







命令行参数解析
Elasticsearch: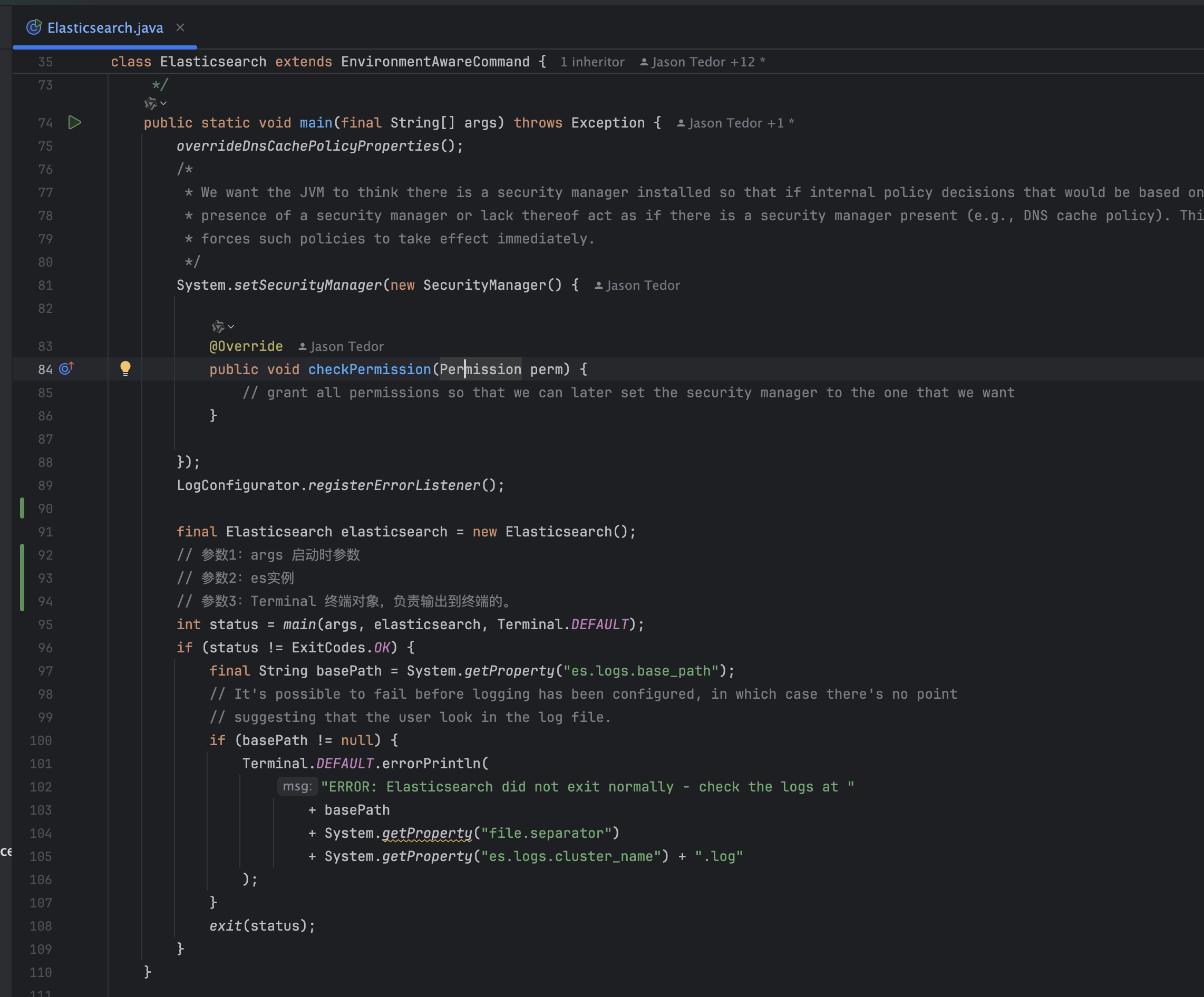
在main里面创建了Elasticsearch实例,然后调用了main方法,这个main方法最终会调用到父类Command的main方法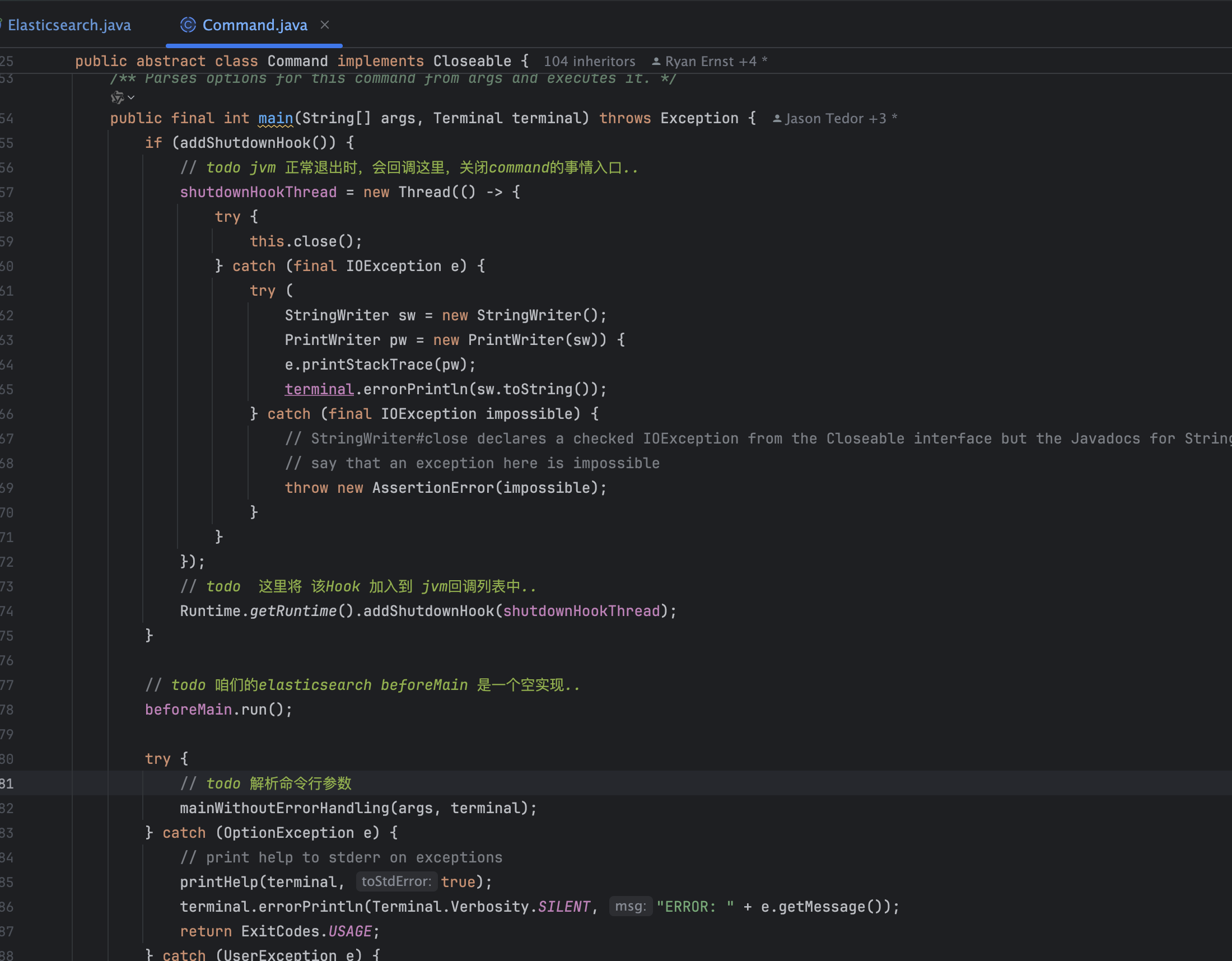
这里做了几件事:
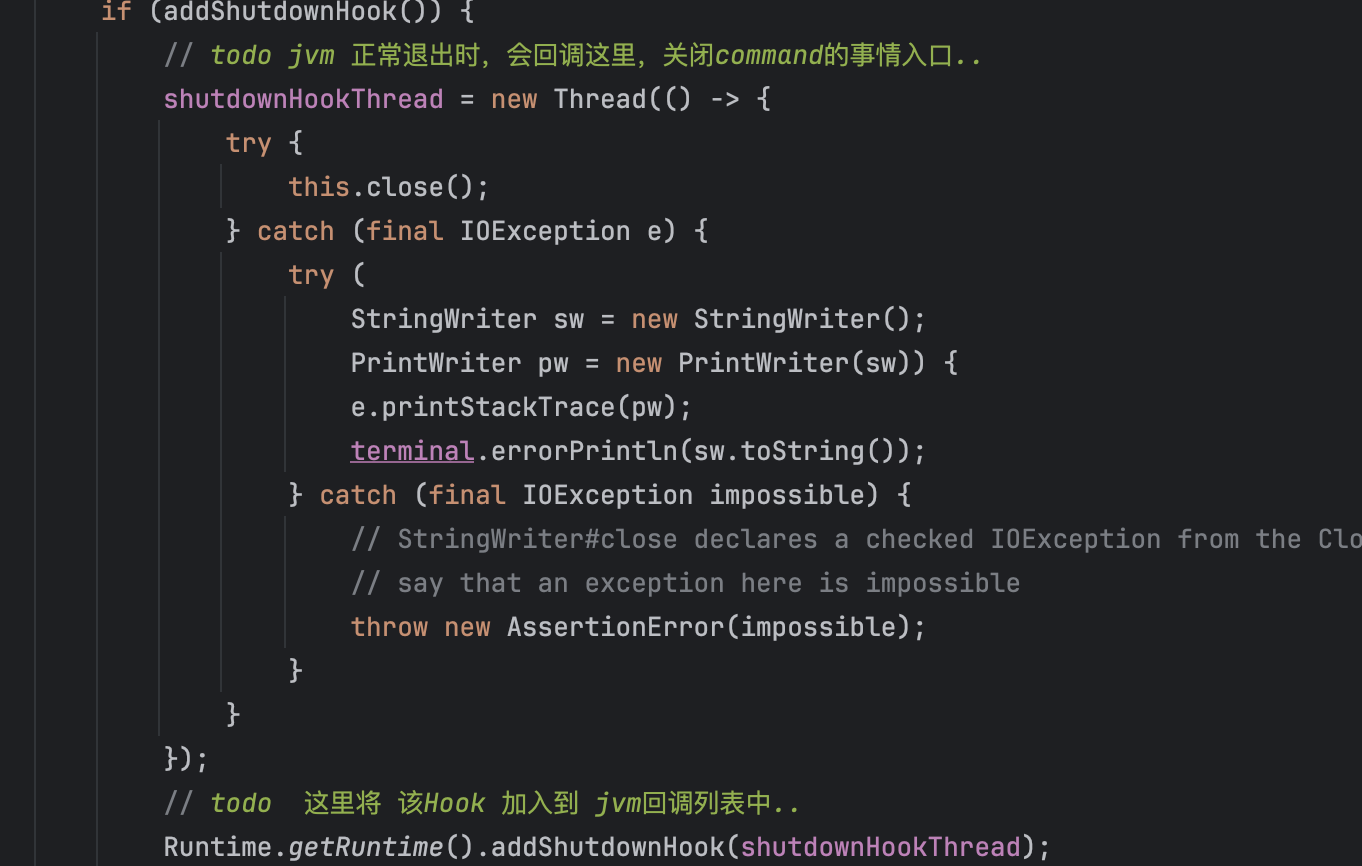
- 注册一个 ShutdownHook,其作用就是在系统关闭的时候捕获IOException并且进行输出
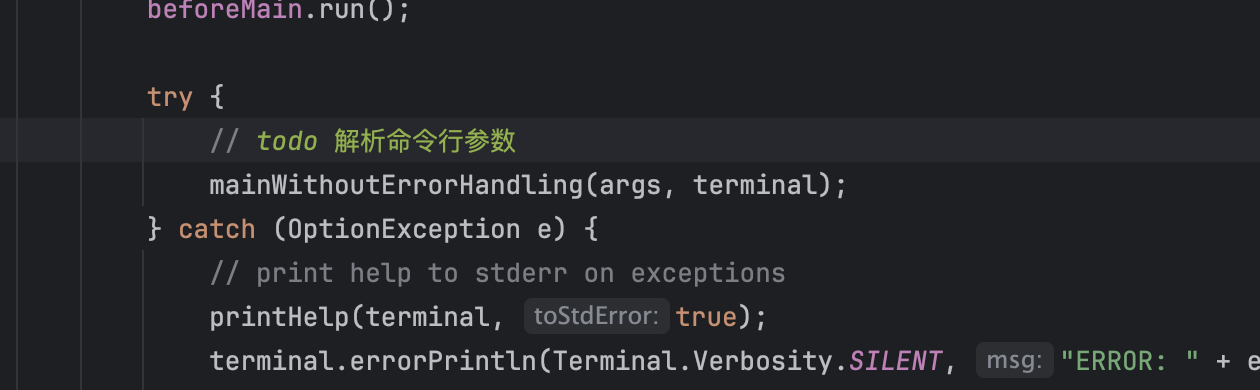
- 解析命令行参数
