







浅谈Master的HA
[睡着的水-hzjs-2016.08.25]
一、Kafka消费者编程模型
1、分区消费模型:一对一的关系
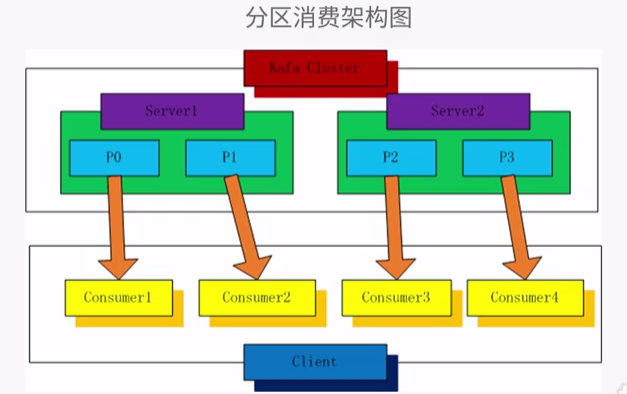
#分区消费模型伪代码描述:

2、组(Group)消费模型
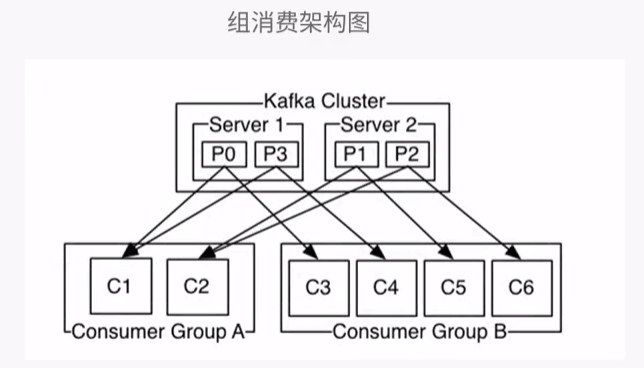
#伪代码描述:

Consumer分配算法:

----1 中T 代表着所有的分区 Ci 代表分组下的所有的实例
----4 对topic 下面的所有的分区进行排序,比如 P0 ,P1,P2, P3
----5 然后再排序客户端consumer实例 C1 C2
----6 然后用partition 的数量除以 Consumer的数量 即 前面的 4 除以 2, 得到一个 n = 2
----7 按照第七步里面这个算法分配,例如上面,我们可以算出P0 ,P3会给C1 ,。。。
----8.9 把这种分配关系写入到集群对应的目录之中
3、两种消费模型对比
