






目录
2.1 从数据中学习
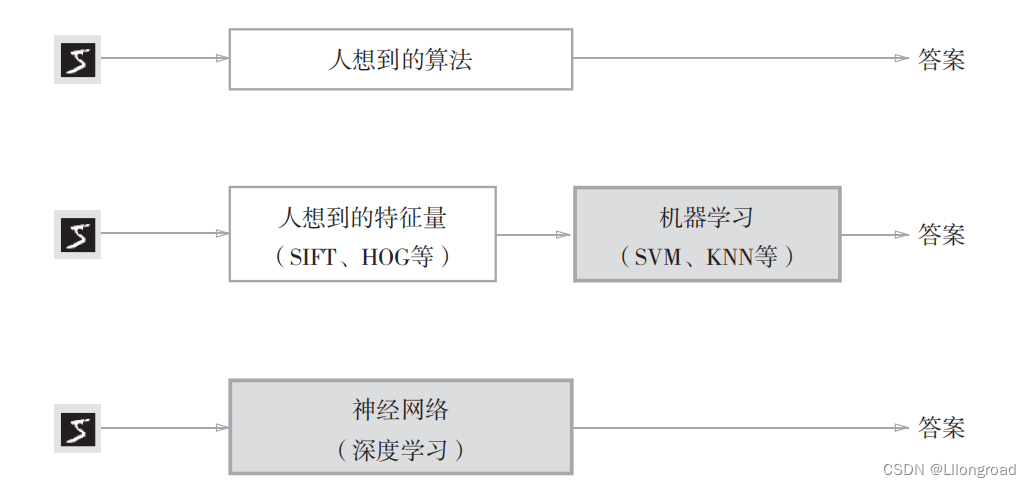
学习的目的:以损失函数为基准,找出能够使得它的值最小的权重参数
从人工设计规则转换为由机器从数据中进行学习,深度学习可以理解为端到端的学习,也就是从原始数据(输入)中获得目标结果(输出),神经网络可以将数据直接作为原始数据。
2.1.1 学习过程
机器学习中,数据分为训练数据和测试数据两部分(目的是为了正确评价模型的泛化能力,也就是处理未被观察过的数据的能力):
首先,使用训练数据(监督数据)进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。
2.2 损失函数
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合。一般使用均方误差和交叉熵误差等。
2.2.1 均方误差
均方误差是计算神经网络的输出和正确解监督数据的各个元素之差的平方
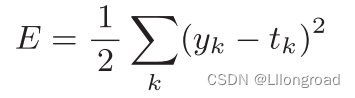 | (2.1) |
其中,表示神经网络的输出,
表示监督数据,k表示数据的维数
使用代码实现如下:
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)2.2.2 交叉熵误差
只计算对应正确解标签的输出的自然对数
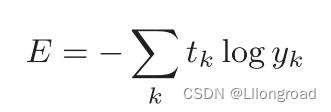 | (2.2) |
其中,log表示以e为底数的自然对数,表示神经网络的输出,
表示正确解标签(只有正确解标签的索引为1,其他均为0(one-hot表示))
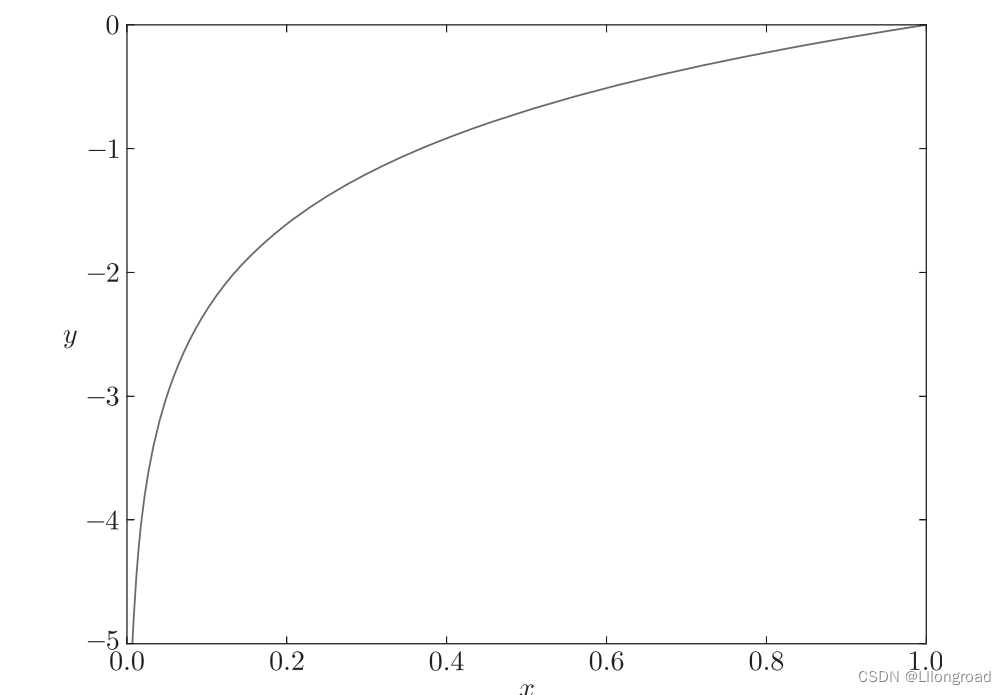
自然对数图像如下:
使用代码实现如下(添加微小数值防止负无限大的发生):
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))2.2.3 mini-batch学习
目的:以MNIST数据集为例,其训练数据有60000个,若以全部数据为对象求损失函数的和,计算需要花费很多时间。故从全部数据中选出一部分,作为全部数据的“近似”。
开始编写从训练数据中随机选择指定个数的数据的代码
首先,引入用于读入MNIST数据集的代码
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
(x_train,t_train),(x_test,t_test) = \
load_mnist(normalize=True,one_hot_label=True)
print(x_train.shape) #(60000,784)
print(t_train.shape) #(60000,10)通过设定参数one_hot_label=True,可以得到one-hot表示(即正确解标签为1,其余为0的数据结构)
下面可以使用NumPy的np.random.choice(),写成如下形式:
train_size = x_train.shape[0]
batch_size = 10
#np.random.choice从0到train_size-1的范围里面抽取batch_size个数字
batch_mask = np.random.choice(train_size,batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]2.2.4 mini-batch版交叉熵误差的实现
'对应mini-batch学习的交叉熵误差'
def cross_entropy_error(y,t):
if y.ndim == 1:
t = t.reshape(1,t.size)
y = y.reshape(1,y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
#监督数据为非one-hot
def cross_entropy_error(y,t):
if y.ndim == 1:
t = t.reshape(1,t.size)
y = y.reshape(1,y.size)
batch_size = y.shape[0]
#arrange生成一个从0到batch_size-1的数组
t = [2,4,6,8,10]
