







算法?时间复杂度?我看就是玄学!
在平时刷题的时候,我总是被各种各样的算法所困惑,最难受的就是我的程序可以正确运行,却总是给我报各种各样的“运行超时”~mud,就不能让我的程序多运行几秒种吗?这也导致我我总是为了节约零点几秒的运行时间而浪费好几个小时改程序。在我看来,这些算法搞的都是没用的玄学。直到。。。
做试卷时正好遇到这么一道题目。

我看了一眼,啪的一下,很快啊~ 我就发现这道题可以用更优化的方式来解(哈希表)。于是我框框框的敲下了一段代码。很快啊~代码就出来了。
Node* MyDelete(Node* head, unordered_map<int, int>& mp) {
if (head == nullptr || head->next == nullptr) return head;
Node* first = head, * second = head->next;
while (second != nullptr) {
while (mp[first->data] >= 1 && second != nullptr) { //可能有小bug
mp[first->data] = -1;
first = second;
second = second->next;
}
while (second != nullptr && mp[second->data == -1]) {
second = second->next;
first->next = second;
}
first->next = second;
first = second;
}
return head;
}
于是我迫不及待得拿去运行。小电驴,启动~!

哈哈!运行成功!
但是~ 这真的比书上的方法更高效吗???
为了探究这个答案,我将试卷上的代码测试了一遍。
Node* DeleteFromList(Node* head) {
Node* p, * p1, * p2;
for (p = head; p != nullptr; p = p->next) {
p1 = p;
p2 = p->next;
while (p2 != nullptr) {
if (p2->data == p->data) {
p1->next = p2->next;
delete p2;
p2 = p1->next;
}
else {
p1 = p2;
p2 = p2->next;
}
}
}
return head;
}
LET’S GO!

额~这玩意儿,难道有区别吗?
为了给我找一个借口 探究原因,我提出了这样的猜测——一定是数据量太少了,嗯,一定是的。那么这一次,我们创建10万个结点测试一下吧~
优化程序:

未优化程序:

哈哈,果然呀~优化的程序运行时间降低了很少。
但是,我节约十几秒的运行时间,却浪费了半小时优化程序的时间,这。。。值得吗?
听说当数据量很大的时候,优化算法的优势就会越来越明显,那么,创建3000万个结点试试吧!!!
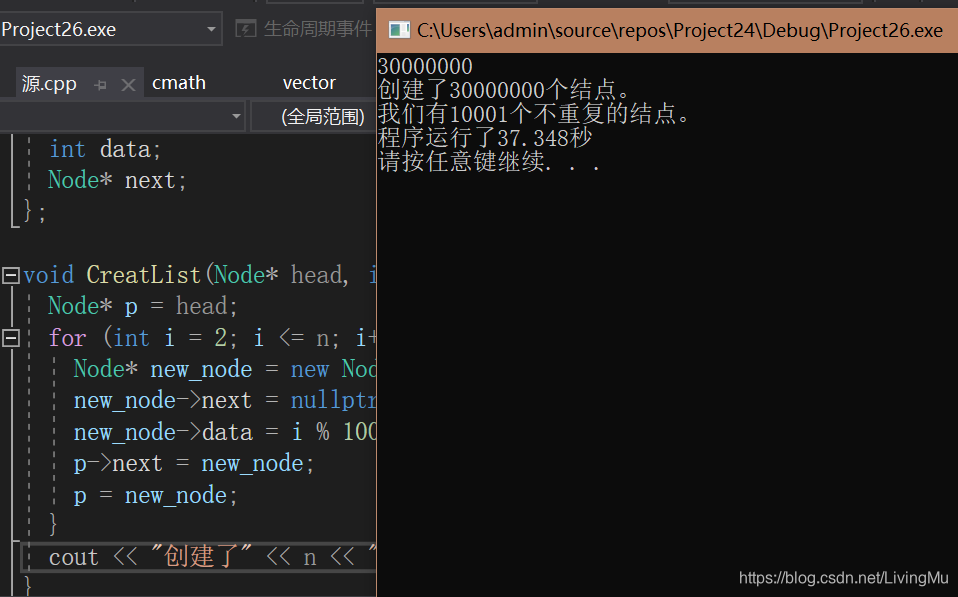
40秒就搞掂啦!
