







硬件
- CPU:选择高性能的CPU,ES依赖CPU处理搜索请求和数据索引。多核CPU有助于提高并行处理能力。
- 内存:内存是关键。确保有足够的内存给操作系统和ES本身。建议分配给ES的JVM堆内存大小是总内存的一半,但不要超过32GB,以避免堆外内存压缩问题。
- 磁盘:使用SSD而不是HDD,SSD能显著提高数据读取和写入的速度。
- 网络:确保高带宽和低延迟的网络环境,特别是在集群节点之间的通信上。
操作系统
- 内存锁定:锁定内存,防止JVM堆内存被交换。可以在
elasticsearch.yml中设置:
bootstrap.memory_lock: true
- 虚拟内存:调整虚拟内存设置,禁用交换(swap)。可以在
/etc/sysctl.conf中添加以下内容:
vm.swappiness = 1
- 文件系统:使用合适的文件系统,如ext4或xfs,ext4一般表现良好。
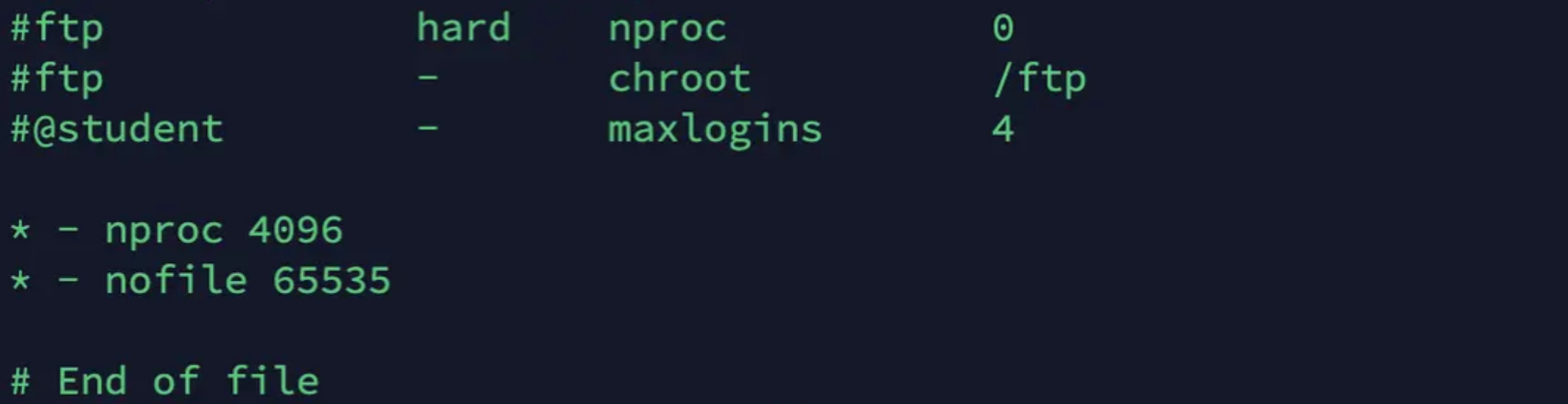
- 文件描述符(文件句柄):增加文件描述符限制,ES需要打开大量文件来处理索引和查询。可以在
/etc/security/limits.conf中进行配置,例如:
* hard nofile 65536
* soft nofile 65536
- 增加系统最大线程数:为了保证 ES 可以创建新的线程,需要在 /etc/security/limits.conf 中设置 nproc 的值为 4096:
- 设置mmap counts
ES 使用了 mmapfs 来存储索引,但是默认的 mmap counts 的数量实在太少了,这样可能会造成 OOM 异常。可以在 /etc/sysctl.conf 中设置 vm.max_map_count 的值为 262144,设置完成后需要执行 sysctl -p 刷新。
- TCP参数调优
ES配置调优
- VM配置:调整JVM堆内存大小,确保堆外内存足够
-Xms16g
-Xmx16g
- 线程池和队列:根据工作负载调整线程池大小和队列长度
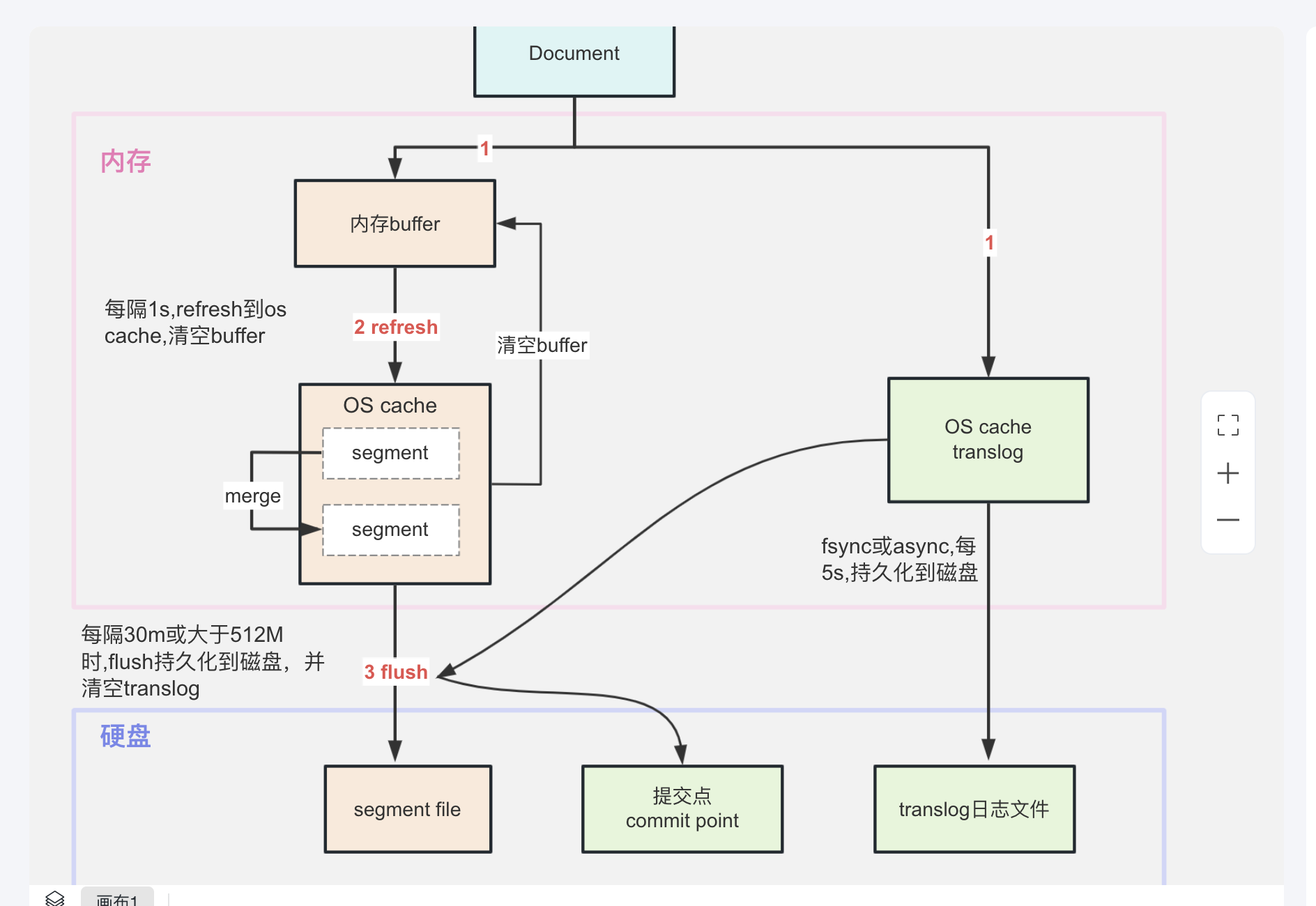
- 加大translog flush的间隔:
为了防止数据丢失,保证数据的可靠性,默认情况下是每个请求 translog 都刷盘。如果我们是在导数数据的应用场景,那么为了提高写入的性能,可以不每个请求都对 translog 进行刷盘。对 translog 刷盘的控制参数有以下几个:
- index.translog.durability,可选项有 request(默认)和 async。request 是指每个请求都会对 translog 进行刷盘,而 async 是异步刷盘,每隔 index.translog.sync_interval 进行刷盘。
- index.translog.sync_interval,translog 刷盘的时间间隔,默认 5s,不能小于 100 ms。
- index.translog.flush_threshold_size,当 translog 的量达到这个阈值将会触发刷盘,默认是 512 M。调大这个阈值可以减少刷盘的次数和大段的合并次数。
这几个参数的配置样例如下:
index.translog.durability: async # 默认值为 request
index.translog.sync_interval: 60s(自己设置)
index.translog.flush_threshold_size: 1gb(自己设置)
如果不进行 Translog Flush,使用以下配置的时候:
PUT articles_buffer_translog_not_flush
{
