








Linux 内核系列文章
Linux 内核设计与实现
深入理解 Linux 内核
Linux 设备驱动程序
Linux设备驱动开发详解
文章目录
一、前言
本章主要用来摘录《Linux 内核设计与实现》一书中学习知识点,其基于 Linux 2.6.34 。
二、进程管理
1、task_struct
// include/linux/sched.h
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
int lock_depth; /* BKL lock depth */
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu;
#endif
#endif
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
/*
* fpu_counter contains the number of consecutive context switches
* that the FPU is used. If this is over a threshold, the lazy fpu
* saving becomes unlazy to save the trap. This is an unsigned char
* so that after 256 times the counter wraps and the behavior turns
* lazy again; this to deal with bursty apps that only use FPU for
* a short time
*/
unsigned char fpu_counter;
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
cpumask_t cpus_allowed;
#ifdef CONFIG_TREE_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct rcu_node *rcu_blocked_node;
struct list_head rcu_node_entry;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
struct list_head tasks;
struct plist_node pushable_tasks;
struct mm_struct *mm, *active_mm;
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat;
#endif
/* task state */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1; /* Tell the LSMs that the process is doing an
* execve */
unsigned in_iowait:1;
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1;
pid_t pid;
pid_t tgid;
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/*
* ptraced is the list of tasks this task is using ptrace on.
* This includes both natural children and PTRACE_ATTACH targets.
* p->ptrace_entry is p's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/*
* This is the tracer handle for the ptrace BTS extension.
* This field actually belongs to the ptracer task.
*/
struct bts_context *bts;
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING
cputime_t prev_utime, prev_stime;
#endif
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
/* process credentials */
const struct cred *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred *cred; /* effective (overridable) subjective task
* credentials (COW) */
struct mutex cred_guard_mutex; /* guard against foreign influences on
* credential calculations
* (notably. ptrace) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by setup_new_exec */
/* file system info */
int link_count, total_link_count;
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
/* hung task detection */
unsigned long last_switch_count;
#endif
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespaces */
struct nsproxy *nsproxy;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
struct audit_context *audit_context;
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid;
unsigned int sessionid;
#endif
seccomp_t seccomp;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed,
* mempolicy */
spinlock_t alloc_lock;
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
struct irqaction *irqaction;
#endif
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;
/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* mutex deadlock detection */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
unsigned long hardirq_enable_ip;
unsigned long hardirq_disable_ip;
unsigned int hardirq_enable_event;
unsigned int hardirq_disable_event;
int hardirqs_enabled;
int hardirq_context;
unsigned long softirq_disable_ip;
unsigned long softirq_enable_ip;
unsigned int softirq_disable_event;
unsigned int softirq_enable_event;
int softirqs_enabled;
int softirq_context;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
gfp_t lockdep_reclaim_gfp;
#endif
/* journalling filesystem info */
void *journal_info;
/* stacked block device info */
struct bio_list *bio_list;
/* VM state */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* For ptrace use. */
struct task_io_accounting ioac;
#if defined(CONFIG_TASK_XACCT)
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
cputime_t acct_timexpd; /* stime + utime since last update */
#endif
#ifdef CONFIG_CPUSETS
nodemask_t mems_allowed; /* Protected by alloc_lock */
int cpuset_mem_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock */
struct css_set *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp;
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy; /* Protected by alloc_lock */
short il_next;
#endif
atomic_t fs_excl; /* holding fs exclusive resources */
struct rcu_head rcu;
/*
* cache last used pipe for splice
*/
struct pipe_inode_info *splice_pipe;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
#endif
struct prop_local_single dirties;
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/*
* time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
struct list_head *scm_work_list;
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack */
int curr_ret_stack;
/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;
/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun.
*/
atomic_t trace_overrun;
/* Pause for the tracing */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* state flags for use by tracers */
unsigned long trace;
/* bitmask of trace recursion */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
#ifdef CONFIG_CGROUP_MEM_RES_CTLR /* memcg uses this to do batch job */
struct memcg_batch_info {
int do_batch; /* incremented when batch uncharge started */
struct mem_cgroup *memcg; /* target memcg of uncharge */
unsigned long bytes; /* uncharged usage */
unsigned long memsw_bytes; /* uncharged mem+swap usage */
} memcg_batch;
#endif
};
进程描述符 task_struct 包含了一个具体进程的所有信息。其相对较大,在 32 位机器上,它大约有 1.7KB。
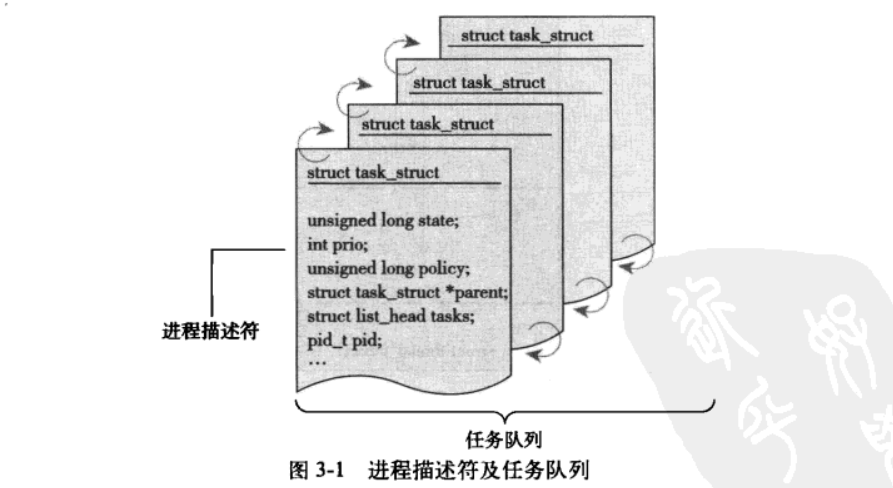
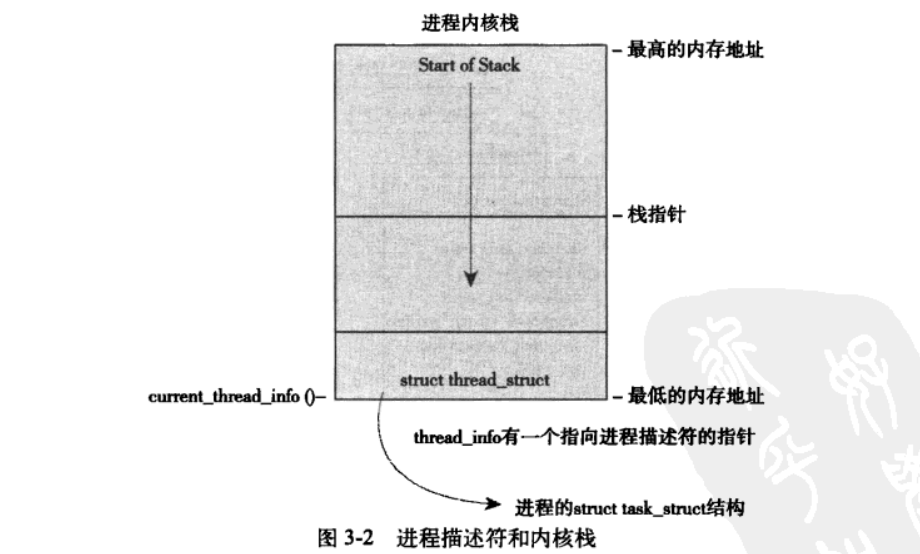
Linux 通过 slab 分配器分配 task_struct 结构。在 2.6 以前的内核中,各个进程的 task_struct 存放在它们内核栈的尾端。这样做是为了让那些像 x86 那样寄存器较少的硬件体系结构只要通过栈指针就能计算出它的位置,而避免使用额外的寄存器专门记录。由于现在用 slab 分配器动态生成 task_struct ,所以只需要在栈底创建一个新的结构 struct thread_info 。
2、thread_info
// arch/x86/include/asm/thread_info.h
struct thread_info {
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
int preempt_count; /* 0 => preemptable,
<0 => BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* ESP of the previous stack in
case of nested (IRQ) stacks
*/
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};
三、调度
CFS 调度
四、系统调用
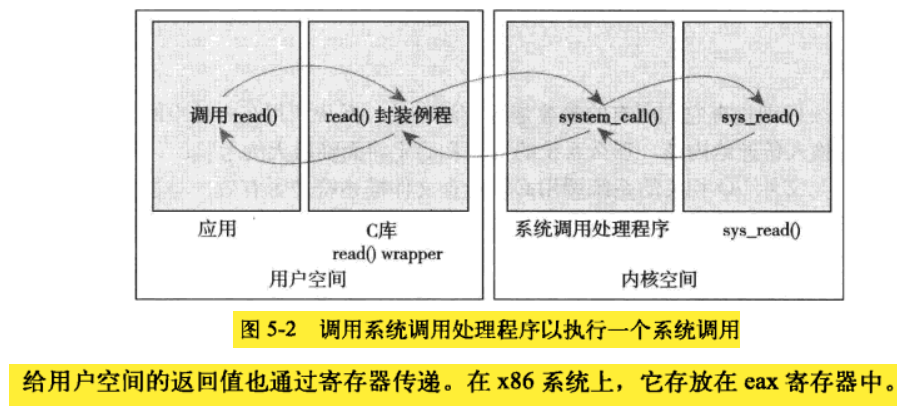
用户空间的程序无法直接执行内核代码。它们不能直接调用内核空间中的函数,因为内核驻留在受保护的地址空间上。
x86 系统通过 int $0x80 指令触发系统调用。系统调用号是通过 eax 寄存器传递给内核的。其响应函数 system_call() 函数通过将给定的系统调用号与 NR_syscalls 做比较来检查其有效性。如果它大于或者等于 NR_syscalls ,该函数就返回 -ENOSYS 。否则,就执行相应的系统调用:
call *sys_call_table(, %rax, 8)
由于系统调用表中的表项是以 64 位(8字节)类型存放的,所以内核需要将给定的系统调用号乘以 8,然后用所得的成果在该表中查询其位置。
除了系统调用号以外,大部分系统调用都还需要一些外部的参数输入。所以,在发生陷入的时候,应该把这些参数从用户空间传给内核。在 x86-32 系统上, ebx、ecx、edx、esi 和 edi 按照顺序存放前五个参数。需要六个或六个以上参数则应该用一个单独的寄存器存放指向所有这些参数在用户空间地址的指针。
五、内核数据结构
1、kfifo
// kernel/kfifo.c
/**
* 使用 buffer 内存创建并初始化kfifo队列
*
* @param fifo kfifo队列
* @param buffer 指向内存地址
* @param size 内存大小,必须是 2 的幂
*/
void kfifo_init(struct kfifo *fifo, void *buffer, unsigned int size);
/**
* 动态创建并初始化kfifo队列
*
* @param fifo kfifo队列
* @param size 创建kfifo队列大小
* @param gfp_mask 标识
* @return
*/
int kfifo_alloc(struct kfifo *fifo, unsigned int size, gfp_t gfp_mask);
/**
* 把数据推入到队列。该函数把 from 指针所指的 len 字节数据拷贝到 fifo 所指的队列中,如果成功,
* 则返回推入数据的字节大小。如果队列中的空闲字节小于 len,则该函数值最多可拷贝队列可用空间那么多
* 的数据,这样的话,返回值可能小于 len。
*/
unsigned int kfifo_in(struct kfifo *fifo, const void *from, unsigned int len);
/**
* 该函数从 fifo 所指向的队列中拷贝出长度为 len 字节的数据到 to 所指的缓冲中。如果成功,
* 该函数则返回拷贝的数据长度。如果队列中数据大小小于 len, 则该函数拷贝出的数据必然小于
* 需要的数据大小
*/
unsigned int kfifo_out(struct kfifo *fifo, void *to, unsigned int len);
/**
* 与 kfifo_out 类似,获取数据,但读后不删除数据。参数 offset 指向队列中的索引位置,如果
* 该参数为 0,则读队列头,这时候和 kfifo_out 一样。
*/
unsigned int kfifo_out_peek(struct kfifo *fifo, void *to, unsigned int len, unsigned offset);


2、映射
// include/linux/idr.h
void *idr_find(struct idr *idp, int id);
int idr_pre_get(struct idr *idp, gfp_t gfp_mask);
int idr_get_new(struct idr *idp, void *ptr, int *id);
int idr_get_new_above(struct idr *idp, void *ptr, int starting_id, int *id);
int idr_for_each(struct idr *idp,
int (*fn)(int id, void *p, void *data), void *data);
void *idr_get_next(struct idr *idp, int *nextid);
void *idr_replace(struct idr *idp, void *ptr, int id);
void idr_remove(struct idr *idp, int id);
void idr_remove_all(struct idr *idp);
void idr_destroy(struct idr *idp);
void idr_init(struct idr *idp);
3、二叉树
// include/linux/rbtree.h
struct rb_node
{
unsigned long rb_parent_color;
#define RB_RED 0
#define RB_BLACK 1
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
/* The alignment might seem pointless, but allegedly CRIS needs it */
struct rb_root
{
struct rb_node *rb_node;
};
#define rb_parent(r) ((struct rb_node *)((r)->rb_parent_color & ~3))
#define rb_color(r) ((r)->rb_parent_color & 1)
#define rb_is_red(r) (!rb_color(r))
#define rb_is_black(r) rb_color(r)
#define rb_set_red(r) do { (r)->rb_parent_color &= ~1; } while (0)
#define rb_set_black(r) do { (r)->rb_parent_color |= 1; } while (0)
static inline void rb_set_parent(struct rb_node *rb, struct rb_node *p)
{
rb->rb_parent_color = (rb->rb_parent_color & 3) | (unsigned long)p;
}
static inline void rb_set_color(struct rb_node *rb, int color)
{
rb->rb_parent_color = (rb->rb_parent_color & ~1) | color;
}
#define RB_ROOT (struct rb_root) { NULL, }
#define rb_entry(ptr, type, member) container_of(ptr, type, member)
#define RB_EMPTY_ROOT(root) ((root)->rb_node == NULL)
#define RB_EMPTY_NODE(node) (rb_parent(node) == node)
#define RB_CLEAR_NODE(node) (rb_set_parent(node, node))
extern void rb_insert_color(struct rb_node *, struct rb_root *);
extern void rb_erase(struct rb_node *, struct rb_root *);
/* Find logical next and previous nodes in a tree */
extern struct rb_node *rb_next(const struct rb_node *);
extern struct rb_node *rb_prev(const struct rb_node *);
extern struct rb_node *rb_first(const struct rb_root *);
extern struct rb_node *rb_last(const struct rb_root *);
/* Fast replacement of a single node without remove/rebalance/add/rebalance */
extern void rb_replace_node(struct rb_node *victim, struct rb_node *new,
struct rb_root *root);
static inline void rb_link_node(struct rb_node * node, struct rb_node * parent,
struct rb_node ** rb_link)
{
node->rb_parent_color = (unsigned long )parent;
node->rb_left = node->rb_right = NULL;
*rb_link = node;
}
六、中断

1、软中断
// include/linux/interrupt.h
/**
* struct irqaction - per interrupt action descriptor
* @handler: interrupt handler function
* @flags: flags (see IRQF_* above)
* @name: name of the device
* @dev_id: cookie to identify the device
* @next: pointer to the next irqaction for shared interrupts
* @irq: interrupt number
* @dir: pointer to the proc/irq/NN/name entry
* @thread_fn: interupt handler function for threaded interrupts
* @thread: thread pointer for threaded interrupts
* @thread_flags: flags related to @thread
*/
struct irqaction {
irq_handler_t handler;
unsigned long flags;
const char *name;
void *dev_id;
struct irqaction *next;
int irq;
struct proc_dir_entry *dir;
irq_handler_t thread_fn;
struct task_struct *thread;
unsigned long thread_flags;
};
struct softirq_action
{
void (*action)(struct softirq_action *);
};
2、tasklet
// include/linux/interrupt.h
/* Tasklets --- multithreaded analogue of BHs.
Main feature differing them of generic softirqs: tasklet
is running only on one CPU simultaneously.
Main feature differing them of BHs: different tasklets
may be run simultaneously on different CPUs.
Properties:
* If tasklet_schedule() is called, then tasklet is guaranteed
to be executed on some cpu at least once after this.
* If the tasklet is already scheduled, but its excecution is still not
started, it will be executed only once.
* If this tasklet is already running on another CPU (or schedule is called
from tasklet itself), it is rescheduled for later.
* Tasklet is strictly serialized wrt itself, but not
wrt another tasklets. If client needs some intertask synchronization,
he makes it with spinlocks.
*/
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
3、工作队列
// kernel/workqueue.c
struct cpu_workqueue_struct {
spinlock_t lock;
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq;
struct task_struct *thread;
} ____cacheline_aligned;
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq;
struct list_head list;
const char *name;
int singlethread;
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
4、下半部机制的选择