- 加载多个路径:data、home、logs,这里会调用到子类EnvironmentAwareCommand的execute方法,将配置解析成hashmap,并且确认 es.path.data、es.path.home、es.path.logs 这几个路径设置的存在,最后调用createEnv方法加载elasticsearch.yml配置文件,在调用Elasticsearch.execute方法
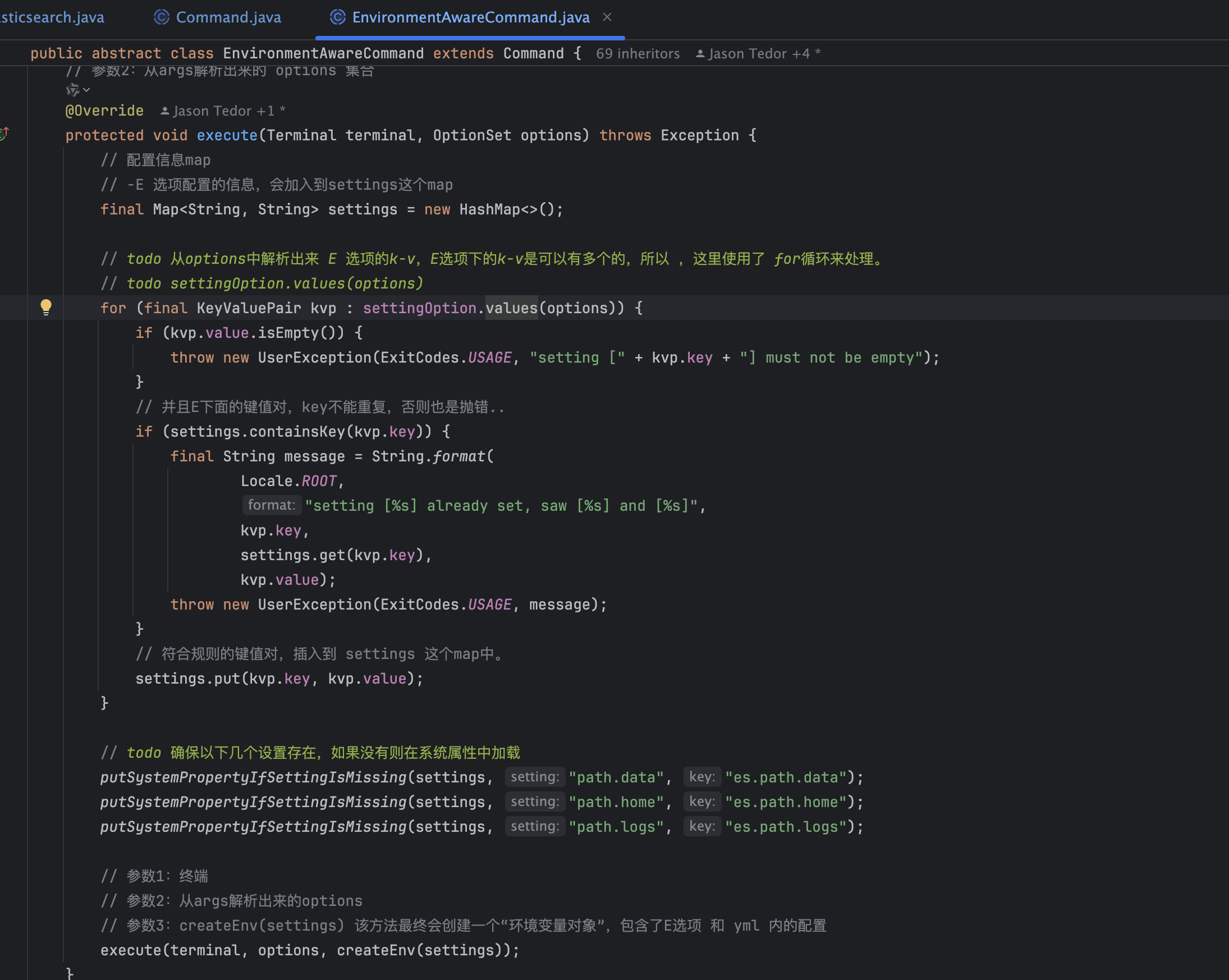
- 加载elasticsearch.yml配置文件
createEnv 函数最终调用了 InternalSettingsPreparer.prepareEnvironment 来加载 elasticsearch.yml 配置文件,并且创建了 command 运行的环境:Environment 对象
- 验证配置
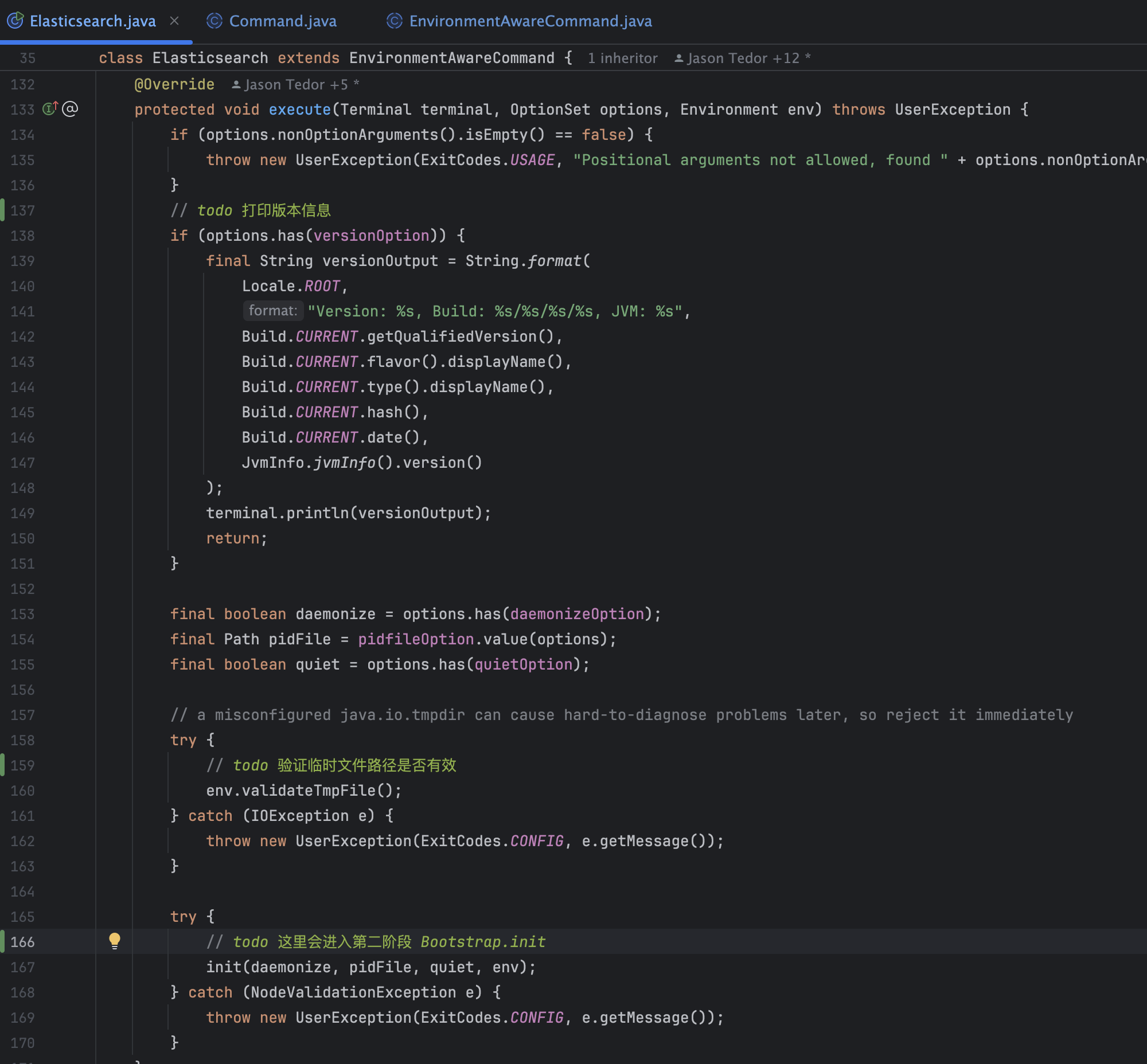
