







这是参加datawhale的学习打卡活动的学习笔记,这次内容是表的变形。
链接: http://joyfulpandas.datawhale.club/Content/%E5%8F%82%E8%80%83%E7%AD%94%E6%A1%88.html
文章目录
长宽表的变形
pivot
pivot 是一种典型的长表变宽表的函数。
对于一个基本的长变宽操作而言,最重要的有三个要素,分别是变形后的行索引、需要转到列索引的列,以及这些列和行索引对应的数值,它们分别对应了 pivot 方法中的 index, columns, values 参数。新生成表的列索引是 columns 对应列的 unique 值,而新表的行索引是 index 对应列的 unique 值,而 values 对应了想要展示的数值列。
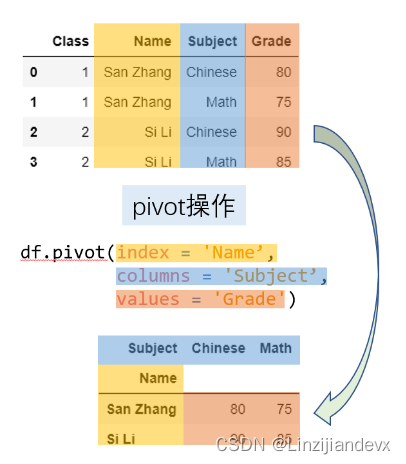
利用 pivot 进行变形操作需要满足唯一性的要求,即由于在新表中的行列索引对应了唯一的 value,因此原表中的 index 和 columns 对应两个列的行组合必须唯一。例如,现在把原表中第二行张三的数学改为语文就会报错,这是由于 Name 与 Subject 的组合中两次出现 (“San Zhang”, “Chinese”) ,从而最后不能够确定到底变形后应该是填写80分还是75分。
pivot_table
pivot 的使用依赖于唯一性条件,那如果不满足唯一性条件,那么必须通过聚合操作使得相同行列组合对应的多个值变为一个值。例如,张三和李四都参加了两次语文考试和数学考试,按照学院规定,最后的成绩是两次考试分数的平均值,此时就无法通过 pivot 函数来完成。