#分区消费模型更加的灵活,但是:
- 需要自己处理各种异常
- 需要自己管理offset(以实现消息传递的其它语义)
- 不需要自己处理异常情况,不需要自己管理offset
- 只能实现kafka默认的最少一次消息传递语义
二、Kafka消费者的Python和Java客户端实现
1、Python客户端实例讲解
-----#需要的软件环境
a、已搭建好的kafka集群、Linux服务器一台、Python2.7.6、Kafka-Python软件包
到github 下载kafka-pythion 软件包
解压(要不要解压呢?)到指定的目录中;在该目录下运行命令:python setup.py install 如果你的服务器能够上网,那么你能够直接安装完成,如果不能上网的话,我们还需要另一个包 six-sfsfsf(版本),对字节进行编码的一种包,这个包我们可以去网上自己下载,可以到pypi.python.org 中去下载。上传到服务器,,进入工程 python setup.py install 就可以安装
-----#分区消费者模型Python实现
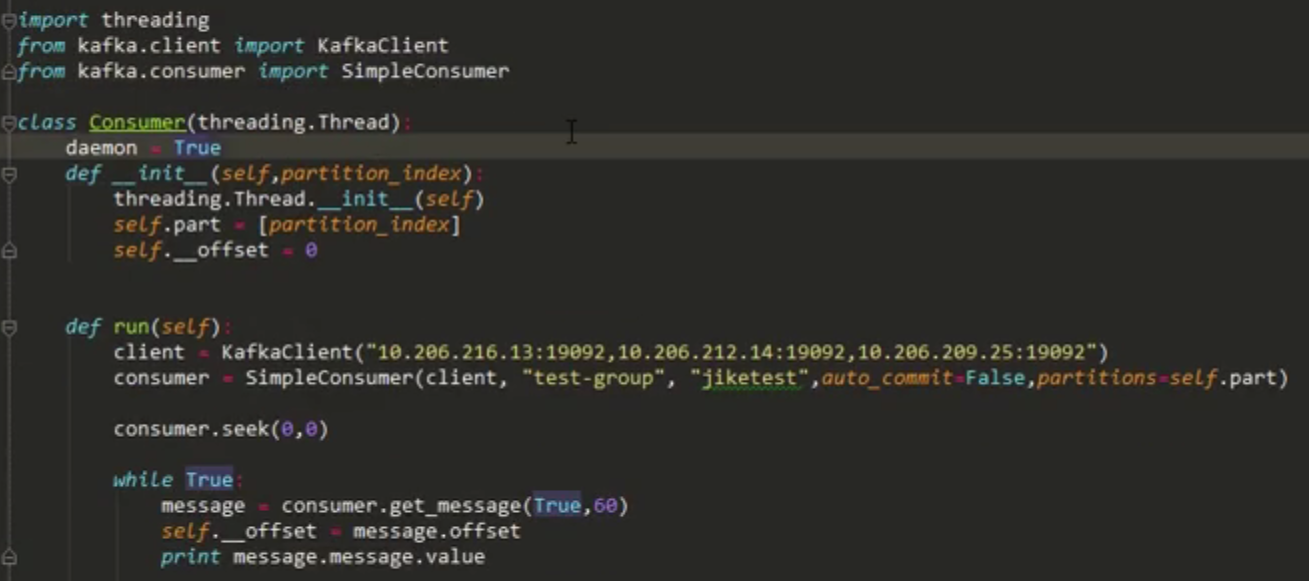
!!!!!详细请看上面伪代码实例的解析;
#分区主程序main代码如下:
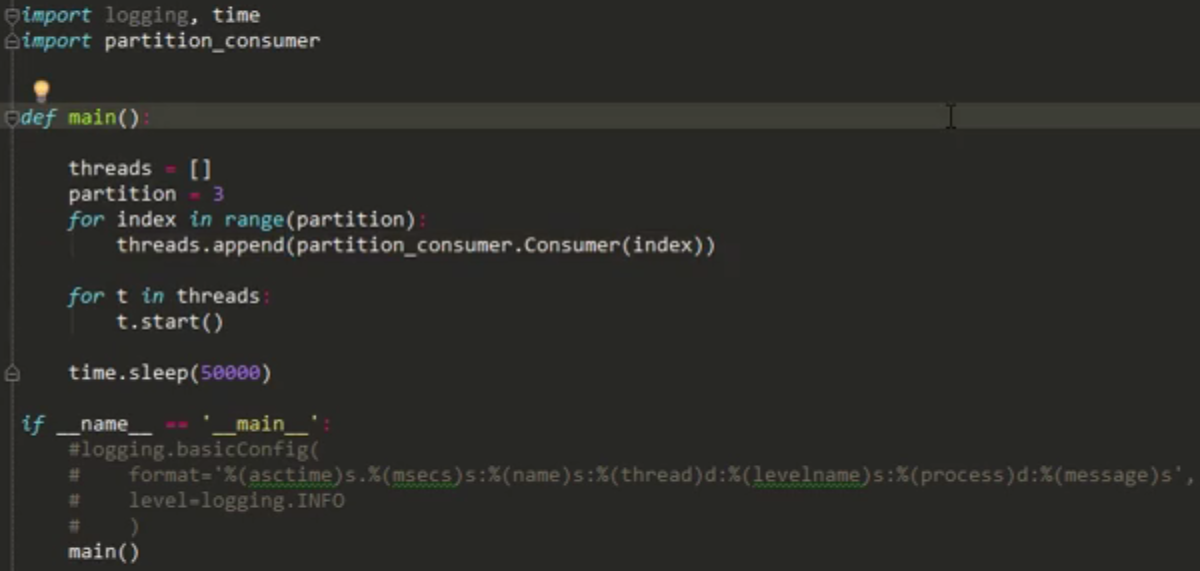
-----#Group消费模型的Python实现
group_consumer.py的代码如下:
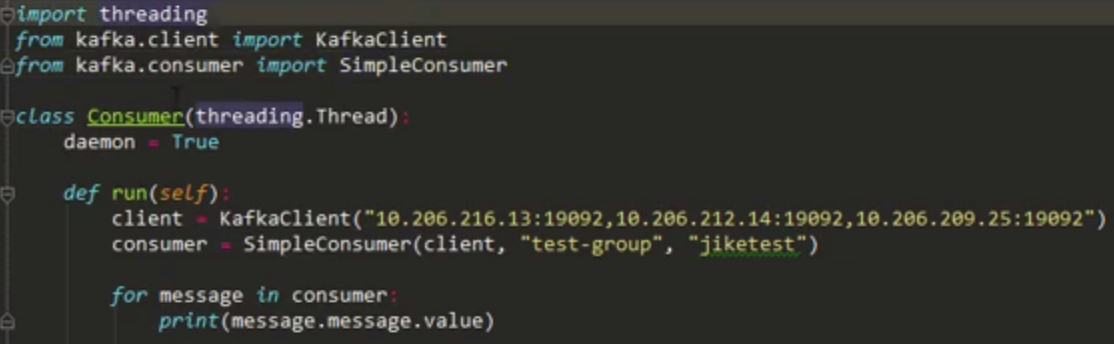
首先定义了一个类Consumer,这个类继承了线程类,所以说他是一个线程,可以用启动线程的方式来启动它;定义daemon是为了让在在主线程退出的时候,从线程自动退出。在run方法中首先建立一个连接,这里配置了集群的host与post,
然后我们创建了一个SimpleConsumer,指定消费者参数。
分组消费者主程序main的代码 :

2、Python客户端参数调优
- fetch_size_bytes : 每次从服务器获取单个包是多大;
