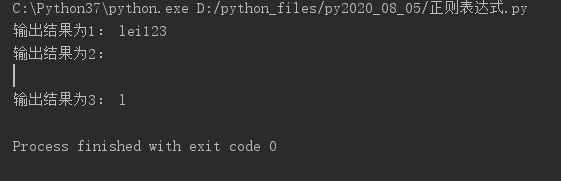
import re
res = re.match("^lei\d+","lei123 wodeshebao")
print("输出结果为1:",res.group())
res1 = re.match(".","\nlei123 wodeshebao",flags=re.DOTALL)
print("输出结果为2:",res1.group())
res2 = re.match(".","lei123 wodeshebao")
print("输出结果为3:",res2.group())
输出结果为:
res3 = re.match("^ab","abc\nleizi",flags=re.MULTILINE)
print(res3.group())
res4 = re.search("wo$","Iwo\nsadif",flags=re.MULTILINE).group()
print(res4)
res5 = re.findall("abc*","abcccsd ab9ji abc4dghf")
print(res5)
res6 = re.findall("ab+","abbhiiog abjii ajf")
print(res6)
res7 = re.findall("ab?","ajjf abjjk abbc")
print(res7)
res8 = re.search(r"ab{3}","abbbm ababbbnn abcm am").group()
print(res8)
res9 = re.search("(abc){2}ad(12|34)c","abcabcad34c").group()
print(res9)
str1 = re.search("\Aabc","abclexabc")
print(str1)
str2 = re.search("ab$","abvfggab").group()
print(str2)
str3 = re.search("\d","wefftg3kkgh2")
print(str3)
str4 = re.search("\D+","ashj12234fd2345").group()
print(str4)
str5 = re.search("\w+","D98asji&@jgif87").group()
print(str5)
str6 = re.search("\W+","D98asji&@jgif87").group()
print(str6)
str7 = re.search("\s+","ab\tdd\noi").group()
print(str7,"前面是匹配结果")
re–groupdict用法、split用法、sub替换用法
result = re.search("(?P<id>[0-9]+)(?P<name>[a-zA-Z]+)","abc123leiyu@12345").groupdict()
print(result)
print(result["id"])
result1 = re.search("(?P<id>[0-9]+)(?P<name>[a-zA-Z]+)","abc123leiyu@12345").group("name")
print(result1)
result2 = re.search("(?P<province>[0-9]{3})(?P<city>[0-9]{3})(?P<birthday>[0-9]{4})","410423199909264687").groupdict()
print(result2)
result3 = re.split("[0-9]","wo12de3she678bao")
print(result3)
result4 = re.split("[0-9]+","wo12de3she678bao")
print(result4)
result6 = re.sub("[0-9]+","=","wq12hgh8mmww56ssaa")
print(result6)
result7 = re.sub("[0-9]+","=","wq12hgh8mmww56ssaa",count=2)
print(result7)
反斜杠匹配
result8 = re.search("\\\\","wq12hg\h8mmww56ssaa").group()
print(result8)
flags的用法
num2 = re.search("[a-z]+","asDjWnQ").group()
print("添加flags前结果",num2)
num1 = re.search("[a-z]+","asDjWnQ",flags=re.I).group()
print("添加flags后结果",num1)
num3 = re.search("^a","\nasd23",flags=re.M).group()
print(num3)
num4 = re.search("^a","\nasd23").group()
print(num4)
num5 = re.search("^.+","\nabc\nhgf").group()
print(num5)
num6 = re.search("^.+","\nabc\nhgf",flags=re.S).group()
print(num6)























 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









