






一.前馈神经网络
在前馈神经网络中,信息从输入层流向输出层,每一层的神经元通过激活函数(如sigmoid、ReLU等)处理输入,并将输出传递给下一层。神经网络的学习过程通常通过反向传播算法(Backpropagation)进行,利用训练数据调整网络中每个连接的权重,以最小化预测输出与实际输出之间的误差
1.1多层感知机
多层感知机(Multilayer Perceptron,简称MLP),是一种基于前馈神经网络(Feedforward Neural Network)的深度学习模型,由多个神经元层组成,其中每个神经元层与前一层全连接。多层感知机可以用于解决分类、回归和聚类等各种机器学习问题。
多层感知机的每个神经元层由许多神经元组成,其中输入层接收输入特征,输出层给出最终的预测结果,中间的隐藏层用于提取特征和进行非线性变换。每个神经元接收前一层的输出,进行加权和和激活函数运算,得到当前层的输出。通过不断迭代训练,多层感知机可以自动学习到输入特征之间的复杂关系,并对新的数据进行预测。
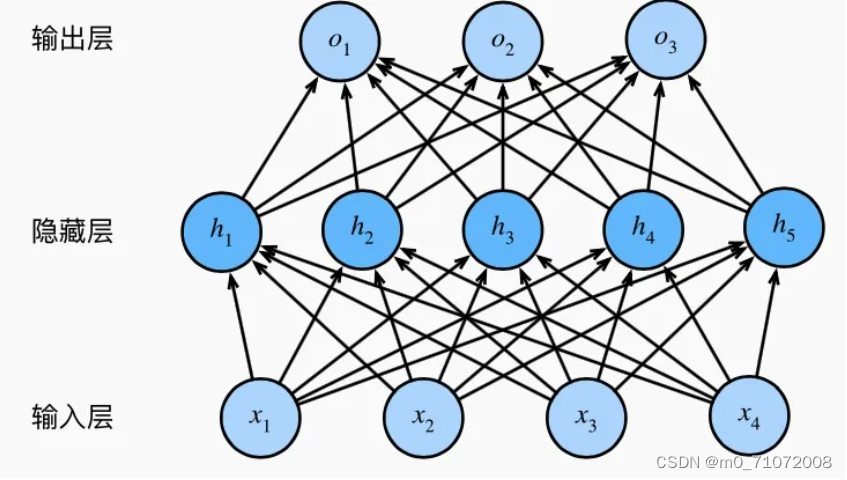
输入层—>隐藏层—>输出层
神经元:包含一个带有权重和偏置的线性变换,以及一个激活函数(通常,输入层不使用激活函数,隐藏层和输出层使用激活函数)用来引入非线性,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中
隐藏层神经元:假设输入层用向量X表示,则隐藏层的输出就是f(w1*X+b1),函数f可以是sigmoid函数或者tanh函数,w1是权重(连接系数),b1是偏置
输出层的输出:softmax(w2*X1+b2),X1是隐藏层的输出
我们在一个二元分类任务中训练感知器和MLP:星和圆。每个数据点是一个二维坐标。在不深入研究实现细节的情况下,最终的模型预测如图4-3所示。在这个图中,错误分类的数据点用黑色填充,而正确分类的数据点没有填充。在左边的面板中,从填充的形状可以看出,感知器在学习一个可以将星星和圆分开的决策边界方面有困难。然而,MLP(右面板)学习了一个更精确地对恒星和圆进行分类的决策边界。

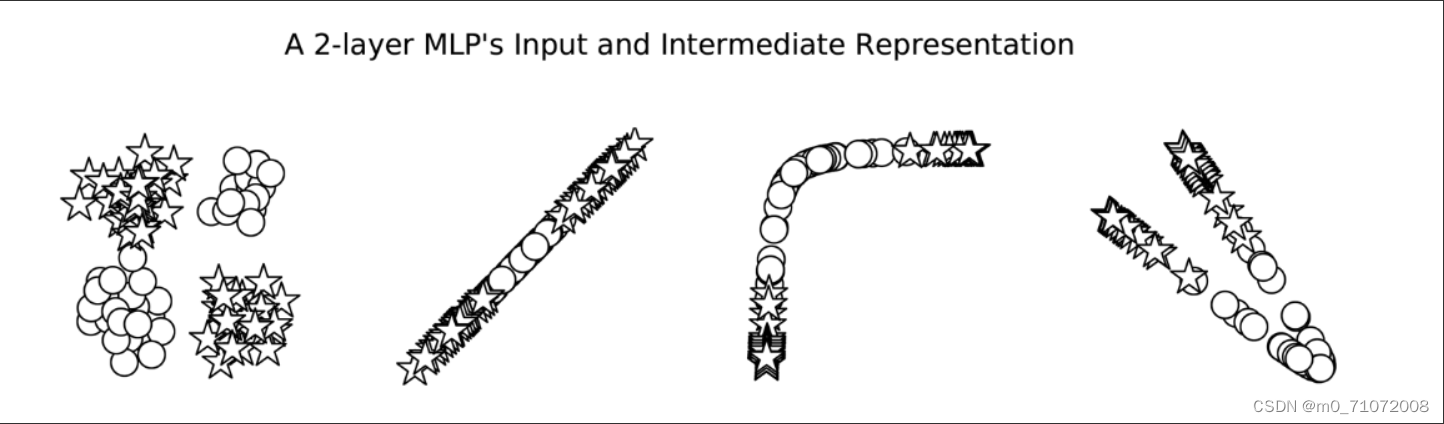
虽然在图中显示MLP有两个决策边界,这是它的优点,但它实际上只是一个决策边界!决策边界就是这样出现的,因为中间表示法改变了空间,使一个超平面同时出现在这两个位置上。我们可以看到MLP计算的中间值。这些点的形状表示类(星形或圆形)。我们所看到的是,神经网络(本例中为MLP)已经学会了“扭曲”数据所处的空间,以便在数据通过最后一层时,用一线来分割它们。
1.2 激活函数的选择
激活函数是神经网络中引入的非线性函数,用于捕获数据中的复杂关系。