- buffer_size : kafka客户端缓冲区的大小 ,从kafka 获取消息,一次能最多获取多大的数据返回给我们,和fetch_size_bytes的区别在于一个buffer_size是由多个fetch_size_bytes组成,因为kafka 客户端需要多个TCP的来回来获取所有的数据,填充到buffer_size里。然后整个buffer_size 回传给我们。带宽低的情况下,我们要设置的大一些,而不是每次返回的数据都很小(跨国)。
- Group :分组消费时分组名
- auto_commit : offset是否自动提交,手动提交可以实现kafka其它语义
3、java 客户端实例讲解
-----#需要的软件环境:
已搭建好的kafka集群、Linux服务器一台,Apache Maven 3.2.3 、kafka0.8.1
-----#分组消费者模型:
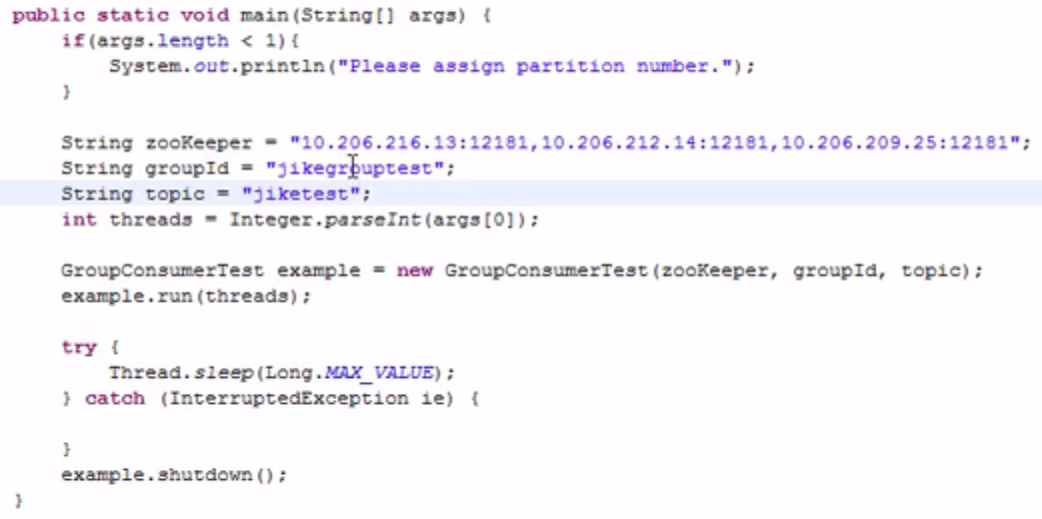
a、main 的代码如下:
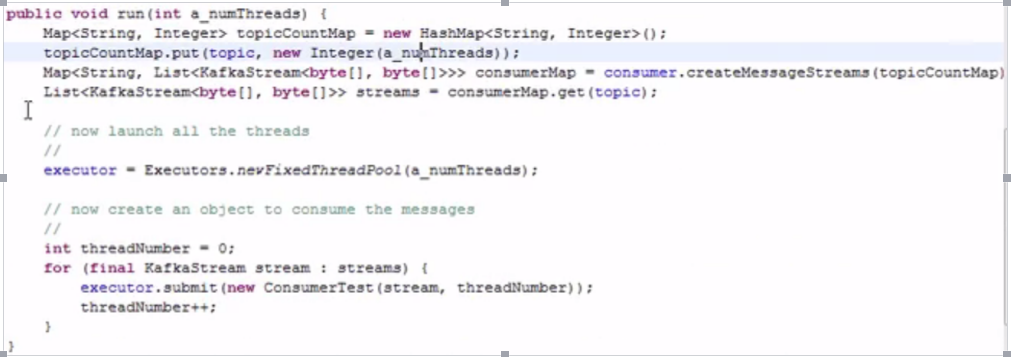
