







1.前言
在众多流行的编程语言中,Java对IO的处理应该是最特殊的,Java打着“尽量减少IO类的设计理念”,搞出了目前应该是最复杂的一套IO相关类,并称之为Java流。
对于新手来说,Java流包含的类众多,含义混杂,上手困难且其中暗藏的陷阱众多;但是对于熟悉了Java流的程序员来说,它的确称得上功能强大。
本文总结了一些Java流的使用指南,给出了一些实例代码,主要内容包括:
- Java流中的字节与字符
- 文件流
- 字节数组流
- 管道流
- 缓冲流
- 数据流
- 压缩流
- 摘要流
- 加密流
- 多重流使用范例
本文的读者应该是Java程序员,最好具有基本的Java基础知识。本文给出的代码都已经在Jdk7上运行通过,如有错误,请及时反馈。
2.Java中的字节与字符
2.1Java流概论
Java流是Java语言用来处理IO的一套类,针对字节进行处理的类被命名为stream结尾,例如FileInputStream、FileOutputStream;针对字符进行处理的类被命名为Reader或Writer结尾,例如FileReader或者FileWriter。要弄清Java流,首先要明白Java中的字节与字符的区别。
包含InputStream或Reader的类被称为输入流,此处的“输入”是指从外部(文件、网络、其他程序)将信息输入到Java程序内部;或者指从Java程序内部的某个变量输入到当前操作的代码块。
包含OutputStream或Writer的类被称为输出流,此处的“输出”是指从Java程序内部将信息输出到外部(文件、网络、其他程序);或者指从当前操作的代码块将信息输出到其他变量。
2.2 字节(byte)的取值
一个字节包含一个8位的二进制数字,在Java中使用byte来表示。最大值为127,最小值为-128。下面的代码列出了所有byte的值:
public static void listAllByteValue(){
for (int i = -128; i < 128; i++) {
byte b = (byte) i;
System.out.println("byte:" + b + ",Binary:" + byteToBinaryString(b));
}
}
public static String byteToBinaryString(byte b) {
String s = Integer.toBinaryString(b);
if (b < 0) {
s = s.substring(24);
} else {
if (s.length() < 8) {
int len = s.length();
for (int i = 0; i < 8 - len; i++) {
s = "0" + s;
}
}
}
return s;
}
大于等于0的byte值,使用其原码表示,即直接存储该byte的二进制值;小于0的byte值,使用其补码表示,即将该值的绝对值的原码按位取反再加1。例如42就存储为00101010;而-42先求42的值00101010,然后按位取反得到11010101,再加1得到11010110,此即为-42的二进制值。
2.3 字节(byte)的赋值
byte可以用多种方法来赋值,见下列代码:
public static void byteGetValue(){
//二进制以0b开头
byte b1 = 0b00101010;
System.out.println("b1:"+b1+",Binary:"+byteToBinaryString(b1));
//八进制以0开头
byte b2 = 052;
System.out.println("b2:"+b2+",Binary:"+byteToBinaryString(b2));
//十进制
byte b3 = 42;
System.out.println("b3:"+b3+",Binary:"+byteToBinaryString(b3));
//十六进制
byte b4 = 0x2a;
System.out.println("b4:"+b4+",Binary:"+byteToBinaryString(b4));
//-42的赋值
//二进制,由于11010110以原码来理解已经超过了127,因此必须使用byte进行强制类型转换
byte b5 = (byte) 0b11010110;
System.out.println("b5:"+b5+",Binary:"+byteToBinaryString(b5));
//八进制以0开头
byte b6 = -052;
System.out.println("b6:"+b6+",Binary:"+byteToBinaryString(b6));
//十进制
byte b7 = -42;
System.out.println("b7:"+b7+",Binary:"+byteToBinaryString(b7));
//十六进制,由于0xd6以原码来理解已经超过了127,因此必须使用byte进行强制类型转换
byte b8 = (byte) 0xd6;
System.out.println("b8:"+b8+",Binary:"+byteToBinaryString(b8));
//将两个int转为byte的示例,示例告诉我们int转byte,就是简单的截取最后8位
int i1 = 0b001011010110;