"mappings": { ...... },
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0,
"index.refresh_interval": "-1",
"index.translog.durability":"async",
"index.translog.sync_interval": "240s",
"index.translog.flush_threshold_size": "512m"
}
}
对于写入的耗时还是很明显的,从一开始每个批次 3200 条数据的耗时 4 分 39 秒,一路优化到最后的 3 分 53 秒,需要注意的是,部分配置是有特定的使用场景的。
- 调整内存 Buffer

调整这里的buffer_size会对性能有一定的影响,但不多
- 段合并:调整段合并策略,减少磁盘I/O。可以在
elasticsearch.yml中配置:
index.merge.policy.max_merge_at_once: 5
index.merge.policy.segments_per_tier: 10
- 选择用于存储的编解码器:如best_compression或default
index.codec: best_compression
- 缓存:合理设置缓存,如查询缓存和字段数据缓存,以提高查询性能
indices.fielddata.cache.size: 控制字段数据缓存的大小。
indices.query.cache.size: 控制查询缓存的大小
Schma设计
设置合理的分片数和副本数
合理设置分片数和副本数,根据数据量和查询负载进行调整。
字段数据类型
选择合适的数据类型,尽量使用较小的精度来节省空间和提高性能,例如 ID、枚举等用 keyword,文章标题用 text 等。
- Text vs Keyword:对于需要全文搜索的字段,使用 text 类型;对于不需要分析且用于过滤或排序的字段,使用 keyword 类型。
- Numeric Fields:对于数值类型的数据,使用 integer、long、float 或 double 类型。
- Date Fields:使用 date 类型,并确保正确解析日期格式。
- Nested Objects:对于嵌套的数组对象,使用 nested 类型,以便独立地索引每个对象。
- Object vs Nested:在多数情况下,使用 nested 类型替代 object 类型,除非不需要对嵌套对象进行独立查询
字段尽量少,够用就好
字段越多,写入的时候占用的资源就越多,相同的 index buffer 能存储的数据条数越少。更多的字段对搜索也是有影响的,ES 非常依赖于底层的文件系统缓存,我们肯定想把更多的数据(index segment)缓存起来,这样可以提升性能。
其实搜索分为两个阶段,一个是 search,一个是 fetch。search 阶段根据查询条件从系统找到对应数据的 ID,而 fetch 则根据这些 ID 从系统中获取对应的数据内容。所以可以把需要搜索的内容放到 ES 里,而文档的源数据放到 mysql 或者 hbase 里,搜索的时候从 ES 里搜索出文档 ID,再从 mysql 或者 habse 中获取文档数据。
不需要的搜索字段不要索引
对于那些存储在 ES 中,但有不需要进行搜索的字段,可以设置其不需要索引:
PUT myindex
{
"mappings": {
"properties": {
"content": { "type": "text" },
"name": {
"type": "text",
"index": false
}
}
}
}
如上示例,name 字段不需要索引,所以将其设置 index 属性为 false 即可。
