






——虽迟但到
一、实现逻辑回归的梯度下降
为了使模型达到最佳效果,我们需要让成本函数越低越好,这时我们就再次用到了我们的梯度下降法,不妨就看看如何进行。

上图是通常的梯度下降算法,而我们展开后就会得到以下的式子

其中阿尔法是学习率,后面的是J的导数。类似于线性回归,我们采取同步更新的方法,先计算等号右侧,然后覆盖左侧的值,尽管编写的算法逻辑回归和线性回归看上去是类似的,但是它们是两种截然不同的算法,因为对于f(x)的定义是不一样的。我们在这里也可以大量使用矢量化使梯度下降的速度加快,在逻辑回归里面,我们也可利用特征缩放,来使得梯度下降的速度变快。
好的那么我们就学会逻辑回归算法了(bushi)
二、过拟合与欠拟合问题
我们已经学会了线性回归和逻辑回归,而在线性回归和逻辑回归的过程中,我们可能遇到这样那样的问题,其中就有过拟合问题以及欠拟合问题,这会使我们的模型表现不佳,我们可以利用正则化来解决过拟合问题,并且让我们的算法更好的工作。
倘若算法有非常强烈的先入之见,以及对某种归纳有着偏好,那么就会与实际的结果出现偏差,我们称之为欠拟合。光文字是难以表述的,如图:

虽然用一元线性回归也能拟合出来,明显还是右侧的函数模型更好,我们称左侧的模型为欠拟合。

当我们选取一个函数模型完美的通过每一个数据点时,我们的成本函数一直是零,但是我们得到的是一个非常摇摆不定的曲线,看上去没有任何的规律,我们称这种情况为过拟合。过拟合通常有很大的方差。
我们希望得到的模型是一个既没有高偏差又没有高方差的模型。
三、如何解决过拟合问题

倘若我们得到了一个过拟合的模型,要想解决过拟合的这种情况,我们就必须想办法。一种办法是增加训练的数据,以获得更好的模型,像这样:

解决过度拟合的第二个方法是观察是否可以用更少的特征来描述模型,即减少我们的变量,或者说减少向量 中元素的数量。这样会让我们的函数曲线变得更加的平滑、合理。我们称这种方法叫做特征选择,特征选择的一种方法是凭我们的直觉选出影响函数最多的特征集,即什么和我们的预测结果是最相关的。特征选择的一个缺点是我们选用的是特征的一个子集,这样我们会丢失一些对特征有用的信息。这使我们需要合适的方法来自动选择我们的特征集。
中元素的数量。这样会让我们的函数曲线变得更加的平滑、合理。我们称这种方法叫做特征选择,特征选择的一种方法是凭我们的直觉选出影响函数最多的特征集,即什么和我们的预测结果是最相关的。特征选择的一个缺点是我们选用的是特征的一个子集,这样我们会丢失一些对特征有用的信息。这使我们需要合适的方法来自动选择我们的特征集。
这就引出了我们解决过拟合的第三种方法,我们的正则化,正则化是一种更温柔的方式,用于减少某一特征对整体模型的影响,而不是暴力的抹除这一个特征。正则化的特征是鼓励算法尽可能的缩小我们的函数的参数,像这样:

四、正则化的具体实现
正则化的具体思路是:参数越少,模型越简单。特征变少,过拟合的可能性变少。
正则化的实现方式通常是惩罚所有的特征,那么什么是惩罚呢?
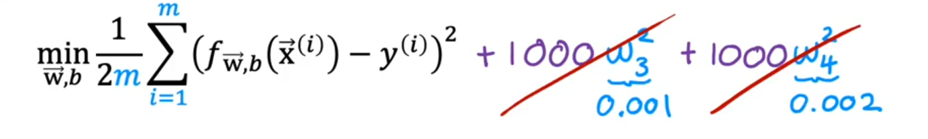
惩罚的规则是对我们的代价函数(成本函数)增加特征变量,若想使成本函数尽可能的变小,那么上图的W3和W4就要尽可能的变小。

那么我们就得到了关于正则化的式子,如上图,公式插入太难了,还是截图方便【嘿嘿嘿
其中的 我们称之为正则化参数,与选择学习率阿尔法类似,我们也需要选择一个合适的,那么我们的代价函数就变成了两部分
我们称之为正则化参数,与选择学习率阿尔法类似,我们也需要选择一个合适的,那么我们的代价函数就变成了两部分

均方误差代价以及正则化
倘若我们选取的非常小,那么将会出现过拟合现象,而非常大的时候,拟合出来的函数又会接近一个直线。因此我们需要选取一个合适的值















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









