






卷积神经网络
我们人类在看到某件事物并对其进行辨别时,会自动地去寻找特征,比如根据长的鼻子判断动物是大象,根据长的耳朵判断动物是兔子,根据直的笔画来判断字母为X,根据弯的笔画判断字母为O。我们在辨别一张图像时,会不自觉地根据其局部来进行判断。

以字母X为例,我们可以发现其具有三种典型的局部特征:1.向右下的直线。2.向左下的直线。3.十字交叉的直线。
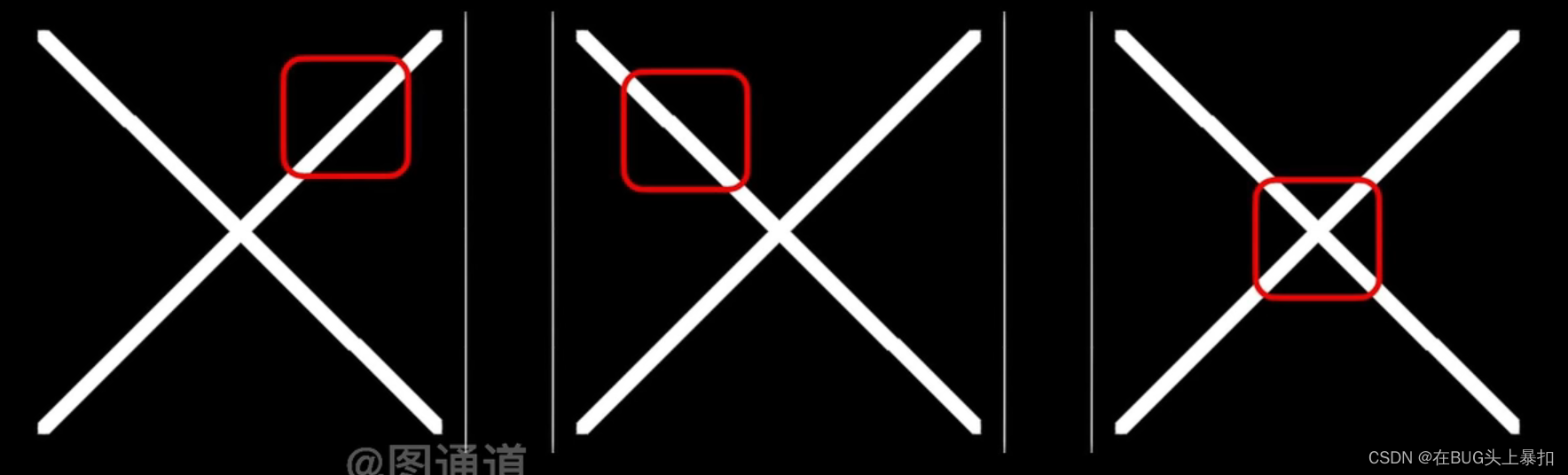
观察到这种特征后,我们使用数学中的矩阵来尝试表示这张图片。
将原始图片,用1表示白色,-1表示灰色表示为一个由1,-1组成的矩阵。

