









scrapy的基本知识以及环境搭建请查看前面的博客 Python爬虫框架Scrapy学习二记——Scrapy开发环境配置 以及Python爬虫框架Scrapy学习一记——认识Scrapy
本文将假设我们的scrapy环境已经OK了,然后我们来开始进行第一次爬行体验。本文将实现以下操作:
- 创建一个Scrapy项目
- 定义提取的Item
- 编写爬取网站的 spider 并提取 Item
- 编写 Item Pipeline 来存储提取到的Item(即数据)
1. 创建一个Scrapy项目
一般我建议在学习或者工作目录下单独建立一个目录来存放某一个特定学习项目或者文档(建议而已),直接上命令:
scrapy startproject first_spider
#命令串解释:命令 创建新项目的动作 项目名称(随便起)
建立好之后我们会看到项目结构如下(划掉的部分为后面写的爬虫文件以及爬虫爬取到的文件,初始没有的):
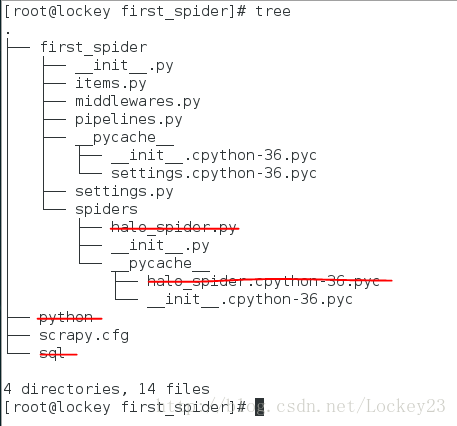
目录中部分文件的作用和含义如下:
scrapy.cfg: 项目的配置文件
first_spider/: 该项目的python模块。之后您将在此加入代码。
first_spider/items.py: 项目中的item文件.
first_spider/pipelines.py: 项目中的pipelines文件.
first_spider/settings.py: 项目的设置文件.
first_spider/spiders/: 放置spider代码的目录.
2. 定义Item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
首先根据需要从runoob.com获取到的数据对item进行建模。 我们需要从根据爬虫获取名字,url,以及网站的描述。 对此,在item中定义相应的字段。编辑 first_spider目录中的 items.py 文件:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class FirstSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
3. 编写第一个爬虫(Spider)来爬取网页