1.2.1 sigmoid函数
sigmoid 是神经网络历史上最早使用的激活函数之一。它取任何实值并将其压缩在0和1之间。数学上,sigmoid 的表达式如下:
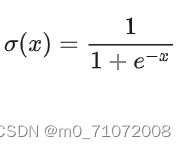
从表达式中很容易看出,sigmoid 是一个光滑的、可微的函数。
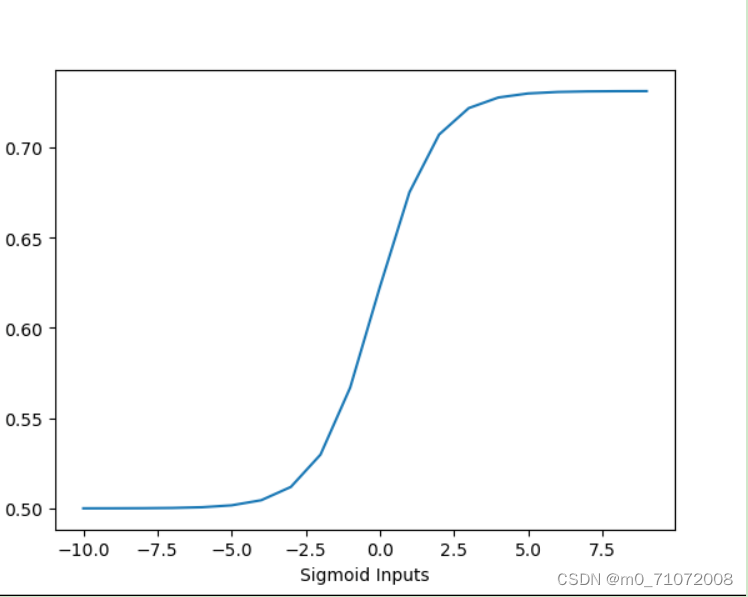
import torch
import matplotlib.pyplot as plt
x = torch.range(-5., 5., 0.1)#在(-5,5)范围中,以步长0.1取值作为x张量
y = torch.sigmoid(x)#计算sigmoid值
plt.plot(x.numpy(), y.numpy())#绘制图像
plt.show()#显示图像这段代码可以展示sigmoid图像,图像展示如下:
1.2.2 tanh函数
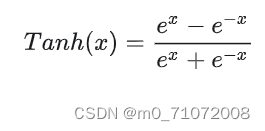
它的输出均值为0,使其收敛速度要比sigmoid快,可以减少迭代次数。它的缺点是需要幂运算,计算成本高;同样存在梯度消失,因为在两边一样有趋近于0的情况
import torch
import matplotlib.pyplot as plt
x = torch.range(-5., 5., 0.1)#在(-5,5)范围中,以步长0.1取值作为x张量
y = torch.tanh(x)#计算tanh()值
plt.plot(x.numpy(), y.numpy())#绘制图像
plt.show()#显现图像函数图像如下:
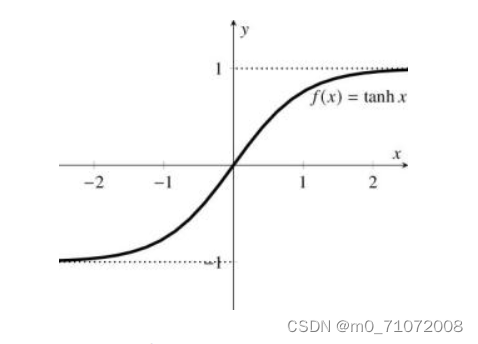
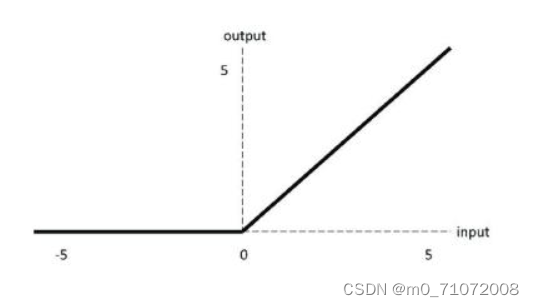
1.2.3 ReLU函数
它的优点是梯度不饱和,收敛速度快;相对sigmoid/tanh,极大地改善了梯度消失的问题;不需要进行指数运算,因此运算速度快,复杂度低。
ReLU函数会使得一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的互相依存关系,缓解了过拟合问题的发生。
它的缺点是对参数初始化和学习率非常敏感;如果前向传播值小于0,反向传播无法计算梯度,权重无法更新,神经网络不能学习
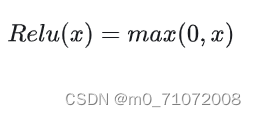
import torch
import matplotlib.pyplot as plt
relu = torch.nn.ReLU()
x = torch.range(-5., 5., 0.1)#在(-5,5)范围中,以步长0.1取值作为x张量
