










这个问题搞了我几天终于解决了,搜遍网上基本没有详细针对TrueNas Scale部署immich应用后,CLIP模型镜像下载超时导致人脸识别失败,以及更换支持中文识别的CLIP模型的博客。
注意:Dragonfish 24.04.2.5版本及以下老版本基于k3s,Electric Eel 24.10.1版本及以上新版本基于docker
分析
现象:TrueNas Scale安装immich官方镜像应用后,导入图片人脸识别失败,中文识别更不行,查看immich-machinelearning pod后台调用日志,显示huggingface.co无法访问,导致下载模型失败。
方案
下载模型文件,手动上传到pod的模型缓存文件夹中,然后设置对应的模型名称,保存后重新识别图片即可。
【关键信息】:TrueNas Scale安装immich应用后mmich-machinelearning pod的默认模型缓存文件路径为:
/mlcache/clip与/mlcache/facial-recognition
此方案是上传到pod中CLIP模型文件的缓存目录下,如果pod被销毁需要重新上传覆盖模型文件到缓存目录
1. TrueNas Scale开启SMB共享,为本地文件上传到宿主机做准备,自行下载XLM-Roberta-Large-Vit-B-16Plus以及buffalo_l模型,并上传到TrueNas文件夹
模型数据对比,感觉XLM-Roberta-Large-Vit-B-16Plus模型好点,支持多语言,包括中文
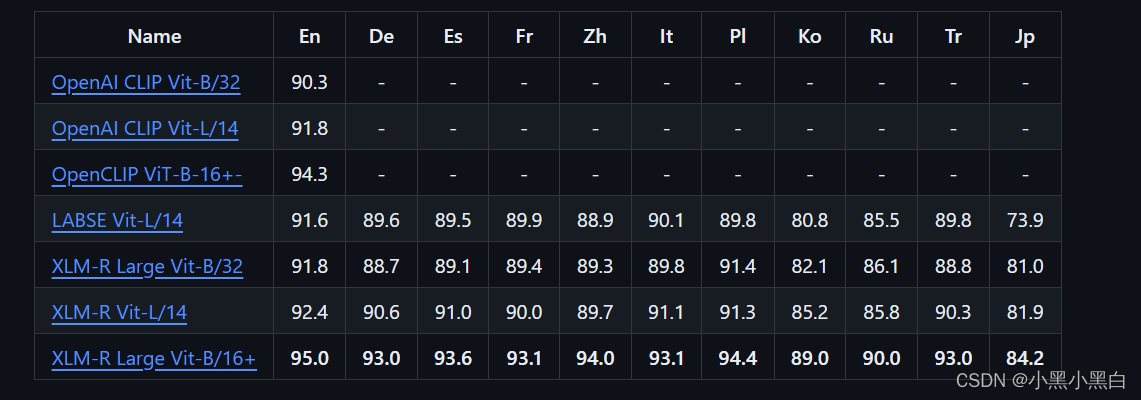
官方默认的immich-app/ViT-B-32__openai模型只支持英文,这里顺便切换成XLM-Roberta-Large-Vit-B-16Plus模型。
贴下immich的官方镜像站https://huggingface.co/immich-app