print([np.arrange(5),t])
return -np.sum(np.log(y[np.arrange(batch_size),t]+1e-7)) / batch_size对于代码,np.log(y[np.arrange(batch_size),t]+1e-7),np.arrange(batch_size)会生成一个从0到batch_size-1的数组。对于t中的标签储存的方式是, t = [2,4,6,8,10],故该程序可以抽出各个数据的正确解标签对应的神经网络的输出。
2.3 数值微分
2.3.1 导数
形式如下:
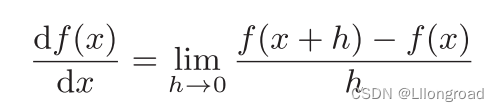 | (2.3) |
为减小误差,可以计算函数f在(x+h)和(x-h)之间的差分,代码实现如下:
def numerical_diff(f,x):
h = 1e-4
return ((f(x+h)-f(x-h))) / (2*h)2.3.2 偏导数
形式如下:
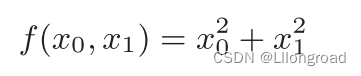 | (2.4) |
2.4 梯度
一起计算x_0,x_1的偏导数,像![]() 这样的由全部变量的偏导数汇总而成的向量称为梯度(梯度指示的方向是各点处函数值减小最多的方向),实现代码如下:
这样的由全部变量的偏导数汇总而成的向量称为梯度(梯度指示的方向是各点处函数值减小最多的方向),实现代码如下:
def _numerical_gradient_1d(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad2.4.1 梯度法
用数学式表示梯度法:
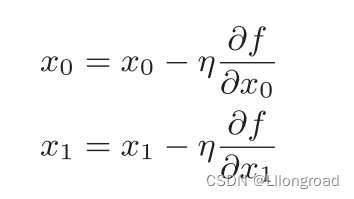 | (2.5) |
![]() 表示更新量,神经网络学习中称为学习率,其决定在一次学习中,应该学习多少,以及在多大程度上更新参数。学习率需要事先确定某个值,过大过小都是不可以的。使用代码实现梯度下降法如下:
表示更新量,神经网络学习中称为学习率,其决定在一次学习中,应该学习多少,以及在多大程度上更新参数。学习率需要事先确定某个值,过大过小都是不可以的。使用代码实现梯度下降法如下:
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x参数f是要进行优化的参数,init_x是初始值,lr是学习率,step_num是梯度法的重复次数。numerical_gradient(f, x)会求函数的梯度,用该梯度乘以学习率得到的数值进行更新操作。
学习率这样的参数一般称为超参数,相对于神经网络的权重参数是通过训练数据和学习算法自动获得的,学习率是由人工设定的。
2.4.2 神经网络的梯度
神经网络在学习的时候也需要求梯度,此处梯度指的是损失函数关于权重参数的梯度。
比如,有一个只有一个形状为2*3的权重W的神经网络,损失函数用L表示。用数学式表示如下:
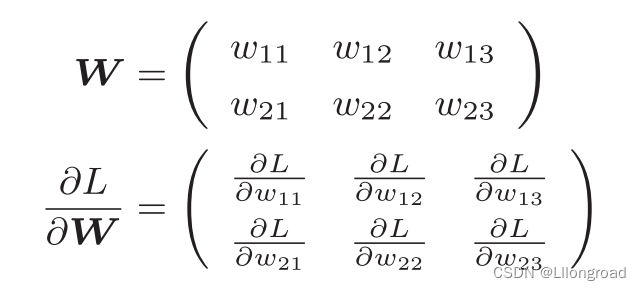 | (2.6) |
以简单神经网络为例,实现求梯度的代码如下:
import sys, os
sys.path.append(os.pardir)
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) #用高斯分布进行初始化
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return losssimpleNet包含两个方法:一是用于预测的predict,另一个是用于求损失函数值的loss(x,t),此处参数x接收输入数据,t接收正确解的标签。
2.5 学习算法的实现
神经网络的学习步骤
步骤1
从训练数据中随机选出一部分数据,这部分数据被称为:mini-batch。目的是为了减小mini-batch的损失函数的数值
步骤2(计算梯度)
为了减小损失函数的数值,需要求出各个权重参数的梯度,梯度表示损失函数的值减小最多的方向。
步骤3(更新参数)
将权重参数沿着梯度方向进行微小的更新
步骤4(重复)
重复上面的步骤
此处使用的数据是随机选择的mini batch数据,故称为随机梯度下降法。
2.5.1 2层神经网络的类
将2层神经网络实现一个名为TwoLayerNet的类。实现代码如下:
#学习算法的实现