为了创建一个Spider,必须要继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。到时候我们启动爬虫就根据这个名字来的。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
以下为我们的第一个Spider代码,保存在 first_spider/spiders 目录下的 halo_spider.py 文件中:
import scrapy
class DmozSpider(scrapy.Spider):
name = "firstSpider"
#爬虫的名字
allowed_domains = ["runoob.com"]
#所允许爬取得域
start_urls = [
"http://www.runoob.com/sql/",
"http://www.runoob.com/python/"
]
#爬虫开始的链接urls
def parse(self, response):
#定义对于爬虫的返回结果的处理,这里只是做了一个文件保存,到时候就会有sql和python两个文件生成
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
4. 开爬,让虫子动起来
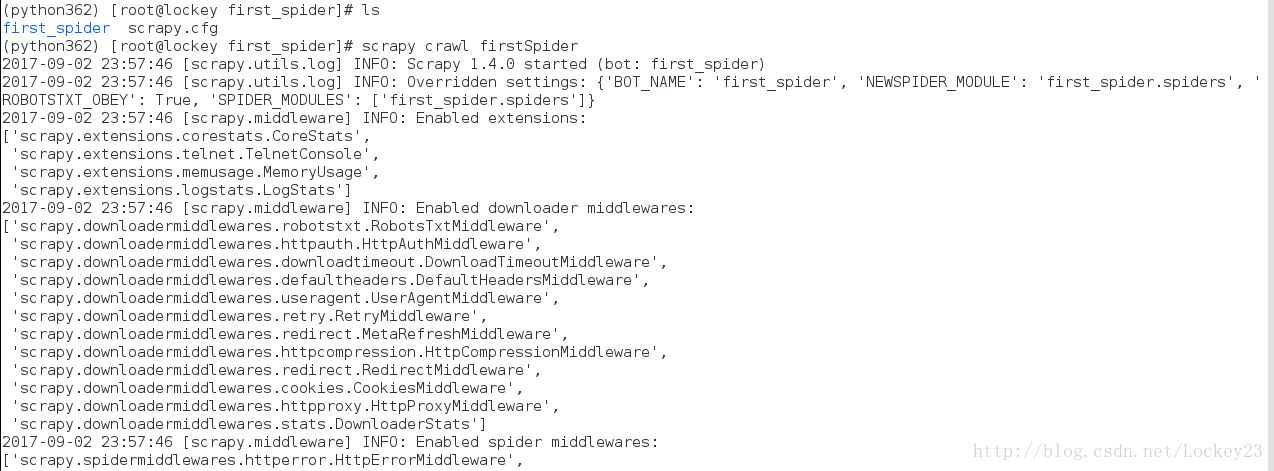
进入项目的根目录(本例中是first_spider),执行下列命令启动spider:
scrapy crawl firstSpider
爬虫启动截图:
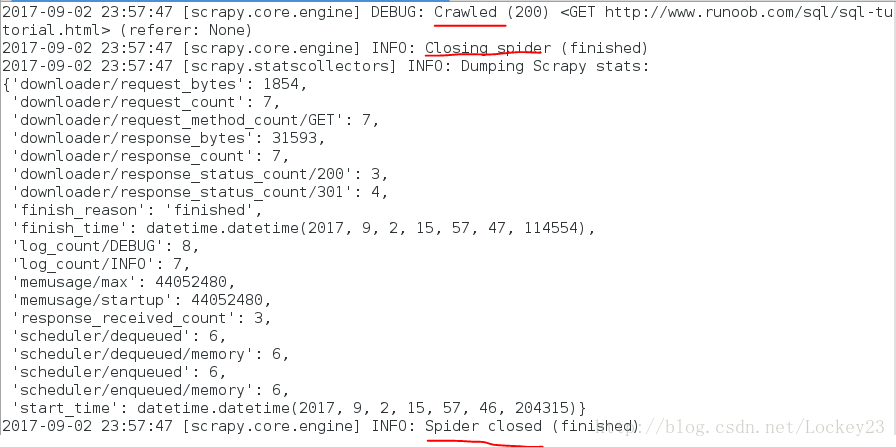
爬去过程截图:
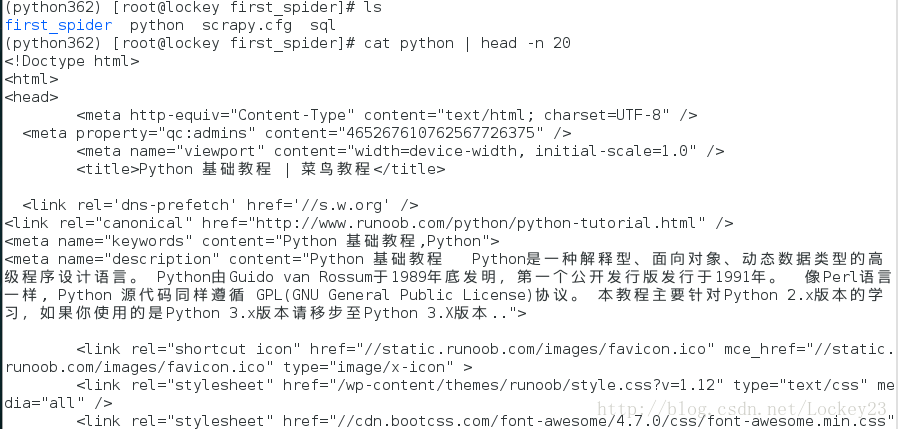
爬去结果截图(得到了两个文件sql和python),查看python名称的文件内容发现是一个网页文件
此过程中:Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
5. 提取Item
提取数据
从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selectors ,没接触过的人可以理解为正则表达式。
我们重新写一下爬虫的处理函数,利用 .xpath() 调用返回selector组成的list,拼接更多的 .xpath() 来进一步获取某个节点信息:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print(title, link, desc)