y = relu(x)#计算relu的值
plt.plot(x.numpy(), y.numpy())#绘制图像
plt.show()函数图像如下 :
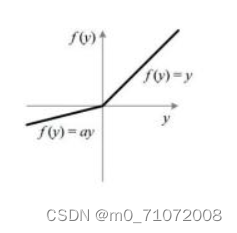
1.2.4 Leak ReLU函数
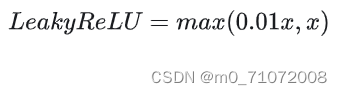
Leaky ReLU 通过把 x 的非常小的线性分量给予负输入(0.01x)来调整负值的零梯度(zero gradients)问题;
leak 有助于扩大 ReLU 函数的范围,通常 a 的值为 0.01 左右;
Leaky ReLU 的函数范围是(负无穷到正无穷)
import torch
import matplotlib.pyplot as plt
prelu = torch.nn.PReLU(num_parameters=1)
x = torch.range(-5., 5., 0.1)#在(-5,5)范围中,以步长0.1取值作为x张量
y = prelu(x)
plt.plot(x.detach().numpy(), y.detach().numpy())#绘制图像
plt.show()函数图像如下:
2.2.5 softmax函数
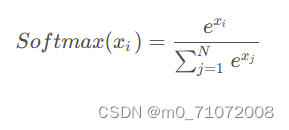
Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。
import torch.nn as nn
import torch
softmax = nn.Softmax(dim=1)
x_input = torch.randn(1, 3)#创建形状为(1, 3)的张量
y_output = softmax(x_input)#计算softmax
print(x_input)
print(y_output)
print(torch.sum(y_output, dim=1))#输出所有y的和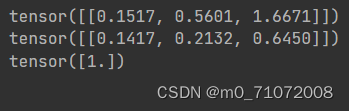
函数图像如下:
二 配置环境
本实验所需环境如下:
Python 3.6.7
三.搭建模型
3.1 多层感知机模型
使用pytorch库来实现。
class MultilayerPerceptron(nn.Module):
"""
"""
def __init__(self, input_size, hidden_size=2, output_size=3,
num_hidden_layers=1, hidden_activation=nn.Sigmoid):
"""Initialize weights.