import numpy as np
import sys, os
sys.path.append(os.pardir)
from tidu import numerical_gradient
from loss_function import cross_entropy_error
from functions import *
class TwoLayerNet:
def __init__(self,input_size,hidden_size,output_size,
weight_init_std=0.01):
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(input_size,hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * \
np.random.randn(hidden_size,output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self,x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1,W2) + b2
y = softmax(a2)
return y
# x:输入数据,t:监督数据
def loss(self,x,t):
y = self.predict(x)
return cross_entropy_error(y,t)
def accuracy(self,x,t):
y = self.predict(x)
y = np.argmax(y,axis=1)
t = np.argmax(t,axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
#计算各参数的梯度
def numerical_gradient(self,x, t):
loss_W = lambda W: self.loss(x,t)
grads = {}
grads['W1'] = numerical_gradient(loss_W.self.params['W1'])
grads['b1'] = numerical_gradient(loss_W.self.params['b1'])
grads['W2'] = numerical_gradient(loss_W.self.params['W2'])
grads['b2'] = numerical_gradient(loss_W.self.params['b2'])
return grads
其中:np.random.randn是NumPy中用于生成服从标准正态分布(均值为0,标准差为1)的随机数的函数。它生成的随机数遵循标准正态分布,也称为高斯分布。np.zeros(hidden_size)表示生成一个一维,元素个数为hidden_size的数组。
实现TwoLayerNet方法的时候,实现进行类的初始化,从第一个参数开始,依次表示输入层的神经元数、隐藏层的神经元数、输出层的神经元数。此处进行的是手写数字识别,输入图像的大小为784,输出为10个类别,故指定参数:input_size=784,output_size=10.将隐藏层设置为一个合适的数值即可。
权重使用符合高斯分布的随机数进行初始化,偏置使用0进行初始化。
numerical_gradient方法会计算各个参数的梯度,根据数值微分,计算各个参数相对于损失函数的梯度。
TwoLayerNet的类使用的变量用列表的形式给出:
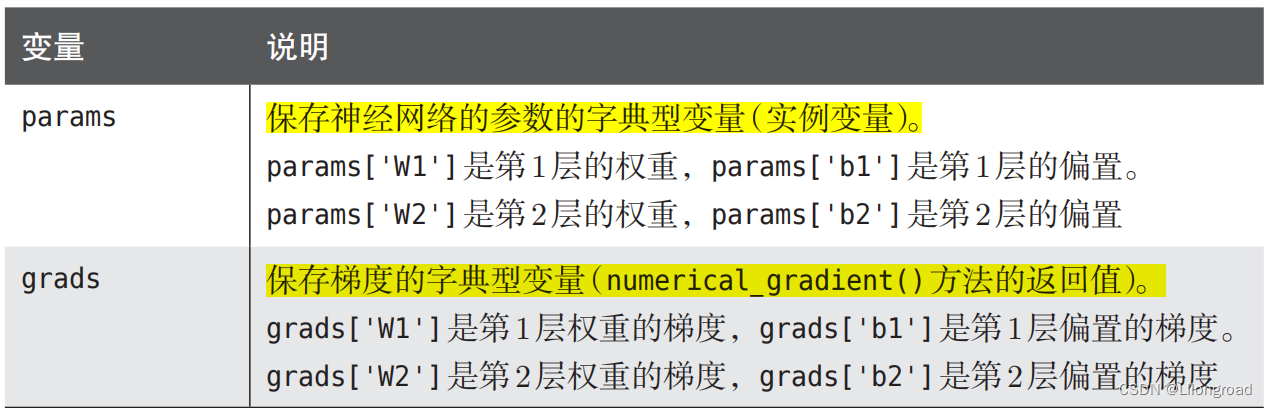 |
TwoLayerNet的类的方法如下:
 |
2.5.2 mini-batch的实现
神经网络的实现使用的是mini-batch学习,即从训练数据中随机选择一部分的数据(称为mini-batch),然后以这些mini-batch为对象,使用梯度法更新参数的过程。
import numpy as np
from mnist import load_mnist
from two_layer_net_my import TwoLayerNet
(x_train, t_train),(x_test, t_test) =load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
