







文章目录
1. 关于 Geatpy
Geatpy是一个高性能实用型进化算法工具箱,提供许多已实现的进化算法中各项重要操作的库函数,并提供一个高度模块化、耦合度低的面向对象的进化算法框架,利用**“定义问题类 + 调用算法模板”**的模式来进行进化优化,可用于求解单目标优化、多目标优化、复杂约束优化、组合优化、混合编码进化优化等,并且能和SCOOP等框架紧密配合进行分布式计算1。
进化算法(Evolutionary Algorithm, EA)是一类通过模拟自然界生物自然选择和自然进化的随机搜索算法,与传统搜索算法如二分法、斐波那契法、牛顿法、抛物线法等相比,进化算法有着高鲁棒性和求解高度复杂的非线性问题(例如NP-Hard问题)的能力。
1.1 安装方式
Geatpy需要 numpy>=1.17.0 和 matplotlib>=3.0.0,因此在安装之前需要先更新这两个依赖库。具体安装Geatpy的方法如下:
方法一:在线利用 pip 工具进行安装:
pip install geatpy
方法二:下载源文件后在本地进行安装:
python setup.py install # 通过 setup.py 文件进行安装
pip install <filename>.whl # 通过 whl 文件进行安装
1.2 Geatpy架构简介
Geatpy2整体上看由工具箱内核函数(内核层)和面向对象进化算法框架(框架层)两部分组成。其中面向对象进化算法框架主要有四个大类:Problem问题类、Algorithm算法模板类、Population种群类和PsyPopulation多染色体种群类。UML图如下所示:

Problem 问题类
该类定义了与问题相关的一些信息,如问题名称 name、优化目标的维数M、决策变量的个数 Dim、决策变量的范围 ranges、决策变量的边界borders等。maxormins是一个记录着各个目标函数是最小化或是最大化的行向量,其中元素为1表示对应的目标是最小化目标;为-1表示对应的是最大化目标。varTypes 是一个记录着决策变量类型的行向量,其中的元素为0表示对应的决策变量是连续型变量;为1表示对应的是离散型变量。待求解的目标函数定义在aimFunc()的函数中。calReferObjV() 函数则用于计算或读取目标函数参考值。对于Problem类中各属性的详细含义可查看Problem.py源码。
Population 种群类
该类是一个表示种群的类。一个种群包含很多个个体,而每个个体都有一条染色体(若要用多染色体,则使用多个种群、并把每个种群对应个体关联起来即可)。除了染色体外,每个个体都有一个译码矩阵Field(或俗称区域描述器) 来标识染色体应该如何解码得到表现型,同时也有其对应的目标函数值以及适应度。种群类就是一个把所有个体的这些数据统一存储起来的一个类。比如里面的Chrom 是一个存储种群所有个体染色体的矩阵,它的每一行对应一个个体的染色体;ObjV 是一个目标函数值矩阵,每一行对应一个个体的所有目标函数值,每一列对应一个目标。对于Population 类中各属性的详细含义可查看Population.py 源码。
PsyPopulation 多染色体种群类
是继承了Population的支持多染色体混合编码的种群类。一个种群包含很多个个体,而每个个体都有多条染色体。用Chroms列表存储所有的染色体矩阵(Chrom);Encodings列表存储各染色体对应的编码方式(Encoding);Fields列表存储各染色体对应的译码矩阵(Field)。EncoIdxs是一个list,其元素表示每条染色体对应编码哪一个变量。比如EncoIdxs = [[0], [1,2,3,4]],表示一共有5个变量,其中第一个变量编码成第一条子染色体;后4个变量编码成第二条子染色体。
Algorithm 算法模板类
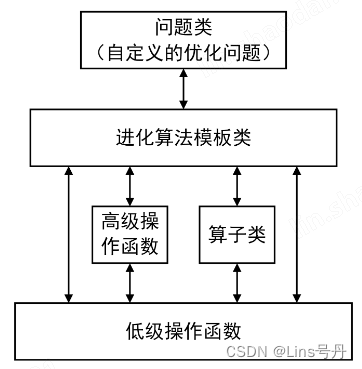
该类是进化算法的核心类。它既存储着跟进化算法相关的一些参数,同时也在其继承类中实现具体的进化算法。比如Geatpy 中的moea_NSGA3_templet.py 是实现了多目标优化NSGA-III 算法的进化算法模板类,它是继承了Algorithm 类的具体算法的模板类。关于Algorithm 类中各属性的含义可以查看Algorithm.py 源码2。这些算法模板通过调用Geatpy 工具箱提供的进化算法库函数实现对种群的进化操作,同时记录进化过程中的相关信息,其基本层次结构如下图:
1.3 Geatpy 基本数据结构
Geatpy的大部分数据都是存储在 numpy 数组里的,存储的结构主要为矩阵和向量,注意,numpy 当中没有列向量的概念,尽管列向量是一维的,但在 array 结构当中是个二维矩阵。以下介绍Geatpy中的基本数据结构:
种群染色体 Chrom:二维矩阵,每一行对应一个个体的一条染色体,若要采用多染色体,则可以创建多个相关联的 Chrom 即可,默认一个 Chrom 的一行对应的只有一条染色体。Chrom 的行数为种群的个体数,也称为种群的规模,常用符号 Nind 表示,Chrom 的列数为染色体长度,常用 Lind 表示。具体结构如下所示:
Chrom = ( g 1 , 1 g 1 , 2 g 1 , 3 ⋯ g 1 , Lind g 2 , 1 g 2 , 2 g 2 , 3 ⋯ g 2 , Lind ⋮ ⋮ ⋮ ⋮ ⋮ g N i n d , 1 g N i n d , 2 g N i n d , 3 ⋯ g N i n d , Lind ) \text { Chrom }=\left(\begin{array}{ccccc} g_{1,1} & g_{1,2} & g_{1,3} & \cdots & g_{1, \text { Lind }} \\ g_{2,1} & g_{2,2} & g_{2,3} & \cdots & g_{2, \text { Lind }} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ g_{N i n d, 1} & g_{N i n d, 2} & g_{N i n d, 3} & \cdots & g_{N i n d, \text { Lind }} \end{array}\right) Chrom = g1,1g2,1⋮gNind,1g1,2g2,2⋮gNind,2g1,3g2,3⋮gNind,3⋯⋯⋮⋯g1, Lind g2, Lind ⋮gNind, Lind
种群表现型 Phen:二维矩阵,该数据结构与种群染色体基本一致。染色体编码了个体的遗传信息,而种群表现型则是对染色体进行解码操作得到的在问题空间中的实际表现或解决方案,即决策变量取值。如果采用不需要解码的“实值编码”种群,则这种种群的染色体的每一位对应着决策变量的实际值,此时 Phen 与 Chrom 等价。Phen 的行数为种群的个体数(方案数),列数为决策变量个数,常用符号 Nvar 表示,每一列代表一个决策变量,具体结构如下:
Phen = ( x 1 , 1 x 1 , 2 x 1 , 3 ⋯ x 1 , N v a r x 2 , 1 x 2 , 2 x 2 , 3 ⋯ x 2 , N v a r x 3 , 1 x 3 , 2 x 3 , 3 ⋯ x 3 , N v a r ⋮ ⋮ ⋮ ⋮ ⋮ x N i n d , 1 x N i n d , 2 x N i n d , 3 ⋯ x N i n d , N v a r ) \text { Phen }=\left(\begin{array}{ccccc} x_{1,1} & x_{1,2} & x_{1,3} & \cdots & x_{1, N v a r} \\ x_{2,1} & x_{2,2} & x_{2,3} & \cdots & x_{2, N v a r} \\ x_{3,1} & x_{3,2} & x_{3,3} & \cdots & x_{3, N v a r} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ x_{N i n d, 1} & x_{N i n d, 2} & x_{N i n d, 3} & \cdots & x_{N i n d, N v a r} \end{array}\right) Phen = x1,1x2,1x3,1⋮xNind,1x1,2x2,2x3,2⋮xNind,2x1,3x2,3x3,3⋮xNind,3⋯⋯⋯⋮⋯x1,Nvarx2,Nvarx3,Nvar⋮xNind,Nvar
目标函数值 ObjV:上面的种群表现型Phen的每一行代表了一组决策变量组合(方案),根据这些方案可以计算出每个个体的目标函数值,如下,目标函数值是一个二维数值矩阵,行数为种群个体数量,列数为目标数,如果为单目标问题,ObjV只会有一列,如果为多目标问题,ObjV会有多列。具体结构如下:
Obj V = ( f 1 ( x 1 , 1 , x 1 , 2 , ⋯ x 1 , N v a r ) , f 2 ( x 1 , 1 , x 1 , 2 , ⋯ x 1 , N v a r ) f 1 ( x 2 , 1 , x 2 , 2 , ⋯ x 2 , N v a r ) , f 2 ( x 2 , 1 , x 2 , 2 , ⋯ x 2 , N v a r ) f 1 ( x 3 , 1 , x 3 , 2 , ⋯ x 3 , N v a r ) , f 2 ( x 3 , 1 , x 3 , 2 , ⋯ x 3 , N v a r ) ⋮ f 1 ( x N i n d , x N i n d , 2 , ⋯ x N i n d , N v a r ) , f 2 ( x N i n d , 1 , x N i n d , 2 , ⋯ x N i n d , N v a r ) ) \operatorname{Obj} \mathrm{V}=\left(\begin{array}{c} f_1\left(x_{1,1}, x_{1,2}, \cdots x_{1, N v a r}\right), f_2\left(x_{1,1}, x_{1,2}, \cdots x_{1, N v a r}\right) \\ f_1\left(x_{2,1}, x_{2,2}, \cdots x_{2, N v a r}\right), f_2\left(x_{2,1}, x_{2,2}, \cdots x_{2, N v a r}\right) \\ f_1\left(x_{3,1}, x_{3,2}, \cdots x_{3, N v a