再用试卷上的程序创建3000万个节点。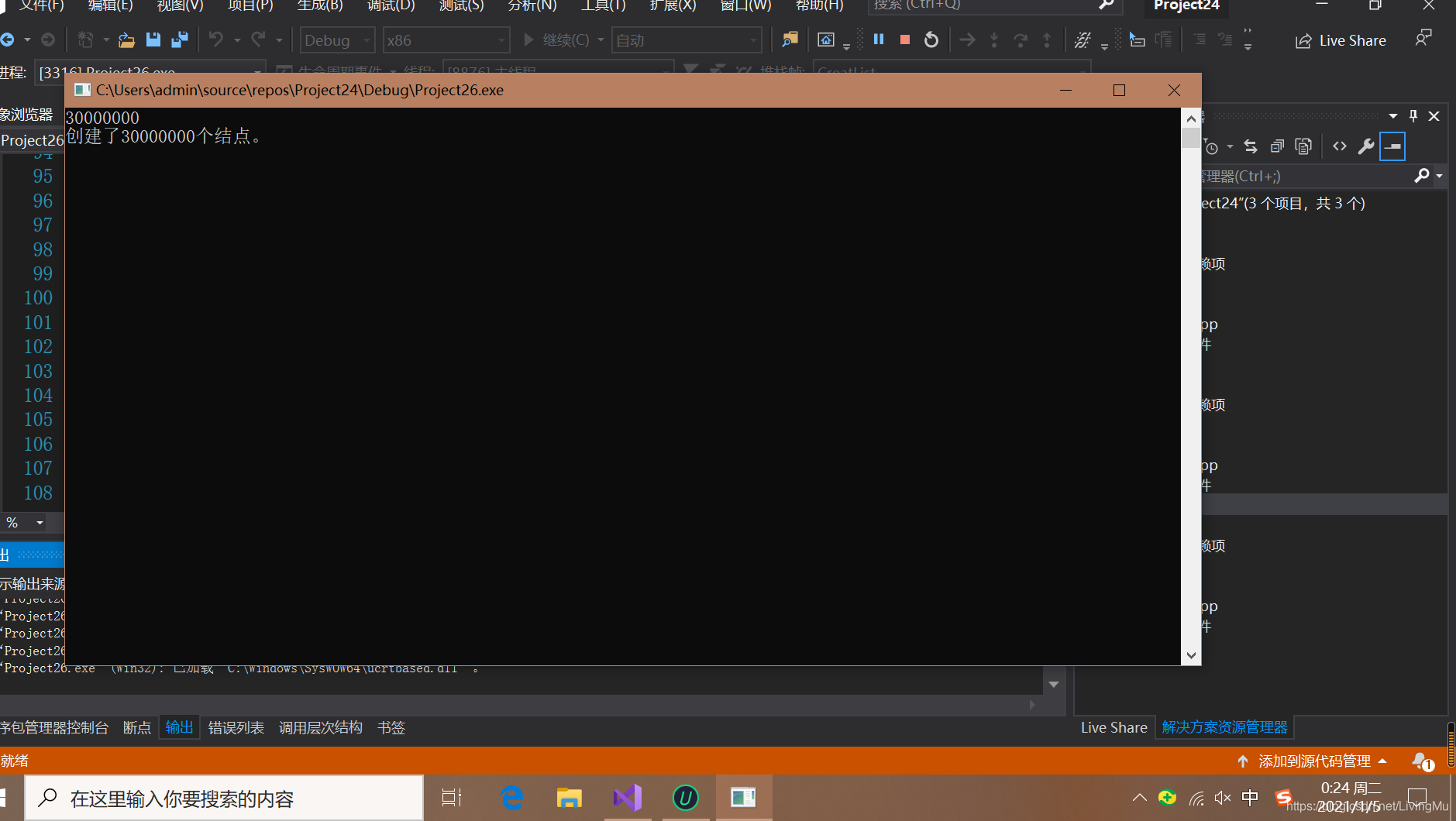
额 ~我都等到12点半啦 ~ 你倒是快点出结果呀!
好吧,你继续运行,我睡觉去啦!
唔~ 风扇太吵,还是把我的“小钢炮”电脑装在柜子里面运行吧。
那个夜晚,我能感受到我的小钢炮被算法支配而发出的“呼呼呼”呻吟声。

第二天,让我看看运行了多少秒?
