






前言
VQ-VAE [1]是一种经典的向量量化方法,可以对图片进行稀疏化,本文基于 [3]的实现方法进行分析解释。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇
\nabla
∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

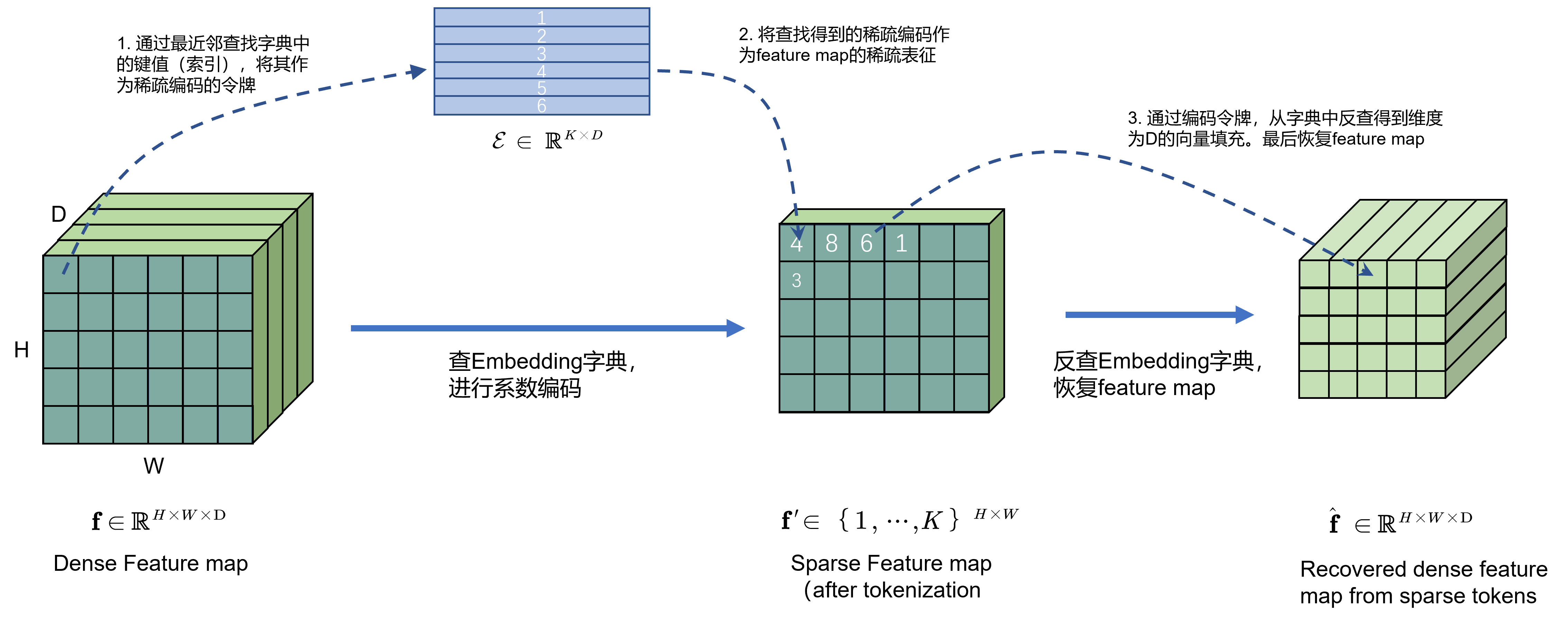
笔者在前文 [2] 中曾经介绍过VQ-VAE模型,如Fig 1.所示,该模型基于最近邻查找的方式从字典
E
∈
R
K
×
D
\mathcal{E} \in \mathbb{R}^{K \times D}
E∈RK×D中查找其索引,作为其稀疏化后的令牌,具体细节可见博文[2]。
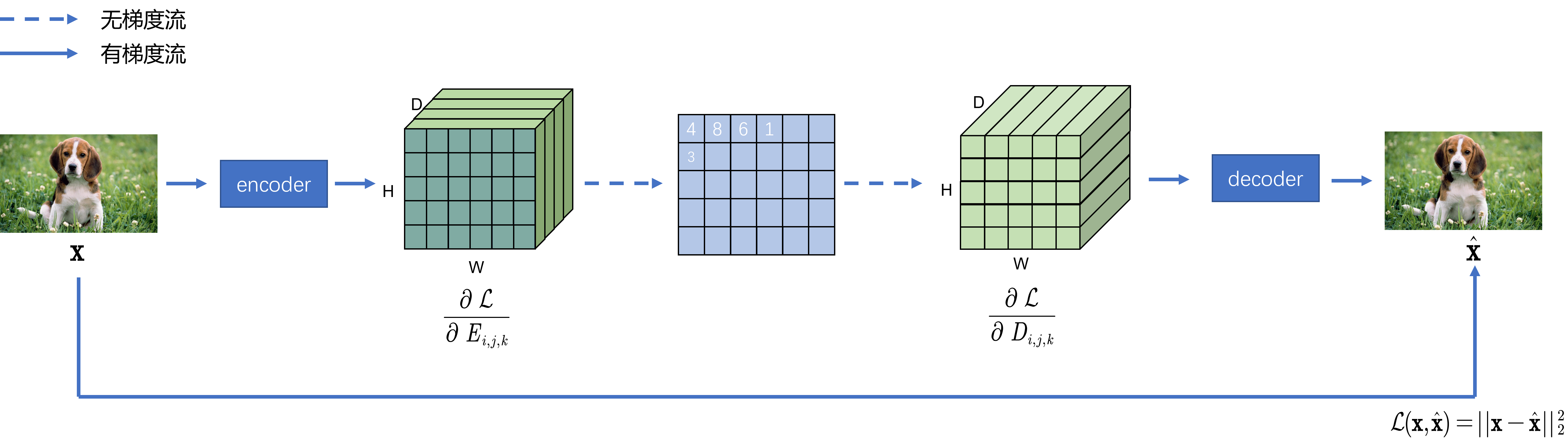
整个框架中有若干参数需要学习,分别是encoder,decoder网络参数和Embedding space字典的参数。然而稀疏编码的过程由于出现了最近邻方法,这个过程显然是无法传递梯度的,为了实现编码器的更新,可以考虑将解码器的梯度直接拷贝到编码器中。假设对于编码后恢复的 z q ( x ) z_q(x) zq(x)而言,其每个元素表示为 D i , j , k D_{i,j,k} Di,j,k,那么对于其中某个元素的梯度表示为 ∂ L ∂ D i , j , k \dfrac{\partial \mathcal{L}}{\partial D_{i,j,k}} ∂Di,j,k∂L,同理,对于编码后的 z e ( x ) z_e(x) ze(x)而言,同样有 ∂ L ∂ E i , j , k \dfrac{\partial \mathcal{L}}{\partial E_{i,j,k}} ∂Ei,j,k∂L,令 ∂ L ∂ E i , j , k = ∂ L ∂ D i , j , k \dfrac{\partial \mathcal{L}}{\partial E_{i,j,k}} = \dfrac{\partial \mathcal{L}}{\partial D_{i,j,k}} ∂Ei,j,k∂L=∂Di,j,k∂L。
那么对于编码器的梯度就可以表示为
∂
L
∂
W
E
=
∂
E
i
,
j
,
k
∂
W
E
∂
L
∂
E
i
,
j
,
k
\dfrac{\partial \mathcal{L}}{\partial W_E} = \dfrac{\partial E_{i,j,k}}{\partial W_E} \dfrac{\partial \mathcal{L}}{\partial E_{i,j,k}}
∂WE∂L=∂WE∂Ei,j,k∂Ei,j,k∂L。在详细分析代码实现逻辑之前,让我们回顾下其损失函数,如(1-1)所示,其中的
s
g
(
⋅
)
sg(\cdot)
sg(⋅)为停止梯度函数,表示该函数无梯度传导。decoder的参数通过第一项损失项进行更新(这部分损失可通过MSE损失
L
(
x
,
x
^
)
\mathcal{L}(\mathbf{x}, \hat{\mathbf{x}})
L(x,x^)建模),称之为重建损失。encoder参数通过第一项和第三项损失进行更新,其中第一项是重建损失,第三项是为了encoder编码产出和embedding space进行对齐而设计的,由于此时通过
s
g
(
⋅