卷积层
卷积核
我们分别构造,符合上述3个独特特征的三个小矩阵。
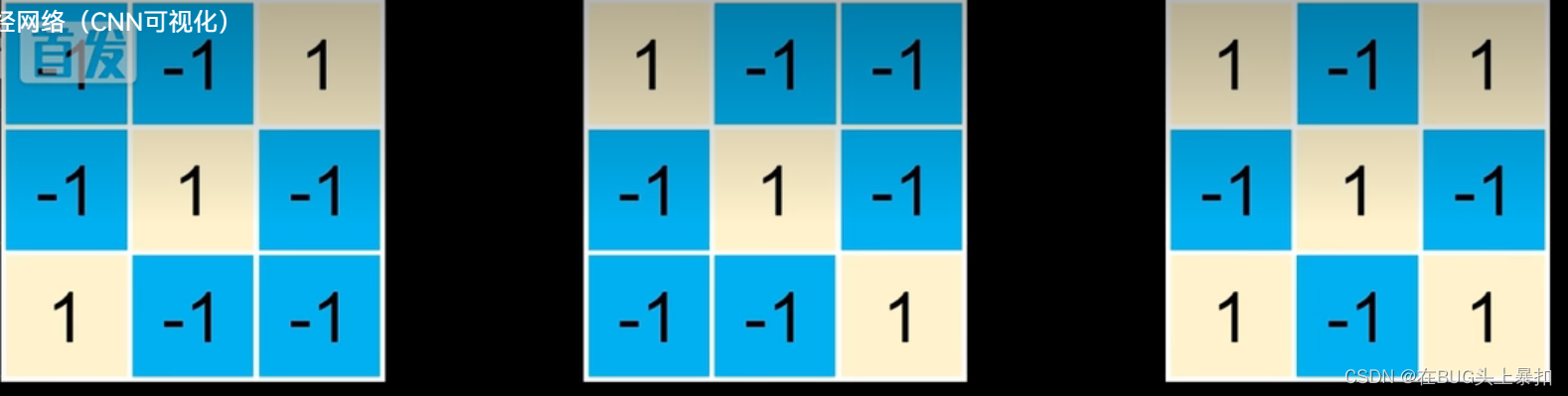
这种表示特征的小矩阵我们称之为:“卷积核”
卷积核的选择
注意卷积核的选择并不是越大越好。原因有以下两点:
-
多层小卷积核堆叠可以和大卷积核有一样的感受野,但小卷积核的参数和计算量更少;(更经济)
-
多层小卷积核堆叠相较于大卷积核可以引入更多的非线性。(效果更好)

原理
用卷积核扫描原有的图像,将对应位置的元素相乘后在相加(线性代数:矩阵乘法)。然后用一个新的矩阵(比原来矩阵元素数少)记录计算后的值。这个操作就叫做卷积。