数据扁平化,尽量避免使用nested、parent-child类型
尽量减少 object 类型的使用,更建议将数据扁平化。越是复杂的数据结构,系统要处理的事情就越多,写入就越慢。而且 nested、parent-child 等数据类型,在查询时候性能也很差。
禁用 Dynamic Mapping
必须明确每个字段的类型和属性,建议禁用 Dynamic Mapping。例如上述的 name 字段,我们想让其不进行索引,但如果是 Dynamic Mapping 处理后,默认是会进行索引的,这并不符合我们的需求。
配置合适的分词器
不同的分词器性能大不相同,需要根据业务符合度来进行选择。例如 IK 分词器有 ik_max_word 和 ik_smart 两种模式,分词的粒度不一样,性能也有差别
关闭Norms
如果一个字段不需要算法,可以关闭其Norms,下面是官方的示例:
PUT my-index-000001/_mapping
{
"properties": {
"title": {
"type": "text",
"norms": false
}
}
}
底层 Norms 存储了各种归一化因子,这些因子在查询数据的时候用于算分。尽管保存这些归一化因子对算分很有用,但是需要耗费一定的磁盘空间。通常来说,开启了 Norms 的字段,每个文档都需要一个字节来保存这些信息,即使这个文档内容里没有这个字段。
关闭doc_values
doc_values 是用来给文档建立正排索引的,与 fielddata 不同的是,doc_values 在索引时创建,并且需要占用磁盘,开启 doc_values 有利于对这个的值进行排序和聚合。 对于非 text 字段的类型,doc_values 默认是打开的,下面是关闭 doc_values 的示例:
PUT my-index-000001
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
写入优化
使用ES 生成的随机 ID
使用 ES 生成的随机 ID 可以将数据均匀分发到各个节点进行处理,可以有效地利用集群的计算资源。并且使用 ES 生成的随机 ID 写入时不需要先检查一遍 ID 是否已经存在,可以有效提高写入的效率。
减少副本的数量
在写入主分片成功后,数据同步到副本是并行进行的,按道理只需要等待最慢的那个返回即可以完成写入。但其实我们在导入数据的时候,可以设置从副本的数量为 0,等数据导入完成后,再设置从副本的数量,然后等系统自己同步到各个节点上,其示例如下:
PUT /myindex/_settings
{
"number_of_replicas": 2
}
调整Bulk大小
通过对源码的阅读,我们知道不管是单个请求还是批请求,最终都转化为 Bulk 的方式来进行处理的。使用 Bulk 的方式有利于提高写入的性能,这个其实也很好理解,如果链接不是长链接,每写入一条数据都进行一次 TCP 链接的过程,那效率是多低啊。另外一般来说,建议一个批里只处理同一个索引的数据,不同索引的数据分多个批进行提交。
虽然说要将数据进行批提交,但是并不是批越大就越好的,建议是 5M 到 10M 一个批。假设平均一条数据为 1k,那么一个批就是 5000 到 10000 条数据。当然这个并不是绝对的,你需要根据你的集群情况来做调整。你可以先每个批 5000 条开始进行测试,然后 8000、12000,直到写入的性能不在提高为止。
数据预处理
- 压缩传输:在批量写入时使用压缩(如gzip)减少网络传输数据量,提高传输速度。
- 数据清洗:在写入ES之前进行数据清洗,去除不必要的字段和冗余数据,减少数据写入量。
异步写入