)
sg(\cdot)
sg(⋅)函数停止了梯度,因此此时
E
\mathcal{E}
E的参数不会得到更新。Embedding space的参数通过第二项损失项进行更新,通过将encoder编码结果进行停止梯度,我们只对
E
\mathcal{E}
E进行参数更新。
L
=
log
(
p
(
x
∣
z
q
(
x
)
)
)
+
∣
∣
s
g
[
z
e
(
x
)
]
−
E
∣
∣
2
2
+
β
∣
∣
z
e
(
x
)
−
s
g
[
E
]
∣
∣
2
2
(1-1)
\mathcal{L} = \log(p(x|z_q(x))) + ||sg[z_e(x)]-\mathcal{E}||^2_2 + \beta ||z_e(x)-sg[\mathcal{E}]||^2_2 \tag{1-1}
L=log(p(x∣zq(x)))+∣∣sg[ze(x)]−E∣∣22+β∣∣ze(x)−sg[E]∣∣22(1-1)
那么在代码中如何实现这些逻辑呢?我们首先可以参考[3]项目中的实现。我们首先分析model.py文件中的forward函数,字典定义为一个nn.Embedding层(Code 1.1),其参数就是self.dict.weight,那么求最近邻的操作就如Code 1.2所示。Code 1.3将最近邻的索引结果(也即是稀疏化后的视觉令牌),在字典中进行查询,对feature map进行恢复。因此W_j的形状和Z是一致的。此时Code 1.4中对Z和W_j进行detach,这个detach的作用之前在博文[4]中阐述过,本文不进行累述,其主要作用可视为是停止了该节点开始的梯度传导,也即是用于实现公式(1-1)中的
s
g
[
z
e
(
x
)
]
sg[z_e(x)]
sg[ze(x)]和
s
g
[
E
]
sg[\mathcal{E}]
sg[E]。
def __init__(self,...):
...
self.dict = nn.Embedding(k_dim, z_dim) # Code 1.1
def forward(self, x):
h = self.encoder(x) # (?, z_dim*2, 1, 1)
sz = h.size()
# BCWH -> BWHC
org_h = h
h = h.permute(0,2,3,1)
h = h.contiguous()
Z = h.view(-1,self.z_dim)
W = self.dict.weight
# Code 1.2
def L2_dist(a,b):
return ((a - b) ** 2)
# Sample nearest embedding
j = L2_dist(Z[:,None],W[None,:]).sum(2).min(1)[1]
# Code 1.3
W_j = W[j]
# Code 1.4, Stop gradients
Z_sg = Z.detach()
W_j_sg = W_j.detach()
# BWHC -> BCWH
h = W_j.view(sz[0],sz[2],sz[3],sz[1])
h = h.permute(0,3,1,2)
# Code 1.5, gradient hook register
def hook(grad):
nonlocal org_h
self.saved_grad = grad
self.saved_h = org_h
return grad