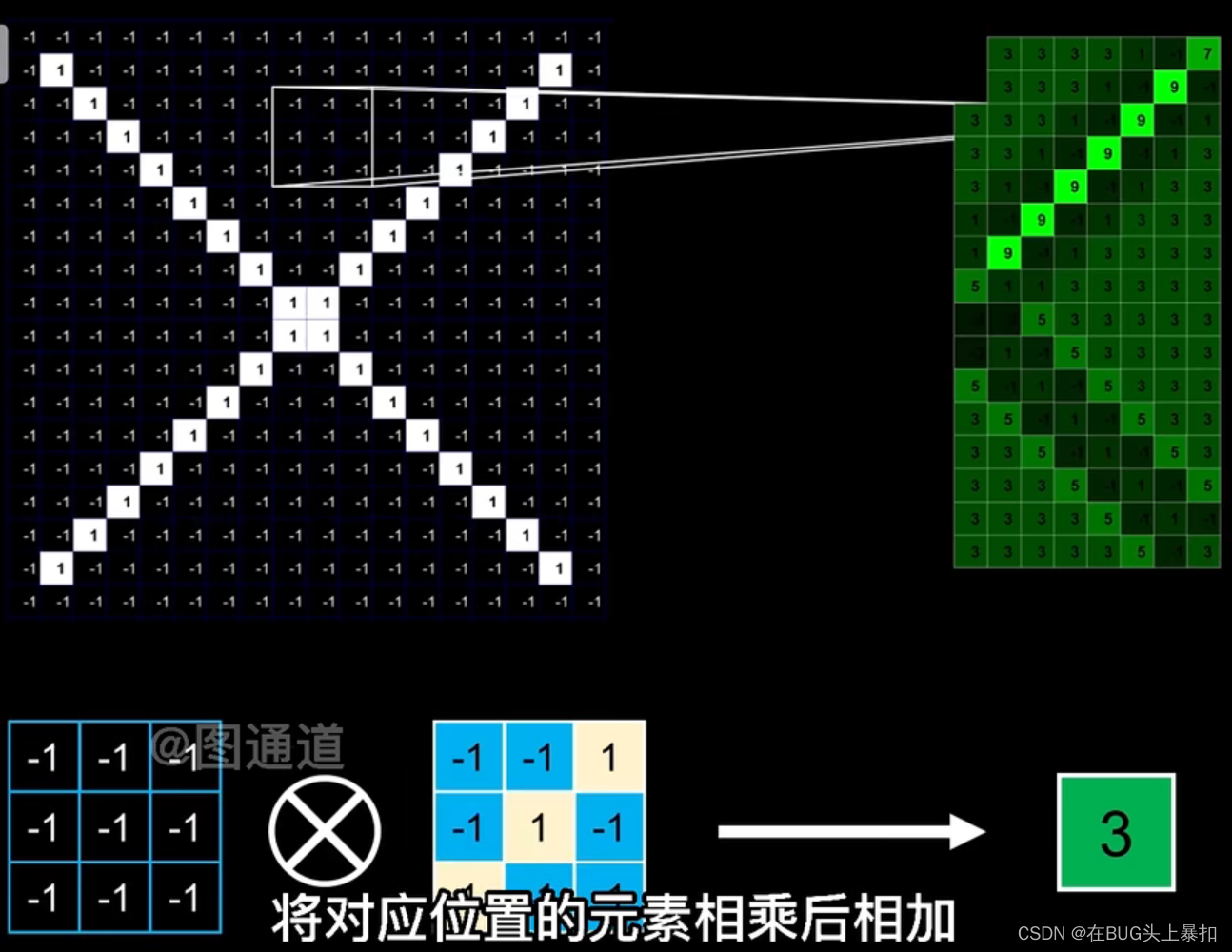
在卷积操作中,当某个位置与卷积核的特征越相近时,该位置计算得到的值就越大。 在结果图像中的颜色越亮,这样该特征就大概的被提取出来了。
单个卷积核一般处理单个特征。对于一幅图像中的多个特征,可以采用多个卷积核。
BN层
Batch Normalization操作,在每次卷积后对结果进行归一化。详情见下链接
https://www.cnblogs.com/guoyaohua/p/8724433.html
池化操作