总结一下第一阶段:解析命令行参数并且验证配置
资源检查和本地资源初始化
阶段二主要是在Bootstrap类中进行的,我们进入到Bootstrap.init方法中看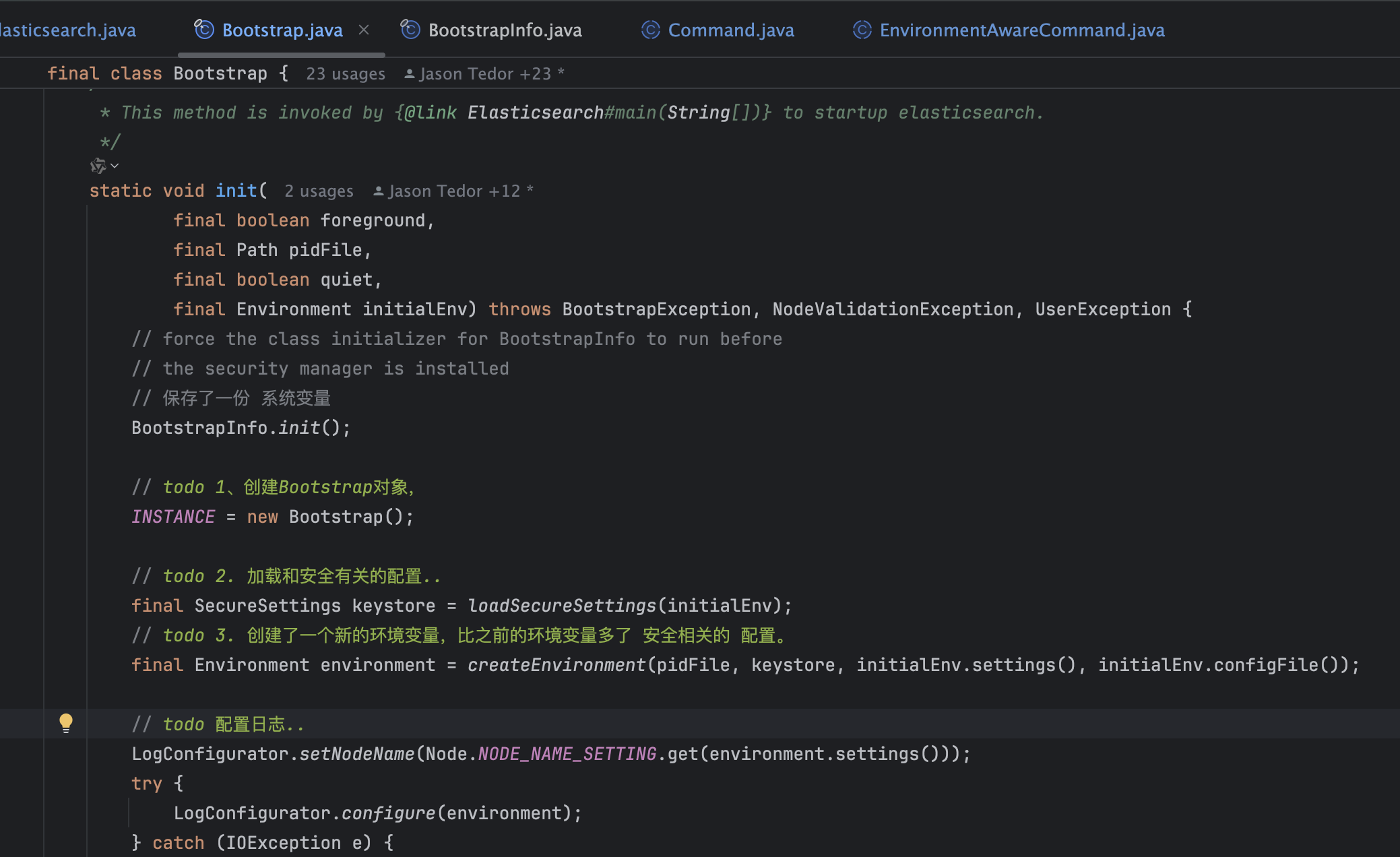
这个方法特别长,主要做了这样几件事:
- 创建BootStrap对象
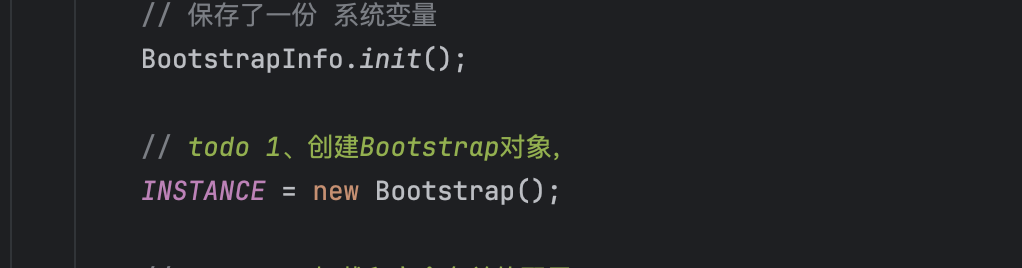
- 加载elasticsearch.keystore 安全配置:在ES运行后,在config目录会生成一个elasticsearch.keystore文件,这个文件是用来保存一些敏感配置的。因为ES大多数配置都是明文保存的,但是像X-Pack中的security配置需要进行加密保存,所以这些配置信息就是保存到elasticsearch.keystore中。

