







zset对象的ziplist和skiplist转换
redis 存储转换如下:
执行zadd命令时会执行如下的函数(t_zset.c):
/* Add a new element or update the score of an existing element in a sorted
* set, regardless of its encoding.
*
* The set of flags change the command behavior. They are passed with an integer
* pointer since the function will clear the flags and populate them with
* other flags to indicate different conditions.
*
* The input flags are the following:
*
* ZADD_INCR: Increment the current element score by 'score' instead of updating
* the current element score. If the element does not exist, we
* assume 0 as previous score.
* ZADD_NX: Perform the operation only if the element does not exist.
* ZADD_XX: Perform the operation only if the element already exist.
*
* When ZADD_INCR is used, the new score of the element is stored in
* '*newscore' if 'newscore' is not NULL.
*
* The returned flags are the following:
*
* ZADD_NAN: The resulting score is not a number.
* ZADD_ADDED: The element was added (not present before the call).
* ZADD_UPDATED: The element score was updated.
* ZADD_NOP: No operation was performed because of NX or XX.
*
* Return value:
*
* The function returns 1 on success, and sets the appropriate flags
* ADDED or UPDATED to signal what happened during the operation (note that
* none could be set if we re-added an element using the same score it used
* to have, or in the case a zero increment is used).
*
* The function returns 0 on error, currently only when the increment
* produces a NAN condition, or when the 'score' value is NAN since the
* start.
*
* The command as a side effect of adding a new element may convert the sorted
* set internal encoding from ziplist to hashtable+skiplist.
*
* Memory management of 'ele':
*
* The function does not take ownership of the 'ele' SDS string, but copies
* it if needed. */
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
/* Turn options into simple to check vars. */
int incr = (*flags & ZADD_INCR) != 0;
int nx = (*flags & ZADD_NX) != 0;
int xx = (*flags & ZADD_XX) != 0;
*flags = 0; /* We'll return our response flags. */
double curscore;
/* NaN as input is an error regardless of all the other parameters. */
if (isnan(score)) {
*flags = ZADD_NAN;
return 0;
}
/* Update the sorted set according to its encoding. */
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *eptr;
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
/* NX? Return, same element already exists. */
if (nx) {
*flags |= ZADD_NOP;
return 1;
}
/* Prepare the score for the increment if needed. */
if (incr) {
score += curscore;