5、下半部禁止与使能

七、内核同步方法
1、原子操作
在 x86 上,实现在 arch/x86/include/asm/atomic.h 文件中。

2、自旋锁
(1)结构体
// include/linux/spinlock_types.h
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
// arch/x86/include/asm/spinlock_types.h
typedef struct arch_spinlock {
unsigned int slock;
} arch_spinlock_t;
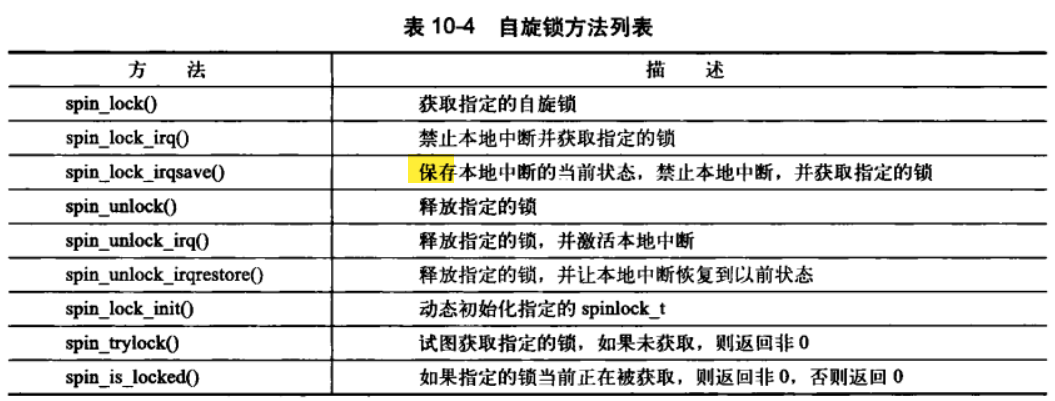
(2)方法说明
函数定义在文件 include/linux/spinlock.h 中
(3)raw_spin_lock 函数分析
- raw_spin_lock 函数
// include/linux/spinlock.h
#define raw_spin_lock(lock) _raw_spin_lock(lock)
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
- _raw_spin_lock 函数
// // kernel/spinlock.c
#ifndef CONFIG_INLINE_SPIN_LOCK
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
#endif
- __raw_spin_lock 函数
// include/linux/spinlock_api_smp.h
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
- do_raw_spin_lock 函数
// include/linux/spinlock.h
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
}
- arch_spin_lock 函数
// arch/x86/include/asm/spinlock.h
static __always_inline void arch_spin_lock(arch_spinlock_t *lock)
{
__ticket_spin_lock(lock);
}
static __always_inline void __ticket_spin_lock(arch_spinlock_t *lock)
{
short inc = 0x0100;
asm volatile (
LOCK_PREFIX "xaddw %w0, %1\n"
"1:\t"
"cmpb %h0, %b0\n\t"
"je 2f\n\t"
"rep ; nop\n\t"
"movb %1, %b0\n\t"
/* don't need lfence here, because loads are in-order */
"jmp 1b\n"
"2:"
: "+Q" (inc), "+m" (lock->slock)
:
: "memory", "cc");
}
3、读写自旋锁
(1)结构体
// include/linux/rwlock_types.h
typedef struct {
arch_rwlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} rwlock_t;
// arch/x86/include/asm/spinlock_types.h
typedef struct {
unsigned int lock;
} arch_rwlock_t;
(2)方法说明
函数定义在文件 include/linux/rwlock.h 中

(3)read_lock函数分析
- read_lock 函数
// include/linux/rwlock.h
#define read_lock(lock) _raw_read_lock(lock)
- _raw_read_lock 函数
// include/linux/rwlock_api_smp.h
#ifdef CONFIG_INLINE_READ_LOCK
#define _raw_read_lock(lock) __raw_read_lock(lock)
#endif
// include/linux/rwlock_api_smp.h
static inline void __raw_read_lock(rwlock_t *lock)
{
preempt_disable();
rwlock_acquire_read(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_read_trylock, do_raw_read_lock);
}
- do_raw_read_lock 函数
// include/linux/rwlock.h
# define do_raw_read_lock(rwlock) do {__acquire(lock); arch_read_lock(&(rwlock)->raw_lock); } while (0)
- arch_read_lock 函数
// arch/x86/include/asm/spinlock.h
static inline void arch_read_lock(arch_rwlock_t *rw)
{
asm volatile(LOCK_PREFIX " subl $1,(%0)\n\t"
"jns 1f\n"
"call __read_lock_failed\n\t"
"1:\n"
::LOCK_PTR_REG (rw) : "memory");
}
4、信号量
(1)结构体
struct semaphore {
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
(2)方法说明
函数定义在文件 include/linux/semaphore.h 中,其允许进入睡眠。不能用在中断上下文,只能用在进程上下文。

(3)down_interruptible 函数分析
- down_interruptible 函数
// include/linux/semaphore.h
extern int __must_check down_interruptible(struct semaphore *sem);
// kernel/semaphore.c
/**
* down_interruptible - acquire the semaphore unless interrupted
* @sem: the semaphore to be acquired
*
* Attempts to acquire the semaphore. If no more tasks are allowed to
* acquire the semaphore, calling this function will put the task to sleep.
* If the sleep is interrupted by a signal, this function will return -EINTR.
* If the semaphore is successfully acquired, this function returns 0.
*/
int down_interruptible(struct semaphore *sem)
{
unsigned long flags;
int result = 0;
spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_interruptible(sem);
spin_unlock_irqrestore(&sem->lock, flags);
return result;
}
EXPORT_SYMBOL(down_interruptible);
- __down_interruptible 函数
// kernel/semaphore.c
static noinline int __sched __down_interruptible(struct semaphore *sem)
{
return __down_common(sem, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
- __down_common 函数
// kernel/semaphore.c
/*
* Because this function is inlined, the 'state' parameter will be
* constant, and thus optimised away by the compiler. Likewise the
* 'timeout' parameter for the cases without timeouts.
*/
static inline int __sched __down_common(struct semaphore *sem, long state,
long timeout)
{
struct task_struct *task = current;
struct semaphore_waiter waiter;
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = task;
waiter.up = 0;
for (;;) {
if (signal_pending_state(state, task))
goto interrupted;
if (timeout <= 0)
goto timed_out;
__set_task_state(task, state);
spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
spin_lock_irq(&sem->lock);
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
}
5、读写信号量
(1)结构体
rw_semaphore 结构体定义在各个体系结构下的 rwsem.h 文件中
// arch/x86/include/asm/rwsem.h
struct rw_semaphore {
rwsem_count_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
(2)方法说明
读写信号量函数定义
// include/linux/rwsem.h
/*
* lock for reading
*/
extern void down_read(struct rw_semaphore *sem);
/*
* trylock for reading -- returns 1 if successful, 0 if contention
*/
extern int down_read_trylock(struct rw_semaphore *sem);
/*
* lock for writing
*/
extern void down_write(struct rw_semaphore *sem);
/*
* trylock for writing -- returns 1 if successful, 0 if contention
*/
extern int down_write_trylock(struct rw_semaphore *sem);
/*
* release a read lock
*/
extern void up_read(struct rw_semaphore *sem);
/*
* release a write lock
*/
extern void up_write(struct rw_semaphore *sem);
/*
* downgrade write lock to read lock
*/
extern void downgrade_write(struct rw_semaphore *sem);
(3)down_read 函数分析
- down_read 函数
// kernel/rwsem.c
/*
* lock for reading
*/
void __sched down_read(struct rw_semaphore *sem)
{
might_sleep();
rwsem_acquire_read(&sem->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(sem, __down_read_trylock, __down_read);
}
EXPORT_SYMBOL(down_read);
- __up_read 函数
// arch/x86/include/asm/rwsem.h
/*
* lock for reading
*/
static inline void __down_read(struct rw_semaphore *sem)
{
asm volatile("# beginning down_read\n\t"
LOCK_PREFIX _ASM_INC "(%1)\n\t"
/* adds 0x00000001, returns the old value */
" jns 1f\n"
" call call_rwsem_down_read_failed\n"
"1:\n\t"
"# ending down_read\n\t"
: "+m" (sem->count)
: "a" (sem)
: "memory", "cc");
}
6、互斥体
(1)结构体
// include/linux/mutex.h
/*
* Simple, straightforward mutexes with strict semantics:
*
* - only one task can hold the mutex at a time
* - only the owner can unlock the mutex
* - multiple unlocks are not permitted
* - recursive locking is not permitted
* - a mutex object must be initialized via the API
* - a mutex object must not be initialized via memset or copying
* - task may not exit with mutex held
* - memory areas where held locks reside must not be freed
* - held mutexes must not be reinitialized
* - mutexes may not be used in hardware or software interrupt
* contexts such as tasklets and timers
*
* These semantics are fully enforced when DEBUG_MUTEXES is
* enabled. Furthermore, besides enforcing the above rules, the mutex
* debugging code also implements a number of additional features
* that make lock debugging easier and faster:
*
* - uses symbolic names of mutexes, whenever they are printed in debug output
* - point-of-acquire tracking, symbolic lookup of function names
* - list of all locks held in the system, printout of them
* - owner tracking
* - detects self-recursing locks and prints out all relevant info
* - detects multi-task circular deadlocks and prints out all affected
* locks and tasks (and only those tasks)
*/
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_SMP)
struct thread_info *owner;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
const char *name;
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
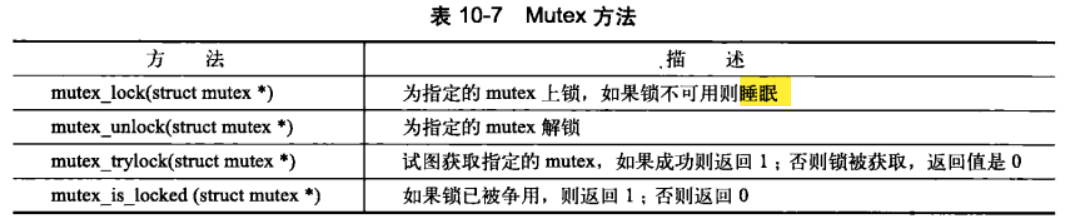
(2)方法说明
函数定义在文件 include/linux/mutex.h 中
(3)mutex_lock 函数分析
- mutex_lock 函数
// include/linux/mutex.h
extern void mutex_lock(struct mutex *lock);
// kernel/mutex.c
/***
* mutex_lock - acquire the mutex
* @lock: the mutex to be acquired
*
* Lock the mutex exclusively for this task. If the mutex is not
* available right now, it will sleep until it can get it.
*
* The mutex must later on be released by the same task that
* acquired it. Recursive locking is not allowed. The task
* may not exit without first unlocking the mutex. Also, kernel
* memory where the mutex resides mutex must not be freed with
* the mutex still locked. The mutex must first be initialized
* (or statically defined) before it can be locked. memset()-ing
* the mutex to 0 is not allowed.
*
* ( The CONFIG_DEBUG_MUTEXES .config option turns on debugging
* checks that will enforce the restrictions and will also do
* deadlock debugging. )
*
* This function is similar to (but not equivalent to) down().
*/
void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
/*
* The locking fastpath is the 1->0 transition from
* 'unlocked' into 'locked' state.
*/
__mutex_fastpath_lock(&lock->count, __mutex_lock_slowpath);
mutex_set_owner(lock);
}
EXPORT_SYMBOL(mutex_lock);
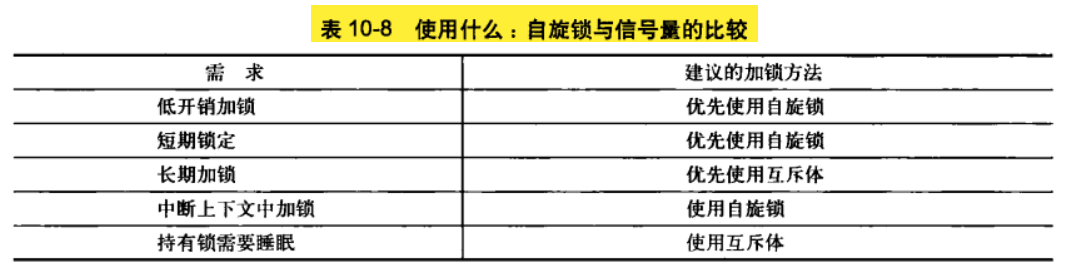
(4)应用比较
7、完成变量
(1)结构体
// include/linux/completion.h
/**
* struct completion - structure used to maintain state for a "completion"
*
* This is the opaque structure used to maintain the state for a "completion".
* Completions currently use a FIFO to queue threads that have to wait for
* the "completion" event.
*
* See also: complete(), wait_for_completion() (and friends _timeout,
* _interruptible, _interruptible_timeout, and _killable), init_completion(),
* and macros DECLARE_COMPLETION(), DECLARE_COMPLETION_ONSTACK(), and
* INIT_COMPLETION().
*/
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
// include/linux/wait.h
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
struct __wait_queue {
unsigned int flags;
#define WQ_FLAG_EXCLUSIVE 0x01
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
(2)方法说明
函数定义在文件 include/linux/completion.h 中

(3)complete 函数分析
- complete 函数
// kernel/sched.c
void complete(struct completion *x)
{
unsigned long flags;
spin_lock_irqsave(&x->wait.lock, flags);
x->done++;
__wake_up_common(&x->wait, TASK_NORMAL, 1, 0, NULL);
spin_unlock_irqrestore(&x->wait.lock, flags);
}
EXPORT_SYMBOL(complete);
- __wake_up_common 函数
// kernel/sched.c
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
8、BLK:大内核锁
(1)方法说明
函数定义在文件 include/linux/smp_lock.h 中

(2)lock_kernel 函数分析
- lock_kernel 函数
// include/linux/smp_lock.h
#define lock_kernel() do { \
_lock_kernel(__func__, __FILE__, __LINE__); \
} while (0)
- _lock_kernel 函数
// lib/kernel_lock.c
void __lockfunc _lock_kernel(const char *func, const char *file, int line)
{
int depth = current->lock_depth + 1;
trace_lock_kernel(func, file, line);
if (likely(!depth)) {
might_sleep();
__lock_kernel();
}
current->lock_depth = depth;
}
- __lock_kernel 函数
// lib/kernel_lock.c
static inline void __lock_kernel(void)
{
do_raw_spin_lock(&kernel_flag);
}
9、顺序锁
(1)结构体
// include/linux/seqlock.h
typedef struct {
unsigned sequence;
spinlock_t lock;
} seqlock_t;
(2)方法说明
// include/linux/seqlock.h
/*
* These macros triggered gcc-3.x compile-time problems. We think these are
* OK now. Be cautious.
*/
#define __SEQLOCK_UNLOCKED(lockname) \
{ 0, __SPIN_LOCK_UNLOCKED(lockname) }
#define SEQLOCK_UNLOCKED \
__SEQLOCK_UNLOCKED(old_style_seqlock_init)
#define seqlock_init(x) \
do { \
(x)->sequence = 0; \
spin_lock_init(&(x)->lock); \
} while (0)
#define DEFINE_SEQLOCK(x) \
seqlock_t x = __SEQLOCK_UNLOCKED(x)
/* Lock out other writers and update the count.
* Acts like a normal spin_lock/unlock.
* Don't need preempt_disable() because that is in the spin_lock already.
*/
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);
++sl->sequence;
smp_wmb();
}
static inline void write_sequnlock(seqlock_t *sl)
{
smp_wmb();
sl->sequence++;
spin_unlock(&sl->lock);
}
static inline int write_tryseqlock(seqlock_t *sl)
{
int ret = spin_trylock(&sl->lock);
if (ret) {
++sl->sequence;
smp_wmb();
}
return ret;
}
/* Start of read calculation -- fetch last complete writer token */
static __always_inline unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret;
repeat:
ret = sl->sequence;
smp_rmb();
if (unlikely(ret & 1)) {
cpu_relax();
goto repeat;
}
return ret;
}
/*
* Test if reader processed invalid data.
*
* If sequence value changed then writer changed data while in section.
*/
static __always_inline int read_seqretry(const seqlock_t *sl, unsigned start)
{
smp_rmb();
return (sl->sequence != start);
}
/*
* Version using sequence counter only.
* This can be used when code has its own mutex protecting the
* updating starting before the write_seqcountbeqin() and ending
* after the write_seqcount_end().
*/
typedef struct seqcount {
unsigned sequence;
} seqcount_t;
#define SEQCNT_ZERO { 0 }
#define seqcount_init(x) do { *(x) = (seqcount_t) SEQCNT_ZERO; } while (0)
/* Start of read using pointer to a sequence counter only. */
static inline unsigned read_seqcount_begin(const seqcount_t *s)
{
unsigned ret;
repeat:
ret = s->sequence;
smp_rmb();
if (unlikely(ret & 1)) {
cpu_relax();
goto repeat;
}
return ret;
}
/*
* Test if reader processed invalid data because sequence number has changed.
*/
static inline int read_seqcount_retry(const seqcount_t *s, unsigned start)
{
smp_rmb();
return s->sequence != start;
}
/*
* Sequence counter only version assumes that callers are using their
* own mutexing.
*/
static inline void write_seqcount_begin(seqcount_t *s)
{
s->sequence++;
smp_wmb();
}
static inline void write_seqcount_end(seqcount_t *s)
{
smp_wmb();
s->sequence++;
}
/*
* Possible sw/hw IRQ protected versions of the interfaces.
*/
#define write_seqlock_irqsave(lock, flags) \
do { local_irq_save(flags); write_seqlock(lock); } while (0)
#define write_seqlock_irq(lock) \
do { local_irq_disable(); write_seqlock(lock); } while (0)
#define write_seqlock_bh(lock) \
do { local_bh_disable(); write_seqlock(lock); } while (0)
#define write_sequnlock_irqrestore(lock, flags) \
do { write_sequnlock(lock); local_irq_restore(flags); } while(0)
#define write_sequnlock_irq(lock) \
do { write_sequnlock(lock); local_irq_enable(); } while(0)
#define write_sequnlock_bh(lock) \
do { write_sequnlock(lock); local_bh_enable(); } while(0)
#define read_seqbegin_irqsave(lock, flags) \
({ local_irq_save(flags); read_seqbegin(lock); })
#define read_seqretry_irqrestore(lock, iv, flags) \
({ \
int ret = read_seqretry(lock, iv); \
local_irq_restore(flags); \
ret; \
})
10、禁止抢占