r}\right), f_2\left(x_{3,1}, x_{3,2}, \cdots x_{3, N v a r}\right) \\ \vdots \\ f_1\left(x_{Nind }, x_{N i n d, 2}, \cdots x_{Nind , N v a r}\right), f_2\left(x_{N i n d, 1}, x_{N i n d, 2}, \cdots x_{Nind, N v a r}\right) \end{array}\right) ObjV= f1(x1,1,x1,2,⋯x1,Nvar),f2(x1,1,x1,2,⋯x1,Nvar)f1(x2,1,x2,2,⋯x2,Nvar),f2(x2,1,x2,2,⋯x2,Nvar)f1(x3,1,x3,2,⋯x3,Nvar),f2(x3,1,x3,2,⋯x3,Nvar)⋮f1(xNind,xNind,2,⋯xNind,Nvar),f2(xNind,1,xNind,2,⋯xNind,Nvar)
个体适应度 FitnV:Geatpy采用列向量来存储种群个体适应度,每一行对应种群中的一个个体,具体结构如下:
FitnV = ( fit 1 fit 2 fit 3 ⋮ fit Nind ) \text { FitnV }=\left(\begin{array}{c} \text { fit }_1 \\ \text { fit }_2 \\ \text { fit }_3 \\ \vdots \\ \text { fit }_{\text {Nind }} \end{array}\right) FitnV = fit 1 fit 2 fit 3⋮ fit Nind
在许多的文献当中,都提到了最小适应度为0的约定,即适应度值为非负数,主要是为了避免在筛选的时候出现不合理的情况。
违反约束程度 CV:个体方案的适应性除了会考虑目标函数的值之外,还会考虑违反各个约束条件的程度,如下存储一个二维矩阵,列数表示约束条件的个数 num,矩阵元素如果小于或等于0,则表示该元素对应的个体满足对应的约束条件,反之,则表示违反约束条件,且值越大表示违反的程度越高。具体结构如下:
C V = ( c 1 , 1 c 1 , 2 c 1 , 3 ⋯ c 1 , num c 2 , 1 c 2 , 2 c 2 , 3 ⋯ c 2 , num c 3 , 1 c 3 , 2 c 3 , 3 ⋯ c 3 , n u m ⋮ ⋮ ⋮ ⋮ ⋮ c N i n d , 1 c N i n d , 2 c N i n d , 3 ⋯ c N i n d , n u m ) \mathrm{CV}=\left(\begin{array}{ccccc} c_{1,1} & c_{1,2} & c_{1,3} & \cdots & c_{1, \text { num }} \\ c_{2,1} & c_{2,2} & c_{2,3} & \cdots & c_{2, \text { num }} \\ c_{3,1} & c_{3,2} & c_{3,3} & \cdots & c_{3, n u m} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ c_{N i n d, 1} & c_{N i n d, 2} & c_{N i n d, 3} & \cdots & c_{Nind,num} \end{array}\right) CV= c1,1c2,1c3,1⋮cNind,1c1,2c2,2c3,2⋮cNind,2c1,3c2,3c3,3⋮cNind,3⋯⋯⋯⋮⋯c1, num c2, num c3,num⋮cNind,num
2. 入门案例
这里引用Geatpy的官方入门案例,采用增强精英保留策略的遗传算法求解,问题如下:
min f ( x 1 , x 2 , x 3 , x 4 , x 5 ) = ( x 1 − 1 ) 2 + ( x 2 − 1 ) 2 + … + ( x 5 − 1 ) 2 s.t. ( x 1 − 0.5 ) 2 ≤ 0.25 ( x 1 − 1 ) 2 ≤ 1 − 1 ≤ x 1 ≤ 1 0 ≤ x 2 ≤ 4 1 ≤ x 3 ≤ 5 1 ≤ x 4 ≤ 2 1 ≤ x 5 ≤ 1 \begin{array}{ll} \min f\left(x_1, x_2, x_3, x_4, x_5\right)= & \left(x_1-1\right)^2+\left(x_2-1\right)^2+\ldots+\left(x_5-1\right)^2 \\ \text { s.t. } & \left(x_1-0.5\right)^2 \leq 0.25 \\ & \left(x_1-1\right)^2 \leq 1 \\ & -1 \leq x_1 \leq 1 \\ & 0 \leq x_2 \leq 4 \\ & 1 \leq x_3 \leq 5 \\ & 1 \leq x_4 \leq 2 \\ & 1 \leq x_5 \leq 1 \end{array} minf(x1,x2,x3,x4,x5)= s.t. (x1−1)2+(x2−1)2+…+(x5−1)2(x1−0.5)2≤0.25(x1−1)2≤1−1≤x1≤10≤x2≤41≤x3≤51≤x4≤21≤x5≤1
其中,
x
1
,
x
2
.
