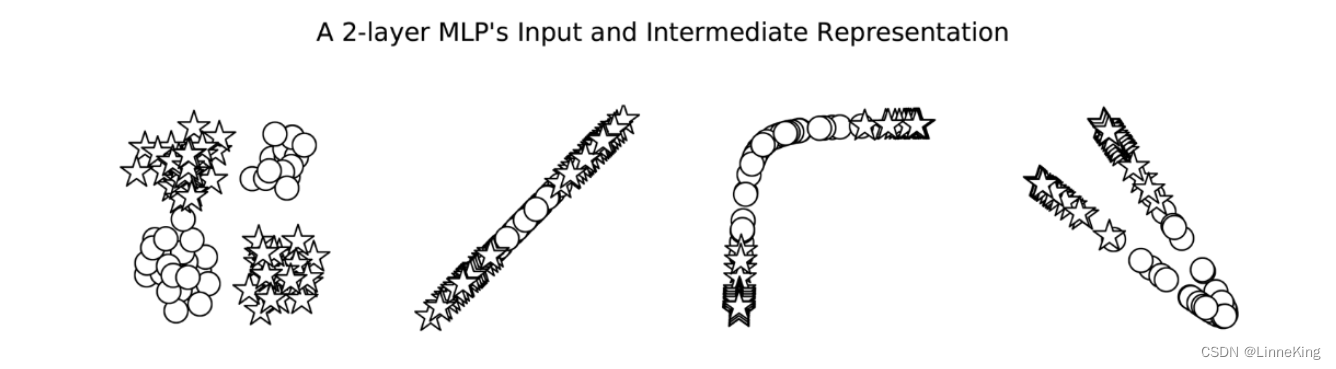
相反,如图1-5所示,感知器没有额外的一层来处理数据的形状来让数据线性可分

1.3 Surname Classification with MLP(姓氏分类之MLP)
1.3.1 任务介绍
The Surname Dataset(姓氏数据集)收集了来自18个不同国家的10,000个姓氏,这些姓氏是作者从互联网上不同的姓名来源收集的。数据集的结构并不平衡。排名前三的种类占据了数据的60%以上,分别是英语姓氏(27%),俄语姓氏(21%),和阿拉伯语姓氏(14%)。此外,该数据集的另一个显著特点是在国籍和姓氏的正字法(拼写)之间存在一种有效且直观的关系。有些拼写变体与原籍国联系非常紧密(例如“O’Neill”、“Antonopoulos”、“Nagasawa”或“Zhu”)。
1.3.2 代码实现与运行结果
考虑神经网络需要经常性的调试,推荐配合jupyter食用
Vocabulary, Vectorizer, and DataLoader
为了使用字符对姓氏进行分类,我们使用词汇表、向量化器和DataLoader将姓氏字符串转换为向量化的minibatches。
class Vocabulary(object):
"""处理文本并提取用于映射的词汇表的类"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
初始化词汇表
参数:
token_to_idx (dict): 预先存在的词到索引的映射字典
add_unk (bool): 是否添加 UNK 令牌的标志
unk_token (str): 要添加到词汇表中的 UNK 令牌
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
# 创建索引到词的反向映射字典
self._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token) # 添加 UNK 令牌并获取其索引
def to_serializable(self):
"""返回可序列化的字典"""
return {
'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token
}
@classmethod
def from_serializable(cls, contents):
"""从序列化字典实例化词汇表"""
return cls(**contents)
def add_token(self, token):
"""根据令牌更新映射字典
参数:
token (str): 要添加到词汇表中的令牌
返回:
index (int): 与令牌对应的整数索引
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""将多个令牌添加到词汇表中
参数:
tokens (list): 字符串令牌列表
返回:
indices (list): 与这些令牌对应的索引列表
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""检索与令牌关联的索引,如果令牌不存在则返回 UNK 索引
参数:
token (str): 要查找的令牌
返回:
index (int): 与令牌对应的索引
备注:
`unk_index` 需要 >= 0(已添加到词汇表)才能启用 UNK 功能
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""返回与索引关联的令牌
参数:
index (int): 要查找的索引
返回:
token (str): 与索引对应的令牌
抛出:
KeyError: 如果索引不在词汇表中
"""
if index not in self._idx_to_token:
raise KeyError("索引 (%d) 不在词汇表中" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
class SurnameVectorizer(object):
"""用于协调词汇表并将其用于向量化的矢量化器"""
def __init__(self, surname_vocab, nationality_vocab):
"""
初始化矢量化器
参数:
surname_vocab (Vocabulary): 将字符映射到整数的词汇表
nationality_vocab (Vocabulary): 将国籍映射到整数的词汇表
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
将姓氏转换为一维的独热编码向量
参数:
surname (str): 姓氏
返回:
one_hot (np.ndarray): 独热编码后的向量
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32) # 创建长度为词汇表大小的零向量
for token in surname:
one_hot[vocab.lookup_token(token)] = 1 # 对姓氏中的每个字符进行独热编码
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""
从数据集的 DataFrame 实例化矢量化器
参数:
surname_df (pandas.DataFrame): 姓氏数据集
返回:
SurnameVectorizer 的实例
"""
surname_vocab = Vocabulary(unk_token="@") # 初始化带有UNK令牌的姓氏词汇表
nationality_vocab = Vocabulary(add_unk=False) # 初始化不带UNK令牌的国籍词汇表
# 遍历数据集,添加所有姓氏中的字符到姓氏词汇表中,并添加所有国籍到国籍词汇表中
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab)
@classmethod
def from_serializable(cls, contents):
"""
从可序列化的字典中实例化矢量化器
参数:
contents (dict): 序列化的词汇表内容
返回:
SurnameVectorizer 的实例
"""
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab)
def to_serializable(self):
"""
返回可序列化的字典
"""
return {
'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable()
}
