






前言
写这个是因为我想了解一下在LLM推理过程中,GPU所使用的高速互联技术。主要知识来自Kimi和Qwen。我主要做整理。
其他参考文献:
https://zhuanlan.zhihu.com/p/647191585
一言以蔽之
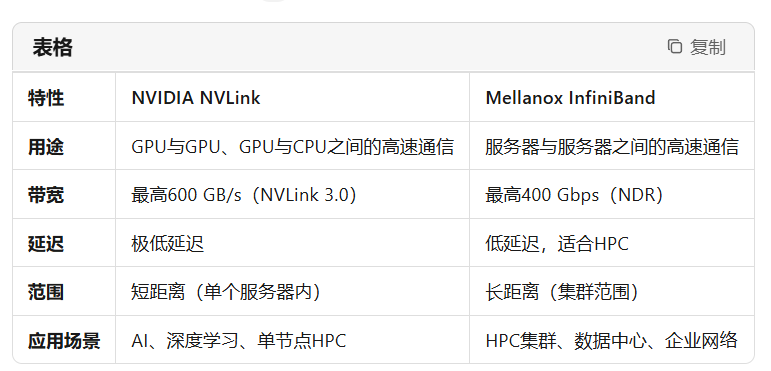
NVLink主要用于单节点内部不同GPU之间的高速通信,InfiniBand主要用于不同节点之间的高速通信。
NVIDIA NVLink技术
由 NVIDIA 开发的 GPU 内部/机箱级高速互联技术 ,专为多 GPU 之间的点对点通信设计,提供 更高带宽 (如 NVLink 4.0 达 1 TB/s)和 更低延迟 (绕过 PCIe 总线)。
典型场景:单台服务器内的多 GPU 互联。
InfiniBand技术
InfiniBand是一种能力很强的通信技术协议,它特别适合计算机集群互联。原来主要是Mellanox公司在开发这项技术,2019年该公司被英伟达收购。2012年之后,随着高性能计算(HPC)需求的不断增长,InfiniBand技术的市场份额越来越高,并在2015年超过了50%,成为超级计算机的首选内部互联技术。
InifiBand的核心技术是RDMA(Remote Direct Memory Access,远程直接数据存取)协议。
技术层级协同
在实际系统中,两者常结合使用:
单机内部 :通过 NVLink 实现 GPU 间的高速直连(如 8 个 A100 通过 NVLink 组成全互连拓扑)。
跨机互联 :通过 Mellanox InfiniBand 连接多台服务器,构建超大规模 GPU 集群(如 NVIDIA DGX SuperPOD)。
这种分层架构既能利用 NVLink 的低延迟优势,又能通过 InfiniBand 的高扩展性满足分布式训练/推理需求。
对比表格
总结
NVLink 专注于同一节点内的GPU与GPU或GPU与CPU之间的高速通信,适用于需要密集GPU计算的任务,如深度学习和AI。
InfiniBand 则用于连接多个服务器或节点,支持大规模分布式计算和数据中心的高性能网络需求。
两者在高性能计算领域中相辅相成,NVLink优化了节点内的计算效率,而InfiniBand则确保了跨节点的高效通信。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