- 创建一个新的Environment:根据保存初始化配置的initialEnv和安全配置keystore调用createEnvironment(最终调用prepareEnvironment方法)重新创建一个运行ES必须的环境

- 设置节点名称:这里设置节点的名字,可以在后续的日志输出中使用,否则只要只要ID可用就会使用节点ID(节点ID可读性不好)

- 加载log4j2配置:会加载log4j2.properties文件中的相关配置,然后配置log4j的属性。

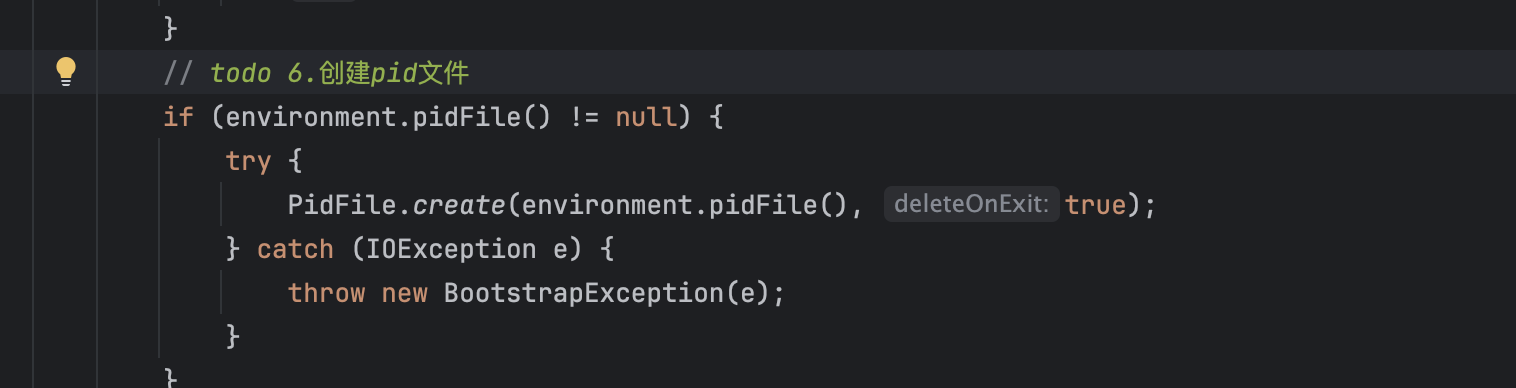
- 创建pid文件
- 检查Lucene jar:通过版本号来检查lucene是否被替换掉了,如果被替换无法被启动

- 为创建Node对象实例做准备工作:通过调用INSTANCE.setup(true, environment)为创建Node实例对象做一些准备工作,下面几步我们进入到INSTANCE.setup(true, environment)

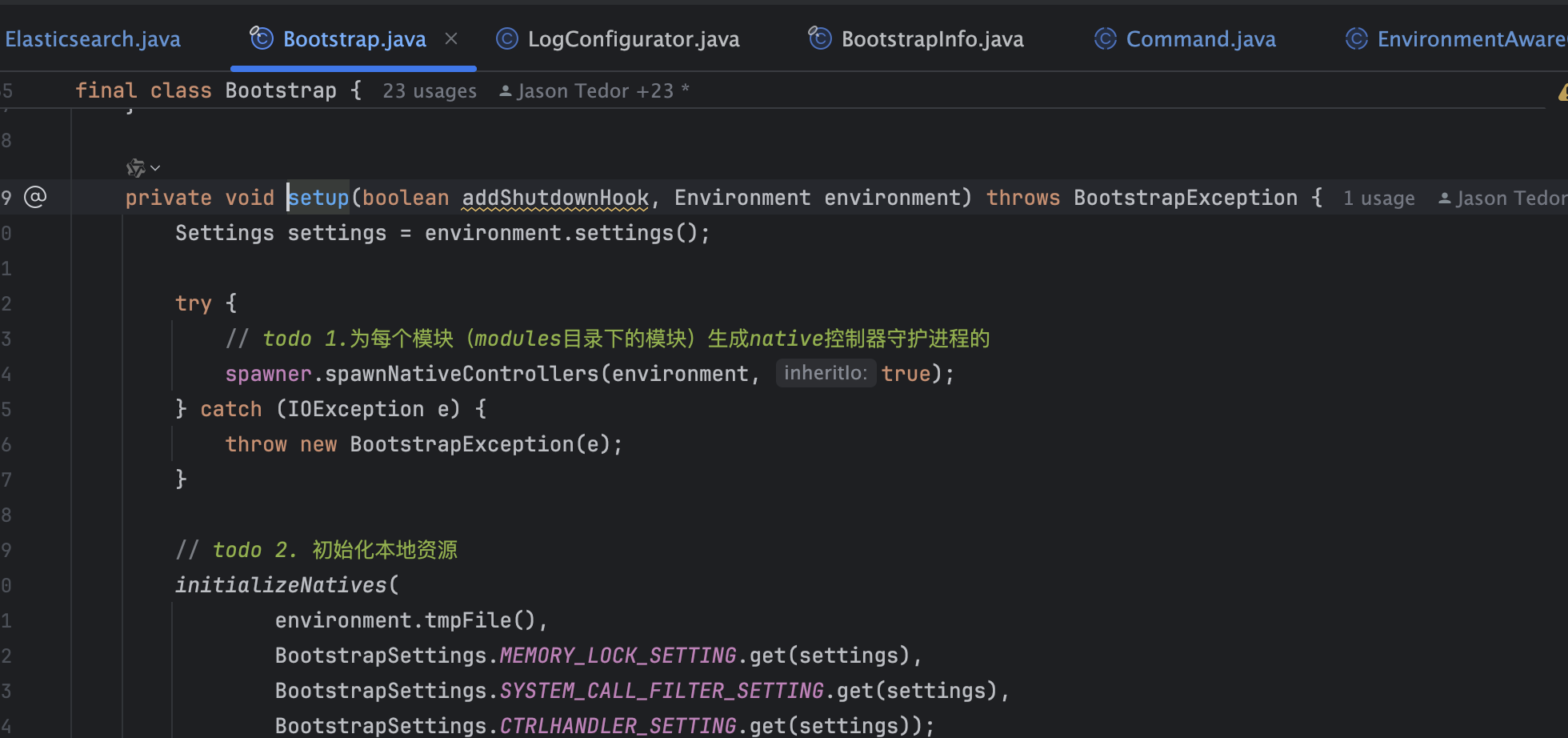
- 为给定模块生成控制器守护程序:尝试为每个模块(modules目录下的模块)生成native控制器守护进程的。