.
.
x
5
x_1,x_2...x_5
x1,x2...x5 为决策变量。有如下三种写法来调用 Geatpy 求解,但思路都是一致,先创建problem问题,再构建algorithm算法,接着调用optimize() 进行求解。
2.1 带装饰器的“求解器模式”写法
具体如下代码。在定义目标函数时,加了装饰器 @ea.Problem.single,此时传入的参数 Vars 为创建问题当中的变量,可以把它的结构视为列表。在定义目标函数的同时,也计算约束违反程度 CV,将该自定义函数传入 ea.Problem() 当中,相当于实例化了一个新的对象 problem,接着再基于算法类实例化 algorithm 对象,调用 ea.optimize() 方法求解,返回的 res 包含求解状态和解的信息。
import geatpy as ea
import numpy as np
# 构建问题
@ea.Problem.single
def evalVars(Vars): # 定义目标函数(含约束)
f = np.sum((Vars - 1) ** 2) # 计算目标函数值
x1 = Vars[0]
x2 = Vars[1]
CV = np.array([(x1 - 0.5)**2 - 0.25,
(x2 - 1)**2 - 1]) # 计算违反约束程度
return f, CV
problem = ea.Problem(name='soea quick start demo',
M=1, # 目标维数
maxormins=[1], # 目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标
Dim=5, # 决策变量维数
varTypes=[0, 0, 1, 1, 1], # 决策变量的类型列表,0:实数;1:整数
lb=[-1, 1, 2, 1, 0], # 决策变量下界
ub=[1, 4, 5, 2, 1], # 决策变量上界
evalVars=evalVars)
# 构建算法
algorithm = ea.soea_SEGA_templet(problem,
ea.Population(Encoding='RI', NIND=20),
MAXGEN=50, # 最大进化代数。
logTras=1, # 表示每隔多少代记录一次日志信息,0表示不记录。
trappedValue=1e-6, # 单目标优化陷入停滞的判断阈值。
maxTrappedCount=10) # 进化停滞计数器最大上限值。
# 求解
res = ea.optimize(algorithm, seed=1, verbose=True, drawing=1, outputMsg=True, drawLog=False, saveFlag=True, dirName='result')
2.2 传入二维数组的“求解器模式”写法
上面的写法通过加装饰器 @ea.Problem.single 使得传入的变量信息可以视为列表结构,如果不加该装饰器,则函数传入的 Vars 是一个二维数组,行数为种群数量 NIND=20,列数为决策变量数量 Dim=5。其余部分的写法一致,相比于前一种写法没那么直观。
def evalVars(Vars): # 定义目标函数(含约束)
ObjV = np.sum((Vars - r) ** 2, 1, keepdims=True) # 计算目标函数值
x1 = Vars[:, [0]] # 把Vars的第0列取出来
x2 = Vars[:, [1]] # 把Vars的第1列取出来
CV = np.hstack([(x1 - 0.5) ** 2 - 0.25,
(x2 - 1) ** 2 - 1]) # 计算违反约束程度
return ObjV, CV # 返回目标函数值矩阵和违反约束程度矩阵
2.3 “面向对象”的写法
前两种写法都是通过 ea.Problem() 方法实例化一个 problem 对象,其实换个思路,就是自建一个类,这个类继承自 ea.Problem,通过传入自定义参数来初始化父类达到创建自定义类的目的(本质与前两种方法是一模一样的),并在类当中重写 evalVars() 方法。具体代码如下:
class MyProblem(ea.Problem):
def __init__(self):
name = "soea quick start demo"
M = 1
maxormins = [1]
Dim = 5
varTypes = [0, 0, 1, 1, 1]
lb = [-1, 1, 2, 1, 0]
ub = [1, 4, 5, 2, 1]
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub)
def evalVars(self, Vars):
ObjV = np.sum((Vars - 1) ** 2, 1, keepdims=True)
x1 = Vars[:, [0]]
x2 = Vars[:, [1]]
CV = np.hstack([(x1 - 0.5) ** 2 - 0.25, (x2 - 1) ** 2 - 1])
return ObjV, CV
problem = MyProblem()
由于ea.Problem 类初始化时必须有参数 name, M, maxormins, Dim, varTypes, lb, ub,因此先定义了这些局部变量之后,再传入到父类当中进行初始化。
至此,对Geatpy做了简单的应用式介绍,要了解更多的相关内容可以查阅Geatpy2的官网:http://geatpy.com/index.php/home/
















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