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
初始化姓氏数据集
参数:
surname_df (pandas.DataFrame): 数据集
vectorizer (SurnameVectorizer): 从数据集中实例化的矢量化器
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split == 'train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split == 'val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split == 'test']
self.test_size = len(self.test_df)
self._lookup_dict = {
'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)
}
self.set_split('train')
# 类别权重
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""从头加载数据集并创建新的矢量化器
参数:
surname_csv (str): 数据集的位置
返回:
SurnameDataset 的实例
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split == 'train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""加载数据集和相应的矢量化器。
在矢量化器已缓存以供重用的情况下使用
参数:
surname_csv (str): 数据集的位置
vectorizer_filepath (str): 已保存的矢量化器的位置
返回:
SurnameDataset 的实例
"""
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
"""静态方法从文件加载矢量化器
参数:
vectorizer_filepath (str): 序列化矢量化器的位置
返回:
SurnameVectorizer 的实例
"""
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
"""使用 json 将矢量化器保存到磁盘
参数:
vectorizer_filepath (str): 保存矢量化器的位置
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
def get_vectorizer(self):
"""返回矢量化器"""
return self._vectorizer
def set_split(self, split="train"):
"""使用数据帧中的列选择数据集中的拆分"""
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
"""PyTorch 数据集的主要入口方法
参数:
index (int): 数据点的索引
返回:
包含数据点特征(x_surname)和标签(y_nationality)的字典
"""
row = self._target_df.iloc[index]
surname_vector = self._vectorizer.vectorize(row.surname)
nationality_index = self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_vector, 'y_nationality': nationality_index}
def get_num_batches(self, batch_size):
"""给定批量大小,返回数据集中的批次数量
参数:
batch_size (int)
返回:
数据集中的批次数量
"""
return len(self) // batch_size
def generate_batches(dataset, batch_size, shuffle=True, drop_last=True, device="cpu"):
"""
包装 PyTorch DataLoader 的生成器函数。
确保每个张量在正确的设备位置上。
参数:
dataset (Dataset): 数据集
batch_size (int): 批量大小
shuffle (bool): 是否打乱数据
drop_last (bool): 是否丢弃最后一个不完整的批次
device (str): 设备("cpu" 或 "cuda")
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
Surname Classifier Model
SurnameClassifier是本实验中实现的多层感知机(MLP)。第一个线性层将输入向量映射到中间向量,并对该向量应用非线性激活函数。第二个线性层将中间向量映射到预测向量。
在最后一步中,可以选择应用softmax操作,以确保输出的和为1,这样就可以解释为“概率”。之所以说是可选的,是因为我们使用的损失函数的数学公式——交叉熵损失。我们在“损失函数”中研究了交叉熵损失。回想一下,交叉熵损失是多类分类的理想选择,但在训练过程中计算softmax不仅浪费计算资源,而且在许多情况下并不稳定。
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
"""用于姓氏分类的两层多层感知器"""
def __init__(self, input_dim, hidden_dim, output_dim):
"""
初始化分类器
参数:
input_dim (int): 输入向量的维度
hidden_dim (int): 第一个全连接层的输出维度
output_dim (int): 第二个全连接层的输出维度
"""
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim) # 定义第一个全连接层
self.fc2 = nn.Linear(hidden_dim, output_dim) # 定义第二个全连接层
def forward(self, x_in, apply_softmax=False):
"""分类器的前向传播过程
参数:
x_in (torch.Tensor): 输入数据张量,形状应为 (batch, input_dim)
apply_softmax (bool): 是否应用 softmax 激活函数的标志
如果与交叉熵损失函数一起使用,应设置为 False
返回:
结果张量,形状应为 (batch, output_dim)