主体类代码:使用消费者的参数构建我们的consumer
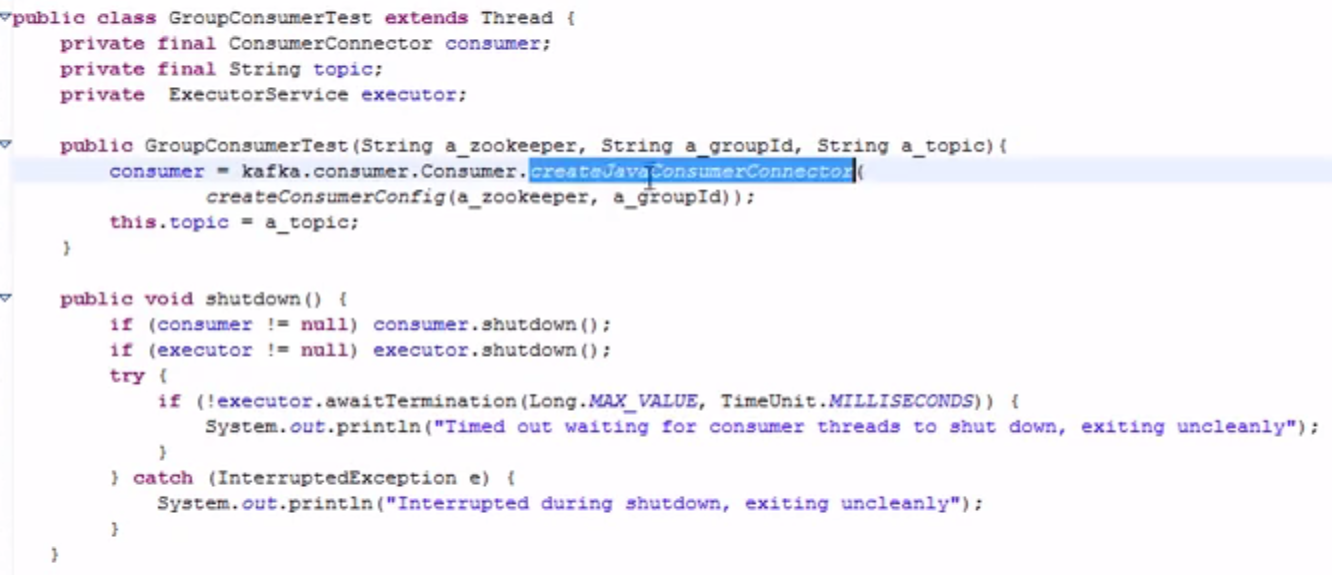
主要是获得了一些流,然后提交流:提交的时候用到了Consumer的客户端实例:
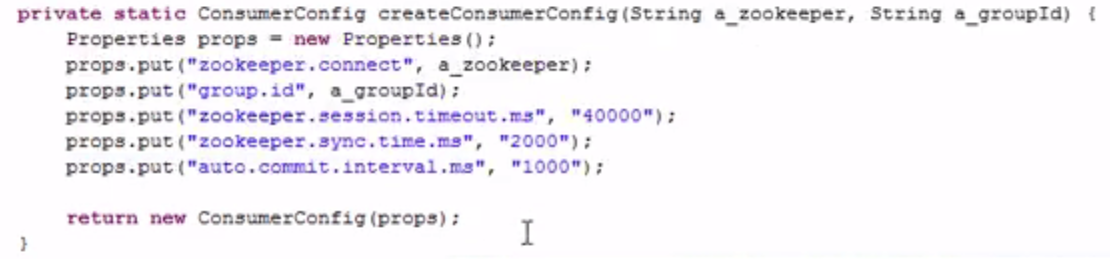
kafka 消费者的一些参数:
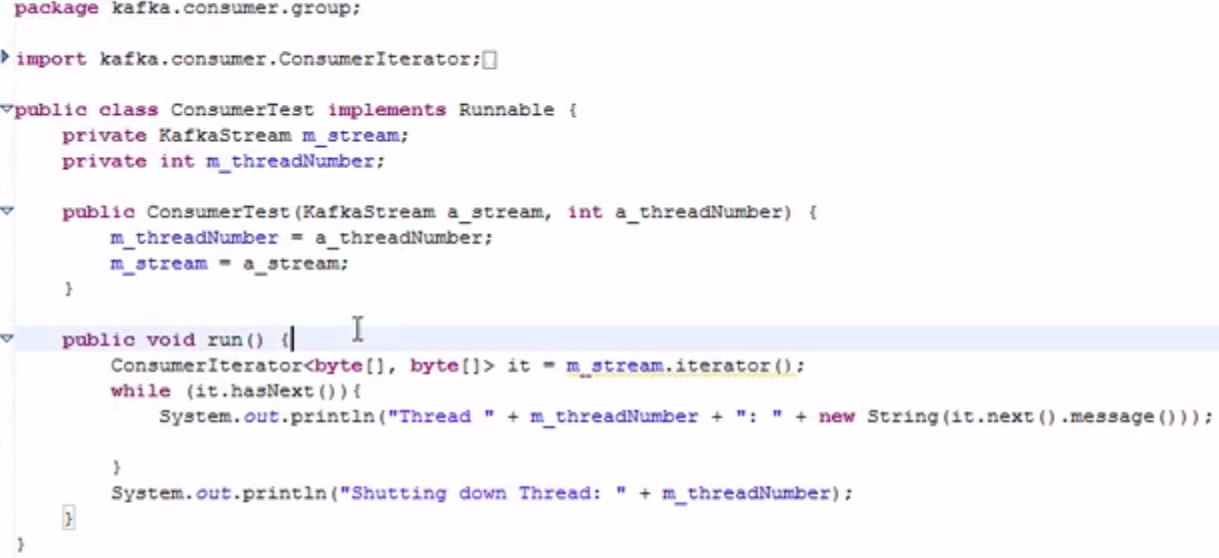
consumer客户端的代码:遍历流的所有消息,将消息取出
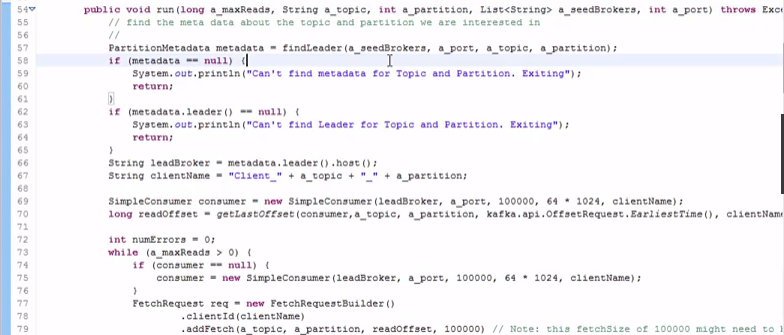
-----#分区消费模型的代码
先指定host,post,然后运行一些线程获取每个分区的数据:


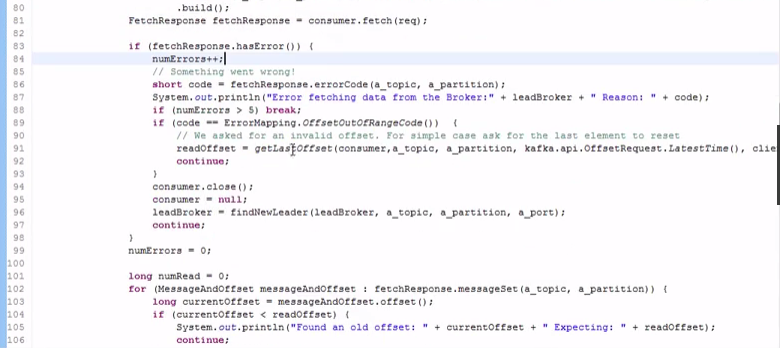
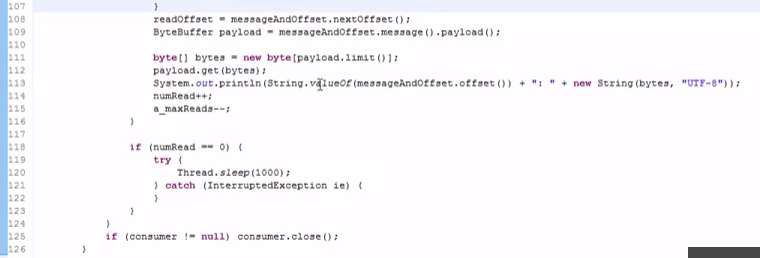
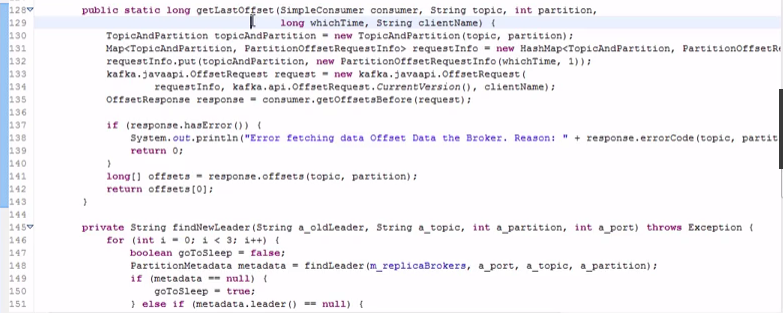
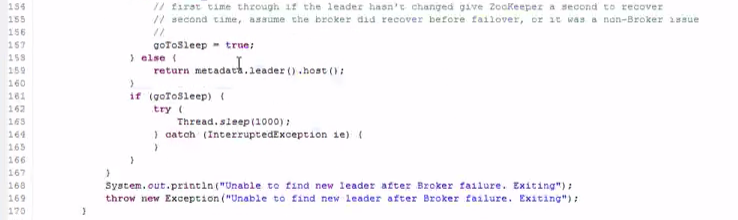
