







C++内存分区和变量存储
引言
💡 作者简介:专注分享高性能服务器后台开发技术知识,涵盖多个领域,包括C/C++、Linux、网络协议、设计模式、中间件、云原生、数据库、分布式架构等。目标是通过理论与代码实践的结合,让世界上看似难以掌握的技术变得易于理解与掌握。公众号《Lion 莱恩呀》。
👉
🎖️ CSDN实力新星、专家博主,阿里云博客专家、华为云云享专家
👉
🔔 专栏介绍:从零到c++精通的学习之路。内容包括C++基础编程、中级编程、高级编程;掌握各个知识点。
👉
🔔 专栏地址:C++从零开始到精通
👉
🔔 博客主页:https://blog.csdn.net/Long_xu
🔔 上一篇:【015】C++ 编程的核心技能:函数,你真的了解它吗?
🔔 下一篇:【017】C++ 指针变量详解,理解指针变量
一、内存分区
可执行文件从运行到结束的整个动态过程称为进程。
内存分区是操作系统为了管理内存空间,将内存划分为不同的区域,每个区域都有特定的用途和访问权限。
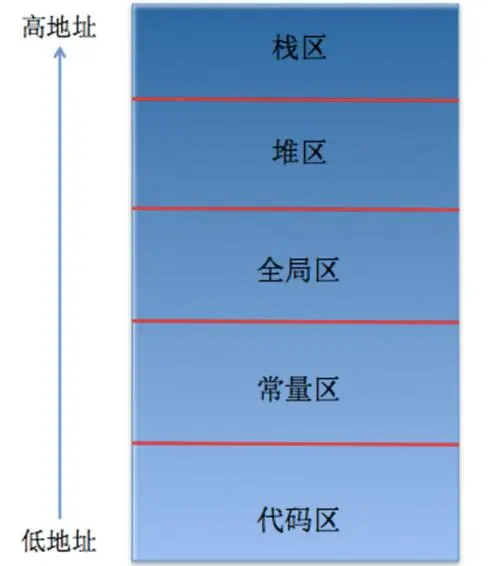
(1)栈区 (Stack)
- 特点: 可读可写,遵循“先进后出”的原则,由系统自动管理。
- 用途: 存储函数调用过程中产生的局部变量、函数形参、返回值等数据。
- 示例:
int sum(int a, int b) { // 函数形参 a 和 b 存储在栈区 int result = a + b; // 局部变量 result 存储在栈区 return result; // 返回值 result 存储在栈区 }
(2)堆区 (Heap)
- 特点: 可读可写,由程序员手动管理,需要使用
malloc、calloc、realloc等函数进行动态内存分配。 - 用途: 存储程序运行过程中动态申请的内存空间,例如数组、结构体等。
- 示例:
int *ptr = (int *)malloc(sizeof(int) * 10); // 在堆区分配 10 个整数大小的内存空间 if (ptr == NULL) { std::cout << "内存分配失败!" << std::endl; return 1; } for (int i = 0; i < 10; i++) { ptr[i] = i * 10; } free(ptr); // 释放堆区内存
(3)全局区 (Global)
- 特点: 可读可写,在程序运行期间一直存在。
- 用途: 存储全局变量、静态全局变量、静态局部变量等数据。
- 示例:
int globalVar = 10; // 全局变量存储在全局区 static int staticVar = 20; // 静态全局变量存储在全局区
(4)常量区 (Constant)
- 特点: 只读,在程序运行期间一直存在。
- 用途: 存储常量数据,例如数值常量、字符常量、字符串常量、符号常量等。
- 示例:
const int num = 100; // 数值常量存储在常量区 const char *str = "Hello, world!"; // 字符串常量存储在常量区
(5)代码区 (Code)
- 特点: 只读,存储程序的二进制指令。
- 用途: 程序执行时,CPU 从代码区读取指令并执行。
理解内存分区对于编写高效、安全的 C++ 代码至关重要,它有助于更好地管理内存资源,避免内存泄漏、栈溢出等问题。
- 栈区和堆区是程序运行过程中动态分配内存的主要区域,但管理方式不同。
- 全局区和常量区存储的是程序运行期间一直存在的静态数据。
- 代码区存储的是程序的二进制指令,是程序执行的核心区域。
二、变量的存储
2.1、普通局部变量
定义:在{} 里面定义的普通变量就是普通局部变量。
int main()
{
int num=0;//局部变量
{
int num2=0;//局部变量
}
return 0;
}
作用范围:所在的{}复合语句之间有效。
生命周期:所在的{}复合语句之间有效。
存储区域:栈区。
注意事项:
- 普通局部变量不初始化,内容是不确定的。
- 普通局部变量同名情况下,采用就近原则。