h.register_hook(hook)
# Code 1.6, losses
return self.decoder(h), L2_dist(Z,W_j_sg).sum(1).mean(), L2_dist(Z_sg,W_j).sum(1).mean()
# Code 1.7, back propagation for encoder
def bwd(self):
self.saved_h.backward(self.saved_grad)
此时有一个比较有意思的函数调用,如Code 1.5所示,此处的h.register_hook(hook_fn)表示对张量h注册了个回调钩子函数 hook_fn,我们先看下这个函数具体作用是什么,从官网的API信息[5]中可以知道,当每次对这个张量进行梯度计算的时候,都会调用这个回调函数hook_fn。hook_fn的输入是该张量的原始梯度grad_orig,hook_fn会对梯度进行变换得到grad_new = hook_fn(grad_orig),并且将grad_orig更新为grad_new。这个功能可以让我们实现将decoder的梯度赋值到encoder中,我们且看是如何实现的。我们留意到其对h,也即是W_j的结果进行了注册回调,我们也知道W_j和Z的形状是一致的,此时我们希望
∂
L
∂
Z
=
∂
L
∂
W
j
\dfrac{\partial L}{\partial Z} = \dfrac{\partial L}{\partial W_j}
∂Z∂L=∂Wj∂L,因此我们需要以某种方式缓存下Z和W_j的梯度,在梯度反向传播的时候,将W_j的梯度赋值到Z的梯度上,这也就是回调hook的目的——缓存下此时W_j的梯度和原始的Z节点。 在Code 1.6就开始构建decoder的输出以及
∣
∣
s
g
[
z
e
(
x
)
]
−
E
∣
∣
2
2
||sg[z_e(x)]-\mathcal{E}||^2_2
∣∣sg[ze(x)]−E∣∣22和
∣
∣
z
e
(
x
)
−
s
g
[
E
]
∣
∣
2
2
||z_e(x)-sg[\mathcal{E}]||^2_2
∣∣ze(x)−sg[E]∣∣22这两个loss了,那么何时我们对其encoder的梯度进行赋值呢?我们继续看到solver.py文件~
def hook(grad):
nonlocal org_h
self.saved_grad = grad
self.saved_h = org_h
return grad
在solver.py中,最主要的逻辑如下所示,其中的self.G(x)即是Code 1所示的forward()逻辑,对于其输出的解码器输出out,构建重建损失,对重建损失loss_rec和其他俩对齐损失loss_e1和loss_e2进行加和后得到loss,对loss进行梯度计算(注意此时需要将retain_graph设置为True,以保留叶子节点的梯度,具体作用见博文[6])。注意到此时由于最近邻查表的引入,loss.backward(retain_graph=True)只对decoder进行了梯度计算,此时为了对encoder也进行梯度计算,还需要进行self.G.bwd(),这个也正是我们刚才提到的,将W_j的梯度赋值到Z的梯度上,我们且看看如何实现的。如Code 1.7所示,self.G.bwd()的逻辑很简单,对缓存的Z进行梯度『赋值』为缓存下来的W_j梯度,但是准确的说,此处并不是对Z的梯度赋值,而是制定了计算Z梯度的前继梯度为self.saved_grad(梯度计算是链式法则,这意味着梯度计算势必有前继和后续),我们在附录里面会举个例子说明tensor.backward()和tensor.register_hook()的作用。总而言之,通过调用self.G.bwd()我们可以对encoder的梯度也进行计算了,最后调用optimizer.step()进行参数更新即可了。