- 初始化本地资源:
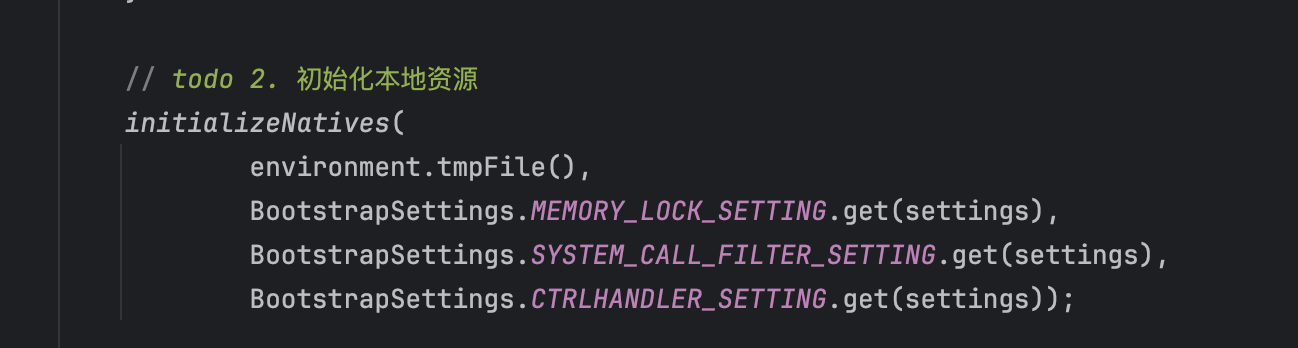
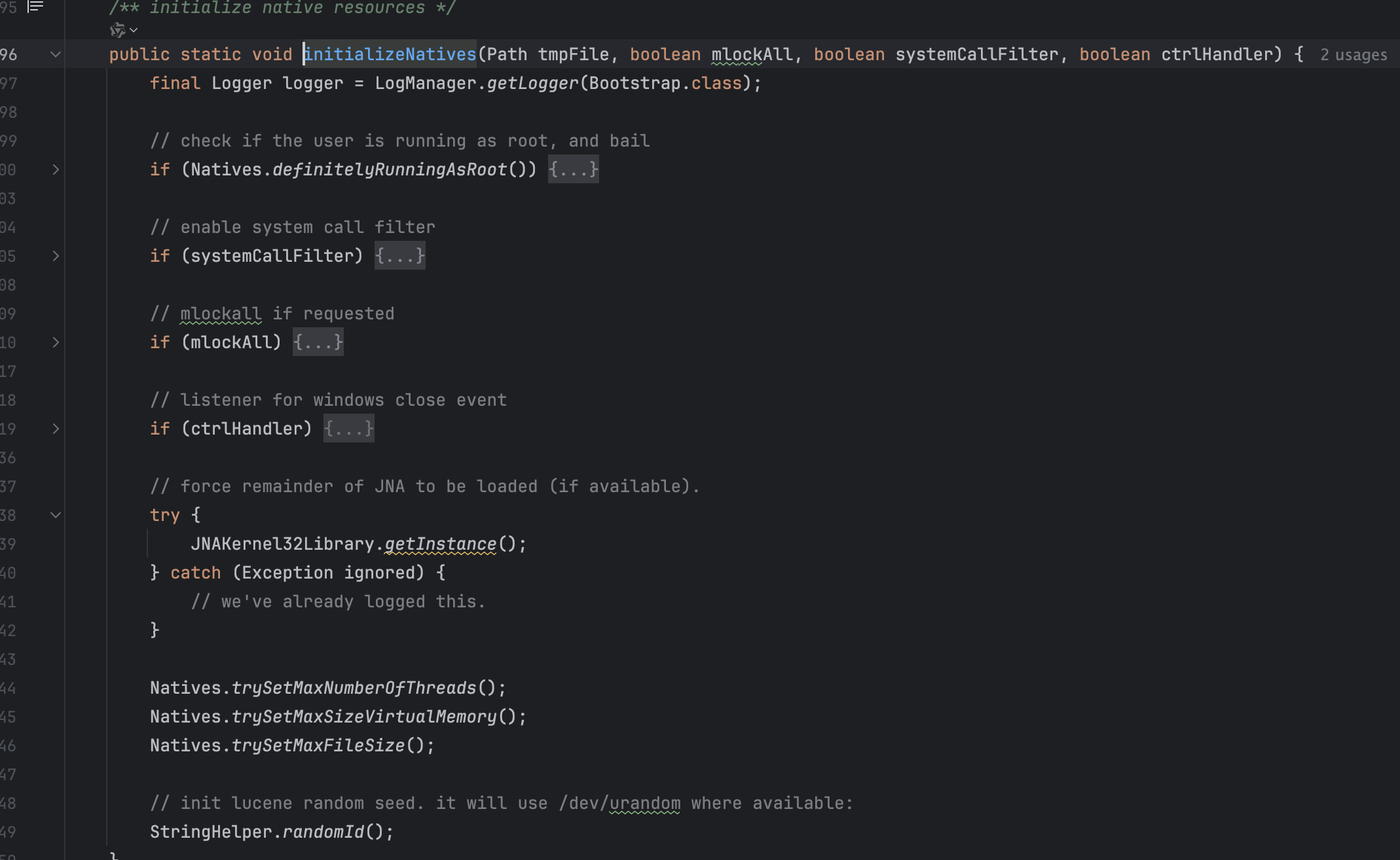
本地资源初始化主要包括:
- 不能以root运行
- 尝试启动系统调用过滤器
- 尝试调用mlockall,mlockall会将进程使用的部分或者全部的地址空间都锁定在物理内存中,防止其被交换到swap空间
- 如果是运行在window的话,关闭事件的监听器
- 尝试设置最大线程数、最大虚拟内存、最大文件size
- 为lucene设置一个随机的seed
除了调用initializeNatives方法进行本地资源初始化,还调用initializeProbes() 进行初始化探针操作,主要用于操作系统负载监控、jvm 信息获取、进程相关信息获取。
- 注册关闭资源的 ShutdownHook
- 通过调用 JarHell.checkJarHell 检查是否有重复的类。

- 在Debug 模式下以 ifconfig 格式输出网络信息

- 加载安全管理器,进行权限认证:通过调用Security.configure 函数进行安全管理器加载,进行权限认证操作:

- 创建Node实例对象:根据加载的运行环境创建Node实例,也快要进入第三个阶段了
- 启动Node节点:回到了之前set up的地方,然后调用start方法,进行node节点的启动
节点实例启动
节点创建
之前只是简单的看了一下Node的创建,再回顾一下:
后续在构造方法里面一共做了这样几件事:
- 设置节点的生命周期:将生命周期设置为INITIALIZED,此时节点正处于初始化状态
- 各种信息的打印:
- 创建插件服务:主要是加载modules目录中的模块和加载plugins目录中已经安装的插件
- 设置格外的节点角色:
- 创建NodeEnvironment:NodeEnvironment实例话的过程中会生成Node ID,最后此处打印节点相关的信息,需要注意的是,此处会通过 Environment.assertEquivalent 函数来保证启动过程中配置没有被更改
- 创建线程池:
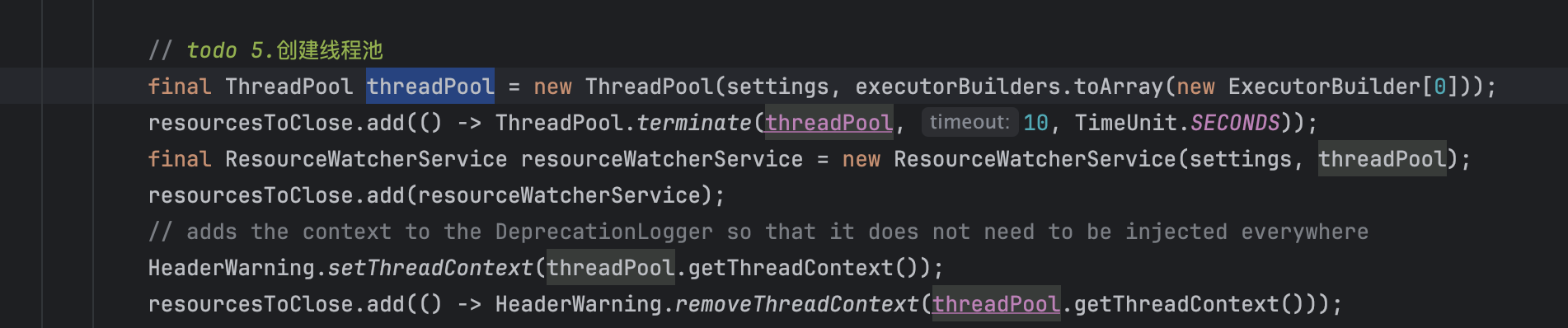
ES线程池的实现封装在ThreadPool中。ThreadPool中定义了4种线程池类型: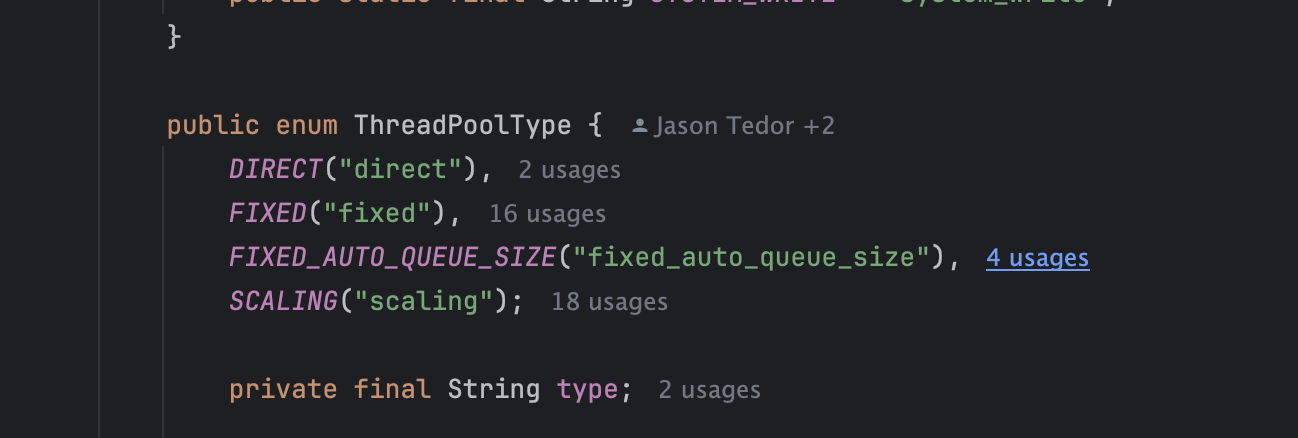
- direct:执行器不支持关闭的线程
- fixed:拥有固定线程的线程池,当一个任务无法分配一条线程时会被排队
- fixed_auto_queue_size:和fixed类似,但是任务队列会根据 Little’s Law 自动调整。8.0 后将被移除。
- scaling, 线程池中线程的数量可变,线程的数量在 core 和 max 间变化,使用 keep_alive 参数可以控制线程在线程池中的空闲时间。
ThreadPool中创建了多个线程池,主要有以下几种:
- 创建NodeClient实例:NodeClient执行本地的action的。

action的类型定义在ActionType:
- 创建各个模块和服务:各个模块和服务的创建
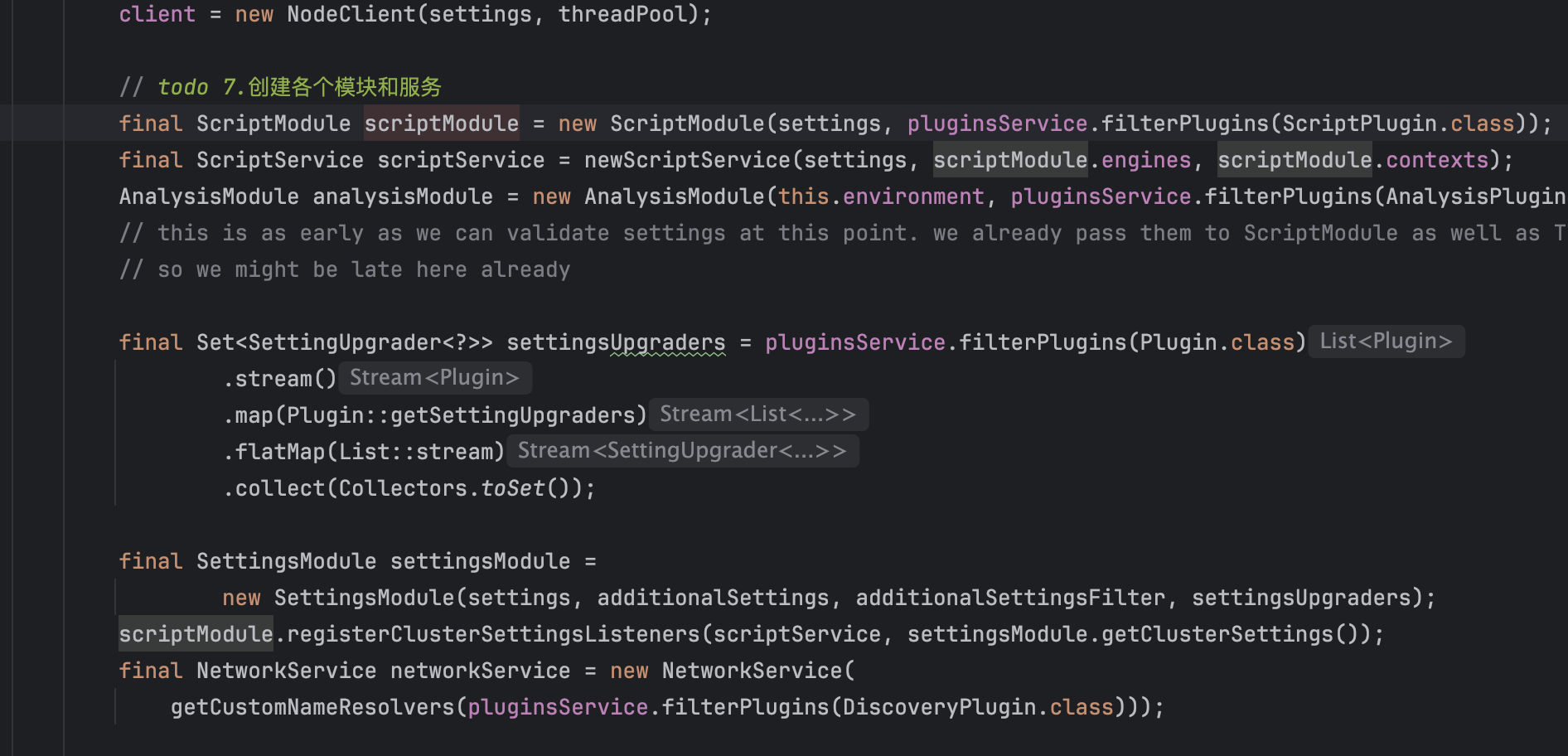
- **绑定对应的对象到Guice:将实例化的对象绑定要ModulesBuilder中,最后调用 modules.createInjector 创建 injector(注入器)。ES 用到了 **Guice这个谷歌提供的轻量级 IOC 库,bind 和 createInjector 是其提供的基本功能。

