






一、距离度量
1.欧氏距离(Euclidean Distance):直观的距离度量方法,两个点在空间中的距离一般都是指欧氏距离。

2.曼哈顿距离(Manhattan Distance):也称为“城市街区距离”(City Block distance),曼哈顿城市特点:横平竖直。

3.切比雪夫距离(Chebyshev Distance):国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。

4.闵可夫斯基距离(MinkowskiDistance):闵氏距离
•不是一种新的距离的度量方式。
•是对多个距离度量公式的概括性的表述
•两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为
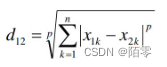
其中p是一个变参数:
当p=1时,就是曼哈顿距离;当p=2时,就是欧氏距离;当p→∞ 时,就是切比雪夫距离
根据p的不同,闵氏距离可表示某一类种的距离。
二、特征预处理
因特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响目标结果,使得一些模型无法学习到其它的特征,所以对模型进行归一化和标准化处理。
1.归一化:通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之间
数据归一化:通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之间
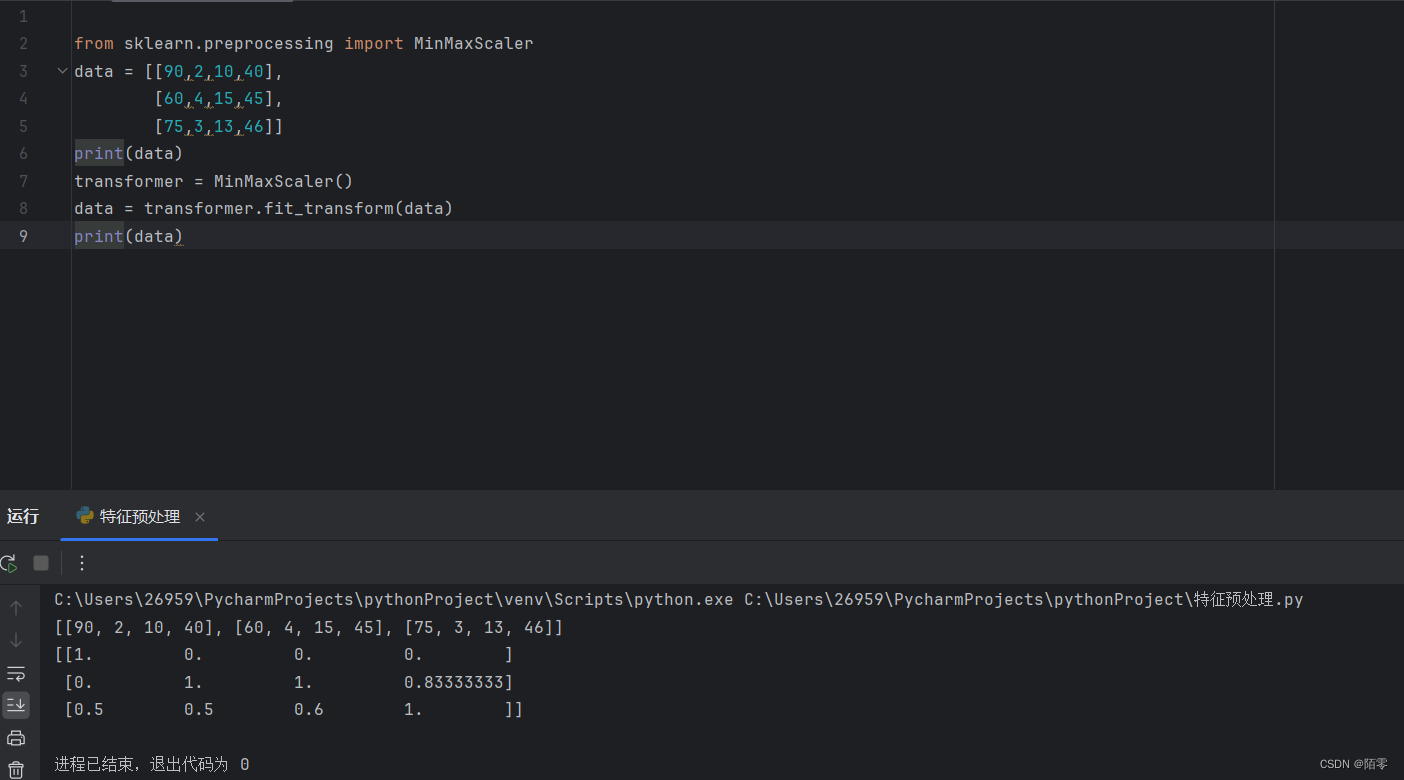 2.数据标准化:通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据
2.数据标准化:通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据