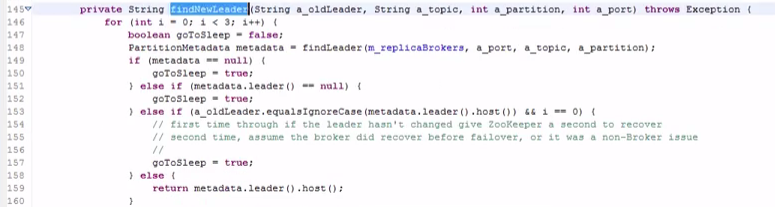
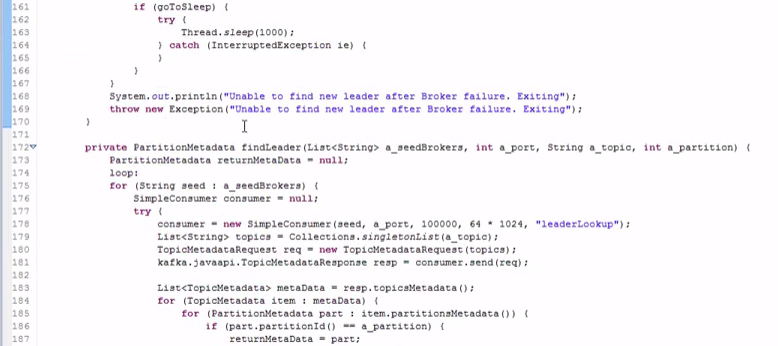
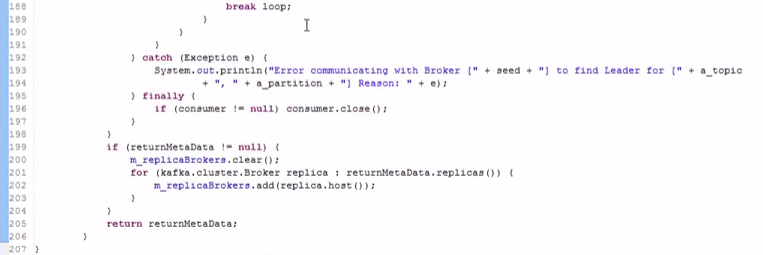
#java比较灵活,性能要高一些,但是代码量太大
4、java客户端参数调优
- fetchSize:每次从服务器获取单个包是多大
- bufferSize: 跟python 时候是一样的
- group.id : 分组消费时分组名,指定不同的group.id 可以实现复制消费的目的,名字不一样但是每个名字都可以取得全量的数据;
三、Kafka生产者编程模型(请看 Kafka消费者生产者编程模型(二))
四、Kafka生产者的Python和Java客户端实现(请看Kafka消费者生产者编程模型(二))















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