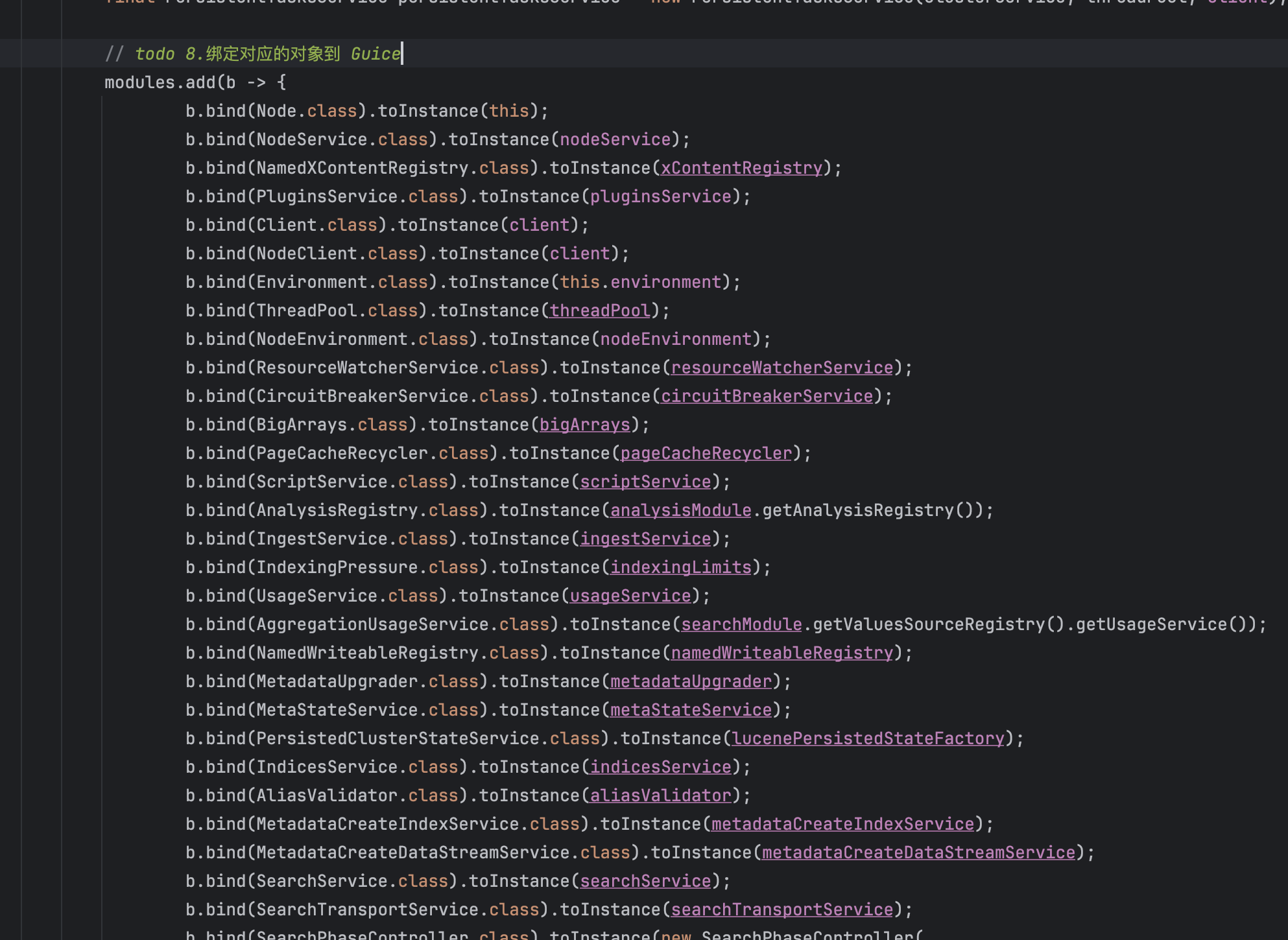

- 初始化HTTP Handler
后续就是节点启动的流程了
节点启动
Node.start主要负责启动各个生命周期组件(LifecycleComponent)和从Guice(也就是injector)中获取需要启动的服务类实例,然后调用它们的start方法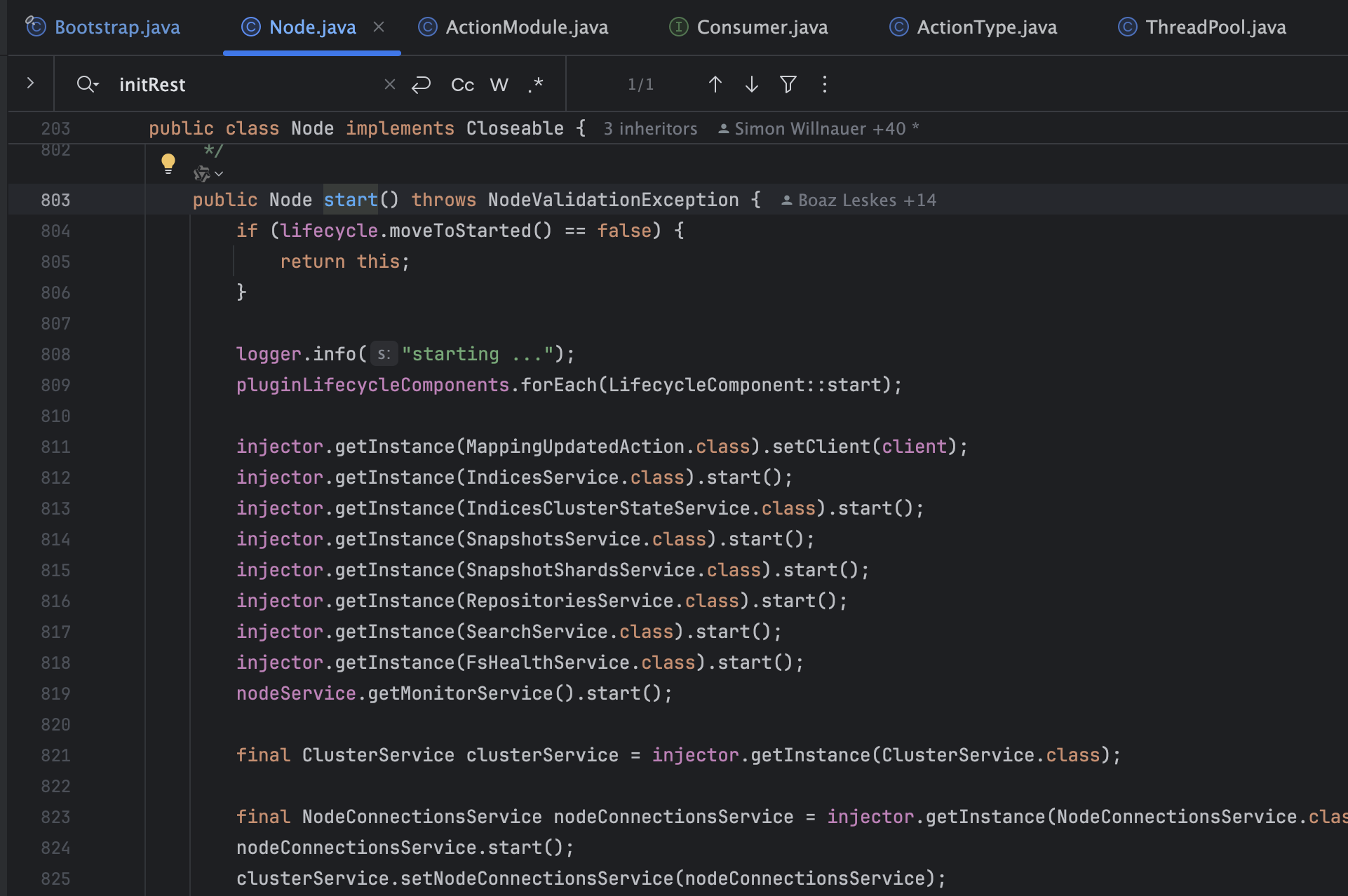
并且后面是一堆server要启动:
总结一下:
- 启动各个生命周期组件和服务,一些重点的服务如下:
| 服务 | 简介 |
|---|---|
| IndicesService | 负责索引管理,如创建、删除等操作。 |
| IndicesClusterStateService | 负责根据各种集群索引状态信息进行相应的操作,如创建或者恢复索引(这些实际的操作会交给具体的模块实现)等。 |
| SnapshotsService | 负责创建快照,在执行快照创建和删除的时候,所有的执行步骤都在主节点上=进行。 |
| SnapshotShardsService | 此服务在 data node 上运行,并且控制此节点上运行中的分片快照。其负责开启和停止分片级别的快照。 |
| RepositoriesService | 负责维护节点快照存储仓库和提供对存储仓库的访问。 |
| SearchService | 提供搜索支持的服务。 |
| ClusterService | 集群管理服务,负责管理集群状态、处理集群任务、发布集群状态等。 |
| FsHealthService | 文件系统健康检查服务。通过创建一个临时文件来检查文件系统是否可写。 |
| MonitorService | 负责提供操作系统、进程、JVM、文件系统级别的监控服务 |
| NodeConnectionsService | 该组件负责维护从该节点到集群状态中列出的所有节点的连接,并在节点从集群状态中删除后断开与节点的连接。并且会定期检查所有链接是否在打开状态,并且在需要的时候恢复它们。需要注意的是此组件不负责移除节点! |
| GatewayService | 网关服务,负责集群元数据的持久化和恢复。 |
| Discovery | 节点发现模块是一个可插拔的模块,其负责发现集群中其他的节点,发布集群状态到所有节点,选举主节点和发布集群状态变更事件。 |
| PeerRecoverySourceService | 负责处理对等分片的恢复请求,并且开启从这个源分片到目标分片的恢复流程。 |
| TransportService | 负责节点间数据同步。 |