def bwd(self):
self.saved_h.backward(self.saved_grad)
# ================== Train G ================== #
# Train with real images (VQ-VAE)
out, loss_e1, loss_e2 = self.G(x)
loss_rec = reconst_loss(out, x)
loss = loss_rec + loss_e1 + self.vq_beta * loss_e2
self.g_optimizer.zero_grad()
# For decoder
loss.backward(retain_graph=True)
# For encoder
self.G.bwd()
self.g_optimizer.step()
附录
A. tensor.backward()和tensor.register_hook()的作用
>>> v = torch.tensor([0., 0., 0.], requires_grad=True)
>>> h = v.register_hook(lambda grad: grad * 2) # 梯度翻倍
>>> v.backward(torch.tensor([1., 2., 3.])) # v的梯度前继为[1, 2, 3]
>>> v.grad # 因此输出的梯度为[2, 4, 6]
2
4
6
[torch.FloatTensor of size (3,)]
>>> h.remove() # removes the hook
Reference
[1]. Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017).
[2]. https://blog.csdn.net/LoseInVain/article/details/129224424, 【论文极速读】VQ-VAE:一种稀疏表征学习方法
[3]. https://github.com/nakosung/VQ-VAE
[4]. https://blog.csdn.net/LoseInVain/article/details/105461904, 在pytorch中停止梯度流的若干办法,避免不必要模块的参数更新
[5]. https://pytorch.org/docs/stable/generated/torch.Tensor.register_hook.html, TORCH.TENSOR.REGISTER_HOOK
[6]. https://blog.csdn.net/LoseInVain/article/details/99172594, 在pytorch中对非叶节点的变量计算梯度
















 74
74











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











