






 本文详细介绍了特征工程的重要步骤,包括特征提取、预处理、降维、选择和组合,以及模型拟合中的欠拟合和过拟合概念。此外,重点讲解了KNN算法的工作原理、K值的选择和调优方法,以及在Python中实际应用示例。
本文详细介绍了特征工程的重要步骤,包括特征提取、预处理、降维、选择和组合,以及模型拟合中的欠拟合和过拟合概念。此外,重点讲解了KNN算法的工作原理、K值的选择和调优方法,以及在Python中实际应用示例。
一、特征工程
定义:利用专业的知识背景和技巧处理数据,让机器学习算法效果最好的过程。
内容:1.特征提取( 从原始数据中提取与任务相关的特征)
2.特征预处理(特征对模型产生影响)
3.特征降维(将原始数据的维度降低,会对原始数据产生影响)
4.特征选择(原始数据特征很多,与任务相关是其中一个特征集合子集,不会改变原数据)
5.特征组合(把多个特征合并成一个特征。一般利用乘法或加法来完成)
二、模型拟合
1.拟合:用来表示模型对样本点的拟合情况
2.欠拟合:模型在训练集上表现很差、在测试集表现也很差
3.过拟合:模型在训练集上表现很好、在测试集表现也很差

三、KNN算法
KNN算法:K-近邻算法(K Nearest Neighbor,简称KNN)。
KNN算法思想:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。
欧氏距离: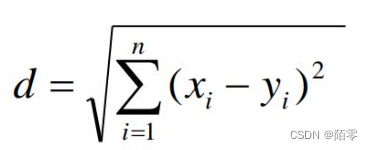
KNN算法解决问题:分类问题、回归问题
K值选择
K值过小:用较小邻域中的训练实例进行预测容易受到异常点的影响
K值的减小就意味着整体模型变得复杂,容易发生过拟合
K值过大:用较大邻域中的训练实例进行预测,受到样本均衡的问题
且K值的增大就意味着整体的模型变得简单,容易发生欠拟合
如何对K超参数进行调优?
交叉验证、网格搜索
KNN算法API使用-分类问题
from sklearn.neighbors import KNeighborsClassifier #导包
x = [[0], [1], [2], [3]] #数据处理
y = [0, 0, 1, 1]
modal = KNeighborsClassifier(n_neighbors=3) #实例化对象
modal.fit(x, y) #训练
mypre= modal.predict([[4]]) #预测
print(f'预测值:{mypre}')KNN算法API使用-回归问题
from sklearn.neighbors import KNeighborsRegressor #导包
modal = KNeighborsRegressor(n_neighbors=2) #实例化对象
x = [[0, 0, 1],[1, 1, 0],[3, 10, 10],[4, 11, 12]] #数据处理
y= [0.1,0.2,0.3,0.4]
modal.fit(x,y) #训练评估
mypre = modal.predict([[3,11,10]]) #预测
print(f'预测值:{mypre}') 














 1773
1773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









