






什么是Cgroups
Cgroups 是 control groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如 CPU、Memory、IO 等等)的机制,为了完成对一组进程进行统一的资源监控和限制。
Cgroups 分 v1 和 v2 两个版本:
- v1 实现较早,功能比较多,但是由于它里面的功能都是零零散散的实现的,所以规划的不是很好,导致了一些使用和维护上的不便。
- v2 的出现就是为了解决 v1 的问题,在最新的 4.5 内核中,Cgroups v2
声称已经可以用于生产环境了,但它所支持的功能还很有限。
核心三部件
- cgroups(结构体)本身:cgroup 是对进程分组管理的一种机制,一个 cgroup 包含一组进程,并可以在这个 cgroup上增加Linux subsystem 的各种参数配置,将一组进程和一组 subsystem 的系统参数关联起来。
- subsystem(子系统): 一个 subsystem 就是一个内核模块,他被关联到一颗cgroup 树之后,就会在树的每个节点(进程组)上做具体的操作。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU的使用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等。
- hierarchy(cgroups层级结构):一个 hierarchy 可以理解为一棵 cgroup 树,树的每个节点就是一个进程组,每棵树都会与零到多个subsystem 关联。
三者之间的关系:
- 系统在创建了新的 hierarchy 之后,系统中所有的进程都会加入这个 hierarchy 的cgroup根节点,这个 cgroup根节点是 hierarchy 默认创建的。
- 一个 subsystem 只能附加到 一 个 hierarchy 上面。
- 一个 hierarchy 可以附加多个 subsystem 。
- 一个进程可以作为多个 cgroup 的成员,但是这些 cgroup 必须在不同的 hierarchy 中。
- 一个进程fork出子进程时,子进程是和父进程在同一个 cgroup 中的,也可以根据需要将其移动到其他 cgroup 中。
理解:
- cgroup 用于对进程进行分组。
- hierarchy 则根据继承关系,将多个 cgroup 组成一棵树。
- subsystem 则负责资源限制的工作,将 subsystem 和 hierarchy 绑定后,该 hierarchy 上的所有cgroup 下的进程都会被 subsystem 给限制。
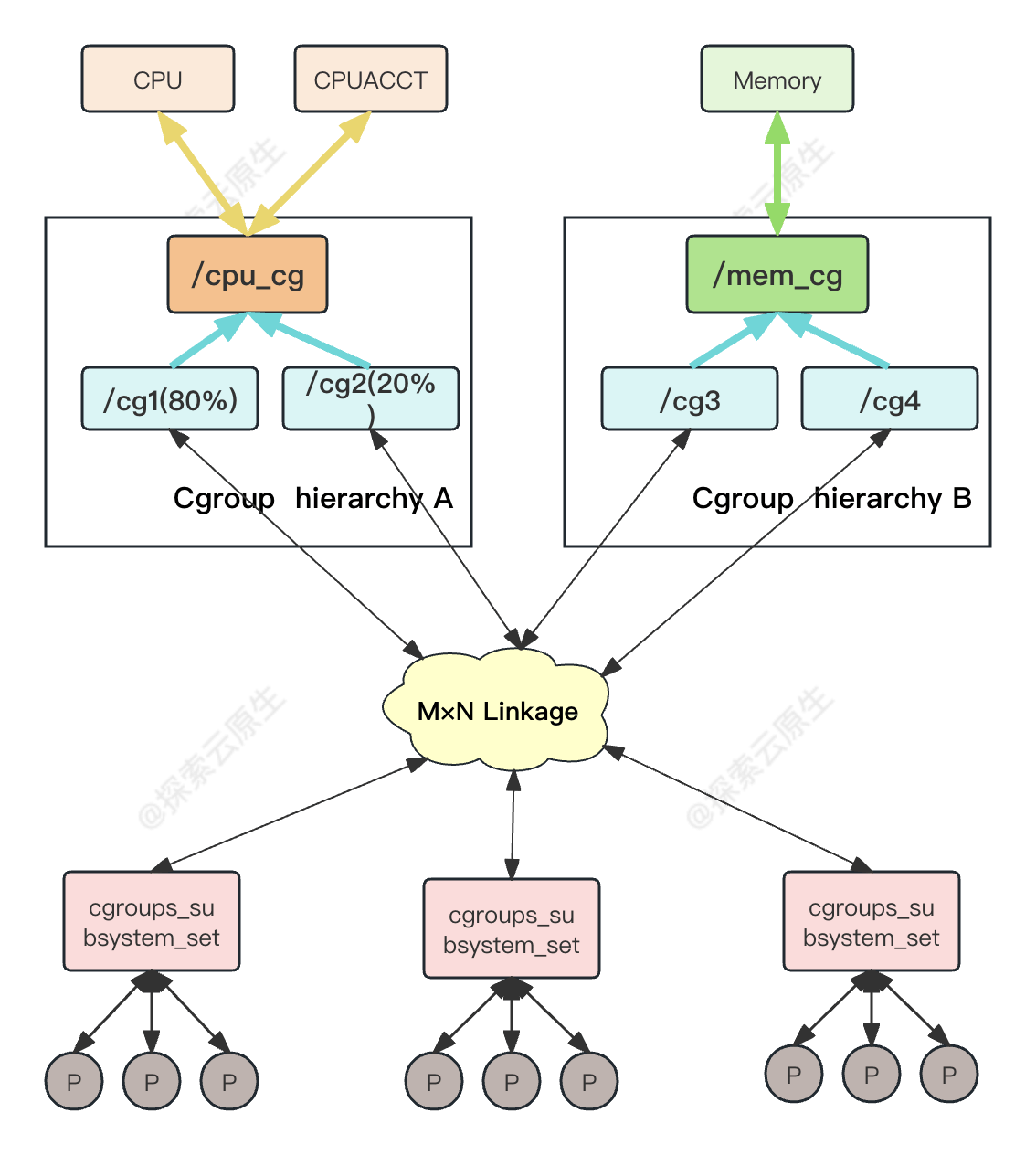
比如上图表示两个 hierarchiy,每一个 hierarchiy 中是一颗树形结构,树的每一个节点是一个 cgroup结构体 (比如 cpu_cgrp, memory_cgrp)。
- 第一个 hierarchiy attach 了 cpu 子系统和 cpuacct 子系统, 因此当前 hierarchiy 中的
cgroup 就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。 - 第二个 hierarchiy attach 了 memory 子系统,因此当前 hierarchiy 中的 cgroup 就可以对
memory 的资源进行限制。
在每一个 hierarchiy 中,每一个节点(cgroup)可以设置对资源不同的限制权重(即自定义配置)。比如上图中 cgrp1 组中的进程可以使用 60%的 cpu 时间片,而 cgrp2 组中的进程可以使用 20%的 cpu 时间片。
cgroups 和 进程间的关系:
上面这个图从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。
- 每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
- 上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups的实现不允许css_set同时关联同一个 cgroups 层级结构下多个节点。 这是因为 cgroups对同一种资源不允许有多个限制配置。
- 一个css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源(可以理解是一种cgroup结构体的限制能力)的控制。而一个cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