if (isnan(score)) {
*flags |= ZADD_NAN;
return 0;
}
if (newscore) *newscore = score;
}
/* Remove and re-insert when score changed. */
if (score != curscore) {
zobj->ptr = zzlDelete(zobj->ptr,eptr);
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
*flags |= ZADD_UPDATED;
}
return 1;
} else if (!xx) {
/* check if the element is too large or the list
* becomes too long *before* executing zzlInsert. */
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries ||
sdslen(ele) > server.zset_max_ziplist_value ||
!ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*flags |= ZADD_ADDED;
return 1;
}
} else {
*flags |= ZADD_NOP;
return 1;
}
}
/* Note that the above block handling ziplist would have either returned or
* converted the key to skiplist. */
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
de = dictFind(zs->dict,ele);
if (de != NULL) {
/* NX? Return, same element already exists. */
if (nx) {
*flags |= ZADD_NOP;
return 1;
}
curscore = *(double*)dictGetVal(de);
/* Prepare the score for the increment if needed. */
if (incr) {
score += curscore;
if (isnan(score)) {
*flags |= ZADD_NAN;
return 0;
}
if (newscore) *newscore = score;
}
/* Remove and re-insert when score changes. */
if (score != curscore) {
znode = zslUpdateScore(zs->zsl,curscore,ele,score);
/* Note that we did not removed the original element from
* the hash table representing the sorted set, so we just
* update the score. */
dictGetVal(de) = &znode->score; /* Update score ptr. */
*flags |= ZADD_UPDATED;
}
return 1;
} else if (!xx) {
ele = sdsdup(ele);
znode = zslInsert(zs->zsl,score,ele);
serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
*flags |= ZADD_ADDED;
if (newscore) *newscore = score;
return 1;
} else {
*flags |= ZADD_NOP;
return 1;
}
} else {
serverPanic("Unknown sorted set encoding");
}
return 0; /* Never reached. */
}
/*-----------------------------------------------------------------------------
* Sorted set commands
*----------------------------------------------------------------------------*/
/* This generic command implements both ZADD and ZINCRBY. */
void zaddGenericCommand(client *c, int flags) {
static char *nanerr = "resulting score is not a number (NaN)";
robj *key = c->argv[1];
robj *zobj;
sds ele;
double score = 0, *scores = NULL;
int j, elements;
int scoreidx = 0;
/* The following vars are used in order to track what the command actually
* did during the execution, to reply to the client and to trigger the
* notification of keyspace change. */
int added = 0; /* Number of new elements added. */
int updated = 0; /* Number of elements with updated score. */
