







一. 前言
1. 说明
我们平时所说的:聚集索引(主键索引),次要索引,覆盖索引,复合索引,前缀索引,唯一索引在MySQL5.7和 8.0版本默认都是使用B+Tree索引,除此之外还有 Hash索引。至于MySQL5.7之前版本,这里就不过多探究了。
学习各种数据结构图解网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html (推荐)
2. 有索引和没索引的区别
下图,左边表格是没有索引,右边是二叉树索引,以col2为索引列.
PS: 在右边二叉树的结构中,每个节点都是 key-value 键值对的形式。key:col2所在行在磁盘文件中的地址指针(比如 34 所在行,通过key中存储 0x07 这个指针就能找到是第1行),value:就是col2的值。
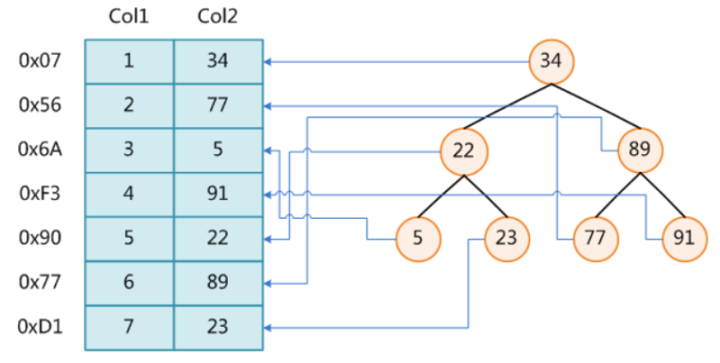
分析下面SQL语句
select * from t where col2 = 89;
(1). 左边没有索引,搜索col2=89需要从上往下搜索, 6次 才能找到,也就是 6次回表操作(6次IO)。
(2). 右边是二叉树索引,搜索col2=89搜索 2次 就可以找到,也就是 2次回表操作(2次IO),性能提升明显。
二. 二叉树、红黑树、Hash
1. 二叉树
(1). 二叉树的特点
左子节点值 < 节点值;右子节点值 > 节点值;当数据量非常大时,要查找的数据又非常靠后,和没有索引相比,那么二叉树结构的查询优势将非常明显。
(2). 存在的问题
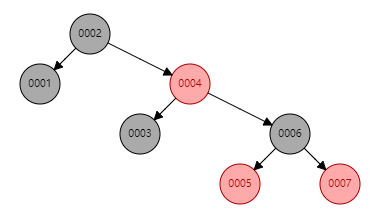
如下图,可以看出,二叉树出现单边增长时,二叉树变成了“链”,这样查找一个数的时候,速度并没有得到很大的优化。

2. 红黑树
(1). 特点
A. 节点是红色或者黑色
B. 根节点是黑色
C. 每个叶子的节点都是黑色的空节点(NULL)
D. 每个红色节点的两个子节点都是黑色的。
E. 从任意节点到其每个叶子的所有路径都包含相同的黑色节点。
(2). 存在的问题
红黑树虽然和二叉树相比,一定程度上缓解了单边过长的问题,但是它依旧存储高度问题。
假设现在数据量有100万,那么红黑树的高度大概为 100,0000 = 2^n, n大概为 20。那么,至少要20次的磁盘IO,这样,性能将很受影响。如果数据量更大,IO次数更多,性能损耗更大。所以红黑树依旧不是最佳方案。
(3). 思考:针对上面的红黑树结构,我们能否优化一下呢?
上述红黑树默认一个节点就存了一个 (索引+磁盘地址),我们设想一个节点存多个 (索引+磁盘地址),这样就可以降低红黑树的高度了。 实际上我们设想的这种结构就是 B-Tree。
3. Hash
(1). 原理
A. 事先将索引通过 hash算法后得到的hash值(即磁盘文件指针)存到hash表中。
B. 在进行查询时,将索引通过hash算法,得到hash值,与hash表中的hash值比对。通过磁盘文件指针,只要一次磁盘IO就能找到要的值。
例如:
在第一个表中,要查找col=6的值。hash(6) 得到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