使用异步写入机制,可以让客户端在等待写入确认的同时继续处理其他任务,从而提高整体的写入吞吐量。
查询优化
使用 Filter 而不是 Query
对于不需要参与评分的条件,使用 filter 而不是 query。filter 会在缓存中执行,如果相同的条件再次出现,可以直接从缓存中获取结果,而无需重新执行。
减少返回字段
在查询时,只请求真正需要的字段,避免返回不必要的数据。这可以通过指定 _source 参数或使用 stored 字段来实现。
使用 Scroll API
对于需要大量结果的查询,使用 Scroll API 可以提高性能。Scroll API 会保留一个搜索上下文,允许分批获取结果,减少每次查询的网络传输量。
调整缓存大小
根据查询模式调整 indices.fielddata.cache.size 和 indices.query.cache.size,以优化缓存的使用,提高查询速度。
使用 Aggregations
聚合查询(Aggregations)可以减少数据扫描量,提高查询效率。使用聚合来计算统计数据,而不是在查询结果中进行计算。
避免使用 Exists 查询
exists 查询在内部会遍历所有文档,因此尽量避免使用。如果必须使用,考虑使用 has_child 或 has_parent 查询作为替代。
优化排序
排序操作会消耗大量资源,尤其是当排序字段没有启用 Field Data 的时候。如果可能,使用 keyword 类型字段进行排序,并开启 Field Data。
使用 Multi Search API
如果需要执行多个查询,可以使用 Multi Search API 将它们组合在一起,减少网络往返次数。
避免使用 Wildcard 查询
wildcard 和 regexp 查询在全文索引上非常慢,尽量避免使用。如果必须使用,考虑将字段类型改为 keyword 并限制查询长度。
使用 Term Queries
对于精确匹配的查询,使用 term 或 terms 查询,它们比 match 查询更快。
限制结果集大小
使用 size 参数限制返回的结果数量,避免不必要的数据传输和内存消耗。
优化分页
使用 from 和 size 参数进行分页时,避免使用过大的 from 值,因为它会导致全表扫描。考虑使用 Scroll API 或者基于排序字段的游标分页。
调整 JVM 和 ES 设置
根据查询负载调整 JVM 堆大小和 ES 的各种设置,如垃圾回收策略、线程池大小等。
监控和分析查询
使用 Kibana 的 Dev Tools 或者 Elasticsearch 的慢查询日志来监控和分析查询性能,找出瓶颈并进行优化。
使用 Explain API
对于复杂的查询,使用 Explain API 来了解查询计划和评分细节,帮助诊断和优化查询。
避免过度使用 Nested 和 Parent-Child 关系
虽然这些功能强大,但过度使用会增加查询复杂度和开销。仅在确实需要时使用。
使用 Caching Bloom Filters
对于频繁的不存在查询,可以考虑使用 Caching Bloom Filters 来减少不必要的文档扫描。
调整 Shard 和 Replica 数量
根据查询模式和集群规模调整索引的分片和副本数量,以达到最佳查询性能。
使用 Query DSL
使用 Query DSL 而不是简单查询字符串,因为它提供了更多控制和优化选项。
测试和基准
在生产环境之前,使用测试数据集进行查询性能测试和基准测试,确保查询优化措施有效。
这些策略需要根据具体的查询模式和业务需求进行调整,以达到最佳的查询性能。

















 9001
9001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