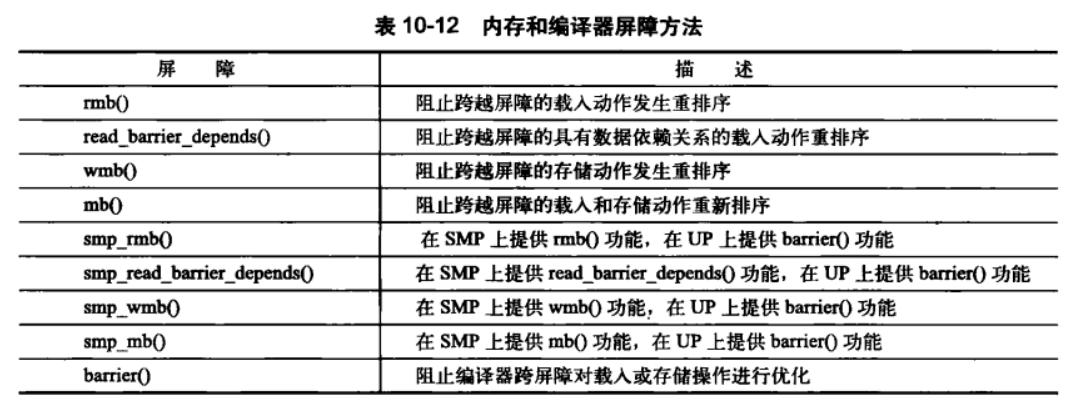
11、顺序与屏障
八、定时器和时间管理
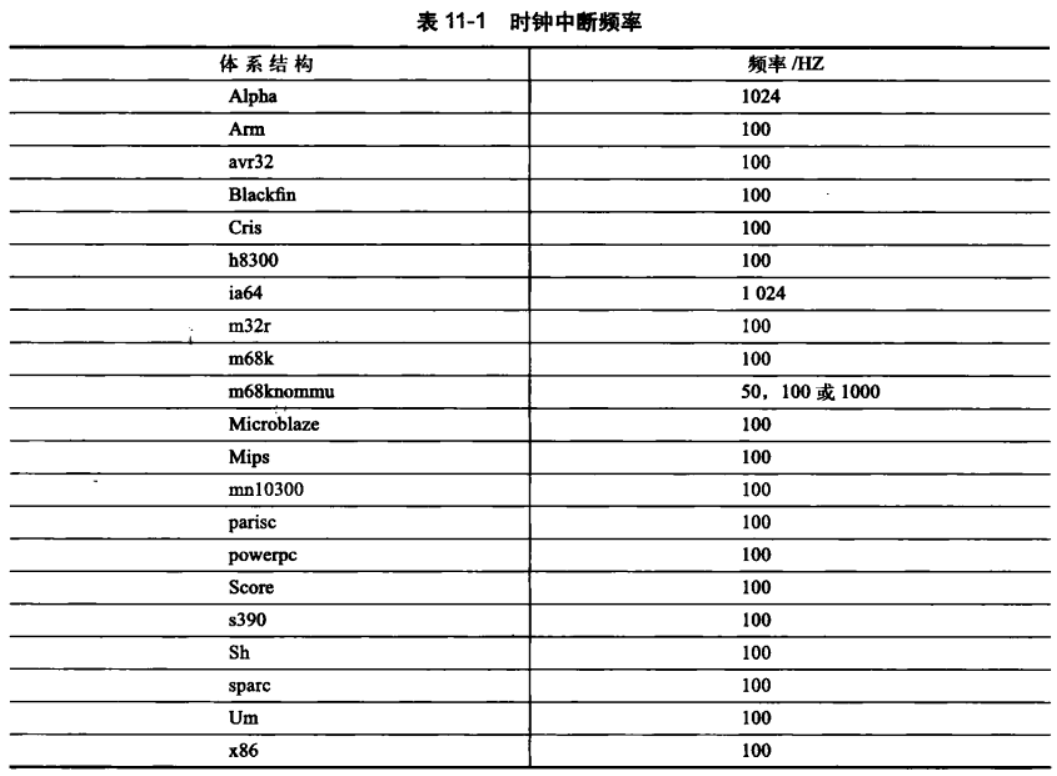
1、节拍率 HZ
// include/linux/param.h
#ifndef _LINUX_PARAM_H
#define _LINUX_PARAM_H
#include <asm/param.h>
#endif
// arch/x86/include/asm/param.h
#include <asm-generic/param.h>
// include/asm-generic/param.h
#ifdef __KERNEL__
# define HZ CONFIG_HZ /* Internal kernel timer frequency */
# define USER_HZ 100 /* some user interfaces are */
# define CLOCKS_PER_SEC (USER_HZ) /* in "ticks" like times() */
#endif
#ifndef HZ
#define HZ 100
#endif
2、jiffies
(1)jiffies 的内部表示
// include/linux/jiffies.h
extern u64 __jiffy_data jiffies_64;
extern unsigned long volatile __jiffy_data jiffies;
#if (BITS_PER_LONG < 64)
u64 get_jiffies_64(void);
#else
static inline u64 get_jiffies_64(void)
{
return (u64)jiffies;
}
#endif
在 32 位体系结构上是 32 位,在 64 位体系结构上是 64 位。
(2)jiffies 的回绕
#define time_after(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(b) - (long)(a) < 0))
#define time_before(a,b) time_after(b,a)
#define time_after_eq(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(a) - (long)(b) >= 0))
#define time_before_eq(a,b) time_after_eq(b,a)
/*
* Calculate whether a is in the range of [b, c].
*/
#define time_in_range(a,b,c) \
(time_after_eq(a,b) && \
time_before_eq(a,c))
/*
* Calculate whether a is in the range of [b, c).
*/
#define time_in_range_open(a,b,c) \
(time_after_eq(a,b) && \
time_before(a,c))
/* Same as above, but does so with platform independent 64bit types.
* These must be used when utilizing jiffies_64 (i.e. return value of
* get_jiffies_64() */
#define time_after64(a,b) \
(typecheck(__u64, a) && \
typecheck(__u64, b) && \
((__s64)(b) - (__s64)(a) < 0))
#define time_before64(a,b) time_after64(b,a)
#define time_after_eq64(a,b) \
(typecheck(__u64, a) && \
typecheck(__u64, b) && \
((__s64)(a) - (__s64)(b) >= 0))
#define time_before_eq64(a,b) time_after_eq64(b,a)
/*
* These four macros compare jiffies and 'a' for convenience.
*/
/* time_is_before_jiffies(a) return true if a is before jiffies */
#define time_is_before_jiffies(a) time_after(jiffies, a)
/* time_is_after_jiffies(a) return true if a is after jiffies */
#define time_is_after_jiffies(a) time_before(jiffies, a)
/* time_is_before_eq_jiffies(a) return true if a is before or equal to jiffies*/
#define time_is_before_eq_jiffies(a) time_after_eq(jiffies, a)
/* time_is_after_eq_jiffies(a) return true if a is after or equal to jiffies*/
#define time_is_after_eq_jiffies(a) time_before_eq(jiffies, a)
/*
* Have the 32 bit jiffies value wrap 5 minutes after boot
* so jiffies wrap bugs show up earlier.
*/
#define INITIAL_JIFFIES ((unsigned long)(unsigned int) (-300*HZ))
(3)用户空间和 HZ
在 2.6 版以前的内核中,如果改变内核中 HZ 的值,会给用户空间中某些程序造成异常结果。这是因为内核是以 节拍数 / 秒 的形式给用户空间导出这个值的,在这个接口稳定了很长一段时间后,应用程序便逐渐依赖于这个特定的 HZ 值了。所以如果在内核中更改了 HZ 的定义值,就打破了用户空间的常量关系——用户空间并不知道新的 HZ 值。所以用户空间可能认为系统运行时间已经是 20 个小时了,但实际上系统仅仅启动了两个小时。
要像避免上面的错误,内核必须更改所有导出的 jiffies 值。因而内核定义了 USER_HZ 来代表用户空间看到的 HZ 值。在 x86 体系结构上,由于 HZ 值原来一直是 100,所以 USER_HZ 值就定义为 100。内核可以使用函数 jiffies_to_clock_t() 将一个由 HZ 表示的节拍数转换成一个由 USER_HZ 表示的节拍技术。
// kernel/time.c
clock_t jiffies_to_clock_t(long x)
{
#if (TICK_NSEC % (NSEC_PER_SEC / USER_HZ)) == 0
# if HZ < USER_HZ
return x * (USER_HZ / HZ);
# else
return x / (HZ / USER_HZ);
# endif
#else
return div_u64((u64)x * TICK_NSEC, NSEC_PER_SEC / USER_HZ);
#endif
}
EXPORT_SYMBOL(jiffies_to_clock_t);
// include/linux/types.h
typedef __kernel_clock_t clock_t;
// arch/x86/include/asm/posix_types_64.h
typedef long __kernel_clock_t;
3、定时器
// include/linux/timer.h
struct timer_list {
struct list_head entry; /* 定时器链表的入口 */
unsigned long expires; /* 以 jiffies 为单位的定时值 */
void (*function)(unsigned long); /* 定时器处理函数 */
unsigned long data; /* 传给处理函数的长整型参数 */
struct tvec_base *base; /* 定时器内部值,用户不要使用 */
#ifdef CONFIG_TIMER_STATS
void *start_site;
char start_comm[16];
int start_pid;
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
4、延迟执行
(1)忙等待
unsigned long timeout = jiffies + 10;
while (time_before(jiffies, timeout))
;
unsigned long timeout = jiffies + 5 * HZ;
while (time_before(jiffies, timeout))
cond_resched();
(2)短延迟
(a)方法说明
void udelay(unsigned long usecs);
void ndelay(unsigned long nsecs);
void mdelay(unsigned long msecs);
(b)mdelay 函数
- mdelay 函数
// include/linux/delay.h
#ifndef mdelay
#define mdelay(n) (\
(__builtin_constant_p(n) && (n)<=MAX_UDELAY_MS) ? udelay((n)*1000) : \
({unsigned long __ms=(n); while (__ms--) udelay(1000);}))
#endif
#ifndef ndelay
static inline void ndelay(unsigned long x)
{
udelay(DIV_ROUND_UP(x, 1000));
}
#define ndelay(x) ndelay(x)
#endif
extern unsigned long lpj_fine;
void calibrate_delay(void);
void msleep(unsigned int msecs);
unsigned long msleep_interruptible(unsigned int msecs);
static inline void ssleep(unsigned int seconds)
{
msleep(seconds * 1000);
}
- udelay 函数
// arch/x86/include/asm/delay.h
/* 0x10c7 is 2**32 / 1000000 (rounded up) */
#define udelay(n) (__builtin_constant_p(n) ? \
((n) > 20000 ? __bad_udelay() : __const_udelay((n) * 0x10c7ul)) : \
__udelay(n))
/* 0x5 is 2**32 / 1000000000 (rounded up) */
#define ndelay(n) (__builtin_constant_p(n) ? \
((n) > 20000 ? __bad_ndelay() : __const_udelay((n) * 5ul)) : \
__ndelay(n))
- __const_udelay 函数
// arch/x86/lib/delay.c
inline void __const_udelay(unsigned long xloops)
{
int d0;
xloops *= 4;
asm("mull %%edx"
:"=d" (xloops), "=&a" (d0)
:"1" (xloops), "0"
(cpu_data(raw_smp_processor_id()).loops_per_jiffy * (HZ/4)));
__delay(++xloops);
}
EXPORT_SYMBOL(__const_udelay);
void __udelay(unsigned long usecs)
{
__const_udelay(usecs * 0x000010c7); /* 2**32 / 1000000 (rounded up) */
}
EXPORT_SYMBOL(__udelay);
void __ndelay(unsigned long nsecs)
{
__const_udelay(nsecs * 0x00005); /* 2**32 / 1000000000 (rounded up) */
}
EXPORT_SYMBOL(__ndelay);
(3)schedule_timeout 函数
// kernel/timer.c
signed long __sched schedule_timeout(signed long timeout)
{
struct timer_list timer;
unsigned long expire;
switch (timeout)
{
case MAX_SCHEDULE_TIMEOUT:
/*
* These two special cases are useful to be comfortable
* in the caller. Nothing more. We could take
* MAX_SCHEDULE_TIMEOUT from one of the negative value
* but I' d like to return a valid offset (>=0) to allow
* the caller to do everything it want with the retval.
*/
schedule();
goto out;
default:
/*
* Another bit of PARANOID. Note that the retval will be
* 0 since no piece of kernel is supposed to do a check
* for a negative retval of schedule_timeout() (since it
* should never happens anyway). You just have the printk()
* that will tell you if something is gone wrong and where.
*/
if (timeout < 0) {
printk(KERN_ERR "schedule_timeout: wrong timeout "
"value %lx\n", timeout);
dump_stack();
current->state = TASK_RUNNING;
goto out;
}
}
expire = timeout + jiffies;
setup_timer_on_stack(&timer, process_timeout, (unsigned long)current);
__mod_timer(&timer, expire, false, TIMER_NOT_PINNED);
schedule();
del_singleshot_timer_sync(&timer);
/* Remove the timer from the object tracker */
destroy_timer_on_stack(&timer);
timeout = expire - jiffies;
out:
return timeout < 0 ? 0 : timeout;
}
EXPORT_SYMBOL(schedule_timeout);
九、内存管理
1、页
// include/linux/mm_types.h
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
atomic_t _count; /* Usage count, see below. */
union {
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
struct { /* SLUB */
u16 inuse;
u16 objects;
};
};
union {
struct {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
};
2、区

3、页操作
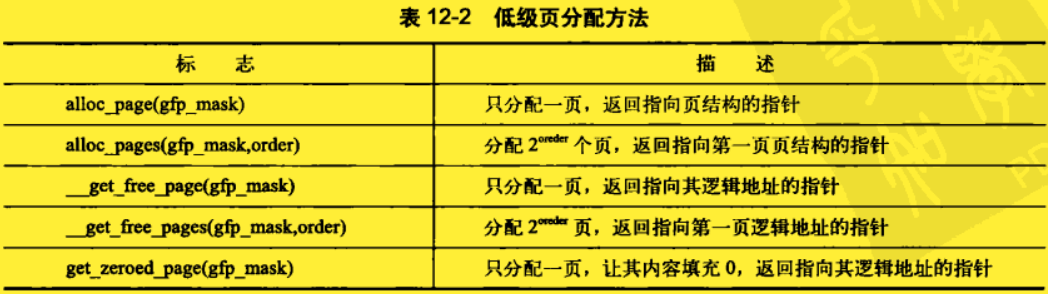
函数定义在文件 include/linux/gfp.h 中
(1)获取页
(2)释放页
extern void __free_pages(struct page *page, unsigned int order);
extern void free_pages(unsigned long addr, unsigned int order);
extern void free_hot_cold_page(struct page *page, int cold);
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr),0)
4、kmalloc 函数
kmalloc() 函数与用户空间的 malloc() 一族函数非常类似,只不过它多了一个 flags 参数。它可以获得以字节为单位的一块内核内存。
// include/linux/slab.h
#ifdef CONFIG_SLUB
#include <linux/slub_def.h>
#elif defined(CONFIG_SLOB)
#include <linux/slob_def.h>
#else
#include <linux/slab_def.h>
#endif
static inline void *kcalloc(size_t n, size_t size, gfp_t flags)
{
if (size != 0 && n > ULONG_MAX / size)
return NULL;
return __kmalloc(n * size, flags | __GFP_ZERO);
}
(1)gfp_t flags
- 行为修饰符