卷积虽然让组成图像的矩阵变得小了一些,但由于要进行复杂的运算,所以还是要对卷积操作生成的图像进行压缩降维。这就是池化操作。
原理
对一块区域(一般为2*2)内的结果取等效值。 可以是取最大值,也可以是取平均值。
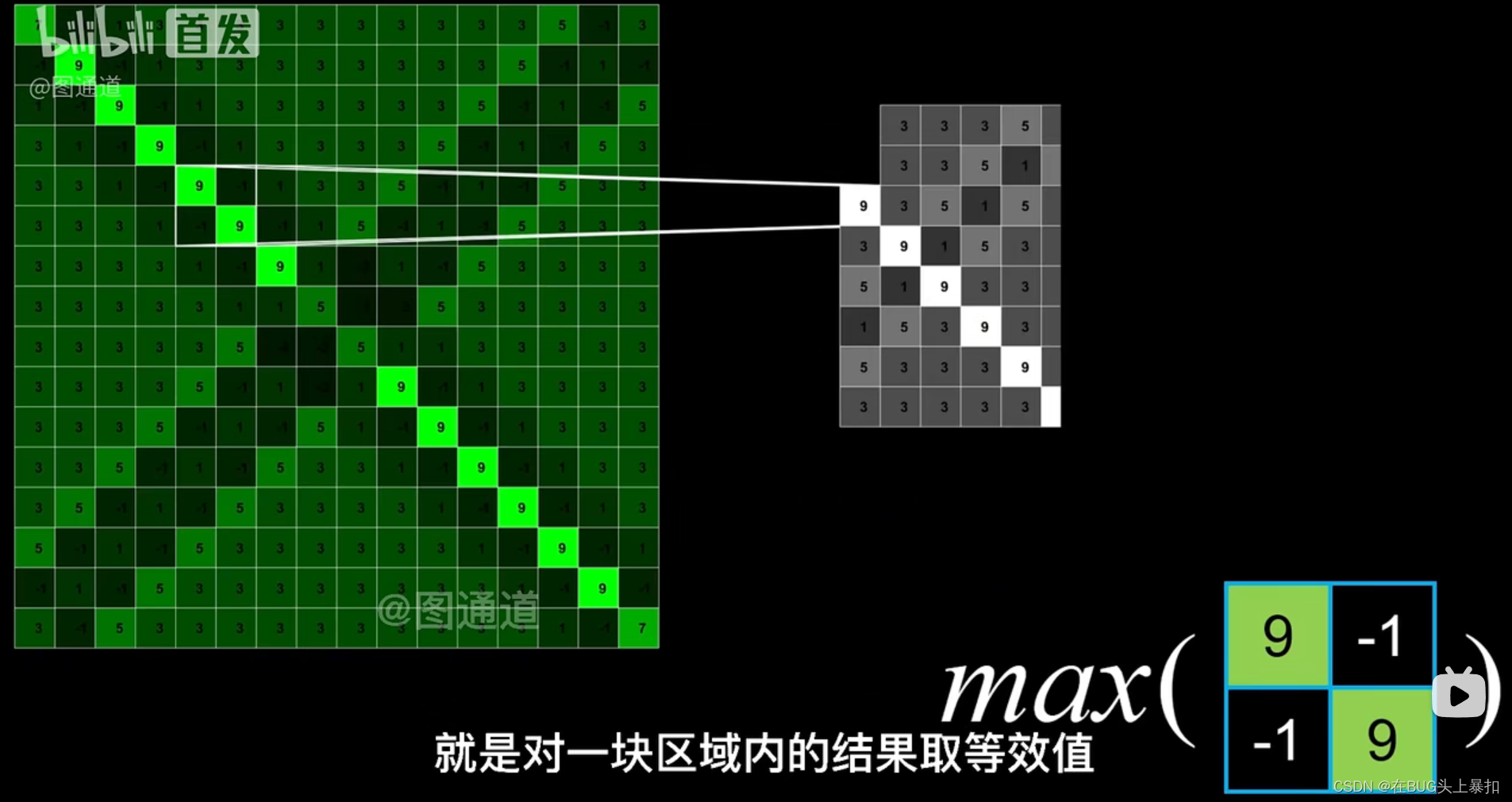
经过池化后,图像的大小会显著地降低。池化能够大幅提高运算速度,也能够很大程度避免过拟合的发生。 提高神经网络的泛化能力。
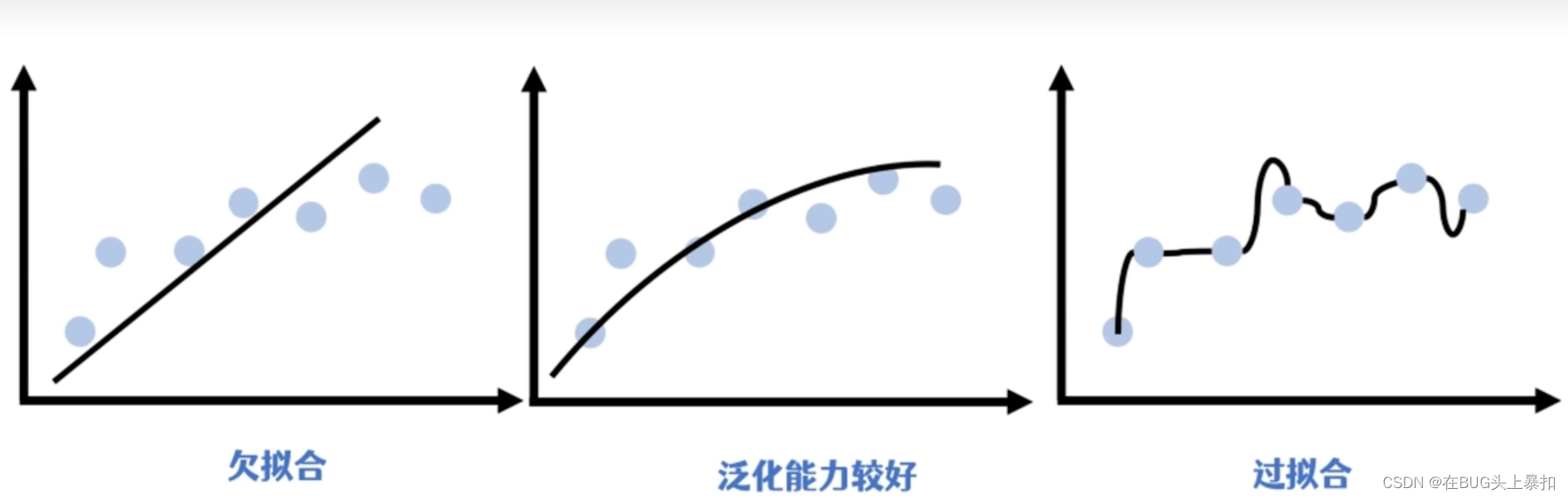
可以进行池化的原因