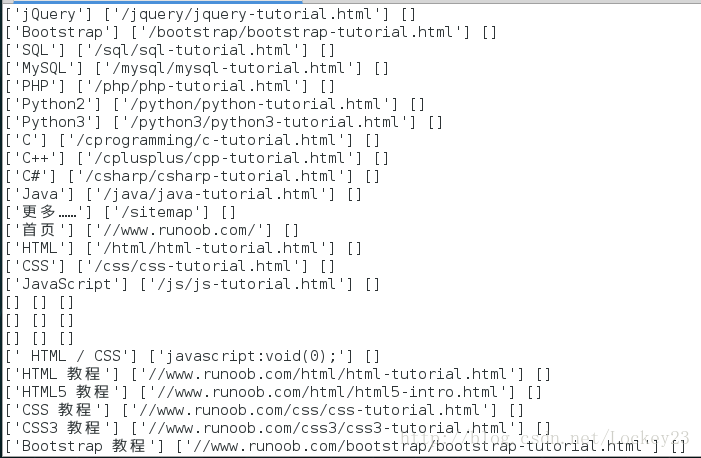
由下图的结果可以看出,爬取得结果现在只包含了网页的标题、链接、描述(大部分为空):
使用item
Item 对象是自定义的python字典。 您可以使用标准的字典语法来获取到其每个字段的值。一般来说,Spider将会将爬取到的数据以 Item 对象返回。所以为了将爬取的数据返回,我们最终的代码将是:
import scrapy
from first_spider.items import FirstSpiderItem
class DmozSpider(scrapy.Spider):
name = "firstSpider"
allowed_domains = ["runoob.com"]
start_urls = [
"http://www.runoob.com/sql/",
"http://www.runoob.com/python/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
item = FirstSpiderItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item
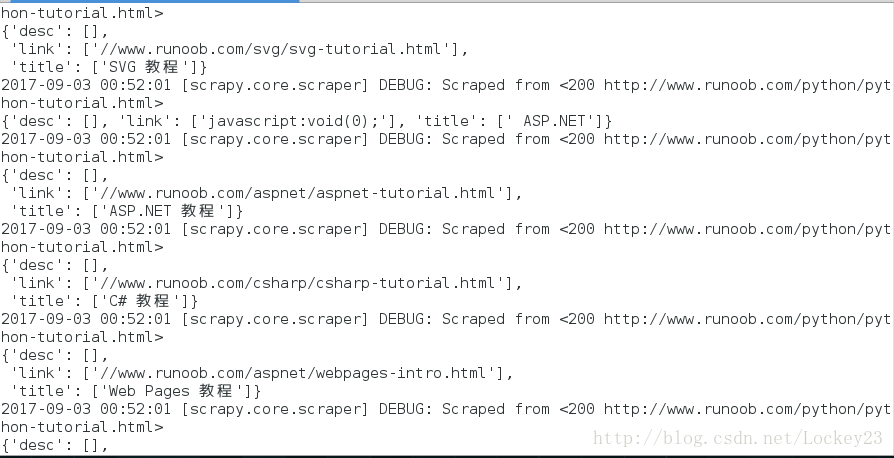
运行结果如下:
可以看到爬取得结果成了字典映射的结构,内容更加清晰了
6. 保存爬取到的数据
scrapy crawl dmoz -o runoob.json
#-o后面跟文件名称
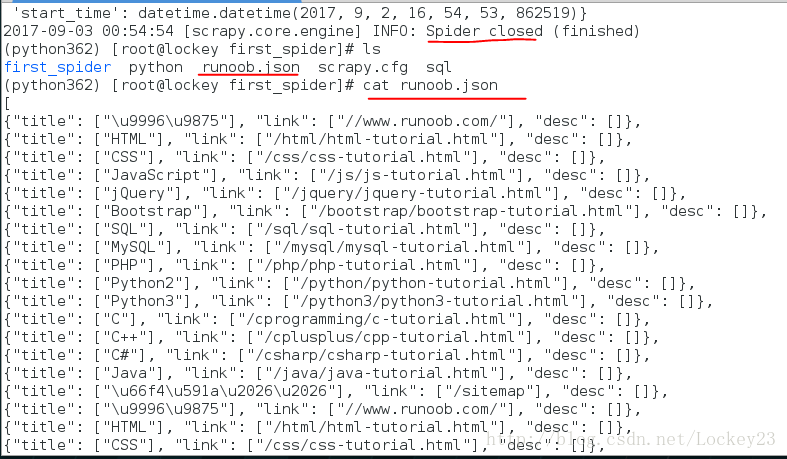
该命令将采用 JSON 格式对爬取的数据进行序列化,生成 runoob.json 文件。
运行结果截图如下,可以看到爬去的数据以json的格式保存到了文件中:
在类似本篇教程里这样小规模的项目中,这种存储方式已经足够。 如果需要对爬取到的item做更多更为复杂的操作,可以编写 Item Pipeline 。 类似于我们在创建项目时对Item做的,用于编写自己的 first_spider/pipelines.py 也被创建。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