- 区修饰符

- 类型标志


(2)kmalloc 函数分析
- kmalloc 函数
// include/linux/slab_def.h
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
struct kmem_cache *cachep;
void *ret;
if (__builtin_constant_p(size)) {
int i = 0;
if (!size)
return ZERO_SIZE_PTR;
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include <linux/kmalloc_sizes.h>
#undef CACHE
return NULL;
found:
#ifdef CONFIG_ZONE_DMA
if (flags & GFP_DMA)
cachep = malloc_sizes[i].cs_dmacachep;
else
#endif
cachep = malloc_sizes[i].cs_cachep;
ret = kmem_cache_alloc_notrace(cachep, flags);
trace_kmalloc(_THIS_IP_, ret,
size, slab_buffer_size(cachep), flags);
return ret;
}
return __kmalloc(size, flags);
}
- __kmalloc 函数
// mm/slab.c
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, NULL);
}
EXPORT_SYMBOL(__kmalloc);
- __do_kmalloc 函数
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
void *caller)
{
struct kmem_cache *cachep;
void *ret;
/* If you want to save a few bytes .text space: replace
* __ with kmem_.
* Then kmalloc uses the uninlined functions instead of the inline
* functions.
*/
cachep = __find_general_cachep(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
ret = __cache_alloc(cachep, flags, caller);
trace_kmalloc((unsigned long) caller, ret,
size, cachep->buffer_size, flags);
return ret;
}
- __cache_alloc 函数
static __always_inline void *
__cache_alloc(struct kmem_cache *cachep, gfp_t flags, void *caller)
{
unsigned long save_flags;
void *objp;
flags &= gfp_allowed_mask;
lockdep_trace_alloc(flags);
if (slab_should_failslab(cachep, flags))
return NULL;
cache_alloc_debugcheck_before(cachep, flags);
local_irq_save(save_flags);
objp = __do_cache_alloc(cachep, flags);
local_irq_restore(save_flags);
objp = cache_alloc_debugcheck_after(cachep, flags, objp, caller);
kmemleak_alloc_recursive(objp, obj_size(cachep), 1, cachep->flags,
flags);
prefetchw(objp);
if (likely(objp))
kmemcheck_slab_alloc(cachep, flags, objp, obj_size(cachep));
if (unlikely((flags & __GFP_ZERO) && objp))
memset(objp, 0, obj_size(cachep));
return objp;
}
5、vmalloc 函数
vmalloc 函数的工作方式类似于 kmalloc(),只不过 vmalloc 分配的内存虚拟地址是连续的,而物理地址则无须连续。
// include/linux/vmalloc.h
void *vmalloc(unsigned long size);
// mm/vmalloc.c
void *vmalloc(unsigned long size)
{
return __vmalloc_node(size, 1, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL,
-1, __builtin_return_address(0));
}
EXPORT_SYMBOL(vmalloc);
6、slab
(1)kmem_cache 结构体
slab 根据配置不同,引用了不同的文件,具体如下:
#ifdef CONFIG_SLUB
#include <linux/slub_def.h>
#elif defined(CONFIG_SLOB)
#include <linux/slob_def.h>
#else
#include <linux/slab_def.h>
#endif
以下列举的是文件 slab_def.h 的信息。
// include/linux/slab_def.h
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *slabp_cache;
unsigned int slab_size;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj);
/* 5) cache creation/removal */
const char *name;
struct list_head next;
/* 6) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif /* CONFIG_DEBUG_SLAB */
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/
};
kmem_list3 结构体
// mm/slab.c
struct kmem_list3 {
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
spinlock_t list_lock;
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
};
(2)slab 结构体
// mm/slab.c
struct slab {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
unsigned short nodeid;
};
(3)函数
// mm/slab.c
static void *kmem_getpages(struct kmem_cache *cachep, gfp_t flags, int nodeid);
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *cachep);
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
7、栈
内核栈一般为 8K,可动态配置,范围为 4~16K。当 1 页栈激活,中断处理程序获得自己的栈(中断栈),不再使用内核栈。
8、高端内存映射
// include/linux/highmem.h
static inline void *kmap(struct page *page)
{
might_sleep();
return page_address(page);
}
static inline void kunmap(struct page *page)
{
}
static inline void *kmap_atomic(struct page *page, enum km_type idx);
#define kunmap_atomic(addr, idx) do { pagefault_enable(); } while (0)
9、分配函数的选择
在这么多分配函数和方法中,有时并不能搞清楚到底该选择那种方式分配——但这确实很重要。如果你需要连续的物理页,就可以使用某个低级页分配器或 kmalloc()。这是内核中内存分配的常用方式,也是大多数情况下你自己应该使用的内存分配方式。回忆一下,传递给这些函数的两个最常用的标志是 GFP_ATOMIC 和 GFP_KERNEL。GFP_ATOMIC 表示进行不睡眠的高优先级分配,这是中断处理程序和其他不能睡眠的代码段的需要。对于可以睡眠的代码,(比如没有持自旋锁的进程上下文代码)则应该使用 GFP_KERNEL获取所需的内存。这个标志表示如果有必要,分配时可以睡眠。
如果你想从高端内存进行分配,就使用 alloc_pages()。alloc_pages() 函数返回一个指向 struct page 结构的指针,而不是一个指向某个逻辑地址的指针。因为高端内存很可能并没有被映射,因此,访问它的唯一方式就是通过相应的 struct page 结构。为了获得真正的指针,应该调用 kmap(),把高端内存映射到内核的逻辑地址空间。
如果你不需要物理上连续的页,而仅仅需要虚拟地址上连续的页,那么就使用 vmalloc()(不过要记住 vmalloc() 相对 kmalloc() 来说,有一定的性能损失)。vmalloc() 函数分配的内存虚地址是连续的,但它本身并不保证物理上的连续。这与用户空间的分配非常类似,它也是把物理内存块映射到连续的逻辑地址空间上。
如果你要创建和撤销很多大的数据结构,那么考虑建立 slab 高速缓存。slab 层会给每个处理器维持一个对象高速缓存(空闲链表),这种高速缓存会极大地提高对象分配和回收的性能。slab 层不是频繁地分配和释放内存,而是为你把事先分配好的对象存放到高速缓存中。当你需要一块新的内存来存放数据结构时,slab 层一般无须另外去分配内存,而只需要从高速缓存中得到一个对象就可以了。
十、虚拟文件系统
1、VFS
VFS中有四个主要的对象类型,它们分别是:
- 超级块对象,它代表一个具体的已安装文件系统。
- 索引节点对象,它代表一个具体文件。
- 目录项对象,它代表一个目录项,是路径的一个组成部分。
- 文件对象,它代表由进程打开的文件。
2、超级块
(1)super_block 结构体
// include/linux/fs.h
struct super_block {
/* 指向所有超级块的链表 */
struct list_head s_list; /* Keep this first */
/* 设备标识符 */
dev_t s_dev; /* search index; _not_ kdev_t */
/* 修改(脏)标志 */
unsigned char s_dirt;
/* 以位为单位的块大小 */
unsigned char s_blocksize_bits;
/* 以字节为单位的块大小 */
unsigned long s_blocksize;
/* 文件大小上限 */
loff_t s_maxbytes; /* Max file size */
/* 文件系统类型 */
struct file_system_type *s_type;
/* 超级块方法 */
const struct super_operations *s_op;
/* 磁盘限额方法 */
const struct dquot_operations *dq_op;
/* 限额控制方法 */
const struct quotactl_ops *s_qcop;
/* 导出方法 */
const struct export_operations *s_export_op;
/* 挂载标志 */
unsigned long s_flags;
/* 文件系统的幻数 */
unsigned long s_magic;
/* 目录挂载点 */
struct dentry *s_root;
/* 卸载信号量 */
struct rw_semaphore s_umount;
/* 超级块互斥体 */
struct mutex s_lock;
/* 超级块引用计数 */
int s_count;
/* 尚未同步标志 */
int s_need_sync;
/* 活动引用计数 */
atomic_t s_active;
#ifdef CONFIG_SECURITY
/* 安全模块 */
void *s_security;
#endif
/* 扩展的属性操作 */
struct xattr_handler **s_xattr;
/* inodes 链表 */
struct list_head s_inodes; /* all inodes */
/* 匿名目录项 */
struct hlist_head s_anon; /* anonymous dentries for (nfs) exporting */
/* 被分配文件链表 */
struct list_head s_files;
/* s_dentry_lru and s_nr_dentry_unused are protected by dcache_lock */
/* 未被使用目录项链表 */
struct list_head s_dentry_lru; /* unused dentry lru */
/* 链表中目录项的数目 */
int s_nr_dentry_unused; /* # of dentry on lru */
/* 相关的块设备 */
struct block_device *s_bdev;
/* */
struct backing_dev_info *s_bdi;
/* 存储磁盘信息 */
struct mtd_info *s_mtd;
/* 该类型文件系统 */
struct list_head s_instances;
/* 限额相关选项 */
struct quota_info s_dquot; /* Diskquota specific options */
/* frozen 标志位 */
int s_frozen;
/* 冻结的等待队列 */
wait_queue_head_t s_wait_unfrozen;
/* 文本名字 */
char s_id[32]; /* Informational name */
/* 文件系统特殊信息 */
void *s_fs_info; /* Filesystem private info */
/* 安装权限 */
fmode_t s_mode;
/* 时间戳粒度 */
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
/* */
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
/* 子类型名称 */
char *s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
/* 已存安装选项 */
char *s_options;
};
(2)super_operations 结构体
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*dirty_inode) (struct inode *);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
void (*drop_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_fs) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
int (*show_stats)(struct seq_file *, struct vfsmount *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
};
3、索引节点
(1)inode 结构体
// include/linux/fs.h
struct inode {
/* 散列表 */
struct hlist_node i_hash;
/* 索引节点链表 */
struct list_head i_list; /* backing dev IO list */
/* 超级块链表 */
struct list_head i_sb_list;
/* 目录项链表 */
struct list_head i_dentry;
/* 节点号 */
unsigned long i_ino;
/* 引用计数 */
atomic_t i_count;
/* 硬链接数 */
unsigned int i_nlink;
/* 使用者的 id */
uid_t i_uid;
/* 使用组的 id */
gid_t i_gid;
/* 实际设备标识符 */
dev_t i_rdev;
/* 以位为单位的块大小 */
unsigned int i_blkbits;
/* 版本号 */
u64 i_version;
/* 以字节为单位的文件大小 */
loff_t i_size;
#ifdef __NEED_I_SIZE_ORDERED
/* 对 i_size 进行串行计数 */
seqcount_t i_size_seqcount;
#endif
/* 最后访问时间 */
struct timespec i_atime;
/* 最后修改时间 */
struct timespec i_mtime;
/* 最后改变时间 */
struct timespec i_ctime;
/* 文件的块数 */
blkcnt_t i_blocks;
/* 使用的字节数 */
unsigned short i_bytes;
/* 访问权限 */
umode_t i_mode;
/* 自旋锁 */
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
/* */
struct mutex i_mutex;
/* 嵌入 i_sem 内部 */
struct rw_semaphore i_alloc_sem;
/* 索引节点操作表 */
const struct inode_operations *i_op;
/* 缺省的索引节点操作 */
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
/* 相关的超级块 */
struct super_block *i_sb;
/* 文件锁链表 */
struct file_lock *i_flock;
/* 相关的地址映射 */
struct address_space *i_mapping;
/* 设备地址映射 */
struct address_space i_data;
#ifdef CONFIG_QUOTA
/* 索引节点的磁盘限额 */
struct dquot *i_dquot[MAXQUOTAS];
#endif
/* 块设备链表 */
struct list_head i_devices;
union {
/* 管道信息 */
struct pipe_inode_info *i_pipe;
/* 块设备驱动 */
struct block_device *i_bdev;
/* 字符设备驱动 */
struct cdev *i_cdev;
};
/* */
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
/* */
__u32 i_fsnotify_mask; /* all events this inode cares about */
/* */
struct hlist_head i_fsnotify_mark_entries; /* fsnotify mark entries */
#endif
#ifdef CONFIG_INOTIFY
/* 索引节点通知监测链表 */
struct list_head inotify_watches; /* watches on this inode */
/* 保护 inotify_watches */
struct mutex inotify_mutex; /* protects the watches list */
#endif
/* 状态标志 */
unsigned long i_state;
/* 第一次弄脏数据的时间 */
unsigned long dirtied_when; /* jiffies of first dirtying */
/* 文件系统标志 */
unsigned int i_flags;
/* 写者计数 */
atomic_t i_writecount;
#ifdef CONFIG_SECURITY
/* 安全模块 */
void *i_security;
#endif
#ifdef CONFIG_FS_POSIX_ACL
/* */
struct posix_acl *i_acl;
/* */
struct posix_acl *i_default_acl;
#endif
/* fs 私有指针 */
void *i_private; /* fs or device private pointer */
};
(2)inode_operations结构体
struct inode_operations {
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,int,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char __user *,int);
void * (*follow_link) (struct dentry *, struct nameidata *);
void (*put_link) (struct dentry *, struct nameidata *, void *);
void (*truncate) (struct inode *);
int (*permission) (struct inode *, int);
int (*check_acl)(struct inode *, int);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
long (*fallocate)(struct inode *inode, int mode, loff_t offset,
loff_t len);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start,
u64 len);
};
4、目录项
(1)dentry 结构体
// include/linux/dcache.h
struct dentry {
/* 使用记数 */
atomic_t d_count;
/* 目录项标识 */
unsigned int d_flags; /* protected by d_lock */
/* 单目录项锁 */
spinlock_t d_lock; /* per dentry lock */
/* 是登录点的目录项吗? */
int d_mounted;
/* 相关联的索引节点 */
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
/* 散列表 */
struct hlist_node d_hash; /* lookup hash list */
/* 父目录的目录项对象 */
struct dentry *d_parent; /* parent directory */
/* 目录项名称 */
struct qstr d_name;
/* 未使用的链表 */
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
/* 目录项内部形成的链表 */
struct list_head d_child; /* child of parent list */
/* RCU 加锁 */
struct rcu_head d_rcu;
} d_u;
/* 子目录链表 */
struct list_head d_subdirs; /* our children */
/* 索引节点别名链表 */
struct list_head d_alias; /* inode alias list */
/* 重置时间 */
unsigned long d_time; /* used by d_revalidate */
/* 目录项操作指针 */
const struct dentry_operations *d_op;
/* 文件的超级块 */
struct super_block *d_sb; /* The root of the dentry tree */
/* 文件系统特有数据 */
void *d_fsdata; /* fs-specific data */
/* 短文件名 */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
(2)super_operations 结构体
// include/linux/dcache.h
struct dentry_operations {
int (*d_revalidate)(struct dentry *, struct nameidata *);
int (*d_hash) (struct dentry *, struct qstr *);
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
int (*d_delete)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
};
5、文件
(1)file 结构体
// include/linux/fs.h
struct file {
/*
* fu_list becomes invalid after file_free is called and queued via
* fu_rcuhead for RCU freeing
*/
union {
/* 文件对象链表 */
struct list_head fu_list;
/* 释放之后的 RCU 链表 */
struct rcu_head fu_rcuhead;
} f_u;
/* 包含目录项 */
struct path f_path;
#define f_dentry f_path.dentry
#define f_vfsmnt f_path.mnt
/* 文件操作表 */
const struct file_operations *f_op;
/* 单个文件结构锁 */
spinlock_t f_lock; /* f_ep_links, f_flags, no IRQ */
/* 文件对象的使用计数 */
atomic_long_t f_count;
/* 当打开文件时所指定的标志 */
unsigned int f_flags;
/* 文件的访问模式 */
fmode_t f_mode;
/* 文件当前的位移量(文件指针) */
loff_t f_pos;
/* 拥有者通过信号进行异步 I/O 数据的传送 */
struct fown_struct f_owner;
/* 文件的信任状 */
const struct cred *f_cred;
/* 预读状态 */
struct file_ra_state f_ra;
/* 版本号 */
u64 f_version;
#ifdef CONFIG_SECURITY
/* 安全模块 */
void *f_security;
#endif
/* needed for tty driver, and maybe others */
/* tty 设备驱动的钩子 */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
/* 事件池链表 */
struct list_head f_ep_links;
#endif /* #ifdef CONFIG_EPOLL */
/* 页缓存映射 */
struct address_space *f_mapping;
#ifdef CONFIG_DEBUG_WRITECOUNT
/* 调试状态 */
unsigned long f_mnt_write_state;
#endif
};
(2)file_operations 结构体
// include/linux/fs.h
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
};
6、和文件系统相关的数据结构
(1)file_system_type 结构体
文件系统类型
// include/linux/fs.h
struct file_system_type {
/* 文件系统的名字 */
const char *name;
/* 文件系统类型标志 */
int fs_flags;
/* 用来从磁盘中读取超级块 */
int (*get_sb) (struct file_system_type *, int,
const char *, void *, struct vfsmount *);
/* 用来终止访问超级块 */
void (*kill_sb) (struct super_block *);
/* 文件系统模块 */
struct module *owner;
/* 链表中下一个文件系统类型 */
struct file_system_type * next;
/* 超级块对象链表 */
struct list_head fs_supers;
/* 剩下的几个字段运行时使锁生效 */
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
struct lock_class_key i_alloc_sem_key;
};
(2)vfsmount 结构体
VFS 文件安装点
// include/linux/mount.h
struct vfsmount {
/* 散列表 */
struct list_head mnt_hash;
/* 父文件系统 */
struct vfsmount *mnt_parent; /* fs we are mounted on */
/* 安装点的目录项 */
struct dentry *mnt_mountpoint; /* dentry of mountpoint */
/* 该文件系统的根目录项 */
struct dentry *mnt_root; /* root of the mounted tree */
/* 该文件系统的超级块 */
struct super_block *mnt_sb; /* pointer to superblock */
/* 子文件系统链表 */
struct list_head mnt_mounts; /* list of children, anchored here */
/* 子文件系统链表 */
struct list_head mnt_child; /* and going through their mnt_child */
/* 安装标志 */
int mnt_flags;
/* 4 bytes hole on 64bits arches */
/* 设备文件名 */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
/* 描述符链表 */
struct list_head mnt_list;
/* 在到期链表中的入口 */
struct list_head mnt_expire; /* link in fs-specific expiry list */
/* 在共享安装链表中的入口 */
struct list_head mnt_share; /* circular list of shared mounts */
/* 从安装链表 */
struct list_head mnt_slave_list;/* list of slave mounts */
/* 从安装链表中的入口 */
struct list_head mnt_slave; /* slave list entry */
/* 从安装链表的主入 */
struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */
/* 相关的命名空间 */
struct mnt_namespace *mnt_ns; /* containing namespace */
/* 安装标识符 */
int mnt_id; /* mount identifier */
/* 组标识符 */
int mnt_group_id; /* peer group identifier */
/*
* We put mnt_count & mnt_expiry_mark at the end of struct vfsmount
* to let these frequently modified fields in a separate cache line
* (so that reads of mnt_flags wont ping-pong on SMP machines)
*/
/* 使用计数 */
atomic_t mnt_count;
/* 如果标记为到期,则值为真 */
int mnt_expiry_mark; /* true if marked for expiry */
/* 钉住进程计数 */
int mnt_pinned;
/* 镜像引用计数 */
int mnt_ghosts;
#ifdef CONFIG_SMP
/* 写者引用计数 */
int __percpu *mnt_writers;
#else
/* 写者引用计数 */
int mnt_writers;
#endif
};