pandas 中提供了 pivot_table 来实现,其中的 aggfunc 参数就是使用的聚合函数。
melt
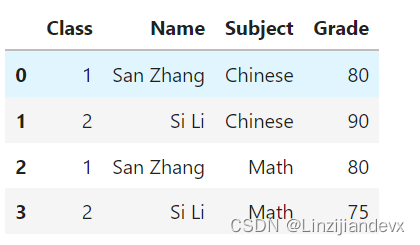
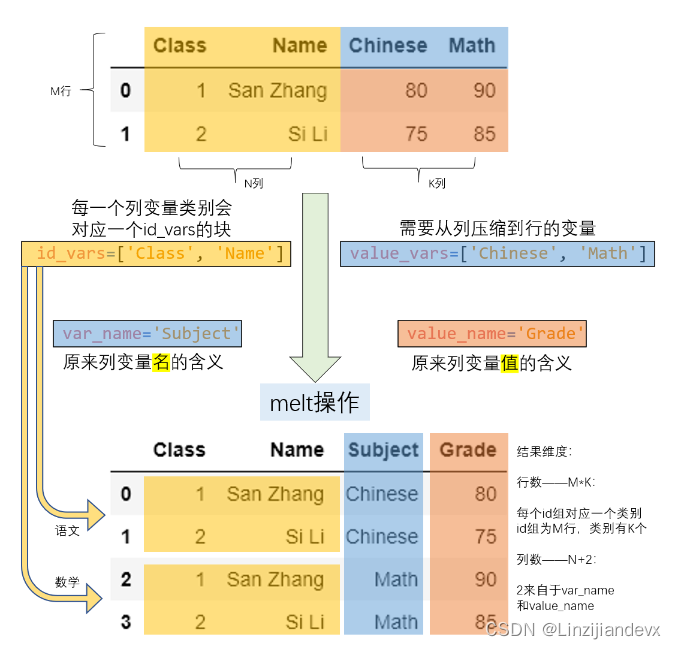
长宽表只是数据呈现方式的差异,但其包含的信息量是等价的,前面提到了利用 pivot 把长表转为宽表,那么就可以通过相应的逆操作把宽表转为长表, melt 函数就起到了这样的作用。在下面的例子中, Subject 以列索引的形式存储,现在想要将其压缩到一个列中。
df = pd.DataFrame({
'Class':[1,2],
'Name':['San Zhang', 'Si Li'],
'Chinese':[80, 90],
'Math':[80, 75]})
out

df_melted = df.melt(id_vars = ['Class', 'Name'],
value_vars = ['Chinese', 'Math'],
var_name = 'Subject',
value_name = 'Grade')
out
melt 的主要参数和压缩的过程如下图所示:
wide_to_long
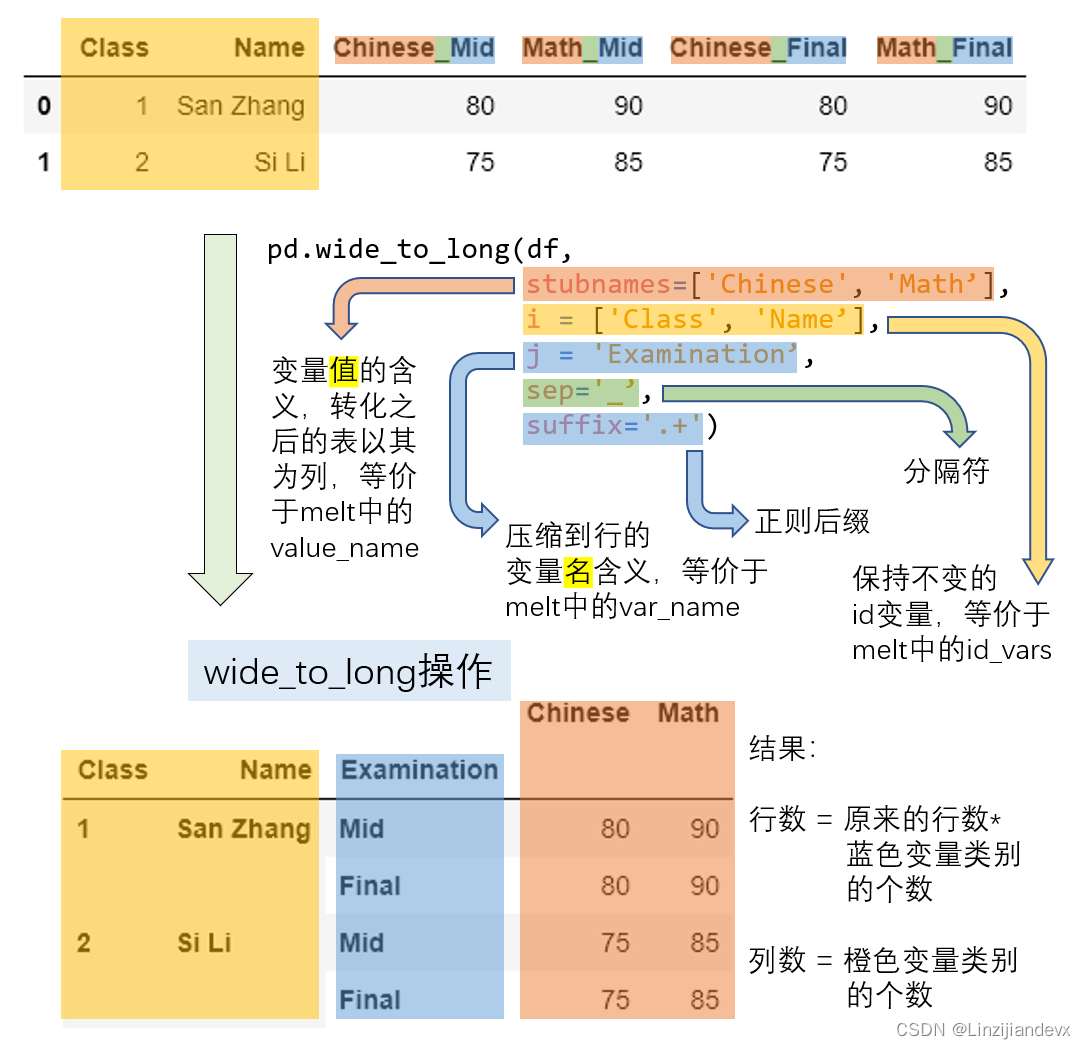
df = pd.DataFrame({
'Class':[1,2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









