







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
统计数据和表格拆分
一、测试中被处理的数据
二、统计数据
1.引入库
代码如下:
import xlrd
from xlutils.copy import copy
在这里,我们使用xlrd和xlutils两个模块来实现下面的操作
2.定义读取数据的函数
代码如下:
# 读取数据
def read_excel():
# 打开excel
wb = xlrd.open_workbook('./create_data/04_数据统计.xls')
# 获取工作簿
ws = wb.sheet_by_index(0)
# 建立两个变量存储数据
count_price = []
_type = {}
# 遍历数据集
for r in range(ws.nrows):
# 统计
count = ws.cell_value(r, 3) * ws.cell_value(r, 4)
# 每行统计的数据记录到列表中
count_price.append(count)
# 获取当前类的名称
key = ws.cell_value(r, 0)
# 判断产品是否已经在字典中存在
if _type.get(key):
# 将统计的数据记录到总的字典中
_type[key] += count
else:
_type[key] = count
return count_price, _type
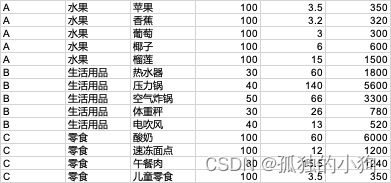
通过定义这个函数,对我们excel文件中的第一个工作簿中的所有数据进行遍历。第四列和第五列的乘积(模拟商品的单价和数量),得到count_price作为新的一列数据,但是在这里只是对数据进行读取,写入操作在下一步。按照第一列的属性值,对所有的数据进行分类,并且建立字典,获得每个分类中的第四列和第五列的乘积和(模拟分类商品的售价总和)。最终返回count_price代表每个商品的总销售额,_type一个字典,代表了每种分类的销售总额。
3. 定义保存数据的函数
# 保存数据
def save(count, fen):
# 打开excel
wb = xlrd.open_workbook('./create_data/04_数据统计.xls')
# 选取工作簿
ws = wb.sheet_by_index(0)
# 拷贝工作簿,用来修改
new_wb = copy(wb)
new_ws = new_wb.get_sheet(0)
# 将每行数据统计追加到统计列
for r in range(len(count)):
new_ws.write(r, ws.ncols, count[r])
# 将每类产品追加到新的工作簿
new_ws2 = new_wb.add_sheet('汇总数据')
for i, key in enumerate(fen.keys()):
data = fen.get(key)
# 追加分类
new_ws2.write(i, 0, key)
# 追加数据
new_ws2.write(i, 1, data)
new_wb.save('./create_data/04_汇总数据.xls')
通过xlutils的copy操作,将通过xlrd读取得到的数据复制成为可以写入的对象。将count中的每一个值对应原数据中的每一行,添加在最后。fen中的数据为读取函数中得到的第二个返回值,创建新的工作簿,将数据保存在新的工作簿中。
4.测试使用
if __name__ == '__main__':
count_price, _type = read_excel()
save(count_price,_type)
最终得到:

三、表格拆分
1.引入库
代码如下:
import xlrd
from xlutils.copy import copy
在这里,我们同样使用xlrd和xlutils两个模块来实现下面的操作
2.定义读取数据的函数
代码如下:
def read_data():
# 打开文件
wb = xlrd.open_workbook('./create_data/04_数据统计.xls')
# 获取工作簿
ws = wb.sheet_by_index(0)
# 获取每一列的数据
all_data = {}
for r in range(ws.nrows):
# 获取具体的数据
temp_data = {'type': ws.cell_value(r, 1), 'name': ws.cell_value(r, 2), 'count': ws.cell_value(r, 3), 'price': ws.cell_value(r, 4)}
# 获取分类数据
key = ws.cell_value(r, 0)
if all_data.get(key):
all_data[key].append(temp_data)
else:
all_data[key] = [temp_data]
return all_data
在这个函数中,我们得到以下数据:
{
'A': [
{'type': '水果', 'name': '苹果', 'count': 100.0, 'price': 3.5},
{'type': '水果', 'name': '香蕉', 'count': 100.0, 'price': 3.2},
{'type': '水果', 'name': '葡萄', 'count': 100.0, 'price': 3.0},
{'type': '水果', 'name': '椰子', 'count': 100.0, 'price': 6.0},
{'type': '水果', 'name': '榴莲', 'count': 100.0, 'price': 15.0}
],
'B': [
{'type': '生活用品', 'name': '热水器', 'count': 30.0, 'price': 60.0},
{'type': '生活用品', 'name': '压力锅', 'count': 40.0, 'price': 140.0},
{'type': '生活用品', 'name': '空气炸锅', 'count': 50.0, 'price': 66.0},
{'type': '生活用品', 'name': '体重秤', 'count': 30.0, 'price': 26.0},
{'type': '生活用品', 'name': '电吹风', 'count': 40.0, 'price': 13.0}
],
'C': [
{'type': '零食', 'name': '酸奶', 'count': 100.0, 'price': 60.0},
{'type': '零食', 'name': '速冻面点', 'count': 100.0, 'price': 12.0},
{'type': '零食', 'name': '午餐肉', 'count': 80.0, 'price': 15.5},
{'type': '零食', 'name': '儿童零食', 'count': 100.0, 'price': 3.5}
]
}
3. 定义保存数据的函数
def save(data):
# 打开文件
wb = xlrd.open_workbook('./create_data/04_数据统计.xls')
new_wb = copy(wb)
for key in data.keys():
# 创建工作簿 根据分类创建不同的工作簿
tmp_sheet = new_wb.add_sheet(key)
# 遍历每个分类的数据
for i, d in enumerate(data.get(key)):
tmp_sheet.write(i, 0, d.get('type'))
tmp_sheet.write(i, 1, d.get('name'))
tmp_sheet.write(i, 2, d.get('count'))
tmp_sheet.write(i, 3, d.get('price'))
new_wb.save('./create_data/05_表格的拆分.xls')
在保存数据中,根据得到的字典的key来建立工作簿,将每个key中的列表一一放入当前工作簿中,达到实现表格拆分的效果
4.测试使用
if __name__ == "__main__":
data = read_data()
save(data=data)
最终得到:


















 2223
2223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