"""
intermediate_vector = F.relu(self.fc1(x_in)) # 第一个全连接层并应用 ReLU 激活函数
prediction_vector = self.fc2(intermediate_vector) # 第二个全连接层
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1) # 如果需要,应用 softmax 激活函数
return prediction_vector # 返回预测向量
Training
from argparse import Namespace
from collections import Counter
import json
import os
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm_notebook
def set_seed_everywhere(seed, cuda):
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
def handle_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
args = Namespace(
# Data and path information
surname_csv="surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/surname_mlp",
# Model hyper parameters
hidden_dim=300,
# Training hyper parameters
seed=1337,
num_epochs=100,
early_stopping_criteria=5,
learning_rate=0.001,
batch_size=64,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# Check CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# # Set seed for reproducibility
set_seed_everywhere(args.seed, args.cuda)
# # handle dirs
handle_dirs(args.save_dir)

#-----------------------------------------------------------------------------------#
# 从数据集中加载并创建矢量化器
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
vectorizer = dataset.get_vectorizer()
# 初始化姓氏分类器
classifier = SurnameClassifier(input_dim=len(vectorizer.surname_vocab),
hidden_dim=args.hidden_dim,
output_dim=len(vectorizer.nationality_vocab))
# 将分类器模型移到指定设备(例如:CPU 或 GPU)
classifier = classifier.to(args.device)
# 初始化损失函数,并使用类别权重来处理类别不平衡问题
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
# 初始化优化器,使用 Adam 优化算法并设置学习率
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
if args.reload_from_files:
# training from a checkpoint
print("Reloading!")
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# create dataset and vectorizer
print("Creating fresh!")
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.get_vectorizer()
classifier = SurnameClassifier(input_dim=len(vectorizer.surname_vocab),
hidden_dim=args.hidden_dim,
output_dim=len(vectorizer.nationality_vocab))
def make_train_state(args):
"""
创建并初始化训练状态字典
参数:
args: 主参数
返回:
包含训练状态值的字典
"""
return {
'stop_early': False, # 是否早停
'early_stopping_step': 0, # 早停步数
'early_stopping_best_val': 1e8, # 早停最佳验证损失
'learning_rate': args.learning_rate, # 学习率
'epoch_index': 0, # 当前周期索引
'train_loss': [], # 训练损失列表
'train_acc': [], # 训练准确率列表
'val_loss': [], # 验证损失列表
'val_acc': [], # 验证准确率列表
'test_loss': -1, # 测试损失
'test_acc': -1, # 测试准确率
'model_filename': args.model_state_file # 模型文件名
}
def update_train_state(args, model, train_state):
"""
处理训练状态更新
组件:
- 早停:防止过拟合
- 模型检查点:如果模型表现更好,则保存模型
参数:
args: 主参数
model: 训练的模型
train_state: 表示训练状态值的字典
返回:
更新后的训练状态字典
"""
# 至少保存一个模型
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# 如果模型性能改善,则保存模型
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# 如果损失变差
if loss_t >= train_state['early_stopping_best_val']:
# 更新步数
train_state['early_stopping_step'] += 1
# 损失减少
else:
# 保存最佳模型
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# 重置早停步数
train_state['early_stopping_step'] = 0
# 是否早停?
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
def compute_accuracy(y_pred, y_target):
"""
计算预测结果的准确率
参数:
y_pred (torch.Tensor): 预测的张量
y_target (torch.Tensor): 目标的张量
返回:
准确率百分比
"""
_, y_pred_indices = y_pred.max(dim=1)
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
# 将分类器模型和类别权重移到指定设备(例如:CPU 或 GPU)
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
# 初始化损失函数,并使用类别权重来处理类别不平衡问题
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
# 初始化优化器,使用 Adam 优化算法并设置学习率
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
# 初始化学习率调度器,在损失不再降低时调整学习率
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
# 初始化训练状态
train_state = make_train_state(args)
# 初始化进度条
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
# 设置数据集的拆分方式为训练集,并初始化训练进度条
dataset.set_split('train')
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
# 设置数据集的拆分方式为验证集,并初始化验证进度条
dataset.set_split('val')
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
# 迭代训练数据集
# 设置:批量生成器,初始化损失和准确率为 0,设置训练模式
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# 训练过程的五个步骤:
# --------------------------------------
# 步骤 1. 将梯度归零
optimizer.zero_grad()
# 步骤 2. 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 步骤 3. 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 步骤 4. 使用损失计算梯度
loss.backward()
# 步骤 5. 使用优化器更新权重
optimizer.step()
# -----------------------------------------
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# 更新进度条
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# 迭代验证数据集
# 设置:批量生成器,初始化损失和准确率为 0,设置评估模式
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# 计算输出
y_pred = classifier(batch_dict['x_surname'])
# 步骤 3. 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.to("cpu").item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# 计算准确率
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
# 更新训练状态
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
# 调整学习率
scheduler.step(train_state['val_loss'][-1])
# 早停
if train_state['stop_early']:
break
# 重置进度条
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")
简单的测试环节
def predict_nationality(name, classifier, vectorizer):
"""
预测姓氏的国籍
参数:
name (str): 输入的姓氏
classifier (SurnameClassifier): 已训练的分类器模型
vectorizer (SurnameVectorizer): 矢量化器,用于将姓氏和国籍映射到整数
返回:
dict: 包含预测的国籍和相应的概率值
"""
# 将姓氏矢量化
vectorized_name = vectorizer.vectorize(name)
# 将矢量化后的姓氏转换为张量,并调整形状为 (1, -1)
vectorized_name = torch.tensor(vectorized_name).view(1, -1)
# 使用分类器进行预测,并应用 softmax 激活函数
result = classifier(vectorized_name, apply_softmax=True)
# 获取最大概率值和相应的索引
probability_values, indices = result.max(dim=1)
index = indices.item()
# 根据索引查找预测的国籍
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality,
'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.to("cpu")
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))

----------------------------------------------------------手动分割-------------------------------------------------------------
二. 卷积神经网络部分(CNN)
2.1 CNN介绍
卷积神经网络(Convolutional Neural Network, CNN)是一种专为处理具有网格状拓扑数据(如图像)的深度学习模型。它在图像识别和分类任务中表现出色,广泛应用于计算机视觉领域。
MLP不能利用字段中的顺序。例如在姓氏数据集中,姓氏可以有(不同长度的)段,这些段可以显示出相当多关于其起源国家的信息(如“O’Neill”中的“O”、“Antonopoulos”中的“opoulos”、“Nagasawa”中的“sawa”或“Zhu”中的“Zh”)。这些段的长度可以是可变的,但是很难在不显式编码的情况下捕获它们,故而利用MLP模型进行学习会损失这部分信息
CNN是一种非常适合检测空间子结构(并因此创建有意义的空间子结构)的神经网络。CNNs通过使用少量的权重来扫描输入数据张量,从而产生表示子结构检测的输出张量。
2.1.1 CNN Hyperparameters
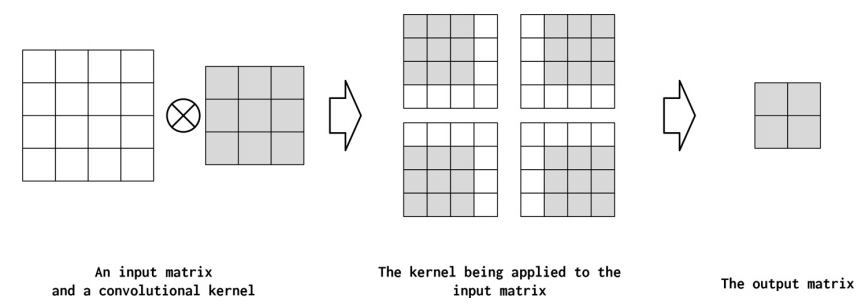
为了理解不同的设计对CNN意味着什么,我们在图2-1中展示了一个示例。在本例中,单个“核(kernel)”应用于输入矩阵。卷积运算(线性算子)的精确数学表达式对于理解这一节并不重要,但是从这个图中可以直观地看出,核是一个小的方阵,它被系统地应用于输入矩阵的不同位置。