int main()
{
int num=0;//局部变量
{
int num=10;//局部变量
cout<<"num = "<<num<<endl;
}
cout<<"num = "<<num<<endl;
return 0;
}
输出:
10
0
2.2、普通全局变量
定义:在函数外定义的普通变量就是普通全局变量。
int num;
int main()
{
cout<<num<<endl;
return 0;
}
作用范围:当前源文件以及其他源文件有效。
生命周期:整个进程。
存储区域:全局区。
注意事项:
-
普通全局变量不初始化,内容是0。
-
普通局部变量和普通全局变量同名情况下,优先选择局部变量。
int num; int main() { int num=10; cout<<num<<endl; cout<<::num<<endl;// C++支持通过作用域方式访问全局变量,c语言不支持 return 0; }输出:
0 10 -
其他源文件使用全局变量必须对全局变量进行
extern声明。extern声明外部可用,该变量或函数来自其他源文件。// main.cpp int num; int main() { int num=10; cout<<num<<endl; cout<<::num<<endl;// C++支持通过作用域方式访问全局变量,c语言不支持 return 0; }// test.cpp extern int num; int test() { cout<<num<<endl; return 0; }
2.3、静态局部变量
定义:在{} 里面用static定义的普通变量就是静态局部变量。
void test()
{
static int data = 10;
}
作用范围:所在的{}复合语句之间有效。
生命周期:整个进程有效。
存储区域:全局区。
注意事项:
- 静态局部变量不初始化时,内容默认为0。
- 静态局部变量整个进程都存在,第一次定义有效。
#include <iostream>
using namespace std;
void test()
{
int data=10;
static int data=10;
data2++;
cout<<"data: "<<data<<endl;
cout<<"data2: "<<data2<<endl;
}
int main()
{
test();
test();
test();
test();
test();
return 0;
}
输出:
data: 10
data2: 11
data: 10
data2: 12
data: 10
data2: 13
data: 10
data2: 14
data: 10
data2: 15
2.4、静态全局变量
定义:在函数外定义的使用static修饰的变量就是静态全局变量。
static int num;
int main()
{
cout<<num<<endl;
return 0;
}
作用范围:只能在当前源文件使用,不能在其他源文件使用。
生命周期:整个进程。
存储区域:全局区。
注意事项:
- 静态全局变量不初始化,内容为0。
- 静态全局变量只能在当前源文件使用。
三、全局函数和静态函数
3.1、全局函数
函数默认都是全局函数。全局函数在当前源文件以及其他源文件都可以使用。如果其他源文件使用需要extern对全局函数进行声明。
// main.cpp
int num;
extern test();//全局函数的声明
int main()
{
int num=10;
cout<<num<<endl;
cout<<::num<<endl;// C++支持通过作用域方式访问全局变量,c语言不支持
test();
return 0;
}
// test.cpp
extern int num;
int test()
{
cout<<num<<endl;
return 0;
}
3.2、静态函数(static修饰的函数)
静态函数只能在当前源文件使用。
// main.cpp
int num;
static int test();//函数的声明
