







EDA
import numpy as np
import pandas as pd
Path=r"C:/Users/10539/Desktop/nlp/"
df_train = pd.read_csv(Path+'train_set.csv', sep='\t')
df_test = pd.read_csv(Path+'test_a.csv', sep='\t')=
df_train.head()
| label | text | |
|---|---|---|
| 0 | 2 | 2967 6758 339 2021 1854 3731 4109 3792 4149 15... |
| 1 | 11 | 4464 486 6352 5619 2465 4802 1452 3137 5778 54... |
| 2 | 3 | 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... |
| 3 | 2 | 7159 948 4866 2109 5520 2490 211 3956 5520 549... |
| 4 | 3 | 3646 3055 3055 2490 4659 6065 3370 5814 2465 5... |
df_test.head()
| text | |
|---|---|
| 0 | 5399 3117 1070 4321 4568 2621 5466 3772 4516 2... |
| 1 | 2491 4109 1757 7539 648 3695 3038 4490 23 7019... |
| 2 | 2673 5076 6835 2835 5948 5677 3247 4124 2465 5... |
| 3 | 4562 4893 2210 4761 3659 1324 2595 5949 4583 2... |
| 4 | 4269 7134 2614 1724 4464 1324 3370 3370 2106 2... |
#按label计数
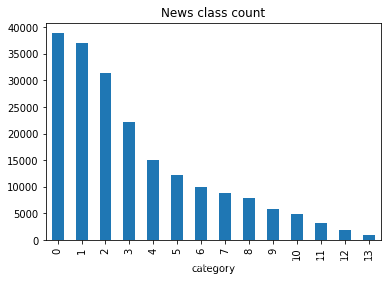
df_train['label'].value_counts()
0 38918
1 36945
2 31425
3 22133
4 15016
5 12232
6 9985
7 8841
8 7847
9 5878
10 4920
11 3131
12 1821
13 908
Name: label, dtype: int64
%%time
df_train['text'] = df_train['text'].apply(lambda x: list(map(lambda y: int(y), x.split())))
df_test['text'] = df_test['text'].apply(lambda x: list(map(lambda y: int(y), x.split())))
Wall time: 1min 2s
df_train.head()
| label | text | text_len | |
|---|---|---|---|
| 0 | 2 | [2967, 6758, 339, 2021, 1854, 3731, 4109, 3792... | 1057 |
| 1 | 11 | [4464, 486, 6352, 5619, 2465, 4802, 1452, 3137... | 486 |
| 2 | 3 | [7346, 4068, 5074, 3747, 5681, 6093, 1777, 222... | 764 |
| 3 | 2 | [7159, 948, 4866, 2109, 5520, 2490, 211, 3956,... | 1570 |
| 4 | 3 | [3646, 3055, 3055, 2490, 4659, 6065, 3370, 581... | 307 |
df_train['text'].map(lambda x: len(x)).describe()
count 200000.000000
mean 907.207110
std 996.029036
min 2.000000
25% 374.000000
50% 676.000000
75% 1131.000000
max 57921.000000
Name: text, dtype: float64
df_test['text'].map(lambda x: len(x)).describe()
count 50000.000000
mean 909.844960
std 1032.313375
min 14.000000
25% 370.000000
50% 676.000000
75% 1133.000000
max 41861.000000
Name: text, dtype: float64
df_train['text_len'] = df_train['text'].apply(lambda x: len(x))
_ = plt.hist(df_train['text_len'], bins=200)k#下划线表示 临时变量
plt.xlabel('Text char count')
plt.title("Histogram of char count")
Text(0.5, 1.0, 'Histogram of char count')

df_train['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")
Text(0.5, 0, 'category')
#total词频统计
%%time
vocab = dict()
for text in df_test['text']:
for word in text:
if vocab.get(word):
vocab[word] += 1
else:
vocab[word] = 1
Wall time: 25.8 s
len(vocab)
6203
chars = sorted(vocab.items(), key=lambda x: x[0])
chars[:10]
[(0, 7),
(2, 182),
(3, 233),
(4, 103),
(5, 282),
(6, 183),
(7, 13),
(8, 962),
(10, 11),
(13, 3532)]
homework1
1.假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成?
#错误示例
Path=r"C:/Users/10539/Desktop/nlp/"
df_train = pd.read_csv(Path+'train_set.csv', sep='\t')
df_train['sentence_num']=df_train['text'].apply(lambda x:len(x.split('3750'or'900'or'648')))
原因是split函数只支持按一种方式分割(x.split[‘a’,n]n指定分割次数),而re.split可以按多种方式分割
返回list,具体操作
df_train
| label | text | sentence_num | sentence_num2 | |
|---|---|---|---|---|
| 0 | 2 | 2967 6758 339 2021 1854 3731 4109 3792 4149 15... | 65 | 121 |
| 1 | 11 | 4464 486 6352 5619 2465 4802 1452 3137 5778 54... | 26 | 51 |
| 2 | 3 | 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... | 28 | 56 |
| 3 | 2 | 7159 948 4866 2109 5520 2490 211 3956 5520 549... | 87 | 158 |
| 4 | 3 | 3646 3055 3055 2490 4659 6065 3370 5814 2465 5... | 12 | 29 |
| ... | ... | ... | ... | ... |
| 199995 | 2 | 307 4894 7539 4853 5330 648 6038 4409 3764 603... | 42 | 101 |
| 199996 | 2 | 3792 2983 355 1070 4464 5050 6298 3782 3130 68... | 68 | 122 |
| 199997 | 11 | 6811 1580 7539 1252 1899 5139 1386 3870 4124 1... | 52 | 130 |
| 199998 | 2 | 6405 3203 6644 983 794 1913 1678 5736 1397 191... | 8 | 15 |
| 199999 | 3 | 4350 3878 3268 1699 6909 5505 2376 2465 6088 2... | 85 | 215 |
200000 rows × 4 columns
np.mean(df_train['sentence_num'].values)
38.41112
#正确示例
##有大佬在上面text 转成list之后直接用re
import re
df_train['sentence_num2']=df_train['text'].apply(lambda x:len(re.split('3750|900|648',x)))
2.统计每类新闻中出现次数对多的字符
#以label为1为例
df_train['text'] = df_train['text'].apply(lambda x: list(map(lambda y: int(y), x.split())))
d_train=df_train.groupby('label')
d_train
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000193E6C29348>
train_1=d_train.get_group(1)
words=train_1['text'].values
words=words.flatten()
words=list(words)
maxlable=max(words,key=words.count)
maxlable#根据出现次数对words进行排序
[2538,2506,1363,5466,...]














 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