int i2 = 0b110011010110;
System.out.println("i1 = "+i1+", i2 = "+i2);
byte b9 = (byte) i1;
byte b10 = (byte) i2;
System.out.println("b9 = "+b9+", b10 = "+b10);
}
值得注意的是,当int转换为byte时,直接截取了int的后8位。
运行结果:
b1:42,Binary:00101010
b2:42,Binary:00101010
b3:42,Binary:00101010
b4:42,Binary:00101010
b5:-42,Binary:11010110
b6:-42,Binary:11010110
b7:-42,Binary:11010110
b8:-42,Binary:11010110
i1 = 726, i2 = 3286
b9 = -42, b10 = -42
2.4 字符(char)的取值
由上面的例子可知byte就是一个单纯的8位二进制数字,它可以有多种赋值方法,但是在内存中始终不变。
字符在Java中使用char基本类型来存储,它是一个16位的unicode码,也可以理解为一个16位的二进制数字,其取值范围为0到65535(2的16次方-1)。下面的例子给出了一段中文的char值:
public static void listCharValue() {
System.out.println("char max value is :"+(int)Character.MAX_VALUE+", min value is :"+(int)Character.MIN_VALUE);
for (char c = 19968; c < 20271; c++) {
System.out.print(c);
}
}
运行结果:
char max value is :65535, min value is :0
一丁丂七丄丅丆万丈三上下丌不与丏丐丑丒专且丕世丗丘丙业丛东丝丞丟丠両丢丣两严並丧丨丩个丫丬中丮丯丰丱串丳临丵丶丷丸丹为主丼丽举丿乀乁乂乃乄久乆乇么义乊之乌乍乎乏乐乑乒乓乔乕乖乗乘乙乚乛乜九乞也习乡乢乣乤乥书乧乨乩乪乫乬乭乮乯买乱乲乳乴乵乶乷乸乹乺乻乼乽乾乿亀亁亂亃亄亅了亇予争亊事二亍于亏亐云互亓五井亖亗亘亙亚些亜亝亞亟亠亡亢亣交亥亦产亨亩亪享京亭亮亯亰亱亲亳亴亵亶亷亸亹人亻亼亽亾亿什仁仂仃仄仅仆仇仈仉今介仌仍从仏仐仑仒仓仔仕他仗付仙仚仛仜仝仞仟仠仡仢代令以仦仧仨仩仪仫们仭仮仯仰仱仲仳仴仵件价仸仹仺任仼份仾仿伀企伂伃伄伅伆伇伈伉伊伋伌伍伎伏伐休伒伓伔伕伖众优伙会伛伜伝伞伟传伡伢伣伤伥伦伧伨伩伪伫伬伭伮
2.5 字符(char)的赋值
后面会提到,char可以表现为世界各国的各种字符,但是在内存中,它就是一个16位的二进制数字,因此其赋值方法也与byte一样多种多样。
public static void charGetValue() {
//把'一'赋值给char
char c1 = '一';
System.out.println(c1);
char c2 = 0b100111000000000;
System.out.println(c2);
char c3 = 047000;
System.out.println(c3);
char c4 = 19968;
System.out.println(c4);
char c5 = 0x4e00;
System.out.println(c5);
char c6 = '\u4e00';
System.out.println(c6);
int i1 = (int) '一';
System.out.println(Integer.toHexString(i1));
}
运行结果:
一
一
一
一
一
一
4e00
2.6 char转换为byte
char存储的是字符,在很多情况下它需要被转换为字节,例如存储到文件中时,或者在网络上进行传递时。当字符转换为byte时,需要用到编码格式,例如GBK或者unicode或者UTF-8等等,不同的编码格式转换得到的byte数组也不一样,如下图所示:
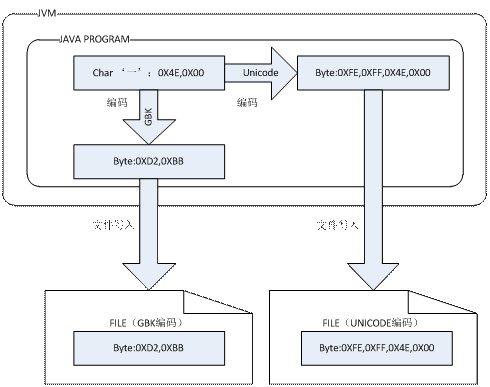
关于编码格式的详细介绍,可以去搜索其他文章,简要说一下:
Java内部使用Unicode作为char的编码格式,它又分为UCS-2(每两个字节代表一个char)和UCS-4(每四个字节代表一个char),目前主流的都是UCS-2。当把字符或者字符串转换为unicode时,会在头部加入两个字节的标志位(FE FF)表示big Endian(字节序,内存低位地址存放最高有效字节)。
UTF-8编码:一个英文字符占一个字节,一个汉字占三个字节;
GBK编码:一个英文字符占一个字节,一个汉字占两个字节。
代码如下:
public static void charToBytes() {
try {
byte[] buf1 = "一".getBytes("unicode");
System.out.println("---------unicode---------");
for (int i = 0; i < buf1.length; i++) {
System.out.println(Integer.toHexString(buf1[i]));
}