一个节点的控制列表中的所有进程都会受到当前节点的资源限制。同时某一个进程也可以被加入到不同的 cgroups 层级结构的节点中,因为不同的 cgroups 层级结构可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。
完成的链路情况:
多个P进程加入到css_set进程链表内,通过MxN Links跟cgroup结构体实现多对多的关联,cgroup结构体本身有对css_set和subsystem的关联限制下进行关联,形成cgroups层级结构也就形成了hierarchy。
cgroup的使用
cgroup 相关的所有操作都是基于内核中的 cgroup virtual filesystem,使用 cgroup 很简单,挂载这个文件系统就行。
groups 以文件的方式提供应用接口,我们可以通过 mount 命令来查看 cgroups 默认的挂载点:
[root@localhost ~]# mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
一般情况下都是挂载到/sys/fs/cgroup 目录下,当然挂载到其它任何目录都问题。
- 第一行的 tmpfs 说明 /sys/fs/cgroup 目录下的文件都是存在于内存中的临时文件。
- 第二行的挂载点 /sys/fs/cgroup/systemd 用于 systemd 系统对 cgroups 的支持。
- 其余的挂载点则是内核支持的各个子系统的根级层级结构。
需要注意的是,在使用 systemd 系统的操作系统中,/sys/fs/cgroup 目录都是由 systemd 在系统启动的过程中挂载的,并且挂载为只读的类型。换句话说,系统是不建议我们在 /sys/fs/cgroup 目录下创建新的目录并挂载其它子系统的。这一点与之前的操作系统不太一样。
查看 subsystem 列表
查看/proc/cgroups知道当前系统支持哪些 subsystem
[root@localhost ~]# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 8 4 1
cpu 3 64 1
cpuacct 3 64 1
memory 9 64 1
devices 5 64 1
freezer 10 4 1
net_cls 4 4 1
blkio 11 64 1
perf_event 7 4 1
hugetlb 2 4 1
pids 6 64 1
net_prio 4 4 1
从左到右,字段的含义分别是:
- subsys_name:subsystem 的名字
- hierarchy:subsystem 所关联到的 cgroup 树的 ID,如果多个 subsystem 关联到同一颗 cgroup树,那么他们的这个字段将一样,比如这里的 cpu 和 cpuacct 就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为0:
- 当前 subsystem 没有和任何 cgroup 树绑定
- 当前 subsystem 已经和 cgroup v2 的树绑定
- 当前 subsystem 没有被内核开启
- num_cgroups:subsystem 所关联的 cgroup 树中进程组的个数,也即树上节点的个数
- enabled:1 表示开启,0 表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制 subsystem的开启).
Cgroups层级结构相关操作
Linux 中,用户可以使用 mount 命令挂载 cgroups 文件系统:
语法为: mount -t cgroup -o subsystems name /cgroup/name
- 其中 subsystems 表示需要挂载的 cgroups 子系统
- /cgroup/name 表示挂载点
这条命令同在内核中创建了一个 hierarchy 以及一个默认的 root cgroup。
示例:
挂载
挂载一个和 cpuset subsystem 关联的 hierarchy 到 ./test 目录
# 首先肯定是创建对应目录
mkdir test
# 具体挂载操作--参数含义如下
# -t cgroup 表示操作的是 cgroup 类型,
# -o cpuset 表示要关联 cpuset subsystem,可以写0个或多个,0个则是关联全部subsystem,
# test 为 cgroup 的名字,
# ./test 为挂载目标目录。
mount -t cgroup -o cpuset test ./test
# 挂载一颗和所有subsystem关联的cgroup树到test目录
mkdir test
mount -t cgroup test ./test