train_acc_list = []
test_acc_list = []
#平均每个epoch的重复次数
iter_per_epoch = max(train_size / batch_size,1)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50,output_size=10)
for i in range(iters_num):
#获取mini-batch
batch_mask = np.random.choice(train_size,batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
#计算梯度
grad = network.numerical_gradient(x_batch,t_batch)
#更新参数
for key in ('W1','b1','W2','b2'):
network.params[key] -= learning_rate * grad[key]
#记录学习过程
loss = network.loss(x_batch,t_batch)
train_loss_list.append(loss)此处,mini-batch的大小为100.需要每次从60000个训练数据取出100个数据(图像数据和正确解的标签数据),然后,对这个包含100笔数据的mini-batch求梯度,使用随机梯度下降法(SGD)更新参数。每更新一次,就对训练数据计算损失函数的值,并且把这个值添加到数组中。
2.5.3 基于测试数据的评价
神经网络的学习中,必须确认是否能够正确识别训练数据以外的其他数据,也就是确认是否会过拟合。过拟合也就是,虽然训练数据中的数字图像能够被正确辨别,但是不在训练数据中的数字图像却无法被识别的现象。
为进行正确评价,使用以下代码进行:
import numpy as np
from mnist import load_mnist
from two_layer_net_my import TwoLayerNet
(x_train, t_train),(x_test, t_test) =load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
train_acc_list = []
test_acc_list = []
#平均每个epoch的重复次数
iter_per_epoch = max(train_size / batch_size,1)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50,output_size=10)
for i in range(iters_num):
#获取mini-batch
batch_mask = np.random.choice(train_size,batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
#计算梯度
grad = network.numerical_gradient(x_batch,t_batch)
#更新参数
for key in ('W1','b1','W2','b2'):
network.params[key] -= learning_rate * grad[key]
#记录学习过程
loss = network.loss(x_batch,t_batch)
train_loss_list.append(loss)
#计算每个epoch的识别精度
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train,t_train)
test_acc = network.accuracy(x_test,t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc |" + str(train_acc) + "," + str(test_acc))
上面代码中,每次经过一个epoch(表示学习中所有数据均被使用过一次时的更新次数),就对所有的训练数据和测试数据计算识别精度。















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