7、和进程相关的数据结构
(1)files_struct 结构体
该结构体由进程描述符中的 files 目录项指向。
// include/linux/fdtable.h
struct files_struct {
/*
* read mostly part
*/
/* 结构的使用计数 */
atomic_t count;
/* 指向其他 fd 表的指针 */
struct fdtable *fdt;
/* 基 fd 表 */
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
/* 单个文件的锁? */
spinlock_t file_lock ____cacheline_aligned_in_smp;
/* 缓存下一个可用的 fd */
int next_fd;
/* exec() 时关闭的文件描述符链表 */
struct embedded_fd_set close_on_exec_init;
/* 打开的文件描述符链表 */
struct embedded_fd_set open_fds_init;
/* 缺省的文件对象数组 */
struct file * fd_array[NR_OPEN_DEFAULT];
};
(2)fs_struct 结构体
该结构体包含文件系统和进程相关的信息。
// include/linux/fs_struct.h
struct fs_struct {
int users; // 用户数目
rwlock_t lock; // 保护该结构体的锁
int umask; // 掩码
int in_exec; // 当前正在执行的文件
struct path root; // 跟目录路径
struct path pwd; // 当前工作目录的路径
};
(3)mnt_namespace 结构体
单进程命名空间,它使得每一个进程在系统中都看到唯一的安装文件系统——不仅是唯一的根目录,而且是唯一的文件系统层次结构。
// include/linux/mnt_namespace.h
struct mnt_namespace {
atomic_t count; // 结构的使用计数
struct vfsmount * root; // 根目录的安装点对象
struct list_head list; // 安装点链表
wait_queue_head_t poll; // 轮询的等待队列
int event; // 事件计数
};
十一、块 I/O 层
1、缓冲区
(1)buffer_head
// include/linux/buffer_head.h
struct buffer_head {
/* 缓冲区状态标志 */
unsigned long b_state; /* buffer state bitmap (see above) */
/* 页面中的缓冲区 */
struct buffer_head *b_this_page;/* circular list of page's buffers */
/* 存储缓冲区的页面 */
struct page *b_page; /* the page this bh is mapped to */
/* 起始块号 */
sector_t b_blocknr; /* start block number */
/* 映像的大小 */
size_t b_size; /* size of mapping */
/* 页面内的数据指针 */
char *b_data; /* pointer to data within the page */
/* 相关联的块设备 */
struct block_device *b_bdev;
/* I/O 完成方法 */
bh_end_io_t *b_end_io; /* I/O completion */
/* io 完成方法 */
void *b_private; /* reserved for b_end_io */
/* 相关的映射链表 */
struct list_head b_assoc_buffers; /* associated with another mapping */
/* 相关的地址空间 */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
/* 缓冲区使用计数 */
atomic_t b_count; /* users using this buffer_head */
};
(2)bh_state_bits
b_state 域表示缓冲区的状态,合法的标志存放在 bh_state_bits 枚举中。
// include/linux/buffer_head.h
enum bh_state_bits {
BH_Uptodate, /* Contains valid data */
BH_Dirty, /* Is dirty */
BH_Lock, /* Is locked */
BH_Req, /* Has been submitted for I/O */
BH_Mapped, /* Has a disk mapping */
BH_New, /* Disk mapping was newly created by get_block */
BH_Async_Read, /* Is under end_buffer_async_read I/O */
BH_Async_Write, /* Is under end_buffer_async_write I/O */
BH_Delay, /* Buffer is not yet allocated on disk */
BH_Boundary, /* Block is followed by a discontiguity */
BH_Write_EIO, /* I/O error on write */
BH_Unwritten, /* Buffer is allocated on disk but not written */
BH_Quiet, /* Buffer Error Prinks to be quiet */
BH_Meta, /* Buffer contains metadata */
BH_Prio, /* Buffer should be submitted with REQ_PRIO */
BH_Defer_Completion, /* Defer AIO completion to workqueue */
BH_PrivateStart,/* not a state bit, but the first bit available
* for private allocation by other entities
*/
};

2、bio 结构体
(1)bio 结构体
// include/linux/bio.h
struct bio {
/* 磁盘上相关的扇区 */
sector_t bi_sector; /* device address in 512 byte
sectors */
/* 请求链表 */
struct bio *bi_next; /* request queue link */
/* 相关的块设备 */
struct block_device *bi_bdev;
/* 状态和命令标志 */
unsigned long bi_flags; /* status, command, etc */
/* 读还是写 */
unsigned long bi_rw; /* bottom bits READ/WRITE,
* top bits priority
*/
/* bio_vecs 偏移的个数 */
unsigned short bi_vcnt; /* how many bio_vec's */
/* bio_io_vect 的当前索引 */
unsigned short bi_idx; /* current index into bvl_vec */
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
/* 结合后的片段数目 */
unsigned int bi_phys_segments;
/* I/O 计数 */
unsigned int bi_size; /* residual I/O count */
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
/* 第一个可合并的段大小 */
unsigned int bi_seg_front_size;
/* 最后一个可合并的段大小 */
unsigned int bi_seg_back_size;
/* bio_vecs 数目上限 */
unsigned int bi_max_vecs; /* max bvl_vecs we can hold */
/* 结束 CPU */
unsigned int bi_comp_cpu; /* completion CPU */
/* 使用计数 */
atomic_t bi_cnt; /* pin count */
/* bio_vecs 链表 */
struct bio_vec *bi_io_vec; /* the actual vec list */
/* I/O 完成方法 */
bio_end_io_t *bi_end_io;
/* 拥有者的私有方法 */
void *bi_private;
#if defined(CONFIG_BLK_DEV_INTEGRITY)
/* */
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
/* 撤销方法 */
bio_destructor_t *bi_destructor; /* destructor */
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
/* 内嵌 bio 向量 */
struct bio_vec bi_inline_vecs[0];
};
(2)bio_vec 结构体
// include/linux/bio.h
struct bio_vec {
/* 指向这个缓冲区所驻留的物理页 */
struct page *bv_page;
/* 这个缓冲区以字节为单位的大小 */
unsigned int bv_len;
/* 缓冲区所驻留的页中以字节为单位的偏移量 */
unsigned int bv_offset;
};
(3)新老方法对比
缓冲区头和新的 bio 结构体之间存在显著差别。bio 结构体代表的是 I/O 操作,它可以包括内存中的一个或多个页:而另一方面,buffer_head 结构体代表的是一个缓冲区,它描述的仅仅是磁盘中的一个块。因为缓冲区头关联的是单独页中的单独磁盘块,所以它可能会引起不必要的分割,将请求按块为单位划分,只能靠以后才能再重新组合。由于 bio 结构体是轻量级的,它描述的块可以不需要连续存储区,并且不需要分割 I/O 操作。
利用 bio 结构体代替 buffer_bead 结构体还有以下好处:
- bio 结构体很容易处理高端内存,因为它处理的是物理页而不是直接指针。
- bio 结构体既可以代表普通页 I/O,同时也可以代表直接 I/O(指那些不通过页高速缓存的 I/O 操作-----请参考第 16 章中对页高速缓存的讨论)。
- bio 结构体便于执行分散—集中(矢量化的)块 I/O 操作,操作中的数据可取自多个物理页面。
- bio 结构体相比缓冲区头属于轻量级的结构体。因为它只需要包含块 I/O 操作所需的信息就行了,不用包含与缓冲区本身相关的不必要信息。
但是还是需要缓冲区头这个概念,毕竟它还负责描述磁盘块到页面的映射。bio 结构体不包含任何和缓冲区相关的状态信息——它仅仅是一个矢量数组,描述一个或多个单独块 I/O 操作的数据片段和相关信息。在当前设置中,当 bio 结构体描述当前正在使用的 I/O 操作时,buffer_head 结构体仍然需要包含缓冲区信息。内核通过这两种结构分别保存各自的信息,可以保证每种结构所含的信息量尽可能地少。
3、请求队列
(1)request_queue
// include/linux/blkdev.h
struct request_queue
{
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
/*
* the queue request freelist, one for reads and one for writes
*/
struct request_list rq;
request_fn_proc *request_fn;
make_request_fn *make_request_fn;
prep_rq_fn *prep_rq_fn;
unplug_fn *unplug_fn;
merge_bvec_fn *merge_bvec_fn;
prepare_flush_fn *prepare_flush_fn;
softirq_done_fn *softirq_done_fn;
rq_timed_out_fn *rq_timed_out_fn;
dma_drain_needed_fn *dma_drain_needed;
lld_busy_fn *lld_busy_fn;
/*
* Dispatch queue sorting
*/
sector_t end_sector;
struct request *boundary_rq;
/*
* Auto-unplugging state
*/
struct timer_list unplug_timer;
int unplug_thresh; /* After this many requests */
unsigned long unplug_delay; /* After this many jiffies */
struct work_struct unplug_work;
struct backing_dev_info backing_dev_info;
/*
* The queue owner gets to use this for whatever they like.
* ll_rw_blk doesn't touch it.
*/
void *queuedata;
/*
* queue needs bounce pages for pages above this limit
*/
gfp_t bounce_gfp;
/*
* various queue flags, see QUEUE_* below
*/
unsigned long queue_flags;
/*
* protects queue structures from reentrancy. ->__queue_lock should
* _never_ be used directly, it is queue private. always use
* ->queue_lock.
*/
spinlock_t __queue_lock;
spinlock_t *queue_lock;
/*
* queue kobject
*/
struct kobject kobj;
/*
* queue settings
*/
unsigned long nr_requests; /* Max # of requests */
unsigned int nr_congestion_on;
unsigned int nr_congestion_off;
unsigned int nr_batching;
void *dma_drain_buffer;
unsigned int dma_drain_size;
unsigned int dma_pad_mask;
unsigned int dma_alignment;
struct blk_queue_tag *queue_tags;
struct list_head tag_busy_list;
unsigned int nr_sorted;
unsigned int in_flight[2];
unsigned int rq_timeout;
struct timer_list timeout;
struct list_head timeout_list;
struct queue_limits limits;
/*
* sg stuff
*/
unsigned int sg_timeout;
unsigned int sg_reserved_size;
int node;
#ifdef CONFIG_BLK_DEV_IO_TRACE
struct blk_trace *blk_trace;
#endif
/*
* reserved for flush operations
*/
unsigned int ordered, next_ordered, ordseq;
int orderr, ordcolor;
struct request pre_flush_rq, bar_rq, post_flush_rq;
struct request *orig_bar_rq;
struct mutex sysfs_lock;
#if defined(CONFIG_BLK_DEV_BSG)
struct bsg_class_device bsg_dev;
#endif
};
(2)request
// include/linux/blkdev.h
struct request {
struct list_head queuelist;
struct call_single_data csd;
struct request_queue *q;
unsigned int cmd_flags;
enum rq_cmd_type_bits cmd_type;
unsigned long atomic_flags;
int cpu;
/* the following two fields are internal, NEVER access directly */
unsigned int __data_len; /* total data len */
sector_t __sector; /* sector cursor */
struct bio *bio;
struct bio *biotail;
struct hlist_node hash; /* merge hash */
/*
* The rb_node is only used inside the io scheduler, requests
* are pruned when moved to the dispatch queue. So let the
* completion_data share space with the rb_node.
*/
union {
struct rb_node rb_node; /* sort/lookup */
void *completion_data;
};
/*
* two pointers are available for the IO schedulers, if they need
* more they have to dynamically allocate it.
*/
void *elevator_private;
void *elevator_private2;
struct gendisk *rq_disk;
unsigned long start_time;
/* Number of scatter-gather DMA addr+len pairs after
* physical address coalescing is performed.
*/
unsigned short nr_phys_segments;
unsigned short ioprio;
int ref_count;
void *special; /* opaque pointer available for LLD use */
char *buffer; /* kaddr of the current segment if available */
int tag;
int errors;
/*
* when request is used as a packet command carrier
*/
unsigned char __cmd[BLK_MAX_CDB];
unsigned char *cmd;
unsigned short cmd_len;
unsigned int extra_len; /* length of alignment and padding */
unsigned int sense_len;
unsigned int resid_len; /* residual count */
void *sense;
unsigned long deadline;
struct list_head timeout_list;
unsigned int timeout;
int retries;
/*
* completion callback.
*/
rq_end_io_fn *end_io;
void *end_io_data;
/* for bidi */
struct request *next_rq;
};
十二、进程地址空间
内核除了管理本身的内存外,还必须管理用户空间中进程的内存。我们称这个内存为进程地址空间,也就是系统中每个用户空间进程所看到的内存。
1、内存描述符 mm_struct
内核使用内存描述符结构体表示进程的地址空间,该结构包含了和进程地址空间有关的全部信息。内存描述符由 mm_struct 结构体表示,定义在文件 include/linux/sched.h 中,sched.h 包含了头文件 mm_types.h 。
// include/linux/mm_types.h
struct mm_struct {
/* 内存区域链表 */
struct vm_area_struct * mmap; /* list of VMAs */
/* VMA 形成的红黑树 */
struct rb_root mm_rb;
/* 最近使用的内存区域 */
struct vm_area_struct * mmap_cache; /* last find_vma result */
#ifdef CONFIG_MMU
/* */
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
/* */
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
#endif
/* */
unsigned long mmap_base; /* base of mmap area */
/* */
unsigned long task_size; /* size of task vm space */
/* */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
/* 地址空间第一个空洞 */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
/* 页全局目录 */
pgd_t * pgd;
/* 使用地址空间的用户数 */
atomic_t mm_users; /* How many users with user space? */
/* 主使用计数器 */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
/* 内存区域的个数 */
int map_count; /* number of VMAs */
/* 内存区域的信号量 */
struct rw_semaphore mmap_sem;
/* 页表锁 */
spinlock_t page_table_lock; /* Protects page tables and some counters */
/* 所有 mm_struct 形成的链表 */
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
/* */
unsigned long hiwater_rss; /* High-watermark of RSS usage */
/* */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
/* 代码段的开始地址 */
unsigned long start_code;
/* 代码段的结束地址 */
unsigned long end_code;
/* 数据的首地址 */
unsigned long start_data;
/* 数据的尾地址 */
unsigned long end_data;
/* 堆的首地址 */
unsigned long start_brk;
/* 堆的尾地址 */
unsigned long brk;
/* 进程栈的首地址 */
unsigned long start_stack;
/* 命令行参数的首地址 */
unsigned long arg_start;
/* 命令行参数的尾地址 */
unsigned long arg_end;
/* 环境变量的首地址 */
unsigned long env_start;
/* 环境变量的尾地址 */
unsigned long env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
/* 懒惰 TLB 交换掩码 */
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
/* 体系结构特殊数据 */
mm_context_t context;
/* Swap token stuff */
/*
* Last value of global fault stamp as seen by this process.
* In other words, this value gives an indication of how long
* it has been since this task got the token.
* Look at mm/thrash.c
*/
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
/* 状态标志 */
unsigned long flags; /* Must use atomic bitops to access the bits */
/* 核心转储的支持 */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
/* AIO I/O 链表锁 */
spinlock_t ioctx_lock;
/* AIO I/O 链表 */
struct hlist_head ioctx_list;
#endif
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct *owner;
#endif
#ifdef CONFIG_PROC_FS
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
unsigned long num_exe_file_vmas;
#endif
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
};
在进程的进程描述符(在 <linux/sched.h> 中定义的 task_struct 结构体就表示进程描述符)中,mm 域存放着该进程使用的内存描述符,所以 current-> mm 便指向当前进程的内存描述符。fork() 函数利用 copy_mm() 函数复制父进程的内存描述符,也就是 current->mm 域给其子进程,而子进程中的 mm_struct 结构体实际是通过文件 kernel/fork.c 中的 allocate_mm() 宏从 mm_cachep slab 缓存中分配得到的。通常,每个进程都有唯一的 mm_struct 结构体,即唯一的进程地址空间。
如果父进程希望和其子进程共享地址空间,可以在调用 clone() 时,设置 CLONE_VM 标志。我们把这样的进程称作线程。回忆第 3 章,是否共享地址空间几乎是进程和 Linux 中所谓的线程间本质上的唯一区别。除此以外,Linux 内核并不区别对待它们,线程对内核来说仅仅是一个共享特定资源的进程而已。
(1)mm_struct 与内核线程
内核线程没有进程地址空间,也没有相关的内存描述符。所以内核线程对应的进程描述符中 mm 域为空。
2、虚拟内存区域
(1)vm_area_struct
内存区域由 vm_area_struct 结构体描述,内存区域在 Linux 内核中也经常称作虚拟内存区域(virtual memoryAreas, VMAs)。
// include/linux/mm_types.h
struct vm_area_struct {
/* 相关的 mm_struct 结构体 */
struct mm_struct * vm_mm; /* The address space we belong to. */
/* 区间的首地址 */
unsigned long vm_start; /* Our start address within vm_mm. */
/* 区间的尾地址 */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
/* VMA 链表 */
struct vm_area_struct *vm_next;
/* 访问控制权限 */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
/* 标志 */
unsigned long vm_flags; /* Flags, see mm.h. */
/* 树上该 VMA 的节点 */
struct rb_node vm_rb;
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
/* anon_vma 项 */
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
/* 匿名 VMA 对象 */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
/* 相关的操作表 */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
/* 文件中的偏移量 */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
/* 被映射的文件(如果存在) */
struct file * vm_file; /* File we map to (can be NULL). */
/* 私有数据 */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
(2)VMA 标志
vm_flags 可为如下值,其定义在 include/linux/mm.h 文件中
(3)vm_operations_struct
// include/linux/mm.h
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf);
/* notification that a previously read-only page is about to become
* writable, if an error is returned it will cause a SIGBUS */
int (*page_mkwrite)(struct vm_area_struct *vma, struct vm_fault *vmf);
/* called by access_process_vm when get_user_pages() fails, typically
* for use by special VMAs that can switch between memory and hardware
*/
int (*access)(struct vm_area_struct *vma, unsigned long addr,
void *buf, int len, int write);
#ifdef CONFIG_NUMA
/*
* set_policy() op must add a reference to any non-NULL @new mempolicy
* to hold the policy upon return. Caller should pass NULL @new to
* remove a policy and fall back to surrounding context--i.e. do not
* install a MPOL_DEFAULT policy, nor the task or system default
* mempolicy.
*/
int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);
/*
* get_policy() op must add reference [mpol_get()] to any policy at
* (vma,addr) marked as MPOL_SHARED. The shared policy infrastructure
* in mm/mempolicy.c will do this automatically.
* get_policy() must NOT add a ref if the policy at (vma,addr) is not
* marked as MPOL_SHARED. vma policies are protected by the mmap_sem.
* If no [shared/vma] mempolicy exists at the addr, get_policy() op
* must return NULL--i.e., do not "fallback" to task or system default
* policy.
*/
struct mempolicy *(*get_policy)(struct vm_area_struct *vma,
unsigned long addr);
int (*migrate)(struct vm_area_struct *vma, const nodemask_t *from,
const nodemask_t *to, unsigned long flags);
#endif
};
(4)内存区域的树型结构和内存区域的链表结构
上文讨论过,可以通过内存描述符中的 mmap 和 mm_rb 域之一访问内存区域。这两个域各自独立地指向与内存描述符相关的全体内存区域对象。其实,它们包含完全相同的 vm_area_struct 结构体的指针,仅仅组织方法不同。
mmap 域使用单独链表连接所有的内存区域对象。每一个 vm_area_struct 结构体通过自身的 vm_next 域被连入链表,所有的区域按地址增长的方向排序,mmap 域指向链表中第一个内存区域,链中最后一个结构体指针指向空。
mm_rb 域使用红黑树连接所有的内存区域对象。mm_rb 域指向红黑树的根节点,地址空间中每一个 vm_area_struct 结构体通过自身的 vm_rb 域连接到树中。
红黑树是一种二叉树,树中的每一个元素称为一个节点,最初的节点称为树根。红 - 黑树的多数节点都由两个子节点:一个左子节点和一个右子节点,不过也有节点只有一个子节点的情况。树末端的节点称为叶子节点,它们没有子节点。红 - 黑树中的所有节点都遵从:左边节点值小于右边节点值;另外每个节点都被配以红色或黑色(要么红要么黑,所以叫做红 -黑树)。分配的规则为红节点的子节点为黑色,并且树中的任何一条从节点到叶子的路径必须包含同样数目的黑色节点。记住根节点总为红色。红 -黑树的搜索、插人、删除等操作的复杂度都为 O(log(n))。
链表用于需要遍历全部节点的时候,而红 -黑树适用于在地址空间中定位特定内存区域的时候。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
(5)实际使用中的内存区域
可以使用 /proc 文件系统和 pmap 工具查看给定进程的内存空间和其中所含的内存区域。我们来看一个非常简单的用户空间程序的例子:
int main(int, char **argv) {
for (;;) {
}
return 0;
}
查看 /proc/pid/maps 显示了该进程地址空间中的全部内存区域:
cat /proc/32698/maps
# 每行数据格式如下:
# 开始-结束 访问权限 偏移 主设备号:次设备号 i节点 文件
00400000-00401000 r-xp 00000000 08:01 3549836 /home/liuqz/learnCPlus/c6/build/c6
00600000-00601000 r--p 00000000 08:01 3549836 /home/liuqz/learnCPlus/c6/build/c6
00601000-00602000 rw-p 00001000 08:01 3549836 /home/liuqz/learnCPlus/c6/build/c6
7f0b474cb000-7f0b4768b000 r-xp 00000000 08:01 77337148 /lib/x86_64-linux-gnu/libc-2.23.so
7f0b4768b000-7f0b4788b000 ---p 001c0000 08:01 77337148 /lib/x86_64-linux-gnu/libc-2.23.so
7f0b4788b000-7f0b4788f000 r--p 001c0000 08:01 77337148 /lib/x86_64-linux-gnu/libc-2.23.so
7f0b4788f000-7f0b47891000 rw-p 001c4000 08:01 77337148 /lib/x86_64-linux-gnu/libc-2.23.so
7f0b47891000-7f0b47895000 rw-p 00000000 00:00 0
7f0b47895000-7f0b478bb000 r-xp 00000000 08:01 77332571 /lib/x86_64-linux-gnu/ld-2.23.so
7f0b47a9c000-7f0b47a9f000 rw-p 00000000 00:00 0
7f0b47aba000-7f0b47abb000 r--p 00025000 08:01 77332571 /lib/x86_64-linux-gnu/ld-2.23.so
7f0b47abb000-7f0b47abc000 rw-p 00026000 08:01 77332571 /lib/x86_64-linux-gnu/ld-2.23.so
7f0b47abc000-7f0b47abd000 rw-p 00000000 00:00 0
7ffd4dcdc000-7ffd4dcfd000 rw-p 00000000 00:00 0 [stack]
7ffd4ddcb000-7ffd4ddce000 r--p 00000000 00:00 0 [vvar]
7ffd4ddce000-7ffd4ddd0000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
3、操作内存区域
// include/linux/mm.h
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr);
struct vm_area_struct * find_vma_prev(struct mm_struct * mm, unsigned long addr,
struct vm_area_struct **pprev);
static inline struct vm_area_struct * find_vma_intersection(struct mm_struct * mm, unsigned long start_addr, unsigned long end_addr);
(1)mmap 和 do_mmap 创建地址区间
(a)用户空间
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
(b)内核空间响应
// include/linux/mm.h
static inline unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
{
unsigned long ret = -EINVAL;
if ((offset + PAGE_ALIGN(len)) < offset)
goto out;
if (!(offset & ~PAGE_MASK))
ret = do_mmap_pgoff(file, addr, len, prot, flag, offset >> PAGE_SHIFT);
out:
return ret;
}
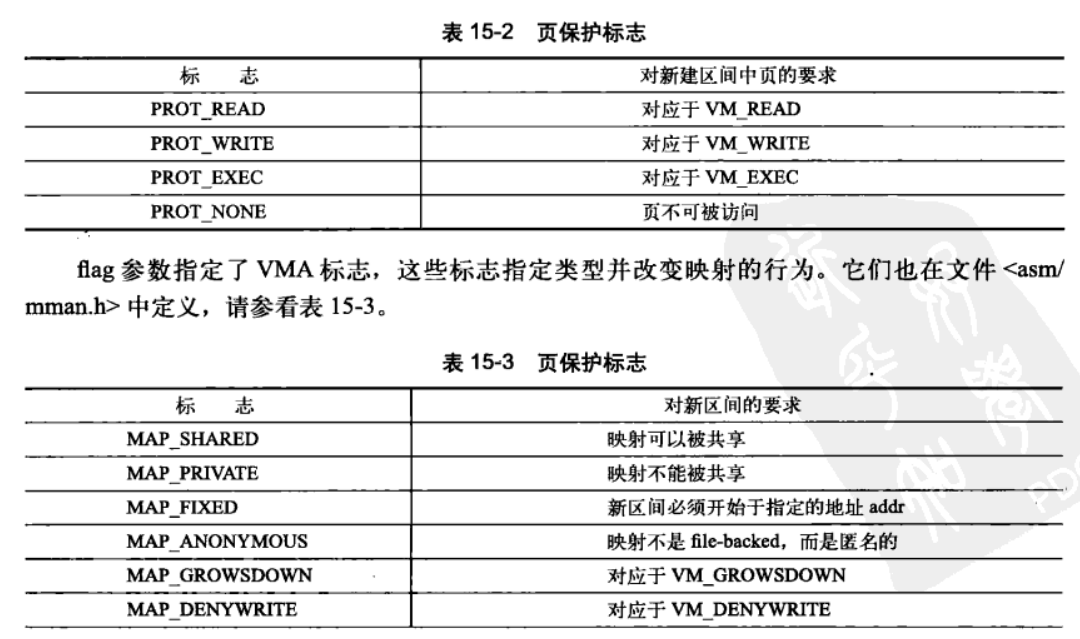