int main()
{
int num=10;
cout<<num<<endl;
cout<<::num<<endl;// C++支持通过作用域方式访问全局变量,c语言不支持
test();
return 0;
}
static int test()
{
cout<<num<<endl;
return 0;
}
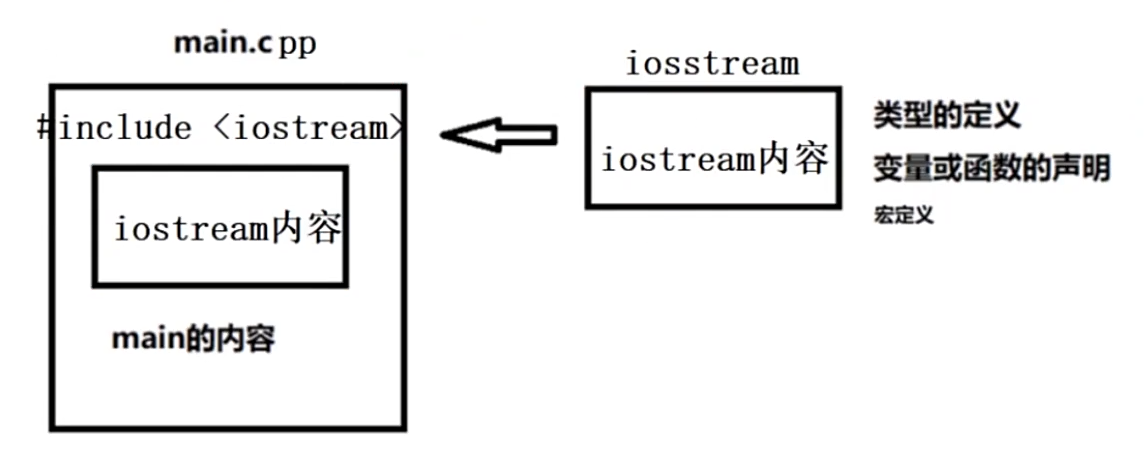
四、头文件包含
在预处理结果将头文件的内容原封不动的包含在目的文件中。
<>从系统指定目录寻找头文件。""先从当前目录寻找头文件,如果找不到,再从系统指定目录寻找头文件。
五、#define宏
编译的四个阶段:预处理、编译、汇编、链接。
使用关键字define定义的称为宏。
#define PI 3.1415926 //宏定义
在预处理时,使用3.1415926替换PI出现的位置,称为宏展开。
注意:
- 不要在宏后面添加分号。
- 宏尽量大写,和变量区分开。
5.1、不带参数的宏
#define PI 3.1415926 //宏定义
#define STRING "hello cpp"
#define INT32 32
宏的作用范围:从定义处开始到当前文件结束有效。#undef可以结束宏的作用域。
#define PI 3.1415926 //宏定义
// ....
#undef PI //结束宏的作用域
// ...
宏没有作用域的限制,只在当前源文件有效。
5.2、带参数的宏
#define MUL(a,b) a*b
cout<<MUL(10,20)<<endl;
// 宏展开后:cout<<10*20<<endl;
(1)宏的参数不能有类型。
(2)宏不能保证参数的完整性。
#define MUL(a,b) a*b
cout<<MUL(10+10,20)<<endl;
// 宏展开后:cout<<10+10*20<<endl;
可以使用()的形式让带参数的宏具备完整性。
#define MUL(a,b) (a)*(b)
cout<<MUL(10+10,20)<<endl;
// 宏展开后:cout<<(10+10)*20<<endl;
(3)宏不能作为结构体、类的成员。
5.3、宏函数和普通函数的区别
- 定义方式不同:宏定义是通过
#define关键字定义的,而普通函数则需要先声明再实现。 - 编译时机不同:宏函数是在编译时展开的,而普通函数则是在运行时执行的。
- 参数传递方式不同:宏函数可以接受任意类型的参数,并且不需要进行类型检查。相比之下,普通函数对于每个参数都需要进行类型检查。
- 返回值处理方式不同:宏函数不能像普通函数一样返回结果。相反,它会直接替换为预处理器指令。
- 带参数宏调用多少次就展开多少次,执行代码的时候没有函数调用的过程,不需要压栈出栈。所以带参数宏是浪费空间来节省时间。
- 带参数函数,代码只有一份,存储在代码段,调用的时候去代码段取指令,调用的时候要压栈出栈,属于浪费时间来节省空间。
- 函数有作用域限制,可以作为类的成员。而宏是没有作用域限制的,不能作为类的成员。
六、总结
C++预处理器是一个非常重要的编译阶段,它在源代码被编译之前对源代码进行一些操作。以下是一些常见的C++预处理指令和其作用:
#define:定义宏常量或宏函数,可以提高代码的可读性和可维护性。#ifdef 、 #ifndef 、 #endif:条件编译指令,用于根据条件选择是否编译某段代码。#include:包含头文件,将其他源代码文件中的定义导入到当前文件中以供使用。#pragma:通用预处理命令,用于指示编译器执行特定的动作或更改默认行为。#error:产生错误消息并停止编译过程。#undef:取消已定义的宏。
除了上述常见预处理指令外,C++还有一些其他的预处理功能,例如__FILE__、__LINE__等预定义标识符。这些标识符可以在程序运行时提供有关程序状态和调试信息。


















 1337
1337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











