







初识Kafka(一)
[睡着的水-hzjs-2016.08.25]
一、Kafka的使用背景
1、在我们大量的使用分布式数据库、分布式计算集群的时候,是否会遇到这样的一些问题呢?
# 我想分析用户行为,以便我能设计出更好的广告位
# 我想对用户搜素的关键词进行统计,分析出当前的流行趋势
# 有些数据,存数据库有些浪费,直接存硬盘操作效率又低
-----这些数据都有一个共同的特征,由上一个模块产生,使用上一个模块的数据进行计算处理统计和分析,这个时候就适合使用消息系统,尤其是分布式消息系统;而Kafka就是这样的一个分布式的消息系统。
Kafka 的定义:
-----是一个分布式的消息系统,有Linkedln 使用Scala 编写,用作Linkedln 的活动流(Activity Strean)和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量。
应用领域:已经被多家不同类型的公司作为多种类型的数据管道和消息系统使用。如:淘宝,支付宝,V爱都,twitter等;
目前越来越多的开源分布式吃力系统如Apache flume 、Apache Storm 、Spark 、elasticsearch(全文检索) 都支持Kafka 集成;
目前的主要的消息分布式队列对比:
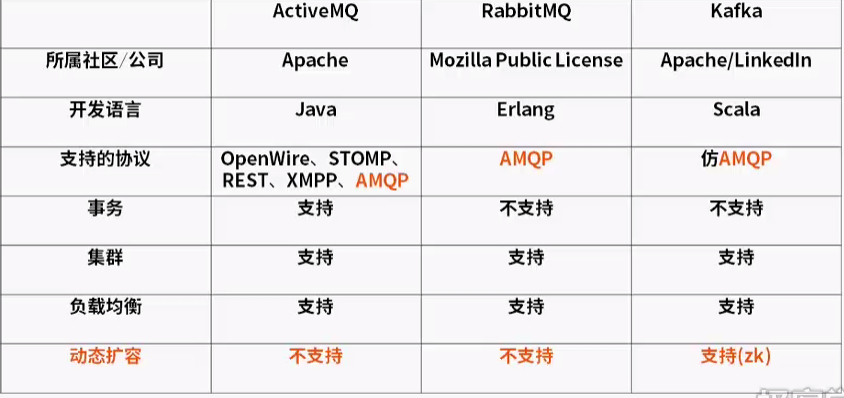
Erlang :语言级别就支持高并发的服务器开发语言,也就使得RabbitMQ具有很高的性能;但是总体上Kafka 的性能还是优于RabbitMQ的;
事务的概念:多个操作同时成功,或者同时失败!
二、Kafka 的相关的概念
1、AMQP协议:

一些基本的概念:
- Consumer(消费者):从消息队列中请求消息的客户端应用程序;
- Producer(生产者):向broker 发布消息的客户端应用程序;
- broker(AMQP服务器端):用来接受生产者发送的消息并将这些消息路由给服务器重的消息队列;
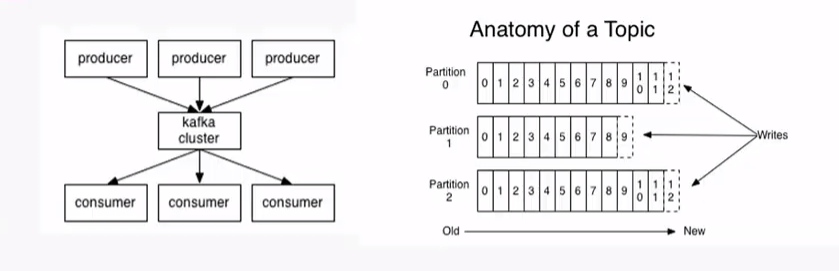
- 主题(Topic): 一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题;
- 分区(Partition): 一个topic 中的消息数据安照多个分区组织,分区是Kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO 的队列;
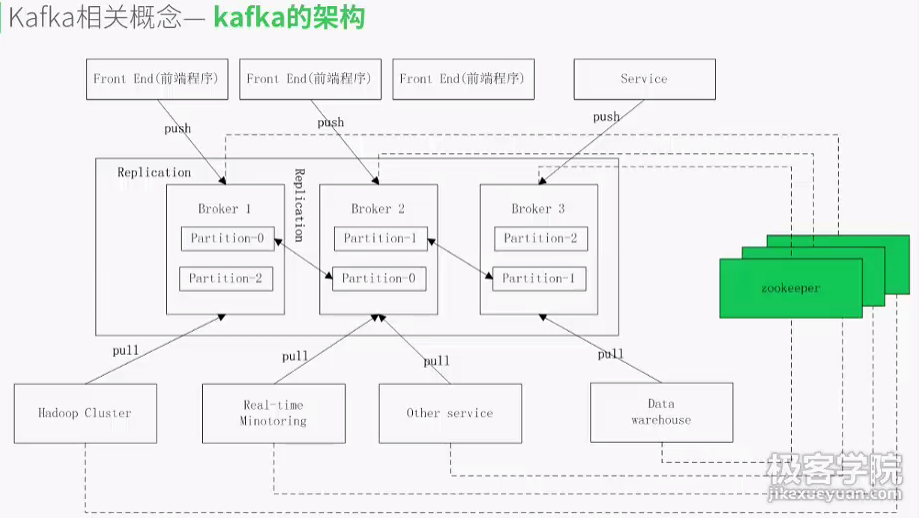
#备份(Replication):为了保证分布式可靠性,kafka0.8开始对每个分区的数据进行备份(不同的Broker上),防止其中一个Broker宕机造成分区数据不可用
#zookeeper:一个提供了分布式状态管理、分布式配置管理、分布式锁服务等的集群。
三、Zookeeper 集群的搭建(因为kafka的状态是保存在zookeeper中的)
-----1、集群搭建:
软件环境:
- Linux 服务器一台、三台、五台(2 * N + 1 台),奇数台;
- Java jdk 1.7
- zookeeper 3.4.6 版本(比较稳定的版本)
集群搭建(3台):
1) 首先搭建Java 的环境(每台机器都同样操作)
-----a、解压到指定的目录
-----b、配置path环境变量(一般写在path的前面)
2)搭建zookeeper集群
-----a、解压zk包到指定的目录(先要创建两个目录,一个是解压的目录,一个是日志的目录)
-----b、进入zk的conf 目录下,改变zoo_simple.cfg为zoo.cfg
dataDir=解压的目录
dataLogDir=事务日志的目录(第二个目录),如果不配置会跟上面在共一个目录中,吞吐量大的时候会影响zk的性能
clientPort= (端口,尽量大一点防止被占用)
#zk之间怎么感知彼此 (1 是本台机器,2 第二台,3 是第三台)
server.1=本机IP : 端口(2888):选举的端口(官网默认3888)
server.2=第二台IP : 端口(2888):选举的端口(官网默认3888)
server.3=第三台IP : 端口(2888):选举的端口(官网默认3888)
!!!!保存退出
-----c 、然后将标识写到解压的目录下面,创建myid的文件,将对应标识写入其中
-----d 、将两个目录拷贝到其它的两台机器上,!!!!注意:修改myid 的对应的标识
-----e、启动zk: ./zkServer.sh 逐一启动三台机器 ; ./zkServer.sh status 查看状态(一个leader,其余两台是follower)
搭建完毕!
#Zookeeper集群搭建成功的标识,在任意一再机器上运行sh zkServer.sh status 出现下面两幅图中任意的输出结果,说明集群搭建成功:

-----2 、集群配置参数讲解
#重要的配置参数:
- myid 文件 和 server.myid :myid 是在快照目录下唯一标识本机器的文件,也是在集群中发现彼此的重要文件。
- zoo.cfg : zk 的配置文件
- log4j.properties : zk 集群的日志配置文件
- zkEnv.sh 和 zkServer.sh 文件 :启动时的环境配置文件 与 启动停止文件
#要定期的清理zk的事务日志,防止占满内存,影响程序的性能(写成脚本cleanup.sh)
crontab -l :查看定时任务
cromtan -e : 编辑定时任务 0 0 * * 0 sh /home/test/zookeeper/zk/cleanup.sh (每月的周末凌晨)定时执行清理任务
三、kafka 集群的搭建
1、集群搭建
-----#软件的环境
- Linux 服务器一台或者多台
- 已经搭建好的zk集群
- kafka_2.9.2-0.8.1.1
- 创建kafka 的(安装目录) kafka 与 kafkaLogs(主要存放kafka 的消息)
- 将kafka 解压到创建的目录中
- 进入kafka的配置文件config
- vim server.properties
bin/kafka-topics.sh --create --zookeeper localhost:2181(自己的)
--replication-factor 1(备份)
--partitions 1(分区数) --topic test(名字)
查看一下是否正确:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test输出:
Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
启动producer程序:
bin/kafka-console-producer.sh --broker-list 本地的ip:9092 --topic test(之前创建的名字)(会有警告,暂时不要管他)
然后再另一台机器上启动一个consumer程序,执行前先查看一下命令是否正确:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
启动:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test
在prodecer 这端发送一条消息 : hello
在consumer 这一段会发现收到一条消息 hello ,说明两台机器组成了集群!
我们可以使用list命令查看有哪些topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181详细请参照kafka官网:点击打开链接 里面第step3-step5我们可以使用describe命令查看具体的topic:bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
http://kafka.apache.org/documentation.html#introduction
强调:
- kafka的默认日志是保存在kafka的根目录下的logs文件下。
- server.log 是运行日志,state-change.log切换日志。
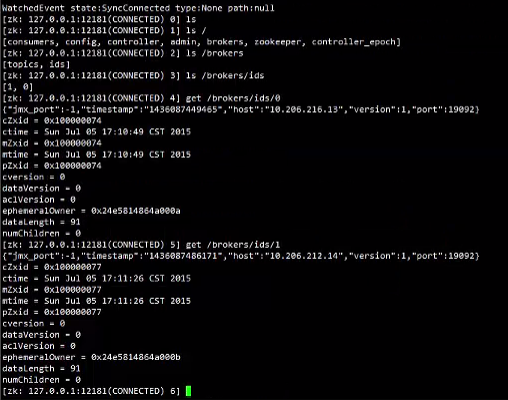
进入zookeeper 客户端查看:./zkCli.sh -server 127.0.0.1:12281(zk端口)
使用 ls / 命令 :

除了zookeeper目录别的都是kafka 的,查看具体: ls /brokers/ids get/brokers/ids/0
2、集群配置参数的介绍(重要的参数)
socket.send.buffer.bytes : 向kafka发送消息的时候,不要一点点就发送出去,我们是先保存在缓冲区,当到达一定数量的时候,再一起发送出去
socket.receive.buffer.bytes: kafka 接受消息的缓冲区。将接过来的消息放入缓冲区,当缓冲区到达一定的数量的时候,再将它序列化到磁盘
socket.request.max.bytes : 向kafka 发送或者请求的最大数,不能超过java 的堆栈的大小
num.partitions :默认的分区数,默认一个topic 是两个分区数
log.retention.hours :发送给kafka 的消息不能无限的写在磁盘上,必须要有一个失效期,默认是七天
log.segment.bytes : 每个消息都追加在一个文件中,如果文件超过了这个大小,就另起一个文件
log.retenttion.check.interval.ns :每隔一段时间检查一下目录是否是持久化的目录,看一下目录下是否有失效消息,如果有的话就执行删除失效的消息
log.cleaner.enable :是否启用log压缩,默认false很少的应用场景,但是能提高效率
zookeeper.connection.timeout.ns :kafka 连接zk 集群的时间
配置文件:
server.properties(已讲解)
consumer.properties
- zookeeper.connection : zk的ip与端口,不需要改动
producer.properties
- metadata.broker.list=本机地址:端口 不需改动
- producer.type = sync 同步的方式
- comoression.codec: 消息是否使用压缩手段,默认是使用(kafka 中两种压缩)
- serializer.class 默认的序列化类 使用自己的















 8951
8951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