由于图像中的相邻像素倾向于具有相似的值。因此通常卷积层相邻的输出像素也具有相似的值。这意味着卷积层输出的大部分信息都是冗余的。池化层解决的就是这个问题。
理解池化操作
对于网络结构而言,上面的层看下面的层经过pooling(池化)后传上来的特征图,就好像在太空上俯瞰地球,看到的只有山脊和雪峰。这即是对特征进行宏观上的进一步抽象。
那么为什么需要 进行抽象 呢?
因为:经过池化后,得到的是 概要统计特征 。它们不仅 具有低得多的维度 (相比使用所有提取得到的特征),同时还会 改善结果(不容易过拟合) 。
常用的池化
-
max_pooling: 夜晚的地球俯瞰图,灯光耀眼的穿透性让人们只注意到最max的部分,产生亮光区域被放大的视觉错觉。故而 max_pooling 对较抽象一点的特征(如纹理)提取更好。
-
average_pooling: 白天的地球俯瞰图,幅员辽阔的地球表面,仿佛被经过了二次插值的缩小,所有看到的都是像素点取平均的结果。故而 average_pooling 对较形象的特征(如背景信息)保留更好。
选用 max_pooling 还是 average_pooling ,要看需要识别的图像细节特征情况。知乎上说二者差异不会超过2%。相比之下, max_pooling 是比 average_pooling 更抽象化的操作,因此可以抽象出更高级一点的特征。