| HttpServerTransport | 提供 REST 接口服务。 |
- 调用ClusterService.setNodeConnectionService将NodeConnectionService绑定到ClusterService中去
- 调用acceptIncomingRequests 尝试接收请求。
- 调用discovery.startInitialJoin 开始进行加入集群的循环
- 开启线程去检查是否已经加入集群
- HttpServerTransport,并且绑定监听地址,接收 REST 请求
4.集群启动流程
- Master 选举
根据前面的内容可知,Master 对集群的重要性,所以集群中多个节点启动后首要的任务是选举出一个 Master,有了 Master 后续的集群启动操作将由 Master 主导。
- 选择集群元数据
在 Master 被选举出来后,其首要任务就是要选择出集群的元数据信息,这部分的工作主要在 Gateway 模块中处理。Master 会向已经加入到集群的所有节点获取各种的元数据信息,然后选择出版本号最新的那个作为集群的元数据,并向所有节点进行广播。
- Allocation
在 allocation 过程中将会选择 shard 级别的元数据信息,并且构建内容路由表。在集群启动的时候,所有的 shard 都是未分配的,allocation 会决定哪个 shard 被分配到哪个节点,并且把这个关系记录下来写入到内容路由表。
我们知道 ES 的分片分为主分片和副分片,所以在分配的时候会先选择出主分片,然后再选择出副分配。
- 索引恢复(recovery )
为了保证数据的可靠性,在启动的时候主分片需要执行 recovery 流程来恢复没有来得及刷盘的数据。而副分片除了要恢复没有刷盘的数据外,还要恢复主分片已经写入但是副分片还没有写入的数据来保证数据的一致性。
集群的启动主要就是上述的几大流程,经过这些流程后,一般来说集群就可以提供对外的服务了。
5.总结
通过 Elasticsearch 这个类,系统进行了命令行参数解析与配置加载。通过 Bootstrap 类进行了资源检查与本地资源初始化。最后实例化了 Node 类,其负责加载各个模块和插件、创建线程池、创建 keepalive 线程等工作,在 Node.start 方法中获取了各个服务的实例并且调用它们的 start 方法。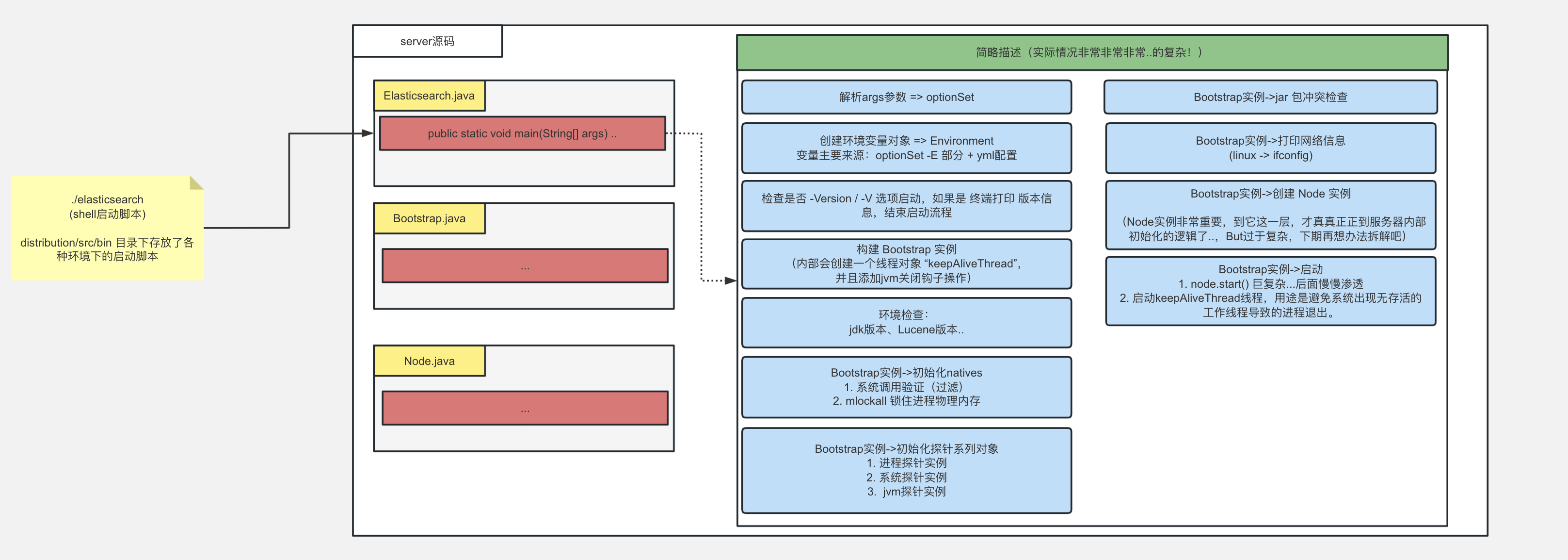















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