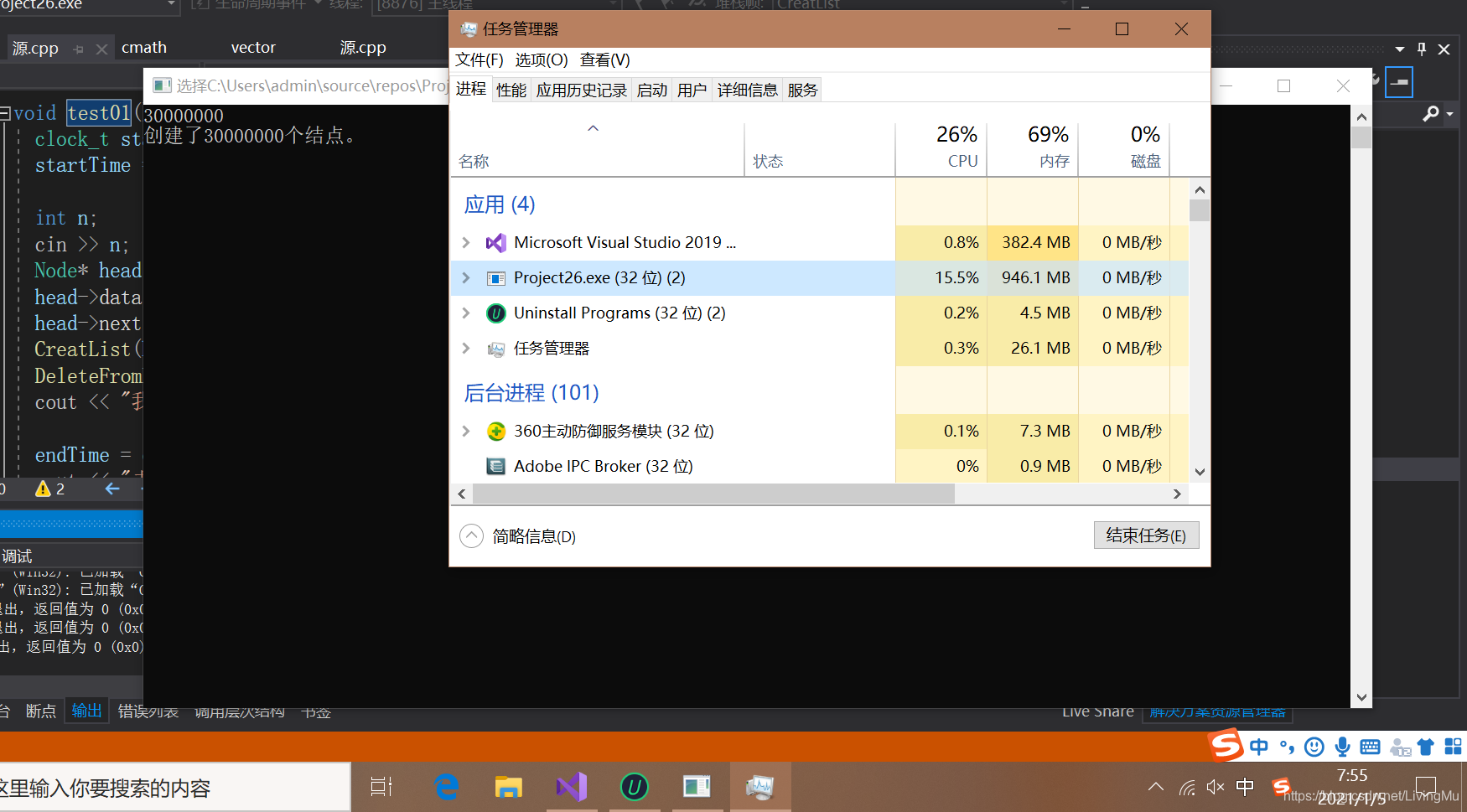
现在是早上7:55。花了一个晚上,也没扫描完3000万个结点。因为马上要上课了,我不得结束运行。
这不由得让我产生了思考,我应该如何直观比较他们的运行速度呢?有了,我可以让系统随时记录生成情况呀!