缺点以及解决办法
由于pooling太过粗暴,操作复杂,目前业界已经逐渐放弃了对pooling的使用。替代方案如下:
采用 Global Pooling 以简化计算;
增大conv的 stride 以免去附加的pooling操作。
激活层(激活函数)
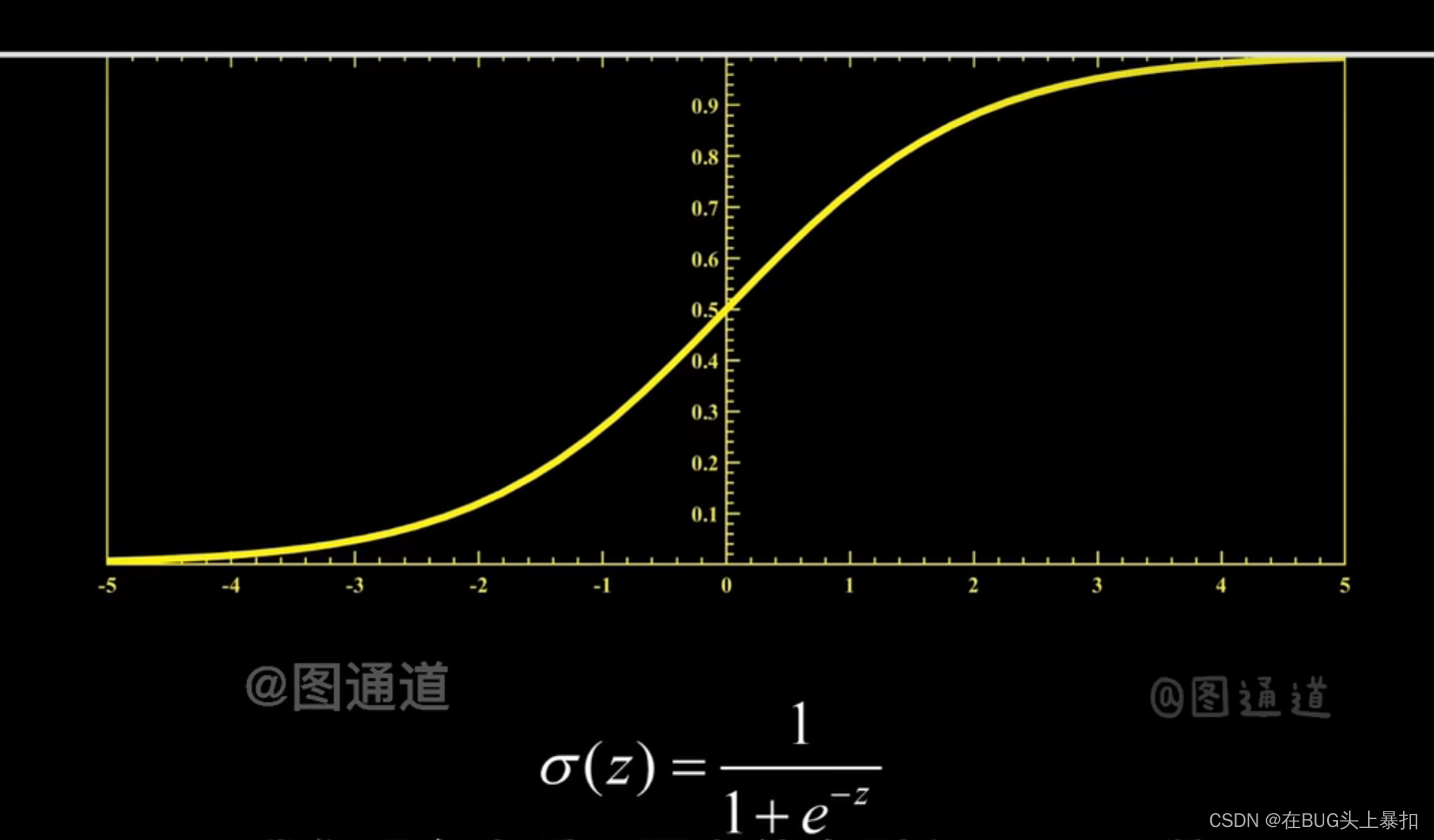
激活层主要对卷积层的输出进行一个非线性的映射,目前在CNN中采用的激活函数大部分为Relu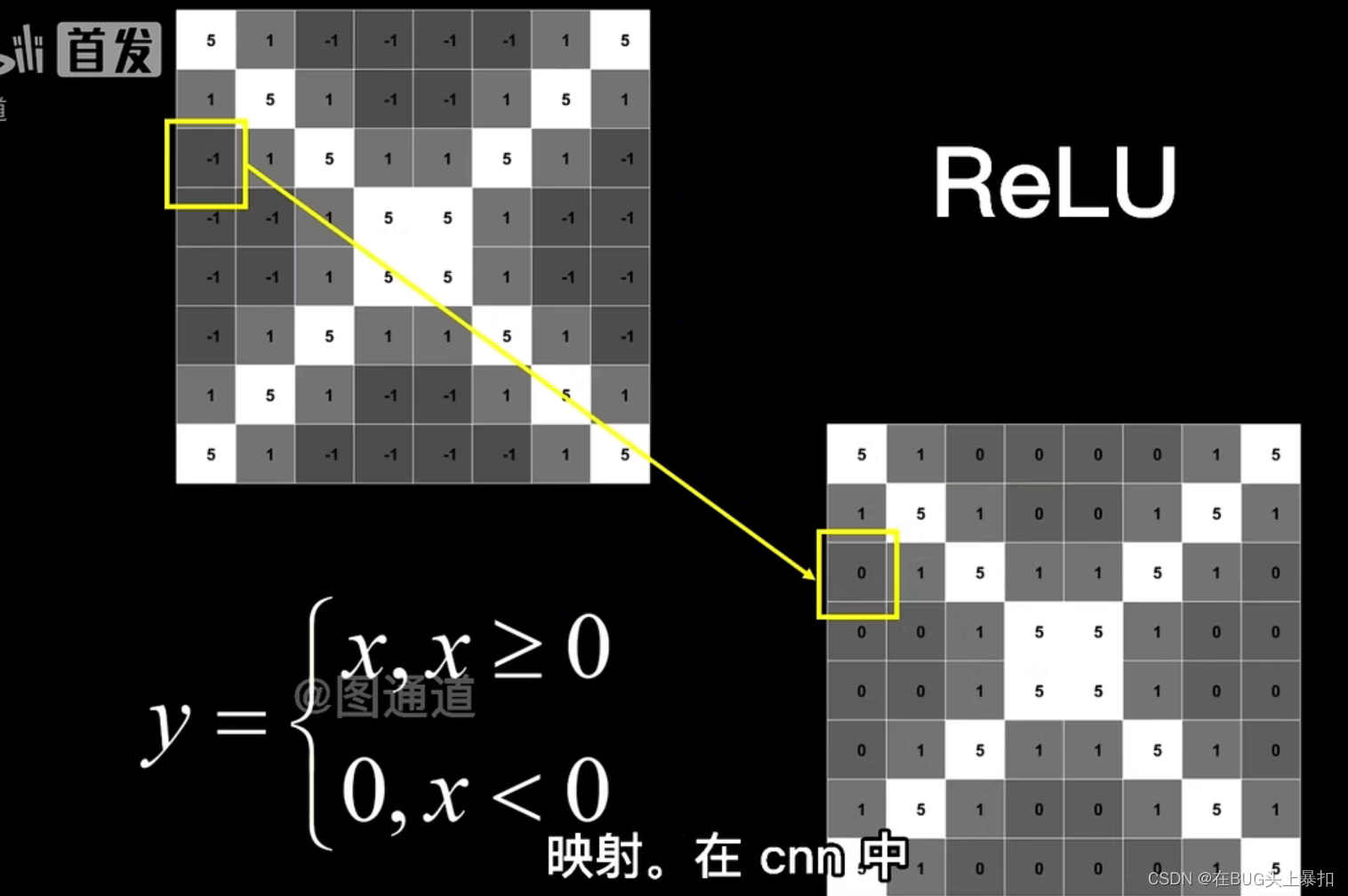
进行非线性映射的原因是为了使得多层的神经网络有着实际的意义。若不进行非线性映射,则无论多少层现行的映射,都会与单层感知机等效。