#挂载一颗与cpu和cpuacct subsystem关联的cgroup树到 test 目录
mkdir test
mount -t cgroup -o cpu,cpuacct test ./test
# 挂载一棵cgroup树,但不关联任何subsystem,这systemd所用到的方式
mkdir test
mount -t cgroup -o none,name=test test ./test
卸载
作为文件系统,同样是使用umount 命令卸载。
# 指定路径来卸载,而不是名字。
$ umount /path/to/your/hierarchy
例如:
[root@localhost ~]# umount /sys/fs/cgroup/cpuset/
[root@localhost ~]# umount /sys/fs/cgroup/cpuset
umount: /sys/fs/cgroup/cpuset:未挂载
cgroup 相关操作
创建 cgroup 比较简单,直接在 hierarchy 或 cgroup 目录下创建子目录(mkdir)即可。
删除则是删除对应目录(rmdir)。
不能直接递归删除对应目录,因为目录中的文件是虚拟的,递归删除时会报错。
可以借助 libcgroup 工具来创建或删除。
[root@localhost ~]# yum install libcgroup
[root@localhost ~]# yum install libcgroup-tools
操作
# path可以用相对路径或者绝对路径,controllers就是subsystem
[root@localhost ~]# cgdelete controllers:path
例如
[root@localhost ~]# cgdelete cpu:./mycgroup
演示
分别演示以下直接在某个已存在的 hierarchy 下创建子 cgroup 或者直接创建一个新的 hierarchy 两种方式。
1、新 hierarchy 方式
创建 hierarchy
首先,要创建并挂载一个 hierarchy。
[root@localhost ~]# mkdir cgroup-test
[root@localhost ~]# mount -t cgroup -o none,name=cgroup-test cgroup-test ./cgroup-test
[root@localhost ~]# cd cgroup-test
[root@localhost cgroup-test]# ls
cgroup.clone_children cgroup.event_control cgroup.procs cgroup.sane_behavior notify_on_release release_agent tasks
这些文件就是 hierarchy 中 cgroup 根节点的配置项。具体含义如下:
- cgroup.clone_ children, cpuset 的 subsystem 会读取这个配置文件,如果这个值是 1 (默认是0),子 cgroup 才会继承父 cgroup 的 cpuset 的配置。
- cgroup.procs 是树中当前节点 cgroup 中的进程组 ID,现在的位置是在根节点,这个文件中会有现在系统中所有进程组的ID。
- notify_on_release 和 release agent 会一起使用。 notify_on_release 标识当这个cgroup 最后一个进程退出的时候是否执行了 release_agent; release_agent则是一个路径,通常用作进程退出之后自动清理掉不再使用的 cgroup。
- tasks 标识该 cgroup 下面的进程 ID,如果把一个进程 ID 写到 tasks 文件中,便会将相应的进程加入到这个cgroup 中。
创建子 cgroup
然后,从刚创建好的 hierarchy 上 cgroup 根节点中扩展出两个子 cgroup:
[root@localhost cgroup-test]# mkdir cgroup-1
[root@localhost cgroup-test]# mkdir cgroup-2
[root@localhost cgroup-test]# tree
.
├── cgroup-1
│ ├── cgroup.clone_children
│ ├── cgroup.event_control
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
├── cgroup-2
│ ├── cgroup.clone_children
│ ├── cgroup.event_control
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── cgroup.sane_behavior