System.out.println("---------UTF-8---------");
byte[] buf2 = "一".getBytes("UTF-8");
for (int i = 0; i < buf2.length; i++) {
System.out.println(Integer.toHexString(buf2[i]));
}
System.out.println("---------UTF-16---------");
byte[] buf3 = "一".getBytes("UTF-16");
for (int i = 0; i < buf3.length; i++) {
System.out.println(Integer.toHexString(buf3[i]));
}
System.out.println("---------gbk---------");
byte[] buf4 = "一".getBytes("gbk");
for (int i = 0; i < buf4.length; i++) {
System.out.println(Integer.toHexString(buf4[i]));
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
public static String byteToHexString(byte b) {
String s = Integer.toHexString(b);
int len = s.length();
if (len >= 2) {
s = s.substring(len - 2);
}else{
s = "0"+s;
}
return s;
}
运行结果:
---------unicode---------
fffffffe
ffffffff
4e
0
---------UTF-8---------
ffffffe4
ffffffb8
ffffff80
---------UTF-16---------
fffffffe
ffffffff
4e
0
---------gbk---------
ffffffd2
ffffffbb
2.7 byte转换为char
当Java程序从外部(文件、网络、其他应用程序)读入字节流时,若该字节流代表的是字符,则需要将字节转换为字符,此动作被称为转码。转码时需要注意其编码格式,例子如下:
public static void byteToChar() {
byte[] unicode_b = new byte[4];
unicode_b[0] = (byte) 0XFE;
unicode_b[1] = (byte) 0XFF;
unicode_b[2] = (byte) 0X4E;
unicode_b[3] = (byte) 0X2D;
String unicode_str;
byte[] gbk_b = new byte[2];
gbk_b[0] = (byte) 0XD6;
gbk_b[1] = (byte) 0XD0;
String gbk_str;
byte[] utf_b = new byte[3];
utf_b[0] = (byte) 0XE4;
utf_b[1] = (byte) 0XB8;
utf_b[2] = (byte) 0XAD;
String utf_str;
try {
unicode_str = new String(unicode_b, "unicode");
System.out.println("unicode string is:" + unicode_str);
gbk_str = new String(gbk_b, "gbk");
System.out.println("gbk string is:" + gbk_str);
utf_str = new String(utf_b, "utf-8");
System.out.println("utf-8 string is:" + utf_str);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
运行结果如下:
unicode string is:中
gbk string is:中
utf-8 string is:中2.8 转码和乱码
将一种编码格式转换为另一中编码格式称之为转码。Java内部使用unicode来进行字符编码,当将字符转换为byte时需要转码,转为GBK或者其他编码;当从外部读入一段byte数组时,也需将其他编码转换为unicode编码的字符。
转码发生的地方只有两个:从char到byte,或者从byte到char。转码发生时必须指定编码格式,如果不指定编码格式,则会使用默认的编码格式(一是IDE的环境中指定的格式,二是操作系统默认的编码格式),你可以用如下代码获取默认的编码格式:
private static void showNativeEncoding() {
String enc = System.getProperty("file.encoding");
System.out.println(enc);
}如果在转码时使用了错误的编码格式,则会出现乱码。
未完待续……















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