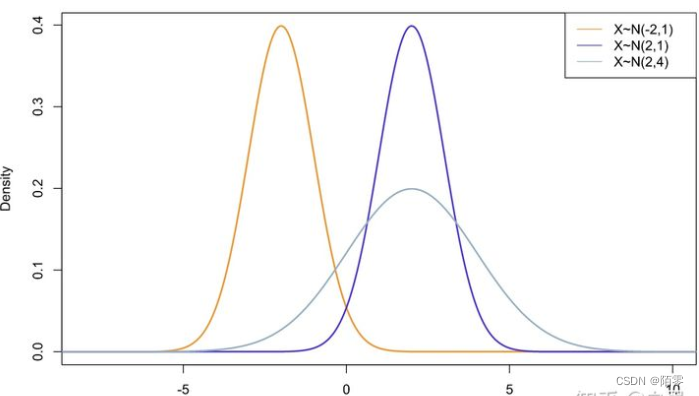
3.正态分布是一种概率分布,大自然很多数据符合正态分布则),也叫高斯分布,钟形分布。正态分布记作N(μ,σ ),μ决定了其位置,其标准差σ决定了分布的幅度,当μ = 0,σ = 1时的正态分布是标准正态分布。
4.方差是在概率论和统计方差衡量一组数据时离散程度的度量,其中M为均值,n为数据总数

5.标准差σ是方差开根号
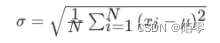
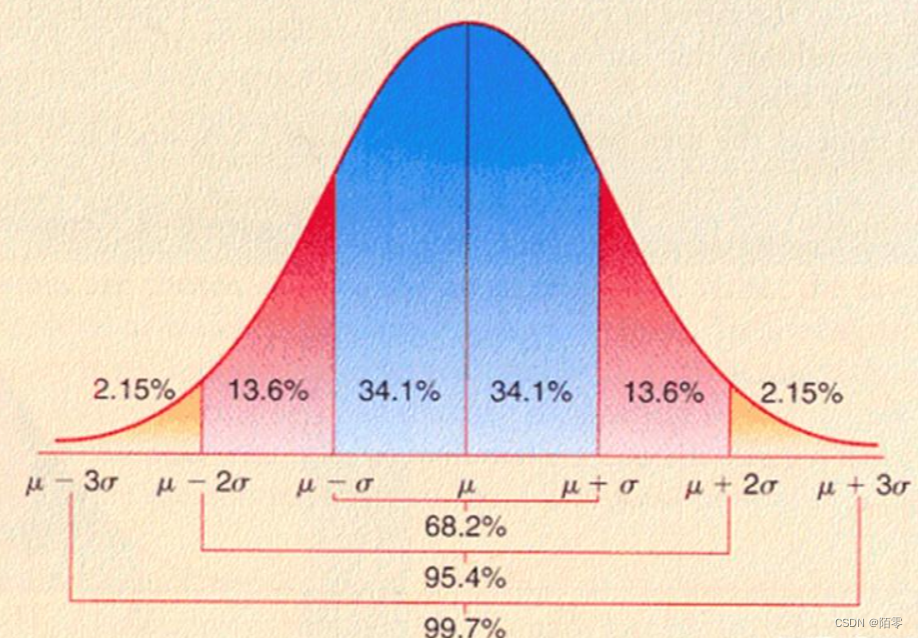
6.正态分布的3σ法则(68-95-99.7法则)
三、利用KNN算法对鸢尾花分类

在Python中,我们可以使用sklearn库中的datasets模块来轻松加载鸢尾花数据集。sklearn是一个强大的机器学习库,提供了大量的数据集和工具,方便我们进行机器学习和数据分析。
1.利用KNN算法对鸢尾花分类-加载鸢尾花数据集
from sklearn import dataset # 加载鸢尾花数据集
iris = datasets.load_iris() # 打印数据集描述
# print(iris.DESCR) # 可选
# 获取特征数据
X = iris.data # 获取目标标签
y = iris.target # 打印特征数据的前5行
print("特征数据前5行:\n", X[:5]) # 打印目标标签的前5个
print("目标标签前5个:\n", y[:5]) # 获取特征名称
feature_names = iris.feature_names
print("特征名称:\n", feature_names) # 获取目标标签的名称
target_names = iris.target_names
print("目标标签名称:\n", target_names)
输出:
特征数据前5行:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
目标标签前5个:
[0 0 0 0 0]
特征名称:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
目标标签名称:
['setosa' 'versicolor' 'virginica']
2.探索鸢尾花数据集
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
#显示鸢尾花数据
def dm02_showiris():
# 1载入鸢尾花数据集并显示特征名称.feature_names
mydataset= load_iris()
print(mydataset.feature_names)
# 2把数据转换成dataframe格式设置data, columns属性目标值名称
iris_d = pd.DataFrame(mydataset['data'], columns=mydataset.feature_names)
iris_d['Species'] = mydataset.target
print('\niris_d-->\n', iris_d)
col1 = 'sepal length (cm)'
col2 = 'petal width (cm)'
# 3 sns.lmplot()显示
sns.lmplot(x=col1, y=col2, data=iris_d, hue='Species', fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('iris')
plt.show()3.使用鸢尾花数据集进行模型训练
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn import datasets
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 打印数据集描述
# print(iris.DESCR) # 可选
# 获取特征数据
X = iris.data
# 获取目标标签
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
clf = svm.SVC(kernel='linear') # 线性核函数
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 打印分类报告
print(classification_report(y_test, y_pred, target_names=iris.target_names))
输出:
precision recall f1-score support
setosa 1.00 1.00 1.00 19
versicolor 1.00 1.00 1.00 13
virginica 1.00 1.00 1.00 13
accuracy 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45















 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