国内镜像站:https://hf-mirror.com/immich-app
2. 登录TrueNas Scale后台,进入命令行,切换root账号,上传模型文件到pod中
上传前,确保当前immich没有执行的JOB。
上传模型文件之前:
【重要】选择应用-选择immich-工作负载-选择immich-machine-learning容器的日志图标-打开-查看是否有日志刷新
确认后再执行模型文件推送
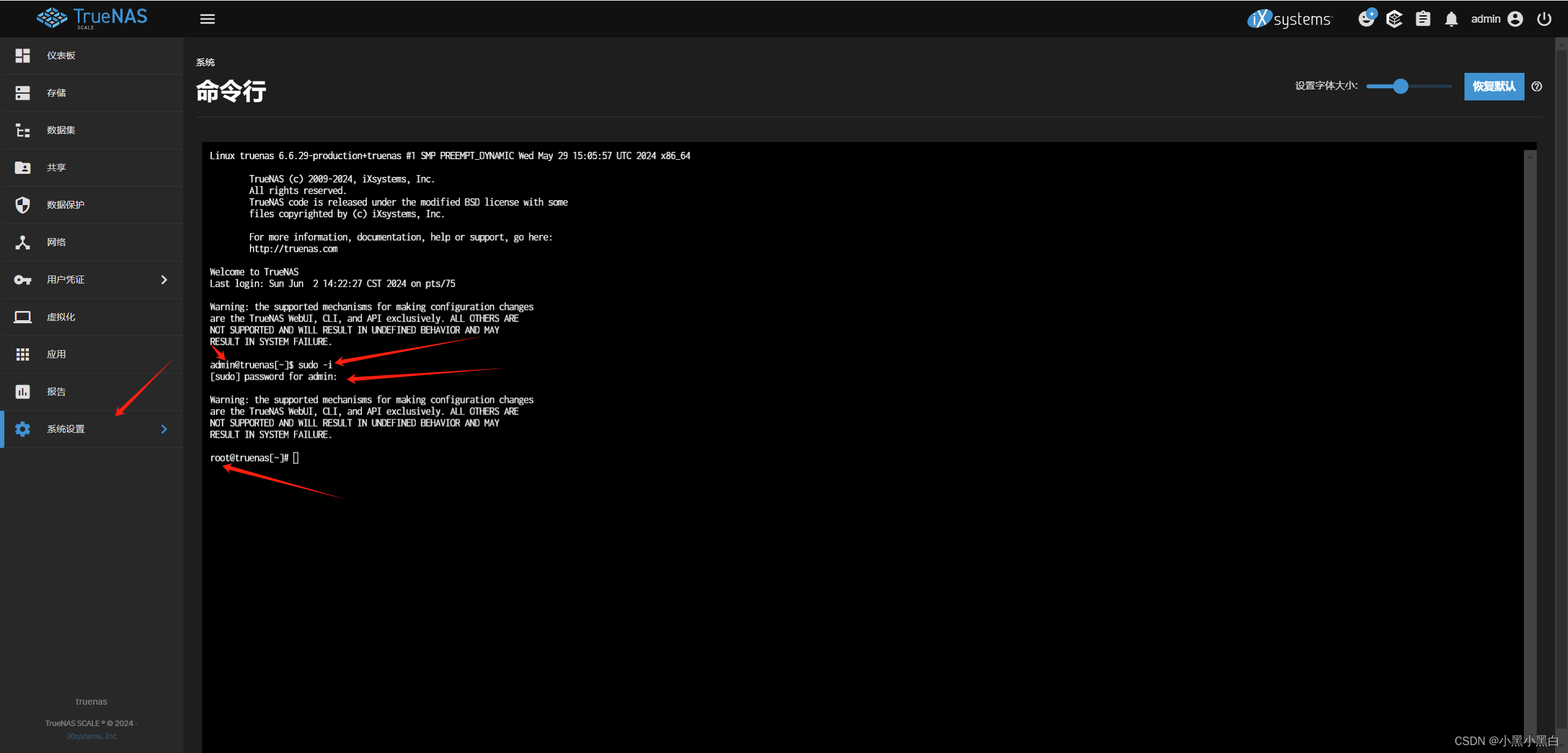
执行cp命令推送到pod
老版本(k3s)
执行k3s kubectl cp命令推送到pod
上传XLM-Roberta-Large-Vit-B-16Plus模型(例):
k3s kubectl cp /mnt/pool/share-folder/SMB/XLM-Roberta-Large-Vit-B-16Plus immich-machinelearning-54969d6cb9-czcdn:/mlcache/clip -n ix-immich