(2)munmap 和 do_mummap 删除地址区间
(a)用户空间
#include <sys/mman.h>
int munmap(void *addr, size_t length);
(b)内核空间响应
// include/linux/mm.h
int do_munmap(struct mm_struct *, unsigned long, size_t);
// mm/nommu.c
int do_munmap(struct mm_struct *mm, unsigned long start, size_t len)
{
struct vm_area_struct *vma;
struct rb_node *rb;
unsigned long end = start + len;
int ret;
kenter(",%lx,%zx", start, len);
if (len == 0)
return -EINVAL;
/* find the first potentially overlapping VMA */
vma = find_vma(mm, start);
if (!vma) {
static int limit = 0;
if (limit < 5) {
printk(KERN_WARNING
"munmap of memory not mmapped by process %d"
" (%s): 0x%lx-0x%lx\n",
current->pid, current->comm,
start, start + len - 1);
limit++;
}
return -EINVAL;
}
/* we're allowed to split an anonymous VMA but not a file-backed one */
if (vma->vm_file) {
do {
if (start > vma->vm_start) {
kleave(" = -EINVAL [miss]");
return -EINVAL;
}
if (end == vma->vm_end)
goto erase_whole_vma;
rb = rb_next(&vma->vm_rb);
vma = rb_entry(rb, struct vm_area_struct, vm_rb);
} while (rb);
kleave(" = -EINVAL [split file]");
return -EINVAL;
} else {
/* the chunk must be a subset of the VMA found */
if (start == vma->vm_start && end == vma->vm_end)
goto erase_whole_vma;
if (start < vma->vm_start || end > vma->vm_end) {
kleave(" = -EINVAL [superset]");
return -EINVAL;
}
if (start & ~PAGE_MASK) {
kleave(" = -EINVAL [unaligned start]");
return -EINVAL;
}
if (end != vma->vm_end && end & ~PAGE_MASK) {
kleave(" = -EINVAL [unaligned split]");
return -EINVAL;
}
if (start != vma->vm_start && end != vma->vm_end) {
ret = split_vma(mm, vma, start, 1);
if (ret < 0) {
kleave(" = %d [split]", ret);
return ret;
}
}
return shrink_vma(mm, vma, start, end);
}
erase_whole_vma:
delete_vma_from_mm(vma);
delete_vma(mm, vma);
kleave(" = 0");
return 0;
}
EXPORT_SYMBOL(do_munmap);
十三、页高速缓存和页回写
1、页高速缓存
(1)address_space 结构
address_space 描述了页高速缓存。或者叫 page_cache_entiry 或者 physical_pages_of_a_file 。
// include/linux/fs.h
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
unsigned int i_mmap_writable;/* count VM_SHARED mappings */
struct prio_tree_root i_mmap; /* tree of private and shared mappings */
struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings */
spinlock_t i_mmap_lock; /* protect tree, count, list */
unsigned int truncate_count; /* Cover race condition with truncate */
unsigned long nrpages; /* number of total pages */
pgoff_t writeback_index;/* writeback starts here */
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits/gfp mask */
struct backing_dev_info *backing_dev_info; /* device readahead, etc */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* ditto */
struct address_space *assoc_mapping; /* ditto */
} __attribute__((aligned(sizeof(long))));
(2)address_space_operations
a_ops 域指向地址空间对象中的操作函数表,这与 VFS 对象及其操作表关系类似。
// include/linux/fs.h
struct address_space_operations {
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*readpage)(struct file *, struct page *);
void (*sync_page)(struct page *);
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *);
/* Set a page dirty. Return true if this dirtied it */
int (*set_page_dirty)(struct page *page);
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages);
int (*write_begin)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
sector_t (*bmap)(struct address_space *, sector_t);
void (*invalidatepage) (struct page *, unsigned long);
int (*releasepage) (struct page *, gfp_t);
ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov,
loff_t offset, unsigned long nr_segs);
int (*get_xip_mem)(struct address_space *, pgoff_t, int,
void **, unsigned long *);
/* migrate the contents of a page to the specified target */
int (*migratepage) (struct address_space *,
struct page *, struct page *);
int (*launder_page) (struct page *);
int (*is_partially_uptodate) (struct page *, read_descriptor_t *,
unsigned long);
int (*error_remove_page)(struct address_space *, struct page *);
};
2、flusher 线程
flusher 线程后台例程会被周期性唤醒,将那些在内存中驻留时间过长的脏页写出,确保内存中不会有长期存在的脏页。在系统启动时,内核初始化一个定时器,让它周期地唤醒 flusher 线程,随后使其运行函数 wb_writeback() 。该函数将把所有驻留时间超过 dirty_expire_interval 毫秒(ms )的脏页写回。
系统管理员可以在 /proc/sys/vm 中设置回写相关的参数,也可以通过 sysctl 系统调用设置它们。下图列出了与 pdflush 相关的所有可设置变量。