├── notify_on_release
├── release_agent
└── tasks
可以看到,在一个 cgroup 的目录下创建文件夹时,Kernel 会把文件夹标记为这个 cgroup 的子 cgroup,它们会继承父 cgroup 的属性。
cgroup 中添加和移动进程
一个进程在一个 Cgroups 的 hierarchy 中,只能在一个 cgroup 节点上存在,系统的所有进程都会默认在根节点上存在。
想要将进程移动到其他 cgroup 节点,只需要将进程 ID 写到目标 cgroup 节点的 tasks 文件中即可。
将当前 shell 所在进程添加到 tasks:
[root@localhost cgroup-1]# cat tasks
4457
[root@localhost cgroup-1]# cat /proc/4457/cgroup
13:name=cgroup-test:/cgroup-1
11:blkio:/user.slice
10:freezer:/
9:memory:/user.slice
8:cpuset:/
7:perf_event:/
6:pids:/user.slice
5:devices:/user.slice
4:net_prio,net_cls:/
3:cpuacct,cpu:/user.slice
2:hugetlb:/
1:name=systemd:/user.slice/user-0.slice/session-97.scope
通过 subsystem 限制 cgroup 中的进程
在上面创建 hierarchy 的时候,这个 hierarchy 并没有关联到任何的 subsystem ,所以没办法通过那个 hierarchy 中的 cgroup 节点限制进程的资源占用。只能在创建 hierarchy 时指定要关联哪些 subsystem,创建后就无法修改。
其实系统默认已经为每个 subsystem 创建了一个默认的 hierarchy,比如 memory 的 hierarchy。
[root@localhost /]# mount | grep mem
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
[root@localhost /]# cd /sys/fs/cgroup/memory/
[root@localhost memory]# ls
cgroup.clone_children memory.force_empty memory.kmem.tcp.limit_in_bytes memory.memsw.failcnt memory.oom_control memory.use_hierarchy
cgroup.event_control memory.kmem.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.limit_in_bytes memory.pressure_level notify_on_release
cgroup.procs memory.kmem.limit_in_bytes memory.kmem.tcp.usage_in_bytes memory.memsw.max_usage_in_bytes memory.soft_limit_in_bytes release_agent
cgroup.sane_behavior memory.kmem.max_usage_in_bytes memory.kmem.usage_in_bytes memory.memsw.usage_in_bytes memory.stat system.slice
docker memory.kmem.slabinfo memory.limit_in_bytes memory.move_charge_at_immigrate memory.swappiness tasks
memory.failcnt memory.kmem.tcp.failcnt memory.max_usage_in_bytes memory.numa_stat memory.usage_in_bytes user.slice
[root@localhost memory]# ls tasks
tasks
[root@localhost memory]# head -n 5 tasks
1
2
4
6
7
2、子 cgroup 方式
在很多使用 systemd 的系统中,systemd 已经帮我们将各个 subsystem 和 cgroup 树关联并挂载好了:如memory、cpu等。
[root@localhost ~]# mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