Args:
input_size (int): size of the input
hidden_size (int): size of the hidden layers
output_size (int): size of the output
num_hidden_layers (int): number of hidden layers
hidden_activation (torch.nn.*): the activation class
"""
super(MultilayerPerceptron, self).__init__()
self.module_list = nn.ModuleList()
interim_input_size = input_size
interim_output_size = hidden_size
for _ in range(num_hidden_layers):
self.module_list.append(nn.Linear(interim_input_size, interim_output_size))
self.module_list.append(hidden_activation())
interim_input_size = interim_output_size
self.fc_final = nn.Linear(interim_input_size, output_size)
self.last_forward_cache = []
def forward(self, x, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
self.last_forward_cache = []
self.last_forward_cache.append(x.to("cpu").numpy())
for module in self.module_list:
x = module(x)
self.last_forward_cache.append(x.to("cpu").data.numpy())
output = self.fc_final(x)
self.last_forward_cache.append(output.to("cpu").data.numpy())
if apply_softmax:
output = F.softmax(output, dim=1)
return output在由于MLP实现的通用性,可以为任何大小的输入建模。为了演示,我们使用大小为3的输入维度、大小为4的输出维度和大小为100的隐藏维度。请注意,在print语句的输出中,每个层中的单元数很好地排列在一起,以便为维度3的输入生成维度4的输出。
batch_size = 2 # number of samples input at once
input_dim = 3#设置输入纬度为3
hidden_dim = 100#设置隐藏维度为100
output_dim = 4#设置输出纬度为4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)输出结果如下:
MultilayerPerceptron(
(fc1): Linear(in_features=3, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=4, bias=True)
)
接下来用随机数据进行测试
import torch
def describe(x):
print("Type: {}".format(x.type()))#打印类型
print("Shape/size: {}".format(x.shape))#打印大小
print("Values: \n{}".format(x))#打印数值
x_input = torch.rand(batch_size, input_dim)
describe(x_input)运行结果如下:
Type: torch.FloatTensor
Shape/size: torch.Size([2, 3])
Values:
tensor([[0.5964, 0.9360, 0.4082],
[0.1855, 0.9629, 0.4520]])
这次将apply_softmax标志设置为True
y_output = mlp(x_input, apply_softmax=True)
describe(y_output)运行结果如下:
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[0.2196, 0.2680, 0.2075, 0.3050],
[0.2245, 0.2648, 0.2144, 0.2963]], grad_fn=<SoftmaxBackward>)
综上所述,mlp是将张量映射到其他张量的线性层。在每一对线性层之间使用非线性来打破线性关系,并允许模型扭曲向量空间。在分类设置中,这种扭曲应该导致类之间的线性可分性。另外,可以使用softmax函数将MLP输出解释为概率,但是不应该将softmax与特定的损失函数一起使用,因为底层实现可以利用高级数学/计算捷径。
3.2 数据集的处理
3.2.1 数据预处理
class SurnameDataset(Dataset):
# Implementation is nearly identical to Section 3.5
def __getitem__(self, index):#获取索引为 index 的行数据
row = self._target_df.iloc[index]
surname_vector = \
self._vectorizer.vectorize(row.surname)#使用 _vectorizer 对象将姓氏 (surname) 向量化
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)#使用 _vectorizer 对象的 nationality_vocab 查找 row.nationality 对应的索引
return {'x_surname': surname_vector,
'y_nationality': nationality_index}
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab):
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""Vectorize the provided surname
Args:
surname (str): the surname
Returns:
one_hot (np.ndarray): a collapsed one-hot encoding
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab)
为了创建最终的数据集,我们从一个比课程补充材料中包含的版本处理更少的版本开始,并执行了几个数据集修改操作。第一个目的是减少这种不平衡——原始数据集中70%以上是俄文,这可能是由于抽样偏差或俄文姓氏的增多。为此,我们通过选择标记为俄语的姓氏的随机子集对这个过度代表的类进行子样本。接下来,我们根据国籍对数据集进行分组,并将数据集分为三个部分:70%到训练数据集,15%到验证数据集,最后15%到测试数据集,以便跨这些部分的类标签分布具有可比性。
SurnameVectorizer负责应用词汇表并将姓氏转换为向量。
3.2.2 姓氏分类器的构建
class SurnameClassifier(nn.Module):
""" A 2-layer Multilayer Perceptron for classifying surnames """
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate_vector = F.relu(self.fc1(x_in))