十四、设备与模块
1、设备类型
在 Linux 以及所有 Unix 系统中,设备被分为以下三种类型:
- 块设备(blkdev)
- 字符设备(cdev)
- 网络设备(ethernet devices)
杂项设备(miscellaneous device,简写为 miscdev),它实际上是个简化的字符设备。
伪设备(pseudo device),最常见的如内核随机数发生器(/dev/random 和 /dev/urandom)、空设备(/dev/null)、零设备(/dev/zero)、满设备(/dev/full)、内存设备(/dev/mem)。
2、模块
(1)hello 模块代码
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
static int hello_init(void) {
printk(KERN_ALERT "I bear a charmed life.\n");
return 0;
}
static void hello_exit(void) {
printk(KERN_ALERT "Out, out, brief candle!\n");
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Shakespeare");
MODULE_DESCRIPTION("A Hello, World Module");
(2)编译
(a)放在内核源代码中编译
例如,希望将它放在 drivers/char 目录下。
- 在 drivers/char 目录下建立 hello 目录。
- 在 drivers/char 目录下 Makefile 文件中添加
obj-m += hello/
或者需要外部控制,则可能如下:
obj-$(CONFIG_HELLO) += hello/
- 在 drivers/char/hello 目录下,新建 Makefile 文件,并添加如下内容:
obj-$(CONFIG_HELLO) += hello.o
- 在内核根目录执行 make,进行编译。
(b)放在内核源代码外编译
- 在你自己的源代码树目录中建立 Makefile 文件,并添加如下内容:
obj-m := hello.o
- 编译
模块在内核内和在内核外构建的最大区别在于构建过程。当模块在内核源代码树外围时,你必须告诉 make 如何找到内核源代码文件和基础 Makefile 文件。命令示例如下:
obj-m := hello.o # 要生成的模块名
# hello-objs:= a.o b.o # 生成这个模块名所需要的目标文件
# KDIR := /lib/modules/`uname -r`/build
KDIR := /home/liuqz/learnLinux/linux-4.15.18
PWD := $(shell pwd)
default:
make -C $(KDIR) M=$(PWD) modules
clean:
rm -rf *.o *.o.cmd *.ko *.mod.c .tmp_versions
(3)安装与卸载模块
# 安装模块
insmod hello.ko
# 卸载模块
rmmod hello.ko
(4)模块参数
(a)代码
module_param(name, type, perm);
// 示例
static int nbr = 10;
module_param(nbr, int, S_IRUGO);
(b)加载模块时传递参数
sudo insmod module_name.ko nbr=4
# 查看信息
dmesg | tail -6
(5)导出符号表
int get_pirate_beard_color(struct pirate *p) {
return p->beard.color;
}
EXPORT_SYMBOL(get_pirate_beard_color);
// 导出符号仅对 GPL 兼容的模块可见
// EXPORT_SYMBOL_GPL(get_pirate_beard_color);
3、设备模型
2.6 内核增加了一个引人注目的新特性——统一设备模型(device model)。设备模型提供了一个独立的机制专门来表示设备,并描述其在系统中的拓扑结构,从而使得系统具有以下优点:
- 代码重复最小化。
- 提供诸如引用计数这样的统一机制。
- 可以列举系统中所有的设备,观察它们的状态,并且查看它们连接的总线。
- 可以将系统中的全部设备结构以树的形式完整、有效地展现出来包括所有的总线和内部连接。
- 可以将设备和其对应的驱动联系起来,反之亦然。
- 可以将设备按照类型加以归类,比如分类为输入设备,而无需理解物理设备的拓扑结构。
- 可以沿设备树的叶子向其根的方向依次遍历,以保证能以正确顺序关闭各设备的电源。
最后一点是实现设备模型的最初动机。若想在内核中实现智能的电源管理,就需要建立表示系统中设备拓扑关系的树结构。当在树上端的设备关闭电源时,内核必须首先关闭该设备节点以下的(处于叶子上的)设备电源。比如内核需要先关闭一个 USB 鼠标,然后才可关闭 USB 控制器 :同样内核也必须在关闭 PCI 总线前先关闭 USB 控制器。简而言之,若要准确而又高效地完成上述电源管理目标,内核无疑需要一裸设备树。
(1)kobject
// include/linux/kobject.h
struct kobject {
const char *name;
struct list_head entry;
struct kobject *parent;
struct kset *kset;
struct kobj_type *ktype;
struct sysfs_dirent *sd;
struct kref kref;
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
};
name 指针指向此 kobject 的名称。
parent 指针指向 kobject 的父对象。这样一来,kobject 就会在内核中构造一个对象层次结构,并且可以将多个对象间的关系表现出来。就如你所看到的,这便是 sysfs 的真正面目:一个用户空间的文件系统,用来表示内核中 kobject 对象的层次结构。
sd 指针指向 sysfs_dirent 结构体,该结构体在 sysfs 中表示的就是这个 kobject。从 sysfs 文件系统内部看,这个结构体是表示 kobject 的一个 inode 结构体。
kref 提供引用计数。ktype 和 kset 结构体对 kobject 对象进行描述和分类。在下面的内容中将详细介绍它们。
kobject 通常是嵌人其他结构中的,其单独意义其实并不大。相反,那些更为重要的结构体,比如定义于 <linux/cdev.h> 中的 struct cdev 中才真正需要用到 kobj 结构。
// include/linux/cdev.h
/* cdev structure - 该对象代表一个字符设备 */
struct cdev {
struct kobject kobj;
struct module *owner;
const struct file_operations *ops;
struct list_head list;
dev_t dev;
unsigned int count;
};
当 kobject 被嵌人到其他结构中时,该结构便拥有了 kobject 提供的标准功能。更重要的一点是,嵌入 kobject 的结构体可以成为对象层次架构中的一部分。比如 cdev 结构体就可通过其父指针 cdev->kobj.parent 和链表 cdev->kobj.entry 插入到对象层次结构中。
(2)ktype
kobject 对象被关联到一种特殊的类型,即 ktype(kernel object type 的缩写)。ktype 类型为 kobj_type 结构体。
// include/linux/kobject.h
struct kobj_type {
void (*release)(struct kobject *kobj);
const struct sysfs_ops *sysfs_ops;
struct attribute **default_attrs;
};
ktype 的存在是为了描述一族 kobject 所具有的普遍特性。如此一来,不再需要每个 kobject 都分别定义自己的特性,而是将这些普遍的特性在 ktype 结构中一次定义,然后所有"同类"的 kobject 都能共享一样的特性。
release 指针指向在 kobject 引用计数减至零时要被调用的析构函数。该函数负责释放所有 kobject 使用的内存和其他相关清理工作。
sysfs_ops 变量指向 sysfs_ops 结构体。该结构体描述了 sysfs 文件读写时的特性。有关其细节参见 17.3.9 节。
最后,default_attrs 指向一个 attribute 结构体数组。这些结构体定义了该 kobject 相关的默认属性。属性描述了给定对象的特征,如果该 kobject 导出到 sysfs 中,那么这些属性都将相应地作为文件而导出。数组中的最后一项必须为 NULL 。
(3)kset
kset 是 kobject 对象的集合体。把它看成是一个容器,可将所有相关的 kobject 对象,比如"全部的块设备"置于同一位置。听起来 kset 与 ktype 非常类似,好像没有多少实质内容。那么"为什么会需要这两个类似的东西呢?" kset 可把 kobject 集中到一个集合中,而 ktype 描述相关类型 kobject 所共有的特性,它们之间的重要区别在于:具有相同 ktype 的 kobject 可以被分组到不同的 kset。就是说,在 Linux 内核中,只有少数一些的 ktype,却有多个 kset 。
kobject 的 kset 指针指向相应的 kset 集合。kset 集合由 kset 结构体表示,定义于头文件 <linux/kobject.h> 中 :
// include/linux/kobject.h
/**
* struct kset - a set of kobjects of a specific type, belonging to a specific subsystem.
*
* A kset defines a group of kobjects. They can be individually
* different "types" but overall these kobjects all want to be grouped
* together and operated on in the same manner. ksets are used to
* define the attribute callbacks and other common events that happen to
* a kobject.
*
* @list: the list of all kobjects for this kset
* @list_lock: a lock for iterating over the kobjects
* @kobj: the embedded kobject for this kset (recursion, isn't it fun...)
* @uevent_ops: the set of uevent operations for this kset. These are
* called whenever a kobject has something happen to it so that the kset
* can add new environment variables, or filter out the uevents if so
* desired.
*/
struct kset {
struct list_head list;
spinlock_t list_lock;
struct kobject kobj;
const struct kset_uevent_ops *uevent_ops;
};
在这个结构中,其中 list 连接该集合(kset)中所有的 kobject 对象,list_lock 是保护这个链表中元素的自旋锁(关于自旋锁的讨论,详见第 10 章),kobj 指向的 koject 对象代表了该集合的基类。uevent_ops 指向一个结构体一一用于处理集合中 kobject 对象的热插拔操作。uevent 就是用户事件(user event)的缩写,提供了与用户空间热插拔信息进行通信的机制。
(4)kobject、ktype 和 kset 的相互关系
上文反复讨论的这一组结构体很容易令人混淆,这可不是因为它们数量繁多(其实只有三个),也不是它们太复杂(它们都相当简单),而是由于它们内部相互交织。要了解 kobject,很难只讨论其中一个结构而不涉及其他相关结构。然而在这些结构的相互作用下,会更有助你深刻理解它们之间的关系。
这里最重要的家伙是 kobject, 它由 struct koject 表示。kobject 为我们引入了诸如引用计数(reference counting)、父子关系和对象名称等基本对象道具,并且是以一个统一的方式提供这些功能。不过 kobject 本身意义并不大,通常情况下它需要被嵌入到其他数据结构中,让那些包含它的结构具有了 kobject 的特性。
kobject 与一个特别的 ktype 对象关联,ktype 由 struct kobj_type 结构体表示,在 koject 中 ktype 字段指向该对象。ktype 定义了一些 kobject 相关的默认特性:析构行为(反构造功能)、sysfs 行为(sysfs 的操作表)以及别的一些默认属性。
kobject 又归入了称作 kset 的集合,kset 集合由 struct kset 结构体表示。kset 提供了两个功能。第一,其中嵌入的 kobject 作为 kobject 组的基类。第二,kset 将相关的 kobject 集合在一起。在 sysfs 中,这些相关的 koject 将以独立的目录出现在文件系统中。这些相关的目录,也许是给定目录的所有子目录,它们可能处于同一个 kset 。
图 17-1 描述了这些数据结构的内在关系。
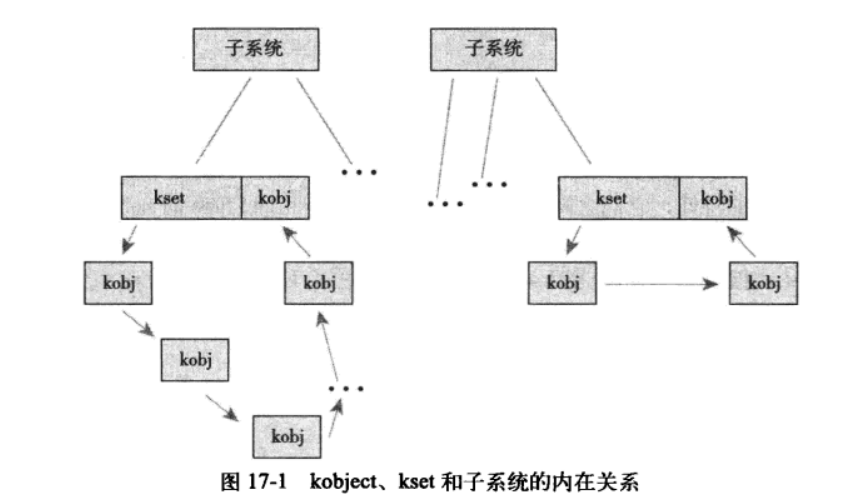
(5)管理和操作 kobject
当了解了 kobject 的内部基本细节后,我们来看管理和操作它的外部接口了。多数时候,驱动程序开发者并不必直接处理 kobject,因为 kobject 是被嵌入到一些特殊类型结构体中的(就如在字符设备结构体中看到的情形),而且会由相关的设备驱动程序在"幕后"管理。即便如此,kobject 并不是有意在隐藏自己,它可以出现在设备驱动代码中,或者可以在设备驱动子系统本身中使用它。
使用 kobjcet 的第一步需要先来声明和初始化。kobject 通过函数 kobject_init 进行初始化,该函数定义在文件 <linux/kobject.h> 中:
void kobject_init(struct kobject *kobj, struct kobj_type *ktype);
该函数的第一个参数就是需要初始化的 kobject 对象,在调用初始化函数前,kobject 必须清空。这个工作往往会在 kobject 所在的上层结构体初始化时完成。如果 kobject 未被清空,那么只需要调用 memset() 即可:
memset (kobj, 0, sizeof (*kobj));
kobject_init 函数的实现如下:
// lib/kobject.c
void kobject_init(struct kobject *kobj, struct kobj_type *ktype)
{
char *err_str;
if (!kobj) {
err_str = "invalid kobject pointer!";
goto error;
}
if (!ktype) {
err_str = "must have a ktype to be initialized properly!\n";
goto error;
}
if (kobj->state_initialized) {
/* do not error out as sometimes we can recover */
printk(KERN_ERR "kobject (%p): tried to init an initialized "
"object, something is seriously wrong.\n", kobj);
dump_stack();
}
kobject_init_internal(kobj);
kobj->ktype = ktype;
return;
error:
printk(KERN_ERR "kobject (%p): %s\n", kobj, err_str);
dump_stack();
}
EXPORT_SYMBOL(kobject_init);
- kobject_init_internal
static void kobject_init_internal(struct kobject *kobj)
{
if (!kobj)
return;
kref_init(&kobj->kref);
INIT_LIST_HEAD(&kobj->entry);
kobj->state_in_sysfs = 0;
kobj->state_add_uevent_sent = 0;
kobj->state_remove_uevent_sent = 0;
kobj->state_initialized = 1;
}
- kref_init
void kref_set(struct kref *kref, int num)
{
atomic_set(&kref->refcount, num);
smp_mb();
}
/**
* kref_init - initialize object.
* @kref: object in question.
*/
void kref_init(struct kref *kref)
{
kref_set(kref, 1);
}
- INIT_LIST_HEAD
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
(6)引用计数
// include/linux/kref.h
struct kref {
atomic_t refcount;
};
void kref_set(struct kref *kref, int num);
void kref_init(struct kref *kref);
void kref_get(struct kref *kref);
int kref_put(struct kref *kref, void (*release) (struct kref *kref));
// lib/kref.c
void kref_set(struct kref *kref, int num)
{
atomic_set(&kref->refcount, num);
smp_mb();
}
void kref_init(struct kref *kref)
{
kref_set(kref, 1);
}
void kref_get(struct kref *kref)
{
WARN_ON(!atomic_read(&kref->refcount));
atomic_inc(&kref->refcount);
smp_mb__after_atomic_inc();
}
int kref_put(struct kref *kref, void (*release)(struct kref *kref))
{
WARN_ON(release == NULL);
WARN_ON(release == (void (*)(struct kref *))kfree);
if (atomic_dec_and_test(&kref->refcount)) {
release(kref);
return 1;
}
return 0;
}
// include/linux/kobject.h
// 递增引用计数
struct kobject *kobject_get(struct kobject *kobj);
void kobject_put(struct kobject *kobj);
// lib/kobject.c
void kobject_put(struct kobject *kobj)
{
if (kobj) {
if (!kobj->state_initialized)
WARN(1, KERN_WARNING "kobject: '%s' (%p): is not "
"initialized, yet kobject_put() is being "
"called.\n", kobject_name(kobj), kobj);
kref_put(&kobj->kref, kobject_release);
}
}
static void kobject_release(struct kref *kref)
{
kobject_cleanup(container_of(kref, struct kobject, kref));
}
static void kobject_cleanup(struct kobject *kobj)
{
struct kobj_type *t = get_ktype(kobj);
const char *name = kobj->name;
pr_debug("kobject: '%s' (%p): %s\n",
kobject_name(kobj), kobj, __func__);
if (t && !t->release)
pr_debug("kobject: '%s' (%p): does not have a release() "
"function, it is broken and must be fixed.\n",
kobject_name(kobj), kobj);
/* send "remove" if the caller did not do it but sent "add" */
if (kobj->state_add_uevent_sent && !kobj->state_remove_uevent_sent) {
pr_debug("kobject: '%s' (%p): auto cleanup 'remove' event\n",
kobject_name(kobj), kobj);
kobject_uevent(kobj, KOBJ_REMOVE);
}
/* remove from sysfs if the caller did not do it */
if (kobj->state_in_sysfs) {
pr_debug("kobject: '%s' (%p): auto cleanup kobject_del\n",
kobject_name(kobj), kobj);
kobject_del(kobj);
}
if (t && t->release) {
pr_debug("kobject: '%s' (%p): calling ktype release\n",
kobject_name(kobj), kobj);
t->release(kobj);
}
/* free name if we allocated it */
if (name) {
pr_debug("kobject: '%s': free name\n", name);
kfree(name);
}
}
4、sysfs
sysfs 文件系统是一个处于内存中的虚拟文件系统,它为我们提供了 kobject 对象层次结构的视图。帮助用户能以一个简单文件系统的方式来观察系统中各种设备的拓扑结构。借助属性对象,kobject 可以用导出文件的方式,将内核变量提供给用户读取或写入(可选)。
虽然设备模型的初表是为了方便电源管理而提出的一种设备拓扑结构,但是 sysfs 是颇为意外的收获。为了方便调试,设备模型的开发者决定将设备结构树导出为一个文件系统。这个举措很快被证明是非常明智的,首先 sysfs 代替了先前处于 /proc 下的设备相关文件;另外它为系统对象提供了一个很有效的视图。实际上,sysfs 起初被称为 driverfs,它早于 kobject 出现。最终 sysfs 使得我们认识到一个全新的对象模型非常有利于系统,于是 kobject 应运而生。今天所有 2.6 内核的系统都拥有 sysfs 文件系统,而且几乎都毫无例外的将其挂载在 sys 目录下。
sysfs 的诀窍是把 kobject 对象与目录项(directory entries)紧密联系起来,这点是通过 kobject 对象中的 dentry 字段实现的。回忆第 12 章,dentry 结构体表示目录项,通过连接 kobject 到指定的目录项上,无疑方便地将 kobject 映射到该目录上。从此,把 kobject 导出形成文件系统就变得如同在内存中构建目录项一样简单。 好了,kobject 其实已经形成了一棵树——就是我们心爱的对象模型体系。由于 kobject 被映射到目录项,同时对象层次结构也已经在内存中形成了一棵树,因此 sysfs 的生成便水到渠成般地简单了。