因此我们可以直接在对应 cgroup 树下创建子 cgroup 即可。
直接进到 /sys/fs/cgroup/cpu 目录创建 cgroup-cpu 子目录即可:
[root@localhost ~]# cd /sys/fs/cgroup/cpu
[root@localhost cpu]# ls
cgroup.clone_children cgroup.procs cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat notify_on_release system.slice user.slice
cgroup.event_control cgroup.sane_behavior cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares docker release_agent tasks
[root@localhost cpu]# mkdir cgroup-cpu
[root@localhost cpu]# cd cgroup-cpu
[root@localhost cgroup-cpu]# ls
cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
测试一下,执行下面这条命令:
[root@localhost cgroup-cpu]# while : ; do : ; done &
[1] 5165
显然,它执行了一个死循环,可以把计算机的 CPU 吃到 100%,根据它的输出,我们可以看到这个脚本在后台运行的进程号(PID)是 5165。
查看一下 CPU 占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5165 root 20 0 115544 632 164 R 100.0 0.0 1:06.10 bash
果然这个 PID=5165 的进程占用了100% 的 CPU。
结下来我们就通过 Cgroups 对其进行限制,这里就用前面创建的 cgroup-cpu 控制组。
我们可以通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
[root@localhost cgroup-cpu]# pwd
/sys/fs/cgroup/cpu/cgroup-cpu
[root@localhost cgroup-cpu]# cat cpu.cfs_quota_us
-1
[root@localhost cgroup-cpu]# cat cpu.cfs_period_us
100000
接下来,我们可以通过修改这些文件的内容来设置限制。比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
这样意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。再把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了。
[root@localhost cgroup-cpu]# echo 20000 > /sys/fs/cgroup/cpu/cgroup-cpu/cpu.cfs_quota_us
[root@localhost cgroup-cpu]# echo 5165 > /sys/fs/cgroup/cpu/cgroup-cpu/tasks
[root@localhost cgroup-cpu]# cat /sys/fs/cgroup/cpu/cgroup-cpu/cpu.cfs_quota_us
20000
[root@localhost cgroup-cpu]# cat /sys/fs/cgroup/cpu/cgroup-cpu/tasks
5165
查看该进程的top cpu使用率:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5165 root 20 0 115544 632 164 R 19.9 0.0 6:23.31 bash
cpu被限制到了20%左右。
汇总一波:
使用步骤:
1)创建 cgroup
2)配置 subsystem 参数
3)将进程加入到该 cgroup
实现原理:
cgroup结构体负责绑定进程链路和subsystem,俗称挂载;一个或者多个绑定组成cgroups树(hierarchy ),通过subsystem对进程链路的进程进行资源限制。















 3054
3054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