变量解释:
- /mnt/pool/share-folder/SMB/XLM-Roberta-Large-Vit-B-16Plus(模型文件上传到TrueNas中的目录)
- immich-machinelearning-54969d6cb9-czcdn(接收模型文件的pod名称,注意启停应用的话pod可能会变)
- /mlcache/clip/(pod固定的默认CLIP大模型缓存文件夹路径)
- ix-immich(namespace名称)
同理上传buffalo_l模型:
k3s kubectl cp /mnt/pool/share-folder/SMB/buffalo_l immich-machinelearning-54969d6cb9-czcdn:/mlcache/facial-recognition -n ix-immich
新版本(docker)
执行docker cp命令推送到pod
//查询容器id,找到智能模型容器的id
docker ps
//cp宿主智能模型相关文件到容器
docker cp /mnt/pool/share-folder/SMB/XLM-Roberta-Large-Vit-B-16Plus 8e6eeaae9069:/mlcache/clip/
docker cp /mnt/pool/share-folder/SMB/buffalo_l 8e6eeaae9069:/mlcache/facial-recognition/
3.检查immich-machine-learning pod中是否成功接收到模型文件
应用-选择immich-工作负载-打开immich-machine-learning容器的命令行
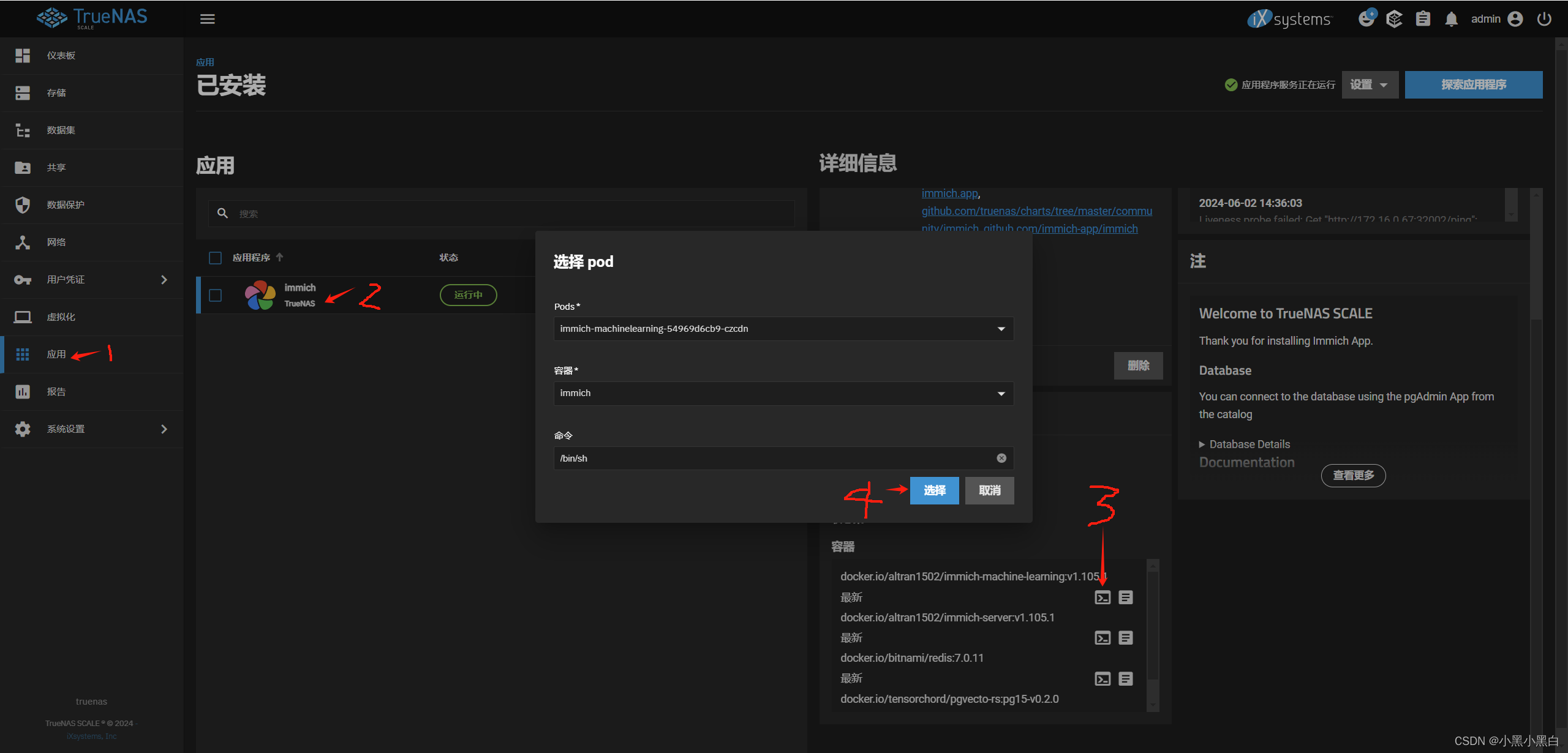
进入根目录,查看是否有mlcache文件夹,cd /mlcache进入mlcache文件夹
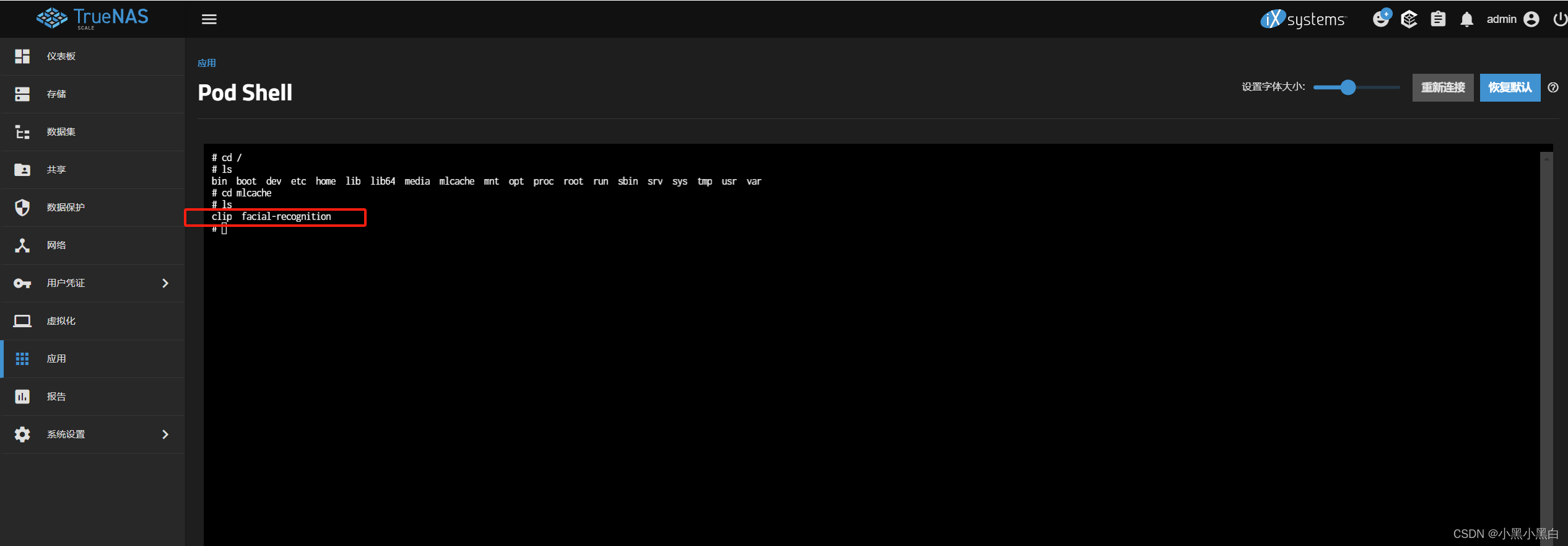