prediction_vector = self.fc2(intermediate_vector)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector第一个线性层将输入向量映射到中间向量,并对该向量应用非线性。第二线性层将中间向量映射到预测向量。
在最后一步中,可选地应用softmax操作,以确保输出和为1。
3.2.3 姓氏空间构建并预训练
args = Namespace(
# Data and path information
surname_csv="data/surnames/surnames.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/surname_mlp",
# Model hyper parameters
hidden_dim=300,
# Training hyper parameters
seed=1337,
num_epochs=100,
early_stopping_criteria=5,
learning_rate=0.001,
batch_size=64,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
)
if args.expand_filepaths_to_save_dir:
args.vectorizer_file = os.path.join(args.save_dir,
args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir,
args.model_state_file)
print("Expanded filepaths: ")
print("\t{}".format(args.vectorizer_file))
print("\t{}".format(args.model_state_file))
# Check CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
# Set seed for reproducibility
set_seed_everywhere(args.seed, args.cuda)
# handle dirs
handle_dirs(args.save_dir) 输出结果如下:
Expanded filepaths:
model_storage/ch4/surname_mlp/vectorizer.json
model_storage/ch4/surname_mlp/model.pth
Using CUDA: False
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
train_state = make_train_state(args)
epoch_bar = tqdm_notebook(desc='training routine',
total=args.num_epochs,
position=0)
dataset.set_split('train')
train_bar = tqdm_notebook(desc='split=train',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
dataset.set_split('val')
val_bar = tqdm_notebook(desc='split=val',
total=dataset.get_num_batches(args.batch_size),
position=1,
leave=True)
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
# Iterate over training dataset
# setup: batch generator, set loss and acc to 0, set train mode on
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# the training routine is these 5 steps:
# --------------------------------------
# step 1. zero the gradients
optimizer.zero_grad()
# step 2. compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# step 4. use loss to produce gradients
loss.backward()
# step 5. use optimizer to take gradient step
optimizer.step()
# -----------------------------------------
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# update bar
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
# Iterate over val dataset
# setup: batch generator, set loss and acc to 0; set eval mode on
dataset.set_split('val')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.to("cpu").item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
val_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
val_bar.update()
train_state['val_loss'].append(running_loss)
train_state['val_acc'].append(running_acc)
train_state = update_train_state(args=args, model=classifier,
train_state=train_state)
scheduler.step(train_state['val_loss'][-1])
if train_state['stop_early']:
break
train_bar.n = 0
val_bar.n = 0
epoch_bar.update()
except KeyboardInterrupt:
print("Exiting loop")
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc'])) 运行结果如下:
Test loss: 1.7435305690765381;
Test Accuracy: 47.875
3.3 CNN模型构建
构造特征向量的第一步是将PyTorch的Conv1d类的一个实例应用到三维数据张量。通过检查输出的大小,可以知道张量减少了多少。
import torch
import torch.nn as nn
# 使用Conv1d类
conv1d_layer = nn.Conv1d(in_channels, out_channels, kernel_size)
batch_size = 2
one_hot_size = 10 # 输入数据的特征数,
sequence_width = 7 # 输入数据的特征数,
data = torch.randn(batch_size, one_hot_size, sequence_width)
conv1 = Conv1d(in_channels=one_hot_size, out_channels=16,
kernel_size=3)
# 将输入数据data传递给conv1进行前向计算
intermediate1 = conv1(data)