DIMENSION OF THE CONVOLUTION OPERATION
在PyTorch中,卷积可以是一维、二维或三维的,分别由Conv1d、Conv2d和Conv3d模块实现。一维卷积适用于时间序列数据,二维卷积用于图像处理,而三维卷积则处理视频数据中的时空信息。我们使用二维卷积进行说明
CHANNELS
通道(channel)是指输入中每个点的特征维度。例如,图像的每个像素有三个通道(RGB)。在卷积操作中,文本数据也可以采用类似的概念,将单词视为“像素”,通道数量为词汇表大小。PyTorch的卷积实现中,in_channels参数表示输入通道数,out_channels表示输出通道数。合理选择输出通道数对模型性能至关重要。


KERNEL SIZE
核矩阵的宽度称为核大小(PyTorch中的kernel_size)。核大小控制卷积操作中本地信息的组合范围。较小的核大小捕捉细粒度特性,而较大的核大小则捕捉较大范围的模式。核大小的选择会影响输出的大小,较大的核会减少输出矩阵的尺寸。
STRIDE
步幅(stride)控制卷积核在输入上的移动步长。如果步幅与核大小相同,卷积计算不会重叠;如果步幅为1,卷积核最大程度重叠。增加步幅可以压缩输出张量,减少计算量,同时总结更多信息。

PADDING
填充(padding)用于在输入数据的边缘添加额外的值(通常是0),以控制输出的形状,避免卷积操作缩小特征映射的总大小。通过填充,可以在不影响核大小和步幅的情况下,保持输出矩阵的尺寸与输入矩阵一致。

DILATION
膨胀(dilation)控制卷积核在应用时的扩展程度。增加膨胀值意味着在核元素之间引入空格,从而扩大卷积的感受野,而不增加参数数量。膨胀卷积在堆叠多个卷积层时非常有用,可以指数级地增大感受野。

2.2 代码实现
SurnameDataset.__getitem__方法在此得到了修改,代码结构基本一致,注释略
from argparse import Namespace
from collections import Counter
import json
import os
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm_notebook
class Vocabulary(object):
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
return cls(**contents)
def add_token(self, token):
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab, max_surname_length):
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
self._max_surname_length = max_surname_length
def vectorize(self, surname):
one_hot_matrix_size = (len(self.surname_vocab), self._max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
for position_index, character in enumerate(surname):
character_index = self.surname_vocab.lookup_token(character)
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix
@classmethod
def from_dataframe(cls, surname_df):
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
max_surname_length = 0
for index, row in surname_df.iterrows():
max_surname_length = max(max_surname_length, len(row.surname))
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab, max_surname_length)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab,
max_surname_length=contents['max_surname_length'])
def to_serializable(self):
return {'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable(),
'max_surname_length': self._max_surname_length}
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# Class weights
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
def get_vectorizer(self):
return self._vectorizer
def set_split(self, split="train"):
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
row = self._target_df.iloc[index]
surname_matrix = \
self._vectorizer.vectorize(row.surname)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_matrix,
'y_nationality': nationality_index}
def get_num_batches(self, batch_size):
return len(self) // batch_size
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
super(SurnameClassifier, self).__init__()
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
features = self.convnet(x_surname).squeeze(dim=2)
prediction_vector = self.fc(features)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector
def make_train_state(args):
return {'stop_early': False,
'early_stopping_step': 0,
'early_stopping_best_val': 1e8,
'learning_rate': args.learning_rate,
'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1,
'model_filename': args.model_state_file}
def update_train_state(args, model, train_state):
# Save one model at least
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# Save model if performance improved
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# If loss worsened
if loss_t >= train_state['early_stopping_best_val']:
# Update step
train_state['early_stopping_step'] += 1
# Loss decreased
else:
# Save the best model
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# Reset early stopping step
train_state['early_stopping_step'] = 0
# Stop early ?
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
def compute_accuracy(y_pred, y_target):
y_pred_indices = y_pred.max(dim=1)[1]
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
args = Namespace(
# Data and Path information
surname_csv="data/surnames/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/cnn",
# Model hyper parameters
hidden_dim=100,
num_channels=256,
# Training hyper parameters
seed=1337,
learning_rate=0.001,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
dropout_p=0.1,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
catch_keyboard_interrupt=True
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# Check CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
def set_seed_everywhere(seed, cuda):
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
def handle_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
# Set seed for reproducibility
set_seed_everywhere(args.seed, args.cuda)
# handle dirs
handle_dirs(args.save_dir)
if args.reload_from_files:
# training from a checkpoint
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# create dataset and vectorizer
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.get_vectorizer()
classifier = SurnameClassifier(initial_num_channels=len(vectorizer.surname_vocab),
num_classes=len(vectorizer.nationality_vocab),
num_channels=args.num_channels)
classifer = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(weight=dataset.class_weights)
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
train_state = make_train_state(args)
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
dataset.set_split('train')
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
dataset.set_split('val')
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
optimizer.zero_grad()
y_pred = classifier(batch_dict['x_surname'])
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
loss.backward()
optimizer.step()
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
y_pred = classifier(batch_dict['x_surname'])
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
scheduler.step(train_state['val_loss'][-1])
if train_state['stop_early']:
break
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
y_pred = classifier(batch_dict['x_surname'])
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))
测试
def predict_nationality(surname, classifier, vectorizer):
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.cpu()
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
三. 写在最后
在本文中,我们探讨了从感知机到多层感知机(MLP),再到卷积神经网络(CNN)在姓氏分类任务中的应用和实现。感知机作为最简单的神经网络模型,虽然在一些简单的任务中表现良好,但在处理复杂数据模式时存在局限性。MLP通过增加隐藏层和非线性激活函数,显著提升了模型的表达能力,使得其能够解决更多复杂的分类问题。然而,对于具有空间结构的数据,如图像和视频,MLP仍然不能充分利用数据中的空间信息。
为了解决这一问题,我们引入了卷积神经网络(CNN)。CNN通过使用卷积层来捕捉数据中的局部特征,极大地提升了模型在图像和视频处理中的表现。在本文的示例中,我们展示了如何使用CNN来处理姓氏分类任务,通过卷积操作捕捉姓氏中局部字符序列的特征,从而提高分类精度。
通过对MLP和CNN的比较,我们可以看到不同模型在处理不同类型数据时的优势和劣势。MLP适用于较为简单和结构化的数据,而CNN在处理具有空间结构的数据时表现出色。这为我们在实际应用中选择合适的模型提供了指导。
总的来说,理解和掌握这些基础的神经网络模型是深入研究深度学习和神经网络的重要基础。希望通过本文的介绍,读者能够对感知机、MLP和CNN有更深入的理解,并能够在实际项目中灵活应用这些模型解决实际问题。















 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