- clip 存放
XLM-Roberta-Large-Vit-B-16Plus文件夹,对应设置里的CLIP MODEL - facial-recognition 存放
buffalo_l文件夹,对应设置里的FACIAL RECOGNITION MODEL
对应模型文件夹子文件展示:

4.web页面设置切换模型参数,保存
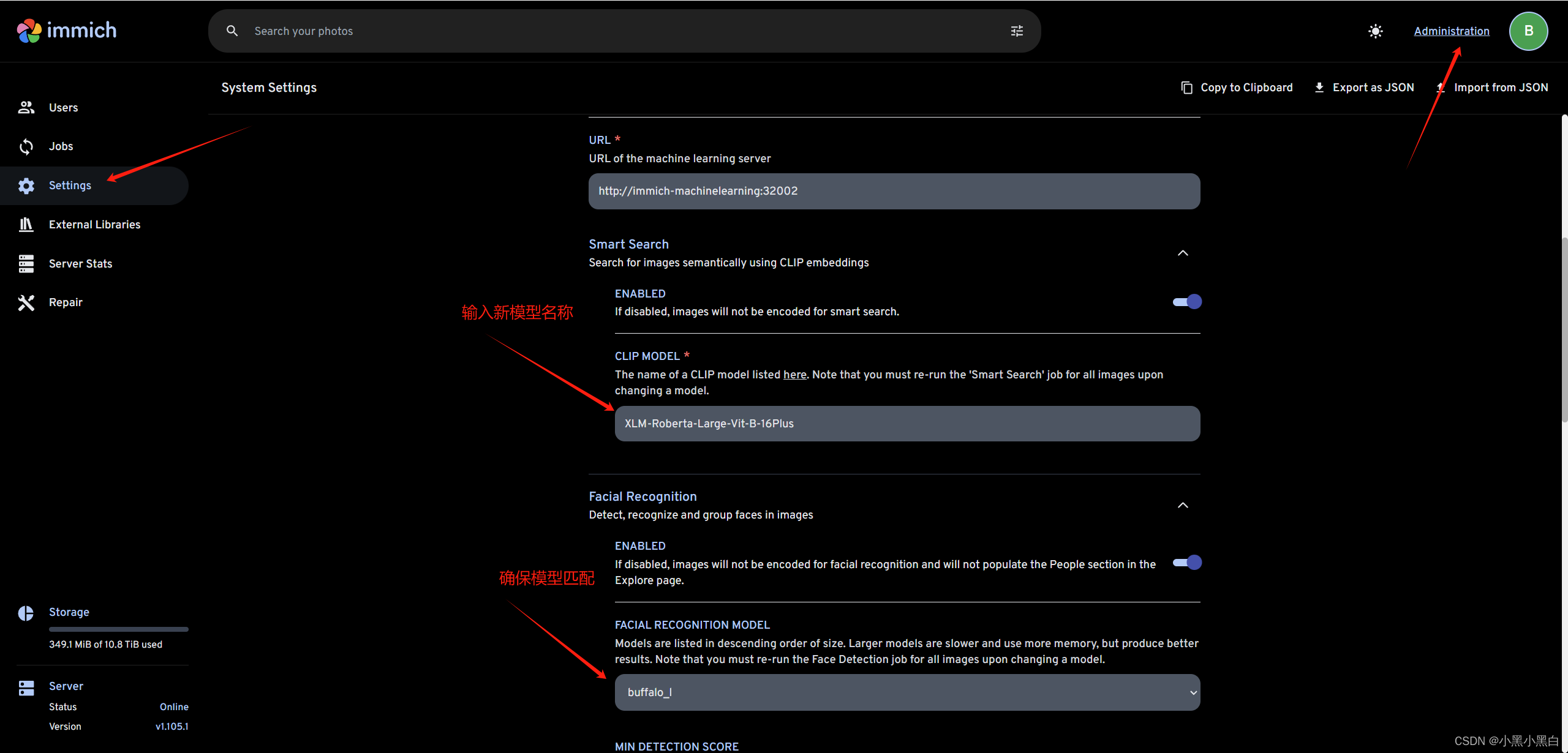
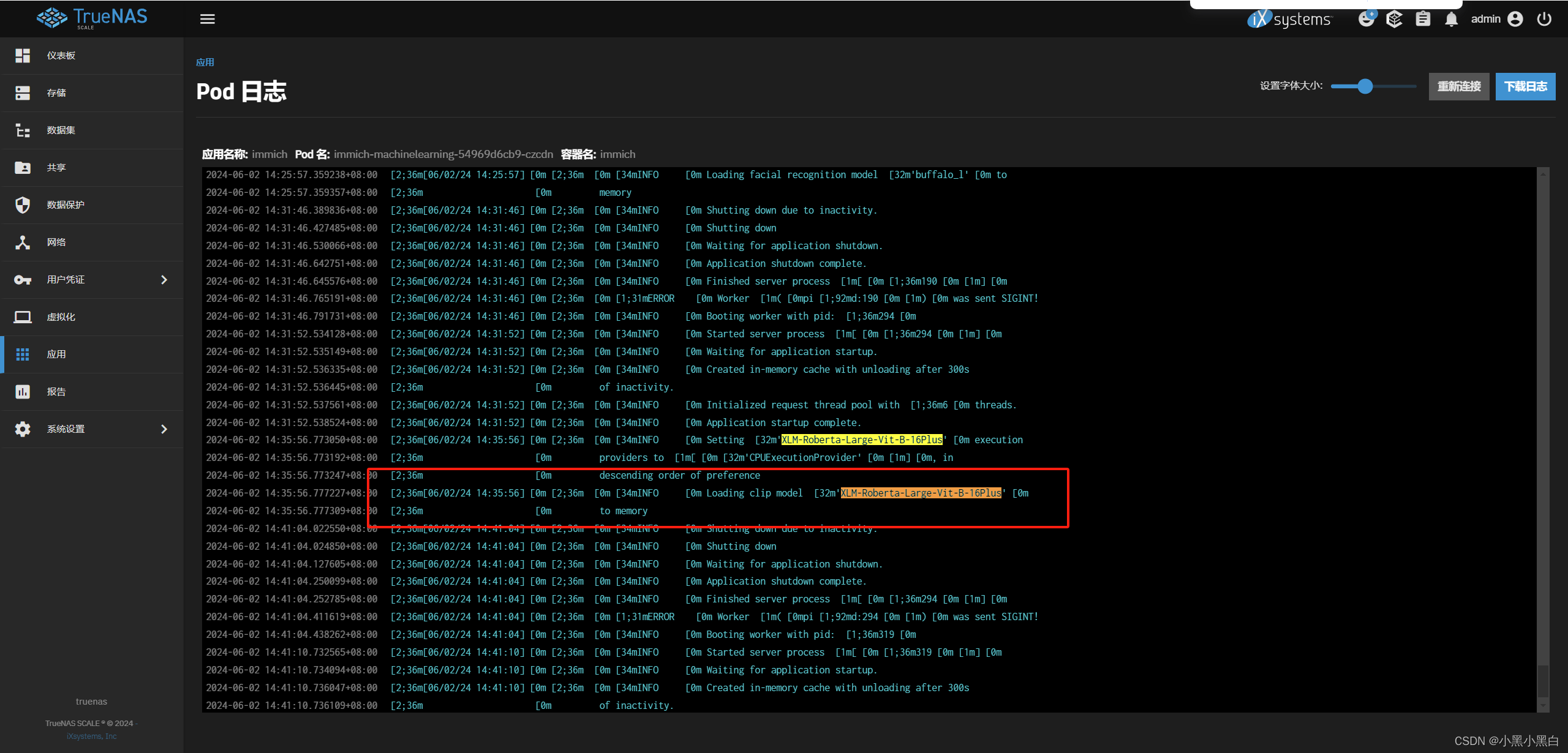
5.重新执行job任务,查看日志,确认是否加载模型文件
重新执行SMART SEARCH与FACE DETECTION任务,重新识别图片。
查看日志确认是否加载
识别成功效果图:

















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