全连接层
最后我们可以将最终的得到的图像展成一维后输入全连接神经网络进行训练。(注:在某些模型如YOLO V2中 采用卷积的方式代替全连接操作)
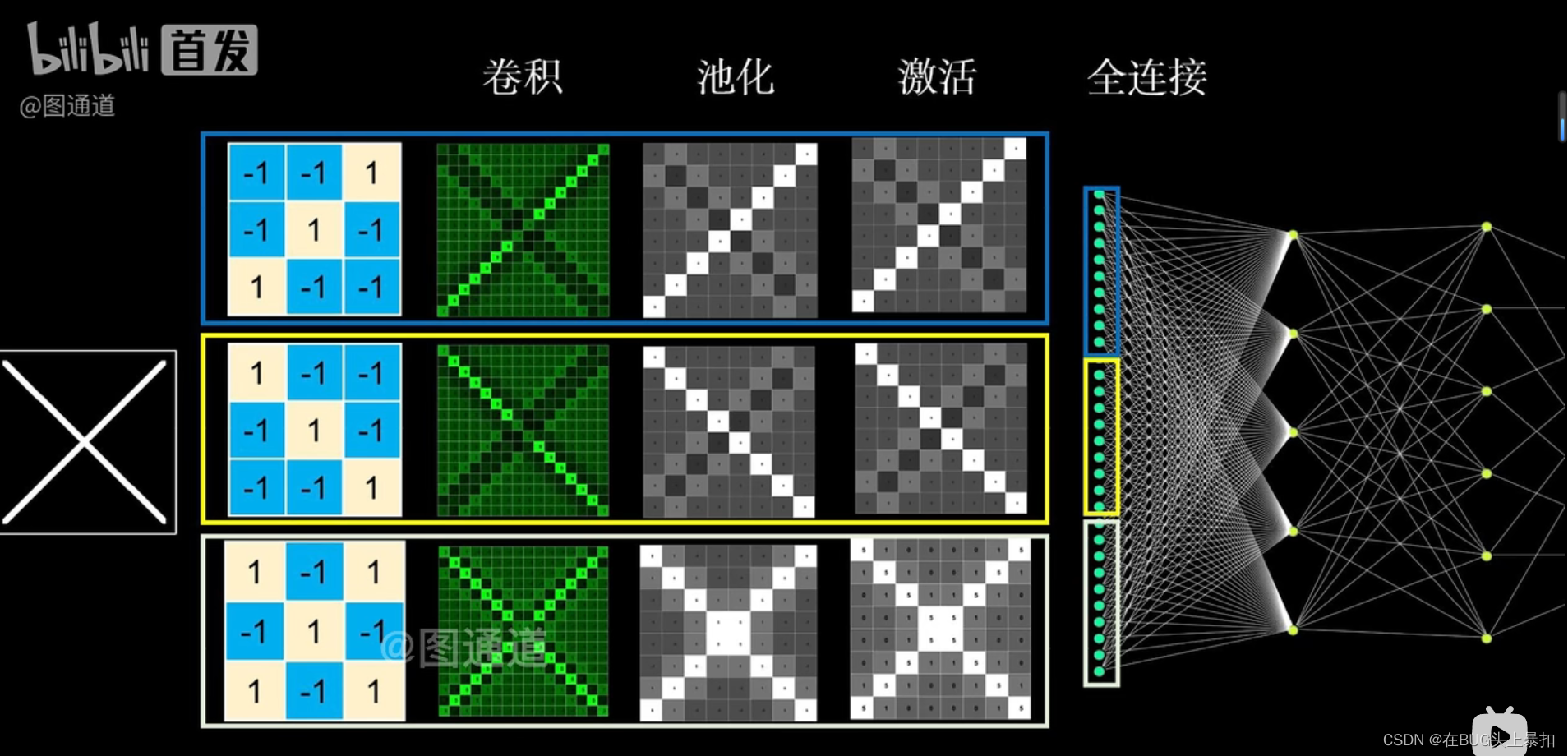
总结
卷积神经网络就是用卷积、池化、激活等操作代替全连接神经网络中的运算,注意这种替代可以是全部的也可以是部分的。















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