思路:
对于未优化的算法,每扫描1个结点记录一次结果。
对于优化的算法,每扫描10万个结点记录一次结果。
那么,有意思的就来了:
未优化算法:
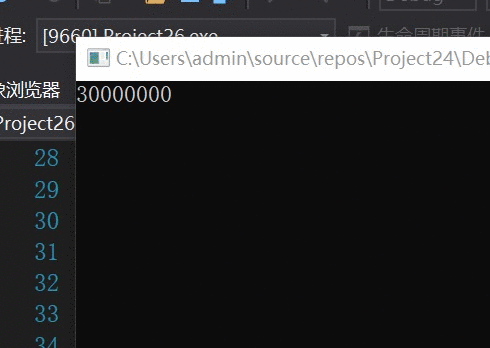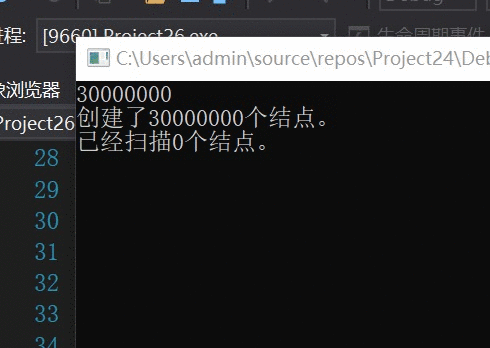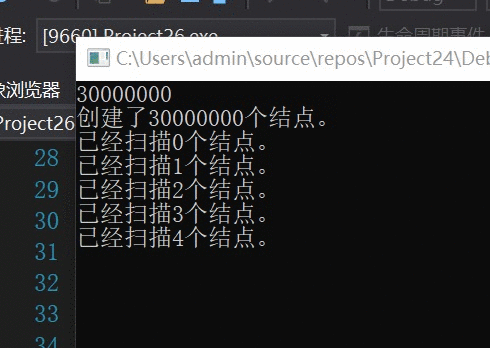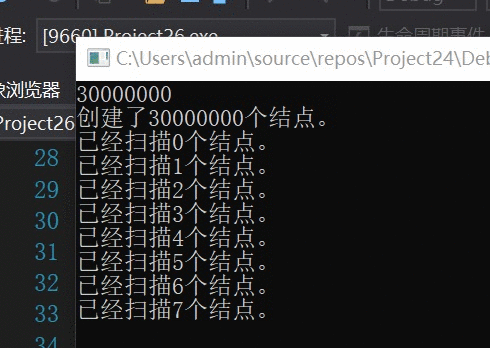
速度还是不错的,预计我大学毕业就能得出结果~~
优化算法:
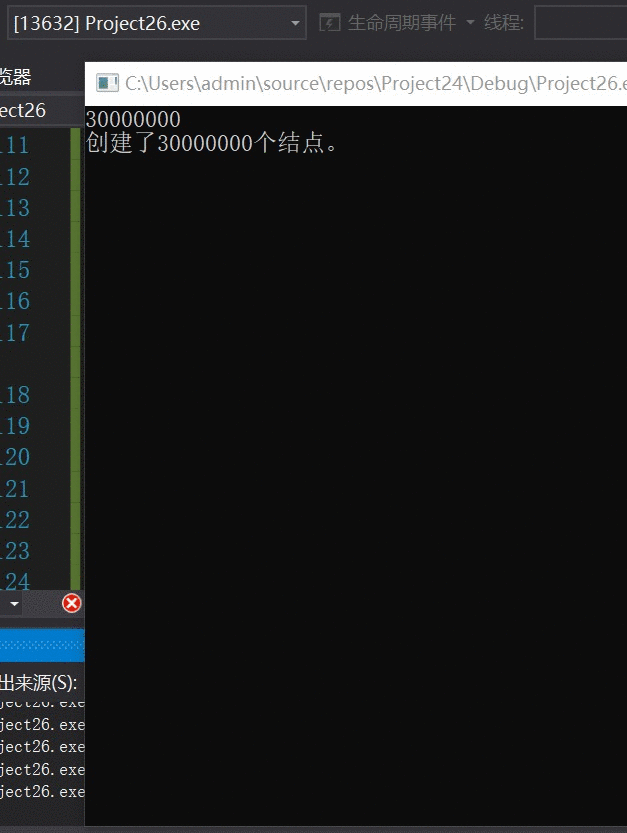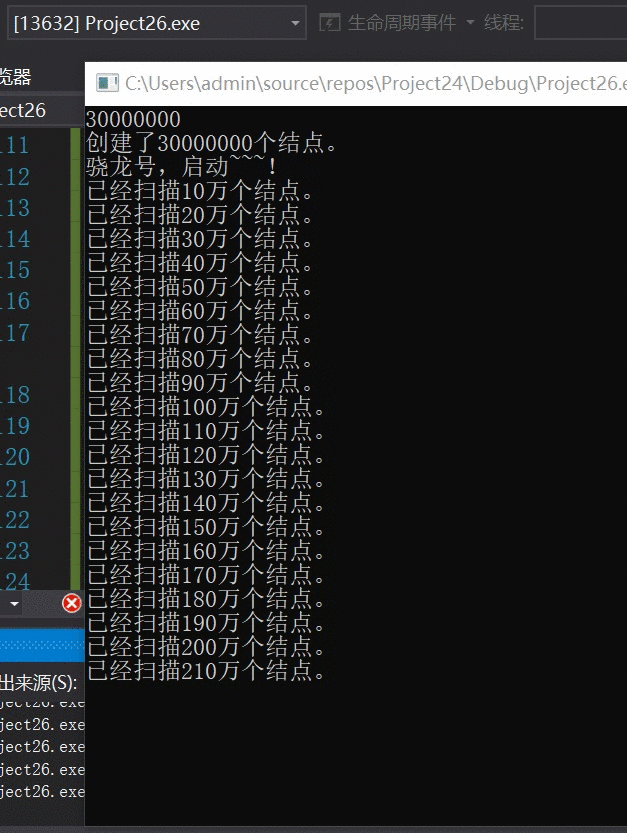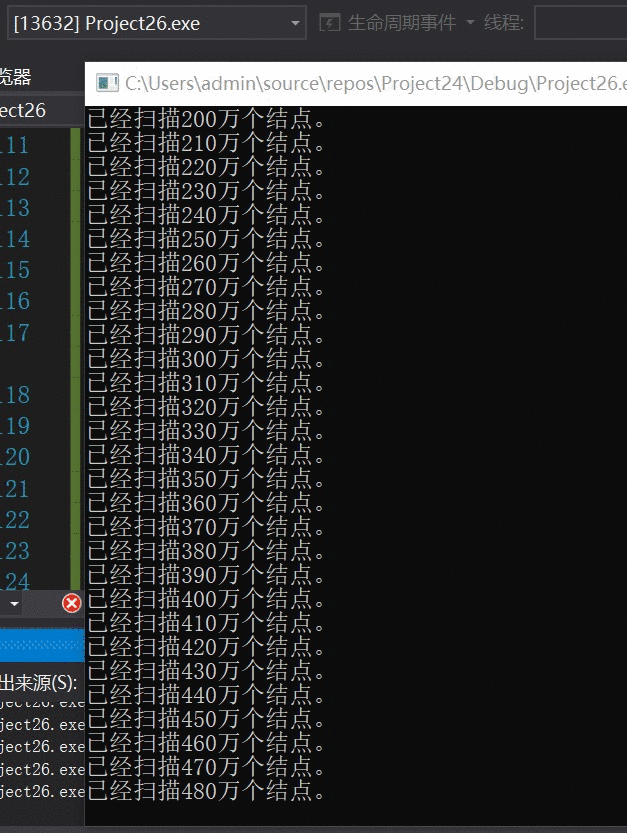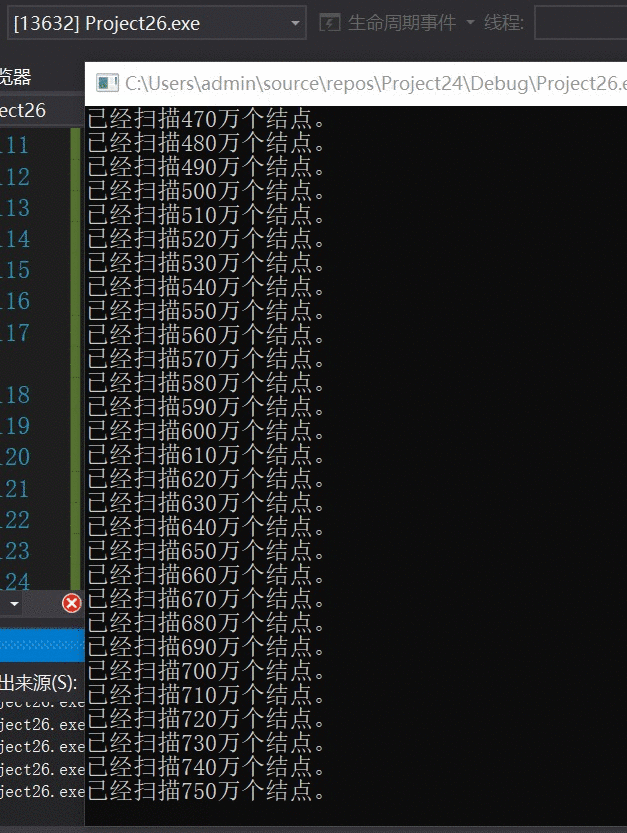
我的天!~ !扫描效率相差百万倍!
最后查阅资料得知,未优化的算法的时间复杂度是n^2,优化后是n。举个例子,优化的程序的时间消耗是y=x这样的增长曲线,那么未优化的程序时间消耗就是y=x ^2。这两个图像在前期差别不大,但是后期一定会是天壤之别!