int processed = 0; /* Number of elements processed, may remain zero with
options like XX. */
/* Parse options. At the end 'scoreidx' is set to the argument position
* of the score of the first score-element pair. */
scoreidx = 2;
while(scoreidx < c->argc) {
char *opt = c->argv[scoreidx]->ptr;
if (!strcasecmp(opt,"nx")) flags |= ZADD_NX;
else if (!strcasecmp(opt,"xx")) flags |= ZADD_XX;
else if (!strcasecmp(opt,"ch")) flags |= ZADD_CH;
else if (!strcasecmp(opt,"incr")) flags |= ZADD_INCR;
else break;
scoreidx++;
}
/* Turn options into simple to check vars. */
int incr = (flags & ZADD_INCR) != 0;
int nx = (flags & ZADD_NX) != 0;
int xx = (flags & ZADD_XX) != 0;
int ch = (flags & ZADD_CH) != 0;
/* After the options, we expect to have an even number of args, since
* we expect any number of score-element pairs. */
elements = c->argc-scoreidx;
if (elements % 2 || !elements) {
addReply(c,shared.syntaxerr);
return;
}
elements /= 2; /* Now this holds the number of score-element pairs. */
/* Check for incompatible options. */
if (nx && xx) {
addReplyError(c,
"XX and NX options at the same time are not compatible");
return;
}
if (incr && elements > 1) {
addReplyError(c,
"INCR option supports a single increment-element pair");
return;
}
/* Start parsing all the scores, we need to emit any syntax error
* before executing additions to the sorted set, as the command should
* either execute fully or nothing at all. */
scores = zmalloc(sizeof(double)*elements);
for (j = 0; j < elements; j++) {
if (getDoubleFromObjectOrReply(c,c->argv[scoreidx+j*2],&scores[j],NULL)
!= C_OK) goto cleanup;
}
/* Lookup the key and create the sorted set if does not exist. */
zobj = lookupKeyWrite(c->db,key);
if (zobj == NULL) {
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
} else {
if (zobj->type != OBJ_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
for (j = 0; j < elements; j++) {
double newscore;
score = scores[j];
int retflags = flags;
ele = c->argv[scoreidx+1+j*2]->ptr;
int retval = zsetAdd(zobj, score, ele, &retflags, &newscore);
if (retval == 0) {
addReplyError(c,nanerr);
goto cleanup;
}
if (retflags & ZADD_ADDED) added++;
if (retflags & ZADD_UPDATED) updated++;
if (!(retflags & ZADD_NOP)) processed++;
score = newscore;
}
server.dirty += (added+updated);
reply_to_client:
if (incr) { /* ZINCRBY or INCR option. */
if (processed)
addReplyDouble(c,score);
else
addReplyNull(c);
} else { /* ZADD. */
addReplyLongLong(c,ch ? added+updated : added);
}
cleanup:
zfree(scores);
if (added || updated) {
signalModifiedKey(c,c->db,key);