sysfs 的根目录下包含了至少十个目录:block、bus、class、dev、devices、firmware、fs、kernel、module 和 power。 block 目录下的每个子目录都对应着系统中的一个已注册的块设备。反过来,每个目录下又都包含了该块设备的所有分区。bus 目录提供了一个系统总线视图。class 目录包含了以高层功能逻辑组织起来的系统设备视图, dev 目录是已注册设备节点的视图, devices 目录是系统中设备拓扑结构视图,它直接映射出了内核中设备结构体的组织层次。firmware 目录包含了一些诸如 ACPI、EDD、EFI 等低层子系统的特殊树。fs 目录是已注册文件系统的视图。kemel 目录包含内核配置项和状态信息,module 目录则包含系统已加载模块的信息。power 目录包含系统范围的电源管理数据。并不是所有的系统都包含所有这些目录,还有些系统含有其他目录,但在这里尚未提到。
其中最重要要的目录是 devices,该目录将设备模型导出到用户空间。目录结构就是系统中实际的设备拓扑。其他目录中的很多数据都是将 devices 目录下的数据加以转换加工而得。比如,/sys/class/net/ 目录是以注册网络接口这一高层概念来组织设备关系的,在这个目录中可能会有
目录 eth0,它里面包含的 devices 文件其实就是一个指回到 devices 下实际设备目录的符号链接。
随便看看你可访问到的任何 Linux 系统的 sys 目录,这种系统设备视图相当准确和漂亮,而且可以看到 class 中的高层概念与 devices 中的低层物理设备,以及 bus 中的实际驱动程序之间互相联络是非常广泛的。当你认识到这种数据是开放的,换句话说,这是内核中维持系统的很好表示方式时,整个经历都弥足珍贵。
(1)sysfs 中添加和删除 kobject
仅仅初始化 kobject 是不能自动将其导出到 sysfs 中的,想要把 kobject 导入 sysfs,你需要用到函数 kobject_add() :
// include/linux/kobject.h
int kobject_add(struct kobject *kobj, struct kobject *parent, const char *fmt, ...);
// lib/kobject.c
int kobject_add(struct kobject *kobj, struct kobject *parent,
const char *fmt, ...)
{
va_list args;
int retval;
if (!kobj)
return -EINVAL;
if (!kobj->state_initialized) {
printk(KERN_ERR "kobject '%s' (%p): tried to add an "
"uninitialized object, something is seriously wrong.\n",
kobject_name(kobj), kobj);
dump_stack();
return -EINVAL;
}
va_start(args, fmt);
retval = kobject_add_varg(kobj, parent, fmt, args);
va_end(args);
return retval;
}
EXPORT_SYMBOL(kobject_add);
kobject 在 sysfs 中的位置取决于 kobject 在对象层次结构中的位置。如果 kobject 的父指针被设置,那么在 sysfs 中 kobject 将被映射为其父目录下的子目录;如果 parent 没有设置,那么 kobject 将被映射为 kset->kobj 中的子目录。如果给定的 kobject 中 parent 或 kset 字段都没有被设置,那么就认为 kobject 没有父对象,所以就会被映射成 sysfs 下的根级目录。这往往不是你所需要的,所以在调用 kobject_add() 前, parent 或 kset 字段应该进行适当的设置。不管怎么样,sysfs 中代表 kobject 的目录名字是由 fmt 指定的,它也接受 printf() 样式的格式化字符串。
辅助函数 kobject_create_and_add() 把 kobject_create() 和 kobject_add() 所做的工作放在一个函数中 :
// include/linux/kobject.h
struct kobject *kobject_create_and_add(const char *name, struct kobject *parent)
注意 kobject_create_and_add() 函数接受直接的指针 name 作为 kobject 所对应的目录名称,而
kobject_add() 使用 printf() 风格的格式化字符率。
从 sysfs 中删除一个 kobject 对应文件目录,需使用函数 kobject_del() :
// include/linux/kobject.h
void kobject_del(struct kobject *kobj)
上述这些函数都定义于文件 lib/kobject.c 中,声明于头文件 <linux/kobject.h> 中。
(2)向 sysfs 中添加文件
我们已经看到 kobject 被映射为文件目录,而且所有的对象层次结构都优雅地、一个不少地映射成 sys 下的目录结构。但是里面的文件是什么? sysfs 仅仅是一个漂亮的树,但是没有提供实际数据的文件。
(a)默认属性
默认的文件集合是通过 kobject 和 kset 中的 ktype 字段提供的。因此所有具有相同类型的 kobject 在它们对应的 sysfs 目录下都拥有相同的默认文件集合。kobj_type 字段含有一个字段——default_attrs,它是一个 attribute 结构体数组。这些属性负责将内核数据映射成 sysfs 中
的文件。
attribute 结构体定义在文件 <linux/sysfs.h> 中 :
// include/linux/sysfs.h
/* attribute 结构体 - 内核数据映射成 sysfs 中的文件 */
struct attribute {
const char *name; /* 属性名称 */
struct module *owner; /* 所属模块,如果存在 */
mode_t mode; /* 权限 */
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lock_class_key *key;
struct lock_class_key skey;
#endif
};
其中名称字段提供了该属性的名称,最终出现在 sysfs 中的文件名就是它。owner 字段在存在所属模块的情况下指向其所属的 module 结构体。如果一个模块没有该属性,那么该字段为 NULL。mode 字段类型为 mode_t,它表示了 sysfs 中该文件的权限。对于只读属性而言,如果是所有人都可读它,那么该字段被设为 S_IRUGO;如果只限于所有者可读,则该字段被设置为 S_IRUSR。同样对于可写属性,可能会设置该字段为 S_IRUGO | S_IWUSR。sysfs 中的所有文件和目录的 uid 与 gid 标志均为零。
虽然 default_attrs 列出了默认的展性,sysfs_ops 字段则描述了如何使用它们。sysfs_ops 字段指向了一个定义于文件 <linux/sysfs.h> 的同名的结构体 :
// include/linux/sysfs.h
struct sysfs_ops {
/* 在读 sysfs 文件时该方法被调用 */
ssize_t (*show)(struct kobject *, struct attribute *attr, char *buffer);
/* 在写 sysfs 文件时该方法被调用 */
ssize_t (*store)(struct kobject *,struct attribute *attr,
const char *buffer, size_t size);
};
当从用户空间读取 sysfs 的项时调用 show() 方法。它会拷贝由 attr 提供的属性值到 buffer 指定的缓冲区中,缓冲区大小为 PAGE_SIZE 字节;在 x86 体系中,PAGE_SIZE 为 4096 字节。该函数如果执行成功,则将返回实际写入 buffer 的字节数;如果失败,则返回负的错误码。
store() 方法在写操作时调用,它会从 buffer 中读取 size 大小的字节,并将其存放入 attr 表示的属性结构体变量中。缓冲区的大小总是为 PAGE_SIZE 或更小些。该函数如果执行成功,则将返回实际从 buffer 中读取的字节数;如果失败,则返回负数的错误码。
由于这组函数必须对所有的属性都进行文件 I/O 请求处理,所以它们通常需要维护某些通用映射来调用每个属性所特有的处理函数。
(b)创建新属性
通常来讲,由 kobject 相关的 ktype 所提供的默认属性是充足的,事实上,因为所有具有相同 ktype 的 kobject,在本质上区别不大的情况下,都应是相互接近的。也就是说,比如对于所有的分区而言,它们完全可以具有同样的属性集合。这不但可以让事情简单,有助于代码合并,还使类似对象在 sysfs 目录中外观一致。
但是,有时在一些特别情况下会碰到特殊的 kobject 实例。它希望(甚至是必须)有自己的属性——也许是通用属性没包含那些需要的数据或者函数。为此,内核为能在默认集合之上,再添加新属性而提供了 sysfs_create_file() 接口:
// fs/sysfs/file.c
int sysfs_create_file(struct kobject * kobj, const struct attribute * attr)
{
BUG_ON(!kobj || !kobj->sd || !attr);
return sysfs_add_file(kobj->sd, attr, SYSFS_KOBJ_ATTR);
}
int sysfs_add_file(struct sysfs_dirent *dir_sd, const struct attribute *attr,
int type)
{
return sysfs_add_file_mode(dir_sd, attr, type, attr->mode);
}
int sysfs_add_file_mode(struct sysfs_dirent *dir_sd,
const struct attribute *attr, int type, mode_t amode)
{
umode_t mode = (amode & S_IALLUGO) | S_IFREG;
struct sysfs_addrm_cxt acxt;
struct sysfs_dirent *sd;
int rc;
sd = sysfs_new_dirent(attr->name, mode, type);
if (!sd)
return -ENOMEM;
sd->s_attr.attr = (void *)attr;
sysfs_dirent_init_lockdep(sd);
sysfs_addrm_start(&acxt, dir_sd);
rc = sysfs_add_one(&acxt, sd);
sysfs_addrm_finish(&acxt);
if (rc)
sysfs_put(sd);
return rc;
}
这个接口通过 attr 参数指向相应的 attribute 结构体,而参数 kobj 则指定了属性所在的 kobject 对象。在该函数被调用前,给定的属性将被赋值,如果成功,该函数返回零,否则返回负的错误码。
注意,kobject 中 ktype 所对应的 sysfs_ops 操作将负责处理新属性。现有的 show() 和 store() 方法必须能够处理新属性。
除了添加文件外,还有可能需要创建符号连接。在 sysfs 中创建一个符号连接相当简单 :
// fs/sysfs/symlink.c
int sysfs_create_link(struct kobject *kobj, struct kobject *target,
const char *name)
{
return sysfs_do_create_link(kobj, target, name, 1);
}
该函数创建的符号链接名由 name 指定,链接则由 kobj 对应的目录映射到 target 指定的目录。如果成功该函数返回零,如果失败返回负的错误码。
(c)删除新属性
删除一个属性需通过函数 sysfs_remove_file() 完成 :
// fs/sysfs/file.c
void sysfs_remove_file(struct kobject * kobj, const struct attribute * attr)
{
sysfs_hash_and_remove(kobj->sd, attr->name);
}
一旦调用返回,给定的属性将不再存在于给定的 kobject 目录中。另外由 sysfs_create_link() 创建的符号连接可通过函数 sysfs_remove_link() 删除:
// fs/sysfs/symlink.c
void sysfs_remove_link(struct kobject * kobj, const char * name)
{
struct sysfs_dirent *parent_sd = NULL;
if (!kobj)
parent_sd = &sysfs_root;
else
parent_sd = kobj->sd;
sysfs_hash_and_remove(parent_sd, name);
}
调用一旦返回,在 kobj 对应目录中的名为 name 的符号连接将不复存在。
上述的四个函数在文件 <linux/kobject.h> 中声明;sysfs_create_file() 和 sysfs_remove_file() 数定义于文件 fs/sysfs/file.c 中;sysfs_create_link() 和 sysfs_remove_link() 函数定义于文件 fs/sysfs/symlink.c 中。
(d)sysfs 约定
当前 sysfs 文件系统代替了以前需要由 ioctl()(作用于设备节点)和 procfs 文件系统完成的功能。目前,在合适目录下实现 sysfs 属性这样的功能的确别具一格。比如利用在设备映射的 sysfs 目录中添加一个 sysfs 属性,代替在设备节点上实现一新的 ioctl() 。采用这种方法避免了在调用 ioctl() 时使用类型不正确的参数和弄乱 /proc 目录结构。
但是为了保持 sysfs 干净和直观,开发者必须遵从以下约定。
首先,sysfs 属性应该保证每个文件只导出一个值,该值应该是文本形式而且映射为简单 C 类型。其目的是为了避免数据的过度结构化或太凌乱,现在 /proc 中就混乱而不具有可读性。每个文件提供一个值,这使得从命令行读写变得简洁,同时也使 C 语言程序轻易地将内核数据从 sysfs 导入到自身的变量中去。但有些时候,一值一文件的规则不能很有效地表示数据,那么可以将同一类型的多个值放入一个文件中。不过这时需要合理地表述它们,比如利用一个空格也许就可使其意义清晰明了。总的来讲,应考虑 sysfs 属性要映射到独立的内核变量(正如通常所做),而且要记住应保证从用户空间操作简单,尤其是从 shell 操作简单。
其次,在 sysfs 中要以一个清晰的层次组织数据。父子关系要正确才能将 kobject 层次结构直观地映射到 sysfs 树中。另外,kobject 相关属性同样需要正确,并且要记住 kobject 层次结构不仅仅存在于内核,而且也要作为一个树导出到用户空间,所以要保证 sysfs 树健全无误。
最后,记住 sysfs 提供内核到用户空间的服务,这多少有些用户空间的 ABI(应用程序二进制接口)的作用。用户程序可以检测和获得其存在性、位置、取值以及 sysfs 目录和文件的行为。任何情况下都不应改变现有的文件,另外更改给定属性,但保留其名称和位置不变无疑是在自找麻烦。
这些简单的约定保证 sysfs 可为用户空间提供丰富和直观的接口。正确使用 sysfs,其他应用程序的开发者绝不会对你的代码抱有微辞,相反会赞美它。
(3)内核事件层
内核事件层实现了内核到用户的消息通知系统——就是建立在上文一直讨论的 kobject 基础之上。在 2.6.0 版本以后,显而易见,系统确实需要一种机制来帮助将事件传出内核输送到用户空间,特别是对桌面系统而言,因为它需要更完整和异步的系统。为此就要让内核将其事件压到堆栈 :硬盘满了!处理器过热了!分区挂载了!
早期的事件层没有采用 kobject 和 sysfs,它们如过眼烟云,没有存在多久。现在的事件层借助 koject 和 sysfs 实现已证明相当理想。内核事件层把事件模拟为信号——从明确的 koject 对象发出,所以每个事件源都是一个 sysfs 路径。如果请求的事件与你的第一个硬盘相关,那么 /sys/block/had 便是源树。实质上,在内核中我们认为事件都是从幕后的 kobject 对象产生的。
每个事件都被赋予了一个动词或动作字符串表示信号。该字符串会以"被修改过"或"未挂载"等词语来描述事件。
最后,每个事件都有一个可选的负载(payload)。相比传递任意一个表示负载的字符串到用户空间而言,内核事件层使用 sysfs 属性代表负载。
从内部实现来讲,内核事件由内核空间传递到用户空间需要经过 netlink。netlink 是一个用于传送网络信息的多点传送套接字。使用 netlink 意味着从用户空间获取内核事件就如同在套接字上堵塞一样易如反掌。方法就是用户空间实现一个系统后台服务用于监听套接字,处理任何读到的信息,并将事件传送到系统栈里。对于这种用户后台服务来说,一个潜在的目的就是将事件融入 D-BUS 系统。D-BUS 系统已经实现了一套系统范围的消息总线,这种总线可帮助内核如同系统中其他组件一样地发出信号。
在内核代码中向用户空间发送信号使用函数 kobject_uevent():
// lib/kobject_uevent.c
int kobject_uevent(struct kobject *kobj, enum kobject_action action)
{
return kobject_uevent_env(kobj, action, NULL);
}
EXPORT_SYMBOL_GPL(kobject_uevent);
第一个参数指定发送该信号的 koject 对象。实际的内核事件将包含该 koject 映射到 sysfs 的路径。
第二个参数指定了描述该信号的"动作"或"动词"。实际的内核事件将包含一个映射成枚举类型 kobject_action 的字符串。该函数不是直接提供一个字符串,而是利用一个枚举变量来提高可重用性和保证类型安全,而且也消除了打字错误或其他错误。该枚举变量为:
// lib/kobject_uevent.c
static const char *kobject_actions[] = {
[KOBJ_ADD] = "add",
[KOBJ_REMOVE] = "remove",
[KOBJ_CHANGE] = "change",
[KOBJ_MOVE] = "move",
[KOBJ_ONLINE] = "online",
[KOBJ_OFFLINE] = "offline",
};
其形式为 KOBJ_foo。当前值包含 KOBJ_MOUNT、KOBJ_UNMOUNT,KOBJ_ADD,KOBJ_REMOVE 和 KOBJ_CHANGE 等,这些值分别映射为字符串 “mount”、“unmount”、“add”、“remove” 和 “change” 等。当这些现有的值不够用时,允许添加新动作。
使用 kobject 和属性不但有利于很好的实现基于 sysfs 的事件,同时也有利于创建新 kojects 对象和属性来表示新对象和数据——它们尚未出现在 sysfs 中。
这两个函数分别定义和声明于文件 lib/kobject_uevent.c 与文件 <linux/kobject.h> 中。
5、小结
本章中,我们考察的内核功能涉及设备驱动的实现和设备树的管理,包括模块、kobject(以及相关的 kset 和 ktype)和 sysfs。这些功能对于设备驱动程序的开发者来说是至关重要的,因为这能够让他们写出更为模块化、更为高级的驱动程序。
十五、调试
1、日志等级 printk
printk(KERN_INFO "SMP alternatives: switching to SMP code\n");

2、syslogd 和 klogd
klogd 是用户空间的守护进程,其从记录缓冲区中获取内核消息,再通过 syslogd 守护进程将它们保存在系统日志文件中。klogd 程序既可以从 /proc/kmsg 文件中,也可以通过 syslog() 系统调用读取这些消息。
syslogd 守护进程把它接收到的所有消息添加进一个文件中,该文件默认是 /var/log/messages 。也可以通过 /etc/syslog.conf 配置文件重新指定。
在启动 klogd 的时候,可以通过指定 -c 标志来改变终端的记录等级。
3、oops
oops 是内核告知用户有不幸发生的最常用的方式。
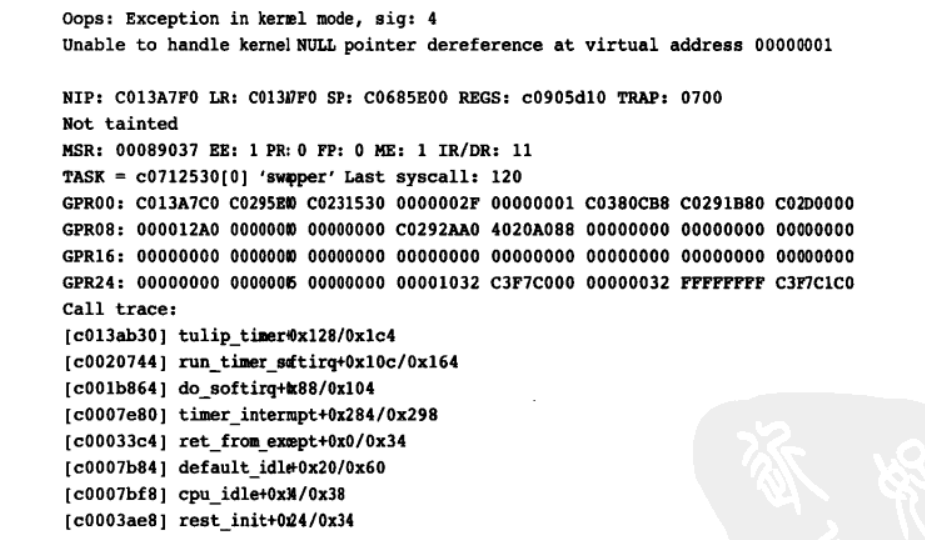
(1)ksymoops
(2)kallsyms
4、内核调试配置选项
5、引发 bug 并打印信息
BUG() 和 BUG_ON()
6、系统请求键 SysRq
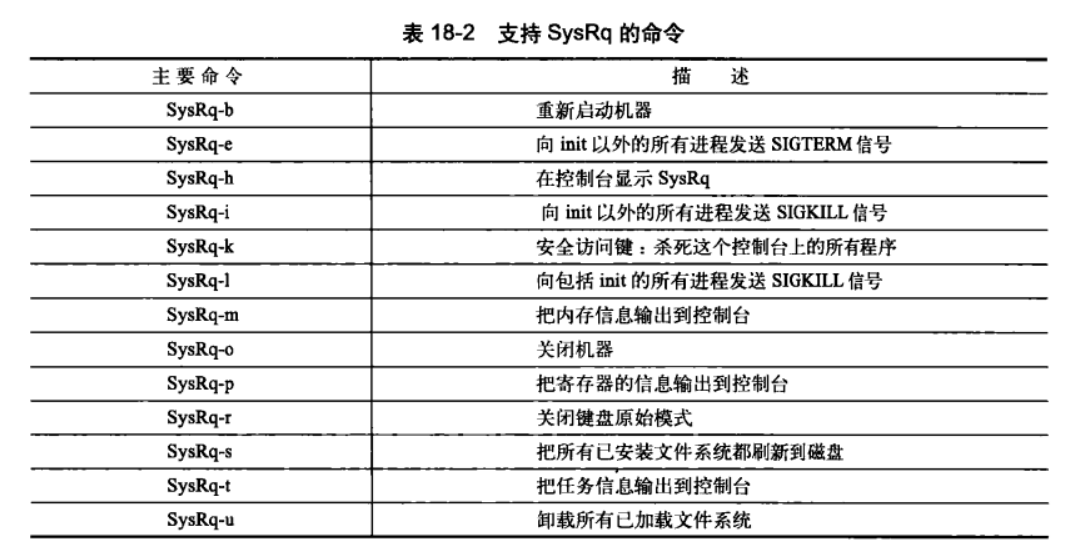
7、内核调试
gdb 和 kgdb














 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