我不经感慨,我和大佬的学习差别不正是如此吗?大佬的困惑是以随着学习量线性增加,而我是以x^2的曲线增加。在0<x<1的阶段,我还认为所谓的大佬也不过如此嘛~但是当x>1的一刹那起,我逐渐体会到了被大佬支配的恐惧。
那是一种被碾压征服的无力~!
所有代码我都放在了下面。如果有兴趣想测试,可以直接在main函数中调用test01或test02函数即可。test01是书本上的测试方式,test02是优化后的测试方式。
#include<iostream>
#include<unordered_map>
#include<ctime>
using namespace std;
struct Node {
int data;
Node* next;
};
void CreatList(Node* head, int n) {
Node* p = head;
for (int i = 2; i <= n; i++) {
Node* new_node = new Node;
new_node->next = nullptr;
new_node->data = i % 10000;
p->next = new_node;
p = new_node;
}
cout << "创建了" << n << "个结点。" << endl;
}
Node* DeleteFromList(Node* head) {
Node* p, * p1, * p2;
int count = 0;
for (p = head; p != nullptr; p = p->next, count++) {
p1 = p;
p2 = p->next;
while (p2 != nullptr) {
if (p2->data == p->data) {
p1->next = p2->next;
delete p2;
p2 = p1->next;
}
else {
p1 = p2;
p2 = p2->next;
}
}
if (count % 100 == 0) cout << "已经扫描" << count / 100 << "百个结点。" << endl;
}
return head;
}
int CountNode(Node* head) {
int count = 0;
Node* phead = head;
while (phead != nullptr) {
phead = phead->next;
count++;
};
return count;
}
Node* MyDelete(Node* head, unordered_map<int, int>& mp) {
if (head == nullptr || head->next == nullptr) return head;
Node* first = head, * second = head->next;
int count = 0;
while (second != nullptr) {
while (mp[first->data] >= 1 && second != nullptr) { //可能有小bug
mp[first->data] = -1;
first = second;
second = second->next;
count++;
if (count % 10000 == 0) cout << "已经扫描" << count / 10000 << "万个结点。" << endl;
}
while (second != nullptr && mp[second->data == -1]) {
count++;
second = second->next;
first->next = second;
if (count % 10000 == 0) cout << "已经扫描" << count / 10000 << "万个结点。" << endl;
}
first->next = second;
first = second;
}
return head;
}
void test01() {
clock_t startTime, endTime;
startTime = clock();
int n;
cin >> n;
Node* head = new Node;
head->data = 1;
head->next = nullptr;
CreatList(head, n);
DeleteFromList(head);
cout << "我们有" << CountNode(head) << "个不重复的结点。" << endl;
endTime = clock();
cout << "试卷上的程序运行了" << (double)(endTime - startTime) / CLOCKS_PER_SEC << "秒" << endl;
}
void test02() {
clock_t startTime, endTime;
startTime = clock();
unordered_map<int, int> mp;
int n;
cin >> n;
Node* head = new Node, * phead = head;
head->data = 1;
head->next = nullptr;
CreatList(head, n);
while (phead != nullptr) { //将数据存储在表中
mp[phead->data]++;
phead = phead->next;
}
MyDelete(head, mp);
cout << "我们有" << CountNode(head) << "个不重复的结点。" << endl;
endTime = clock();
cout << "我的程序运行了" << (double)(endTime - startTime) / CLOCKS_PER_SEC << "秒" << endl;
}
int main() {
test02();
system("pause");
return 0;
}
后记:
1.写程序加上写博客花了两三个小时左右,因为要考试,所以我编写的优化代码还可以进一步优化。
2.千万不要用机房的电脑运行这个程序,即便是性能最猛的4D机房,我生成1000万个结点直接就把电脑搞奔溃了。
3.如果你很闲,可以使用5000+元的笔记本电脑或者是2000+元的台式机生成千万个结点。
4.理论上用我的算法可以在几分钟内扫描数亿个结点,但是为什么我只测试了3000万个结点呢?因为我猜测我的“小钢炮”只能装下3000万个结点。
计算如下:1个结点8字节,1个哈希表单元8字节,(8+8)*3000万 / 1024 / 1024 …(呃,我也不知道是否正确~ )
5.感谢大佬们教我各种奇技淫巧。
6.最重要的是,大家一定会考高分!















 2665
2665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