notifyKeyspaceEvent(NOTIFY_ZSET,
incr ? "zincr" : "zadd", key, c->db->id);
}
}
void zaddCommand(client *c) {
zaddGenericCommand(c,ZADD_NONE);
}
lookupKeyWrite(c->db,key)检查key是否存在。
createZsetObject()是创建跳表;createZsetZiplistObject()是创建ziplist。
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST)转换存储类型。
创建调表的条件由zset_max_ziplist_entries和zset_max_ziplist_value两个参数决定。调试时可以在redis.conf文件中修改这两个参数。
# Similarly to hashes and lists, sorted sets are also specially encoded in
# order to save a lot of space. This encoding is only used when the length and
# elements of a sorted set are below the following limits:
zset-max-ziplist-entries 2
zset-max-ziplist-value 64
跳表的实现
跳表(多层级有序链表)结构用来实现有序集合。
鉴于 redis 需要实现 zrange 以及 zrevrange 功能;需要节点间最好能直接相连并且增删改操作后结构依然有序。
B+ 树时间复杂度为
h
×
O
(
log
2
n
)
h \times O(\log_2 n)
h×O(log2n),但 B+ 数有复杂的节点分裂操作;有序数组通过二分查找能获得
O
(
log
2
n
)
O(\log_2 n)
O(log2n) 时间复杂度;平衡二叉树也能获得
O
(
log
2
n
)
O(\log_2 n)
O(log2n) 时间复杂度。
理想跳表
每隔一个节点生成一个层级节点;模拟二叉树结构,以此达到搜索时间复杂度为
O
(
log
2
n
)
O(\log_2 n)
O(log2n);通过空间换时间的结构。
但是如果对理想跳表结构进行删除增加操作,很有可能改变跳表结构;如果重构理想结构,将是巨大的运算。
考虑用概率的方法来进行优化:
从每一个节点出发,每增加一个节点都有
1
2
\frac{1}{2}
21 的概率增加一个层级,
1
4
\frac{1}{4}
41 的概率增加两个层级, 的概率增加
3 个层级,以此类推。
经过证明,当数据量足够大(256)时,通过概率构造的跳表趋向于理想跳表,并且此时如果删除节点,无需重构跳表结构,此时依然趋向于理想跳表。此时时间复杂度为:
(
1
−
1
n
c
)
×
O
(
log
2
n
)
,
c
是常数
(1-\frac{1}{n^c})\times O(\log_2 n) \space\space\space\space\space\space\space\space\space\space\space,\space c是常数
(1−nc1)×O(log2n) , c是常数
redis 跳表
从节约内存出发,redis 考虑牺牲一点时间复杂度让跳表结构更加变扁平,就像二叉堆改成四叉堆结构;并且 redis 还限制了跳
表的最高层级为 32。
节点数量大于 128 或者有一个字符串长度大于 64,则使用跳表(skiplist)。
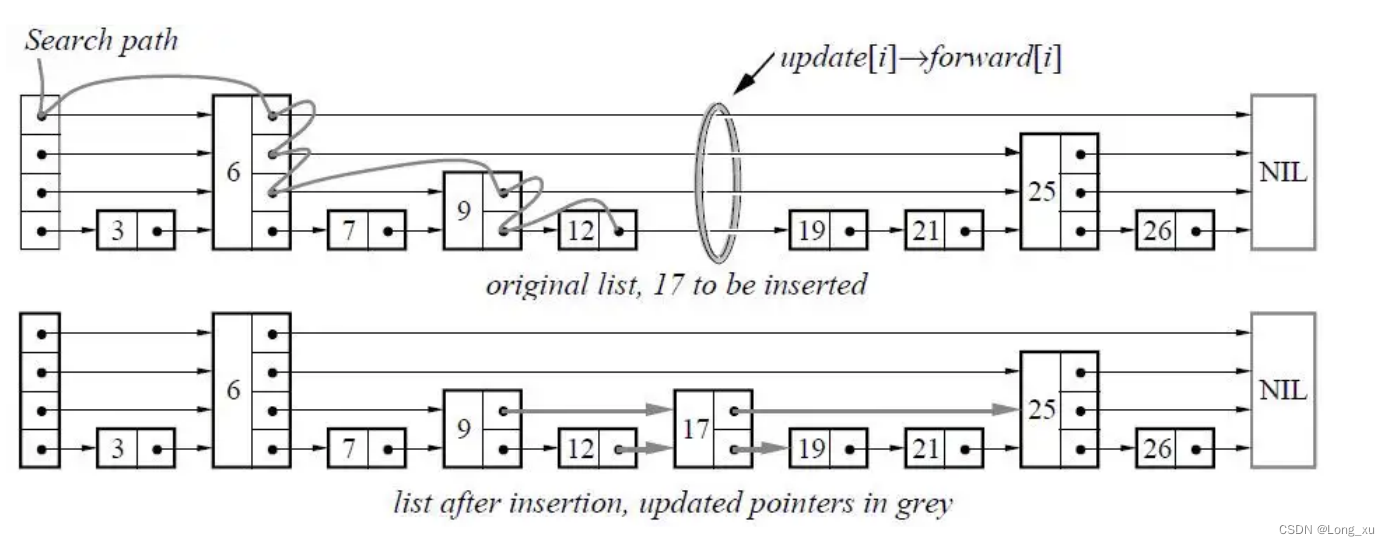
数据结构
server.h
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;// 用于zrank
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
-
层级通过柔性数组来组织。
-
zset为了优化,加了dict,帮助快速索引到节点,因为dict的查询时间复杂度是 O ( 1 ) O(1) O(1)。特别是删除和修改操作时,可以通过dict快速查找节点是否存在;如果存在,就可以找到该节点的左右两个节点以及有多少个层级,以达到以 O ( 1 ) O(1) O(1)的时间复杂度进行删除或修改操作。
-
zset的添加节点操作的时间复杂度是 O ( log 2 n ) O(\log_2 n) O(log2n)。
-
zset的修改操作是先删除节点再添加节点。
-
redis的跳表数据结构做了调整,它是一个循环双向链表的结构;这样的结构可以实现逆向查询。
结构图
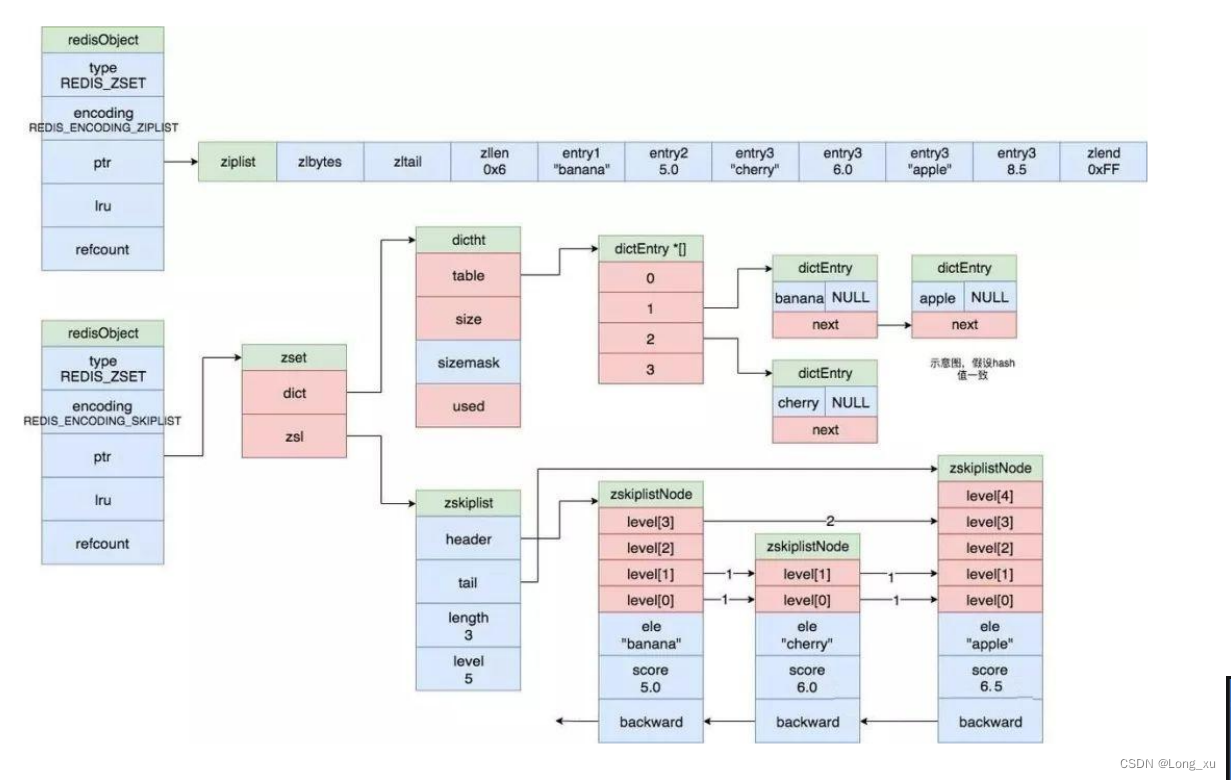
要实现 O ( log 2 n ) O(\log_2 n) O(log2n)的时间复杂度,有很多方式,redis使用调表的原因是调表中的所有元素都在第一个层级(即level 0),如果要进行范围查询,只需要找到两个边界,(因为调表是有序的)第一层往下遍历就行了,这是其他数据结构时间复杂度不能达到的高效范围查询。
总结
- 有序数据查询数据的时间复杂度是 O ( log 2 n ) O(\log_2 n) O(log2n),有序链表查询数据的时间复杂度是 O ( n ) O(n) O(n)。
- 调表是多层级有序链表,可以二分查找数据,它的最底层包含所有的元素。
- 调表的范围查询非常方便,通过 O ( log 2 n ) O(\log_2 n) O(log2n)的时间复杂度快速找到边界,然后在最底层找到范围内所有元素。
- 调表的增删改查时间复杂度都是 O ( log 2 n ) O(\log_2 n) O(log2n)。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