# 打印输入数据data和输出数据intermediate1的大小
print(data.size())
print(intermediate1.size())进一步减小输出张量的主要方法有三种。第一种方法是创建额外的卷积并按顺序应用它们。最终,对应的sequence_width (dim=2)维度的大小将为1。我们在例4-15中展示了应用两个额外卷积的结果。一般来说,对输出张量的约简应用卷积的过程是迭代的,需要一些猜测工作。我们的示例是这样构造的:经过三次卷积之后,最终的输出在最终维度上的大小为1。
conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3)
conv3 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3)
# intermediate1 是之前计算得到的输出结果
# 使用 conv2 对 intermediate1 进行一维卷积操作
intermediate2 = conv2(intermediate1)
intermediate3 = conv3(intermediate2)我们在本例中使用的模型是使用我们在“卷积神经网络”中介绍的方法构建的。实际上,我们在该部分中创建的用于测试卷积层的“人工”数据与姓氏数据集中使用本例中的矢量化器的数据张量的大小完全匹配。正如在示例4-19中所看到的,它与我们在“卷积神经网络”中引入的Conv1d序列既有相似之处,也有需要解释的新添加内容。具体来说,该模型类似于“卷积神经网络”,它使用一系列一维卷积来增量地计算更多的特征,从而得到一个单特征向量。
然而,本例中的新内容是使用sequence和ELU PyTorch模块。序列模块是封装线性操作序列的方便包装器。在这种情况下,我们使用它来封装Conv1d序列的应用程序。ELU是类似于实验3中介绍的ReLU的非线性函数,但是它不是将值裁剪到0以下,而是对它们求幂。ELU已经被证明是卷积层之间使用的一种很有前途的非线性(Clevert et al., 2015)。
在本例中,我们将每个卷积的通道数与num_channels超参数绑定。我们可以选择不同数量的通道分别进行卷积运算。这样做需要优化更多的超参数。我们发现256足够大,可以使模型达到合理的性能。
构建cnn分类器
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
Args:
initial_num_channels (int): size of the incoming feature vector
num_classes (int): size of the output prediction vector
num_channels (int): constant channel size to use throughout network
"""
super(SurnameClassifier, self).__init__()
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_surname (torch.Tensor): an input data tensor.
x_surname.shape should be (batch, initial_num_channels,
max_surname_length)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, num_classes)
"""
features = self.convnet(x_surname).squeeze(dim=2)
prediction_vector = self.fc(features)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector采用上文的姓氏空间可进行直接测试
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.CrossEntropyLoss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc'])) Test loss: 1.9216371824343998;
Test Accuracy: 60.7421875
接下来进行预测评估:
def predict_nationality(surname, classifier, vectorizer):
"""Predict the nationality from a new surname
Args:
surname (str): the surname to classifier
classifier (SurnameClassifer): an instance of the classifier
vectorizer (SurnameVectorizer): the corresponding vectorizer
Returns:
a dictionary with the most likely nationality and its probability
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.cpu()
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))
def predict_topk_nationality(surname, classifier, vectorizer, k=5):
"""Predict the top K nationalities from a new surname
Args:
surname (str): the surname to classifier
classifier (SurnameClassifer): an instance of the classifier
vectorizer (SurnameVectorizer): the corresponding vectorizer
k (int): the number of top nationalities to return
Returns:
list of dictionaries, each dictionary is a nationality and a probability
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(dim=0)
prediction_vector = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = torch.topk(prediction_vector, k=k)
# returned size is 1,k
probability_values = probability_values[0].detach().numpy()
indices = indices[0].detach().numpy()
results = []
for kth_index in range(k):
nationality = vectorizer.nationality_vocab.lookup_index(indices[kth_index])
probability_value = probability_values[kth_index]
results.append({'nationality': nationality,
'probability': probability_value})
return results
new_surname = input("Enter a surname to classify: ")
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability'])) 















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









